
阅读量:3
系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
AI大模型探索之路-训练篇14:大语言模型Transformer库-Trainer组件实践
AI大模型探索之路-训练篇15:大语言模型预训练之全量参数微调
AI大模型探索之路-训练篇16:大语言模型预训练-微调技术之LoRA
AI大模型探索之路-训练篇17:大语言模型预训练-微调技术之QLoRA
AI大模型探索之路-训练篇18:大语言模型预训练-微调技术之Prompt Tuning
AI大模型探索之路-训练篇19:大语言模型预训练-微调技术之Prefix Tuning
AI大模型探索之路-训练篇20:大语言模型预训练-常见微调技术对比
AI大模型探索之路-训练篇21:Llama2微调实战-LoRA技术微调步骤详解
AI大模型探索之路-训练篇22: ChatGLM3微调实战-从原理到应用的LoRA技术全解
AI大模型探索之路-训练篇23:ChatGLM3微调实战-基于P-Tuning V2技术的实践指南
AI大模型探索之路-训练篇24:ChatGLM3微调实战-多卡方案微调步骤详解
目录
前言
在当前信息技术迅猛发展的时代,知识库的构建与应用已成为企业竞争的关键。随着自然语言处理技术的不断进步,基于微调的企业级知识库改造落地方案受到越来越多的关注。在前面的系列篇章中我们分别实践了基于CVP架构-企业级知识库实战落地和基于基于私有模型GLM-企业级知识库开发实战;本文将深入探讨和实践一种基于微调技术的企业级知识库改造方法,以期为企业提供更加高效、安全和可靠的知识管理解决方案。
一、概述
企业知识库架构方案,通常有3中可选方案:
1)基于在线的大模型如ChatGPT,加上Embedding技术,通过更新迭代向量数据库;开发、运维简单,开发门槛比较低;仅需少量的AI知识技能储备,但是需要将知识开放给大模型;
2)基于开源的大模型如GLM,Llama,自己独立部署,同样加上Embedding技术,通过更新迭代向量数据库;开发、运维简单,需要提供硬件GPU资源保障;需要较少的AI知识技能储备,可以保障知识库的隐私安全;
3)基于开源的大模型如GLM,Llama,自己独立部署,采用微调技术,再同样加上Embedding技术,通过更新迭代向量数据库;开发、运维简单,需要提供硬件GPU资源保障;需要较深的AI知识技能储备,可以保障知识库的隐私安全;可以自己定制化扩展。( 如果知识库更新频率较低,可以不需要引入向量数据库作为补充,直接定期微调即可)
二、知识库核心架构回顾(RAG)
1、知识数据向量化
首先,通过文档加载器加载本地知识库数据,然后使用文本拆分器将大型文档拆分为较小的块,便于后续处理。接着,对拆分的数据块进行Embedding向量化处理,最后将向量化后的数据存储到向量数据库中以便于检索。
2、知识数据检索返回
根据用户输入,使用检索器从向量数据库中检索相关的数据块。然后,利用包含问题和检索到的数据的提示,交给ChatModel / LLM(聊天模型/语言生成模型)生成答案。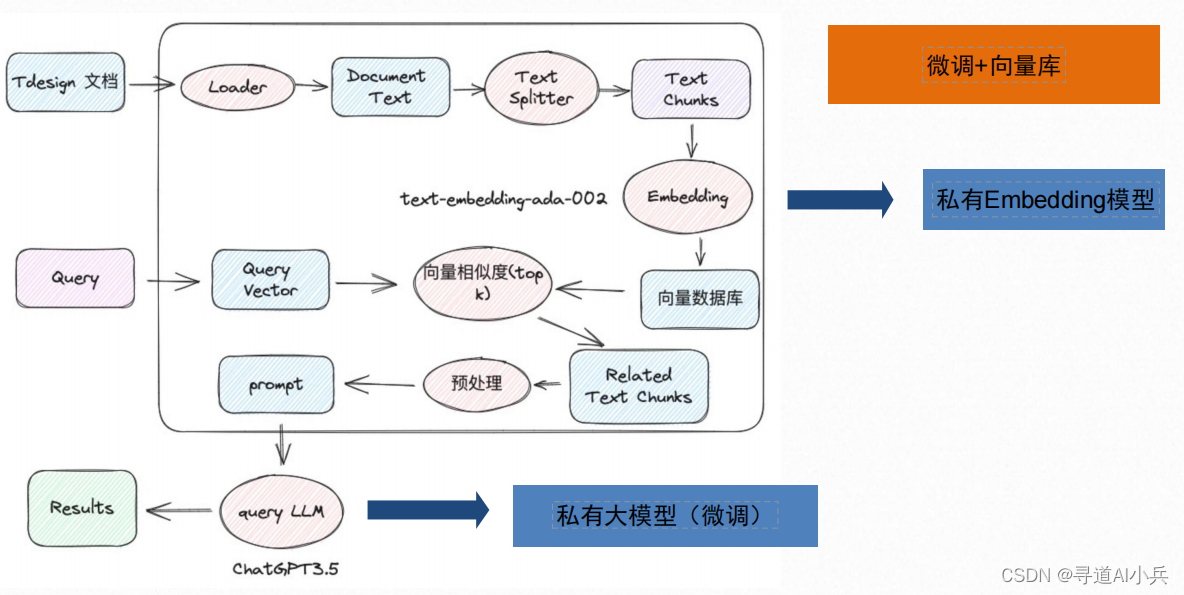
三、技术选型
