阅读量:1
- 转义字符由反斜杠\x组成,用于实现特殊功能
- 当想取消这些特殊功能时可以在前面加上反斜杠\
例如在Java中当\出现时是转义字符的一部分,具有特殊意义,前面加一个反斜可以取消其特殊意义,表示1个普通的反斜杠\,\\\\表示2个普通的反斜杠\\。其实就是要求Java中的字符串输出结果是正确的正则表达式。
1. 概念
正则表达式其实就是规则。
2. 字符类
- 单字符匹配规则,语法示例:
- [abc]:a 或者 b,或者 c 字符中的一个;
- [^abc]:除 a,b,c 以外的任何字符中的一个;
- [a-z]:a-z 小写字母中的一个;
- [A-Z]:A-Z 大写字母中的一个;
- [0-9]:0-9 数字中的一个;
- [a-zA-Z0-9]:a-z 或者 A-Z 或者 0-9 中的一个;
- [a-dm-p]:a 到 d 或 m 到 p 中的一个。
3. 逻辑运算符
- 语法示例:
- &&:并且
- | :或者
4. 预定义字符
- 语法示例:
- “.” : 匹配任何字符;
- “\d”:任何数字 [0-9] 的简写;
- “\D”:任何非数字 [^0-9] 的简写;
- “\s”: 空白字符 [ \t\n\x0B\f\r] 的简写;
- “\S”: 非空白字符 [^\s] 的简写;
- “\w”:大小字母或数字或下划线或汉字;
- “\W”:非单词字符 [^\w] ;
- “\t”:一个 Tab 的间隔。
5. 数量词
- 语法示例:
- X? : 0 次或 1 次;
- X* : 0 次或者多次;
- X+ : 1 次或者多次;
- X{n} : 正好好 n 次;
- X{n,} : 至少 n 次;
- X{n,m}: n 到 m 次(n 和 m 都是包含的)
正则表达式的作用:
(1)检验字符串是否满足某些规则。
(2)查找一段文本中满足某些规则的内容。
1、下面是作用1:检验字符串是否满足某些规则的练习
(1)请编写正则表达式验证用户输入的手机号码是否满足要求。
- 中国手机号码是以 13、14、15、16、17、18、19 开头的11位数字:1[3-9]
String regex = "1[3-9]\\d{9}"; System.out.println("15236302279".matches(regex));(2)请编写正则表达式验证用户输入的邮箱号是否满足要求。
- 邮箱包括用户名和域名两部分,它们之间由@符号连接
- 用户名包括字母、数字和下划线,至少有一个字符:\\w+
- 域名包括两部分:邮箱服务提供商和域名
- 邮箱服务提供商:任意的字母加数字,总共出现2-7次:[\\w&&[^_]]{2,7}
- 域名:大小写字母,如.com,.cn,.edu.cn等,出现2-3次:(\\.[a-zA-Z]+){1,2}
String regex2 = "\\w+@[\\w&&[^_]]{2,7}(\\.[a-zA-Z]+){1,2}"; System.out.println("liuyujie@163.com".matches(regex2));(3)请编写正则表达式验证用户输入的座机号码是否满足要求。
- 座机号码包括区号和电话号码两部分,它们之间通常用连字符
-隔开。有时候也可以省略连字符。 - 区号一般是3位或4位数字,第一位是0:0\\d{2,3}
- 连字符-,有时也可省略:-?