1、模型选择ChatGLM3-6B
1)开源的:需要选择开源的项目方便自主扩展。
2)高性能的:选择各方面性能指标比较好的,能够提升用户体验。
3)可商用的:在不增加额外成本的前提下,保证模型的商用可行性。
4)低成本部署的:部署时要能够以最低成本代价部署运行知识库,降低公司成本开支。
5)中文支持:需要选择对我母语中文支持性比较好的模型,能够更好的解析理解中文语义。
注意:选择ChatGLM3-6B更主要的原因是方便自己能够跑起来(本钱不够)
企业实践可以考虑通义千问-72B(Qwen-72B),阿里云研发的通义千问大模型系列的720亿参数规模的模型。Qwen-72B是基于Transformer的大语言模型,
在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-72B的基础上,还使用对齐机制打造了基于大语言模型的AI助手Qwen-72B-Chat。
主要有以下特点:
1)大规模高质量训练语料:使用超过3万亿tokens的数据进行预训练,包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。通过大量对比实验对预训练语料分布进行了优化。
2)强大的性能:Qwen-72B在多个中英文下游评测任务上(涵盖常识推理、代码、数学、翻译等),效果显著超越现有的开源模型。具体评测结果请详见下文。
3)覆盖更全面的词表:相比目前以中英词表为主的开源模型,Qwen-72B使用了约15万大小的词表。该词表对多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强和扩展。
4)更长的上下文支持:Qwen-72B支持32k的上下文长度。
5)系统指令跟随:Qwen-72B-Chat可以通过调整系统指令,实现角色扮演,语言风格迁移,任务设定,和行为设定等能力。*
资源要求:运行FP16模型需要多卡至少144GB显存(例如2xA100-80G或5xV100-32G);运行Int4模型(生产环境不建议采用量化技术,避免影响准确度)
至少需要48GB显存(例如1xA100-80G或2xV100-32G)
2、Embedding模型选择
我们要选择一个开源免费的、中文支持性比较好的,场景合适的,各方面排名靠前的嵌入模型。
MTEB排行榜:https://huggingface.co/spaces/mteb/leaderboard ,MTEB是衡量文本嵌入模型在各种嵌入任务上性能的重要基准;可从排行榜中选相应的Enbedding模型;
本次从中选择使用比较广泛的 bge-large-zh-v1.5 (同样也是智谱AI的开源模型),常用的还有text2vec-base-chinese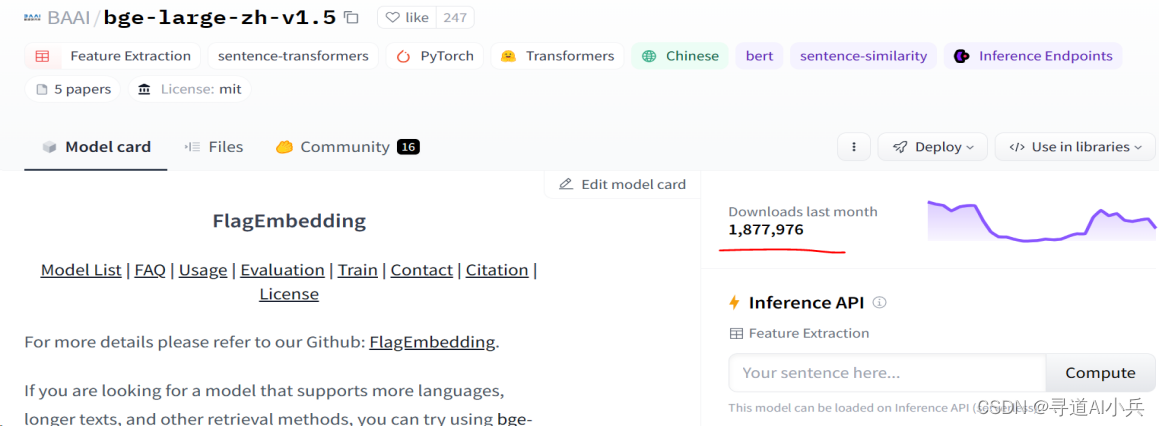
四、改造后的技术选型
1)LLM模型:ChatGLM3-6B
2)Embedding模型:bge-large-zh-v1.5/text2vec-base-chinese
3)应用开发框架:LangChain
4)向量数据库:FAISS/pinecone/Milvus
5)WEB框架:streamlit/gradio