- 电话号码一般是7位或8位数字,第一位不能为0:\\d{7,8}。
String regex3 = "0\\d{2,3}-?\\d{7,8}"; System.out.println("010-12345678".matches(regex3));2、查找一段文本中满足某些规则的内容
练习:
- 首先获取正则表达式的对象;
- 然后获取文本匹配器的对象;
- find()方法:文本匹配器从头开始读取,寻找是否有满足规则的子串。如果没有,方法返回false;如果有,返回true。在底层记录子串的起始索引和结束索引+1。
- group()方法:方法底层会根据find方法记录的索引进行字符串的截取,其实就是利用substring(起始索引,结束索引);包头不包尾,把截取的小串进行返回。
//1.获取正则表达式的对象 Pattern p = Pattern.compile("Java\\d{0,2}"); //2.获取文本匹配器的对象 //m去读取text,找符合p规则的子串 Matcher m = p.matcher(text); //3.利用循环获取 while (m.find()) { String s = m.group(); System.out.println(s); }有如下文本,按要求爬取数据。
Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台。
需求1:爬取版本号为8,11.17的Java文本,但是只要Java,不显示版本号。
需求2:爬取版本号为8,11,17的Java文本。正确爬取结果为:Java8 Java11 Java17 Java17
需求3:爬取除了版本号为8,11,17的Java文本。
6. 零宽断言和负向零宽断言
- (?=...) 用于查找在某些内容(但并不包括这些内容)之前的东西。
- (?!...) 排除某些内容的匹配。例如:\d{3}(?!\d),首先匹配三位数字,然后这三位数字的后面不能是数字。
- (?:...)用来对表达式进行分组,但是不会捕获。例如:表示匹配 "Java" 这个单词,但不会把它作为一个捕获组,因此不能通过后向引用\1等方式再次使用这个匹配结果。
String s = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," + "因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台"; //1.定义正则表达式 //?指代前面的数据Java //=表示在Java后面要跟随的数据 //但是在获取的时候,只获取前半部分 //需求1: String regex2 = "((?i)Java)(?=\\d{1,2})"; //需求2: String regex2 = "((?i)Java)(\\d{1,2})"; String regex3 = "((?i)Java)(?:\\d{1,2})"; //需求3: String regex4 = "((?i)Java)(?!\\d{1,2})"; Pattern p = Pattern.compile(regex4); Matcher m = p.matcher(s); while (m.find()) { System.out.println(m.group()); }7. 贪婪匹配和懒惰匹配
- 贪婪匹配:匹配尽可能多的字符。
- 懒惰匹配:匹配尽可能少的字符。
- 正则表达式在匹配多个字符时尽可能多,默认是贪婪匹配;如果在后面加上?则表示懒惰匹配,如 +? 表示懒惰匹配。
8. 忽略大小写
- (?i) :在开头使用表示接下来所有的数据都忽略大小写,但是一个字符串中如果只想忽略某个字符的大小写,可以这样写:a((?i)b)c,只忽略字母b的大小写,a和c只能是小写。
9. 捕获分组和非捕获分组
- 捕获分组是用()定义的分组,它可以把匹配到的内容保存到一个单独的组中,以便后续引用或者在匹配后进行处理。
- (?:) (?=) (?!)都是非捕获分组,更多的使用(?:...)这样的语法来剥夺一个分组对组号分配的参与权。
10. 分组组号
- ()表示捕获分组。
- 组号如何识别?从左往右,左括号是第几个就是第几组,组号是连续不间断的。
- \\X:表示把第X组的内容再出来用一次。
需求1:判断一个字符串的开始字符和结束字符是否一致?只考虑一个字符。
- 用.来匹配第一个字符。
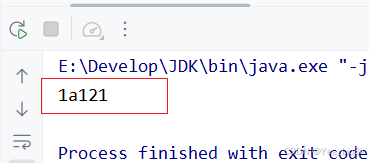
String regex = "(.).*\\1"; System.out.println("a121a".matches(regex));需求2:判断一个字符串的开始部分和结束部分是否一致?可以有多个字符。
String regex2 = "(.+).*\\1"; System.out.println("abc123abc".matches(regex2));需求3:判断一个字符串的开始部分和结束部分是否一致?开始部分内部每个字符也需要一致。
String regex3 = "((.)\\2*).*\\1"; System.out.println("aaa123aaa".matches(regex3));需求4:将字符串“我要学学编编编编程程程程程程”替换为“我要学编程”,即将重复的字符替换为单个字符。
- 如何获取一段文本中重复2次及以上的字符?(.)\\1+
- 字符串的replaceAll和split两个方法都可以使用正则表达式
- 在正则表达式外使用分组,格式为$X,其中X为组号
String text = "我要学学编编编编程程程程程程"; String regex = "(.)\\1+"; System.out.println(text.replaceAll(regex, "$1"));结合需求1-3以及4的思考:
public class RegexDemo7 { public static void main(String[] args) { String text = "1a222a"; String regex1 = "(.).*\\1"; Pattern p = Pattern.compile(regex1); Matcher m = p.matcher(text); while (m.find()) { String s = m.group(); System.out.println(s); } } }输出结果
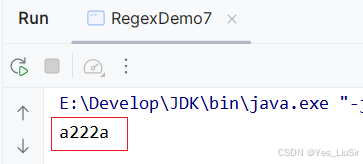
当文本为下面这个时输出结果为
String text = "1a121a";