6)训练技术:高效微调
7)高效微调技术:LoRA
五、服务器资源准备
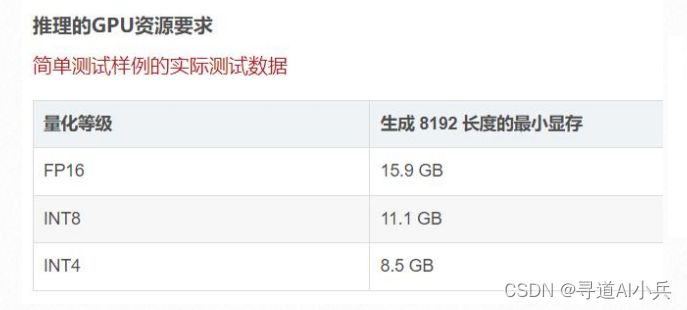
1)如果精度为FP16, 需要GPU显存大概需要16G左右。
2)如果量化为int8, 需要GPU显存大概需要12G左右。
3)如果量化为int4, 需要GPU显存大概需要8.5G左右。
实际情况需要比估算值要更大一点,购买云资源配置如下
六、私有模型下载测试
1、下载ChatGLM3工程
git clone https://github.com/THUDM/ChatGLM3
2、安装依赖
执行下面的pip命令,安装依赖
cd ChatGLM3
pip install -r requirements.txt
3、模型测试
进入basic_demo目录,查看测试的demo,执行脚本:
python cli_demo.py
这个目录放了各种测试用的demo,为了方便使用,本次主要采用命令行客户端的方式测试 
七、微调工具LLaMA-Factory
1、LLaMA-Factory简介
本次采用市面流行的微调工具LLaMA-Factory,实现无代码微调;它提供了简单易用的训练推理一体化WebUI 。
git地址:https://github.com/hiyouga/LLaMA-Factory.git
特点如下:
1)几乎为0的命令行操作和零代码编辑
2)中英文双语界面即时切换
3)训练、评估和推理一体化界面
4)预置 25 种模型和 24 种多语言训练数据
5)即时的训练状态监控和简洁的模型断点管理
2、LLaMA-Factory下载安装
1)下载工程
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
2)创建单独python环境
conda create -n llama_factory python=3.10
conda activate llama_factory
3)安装依赖
cd LLaMA-Factory
pip install -e .[torch,metrics]
3、LLaMA-Factory测试
使用官网提供的 Llama3-8B-Instruct 进行测试
1)下载Llama3-8B-Instruct
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
下面三行命令分别对 Llama3-8B-Instruct 模型进行 LoRA 微调、推理和合并。
注意:执行之前将下面3个文件中的模型地址改为本地下载的地址
2)模型微调
执行命令:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/lora_single_gpu/llama3_lora_sft.yaml 也可以直接采用原始命令参数的方式调用,例如:
llamafactory-cli train \ --model_name_or_path /root/autodl-tmp/model/Meta-Llama-3-8B-Instruct \ --template llama3 微调结果如下: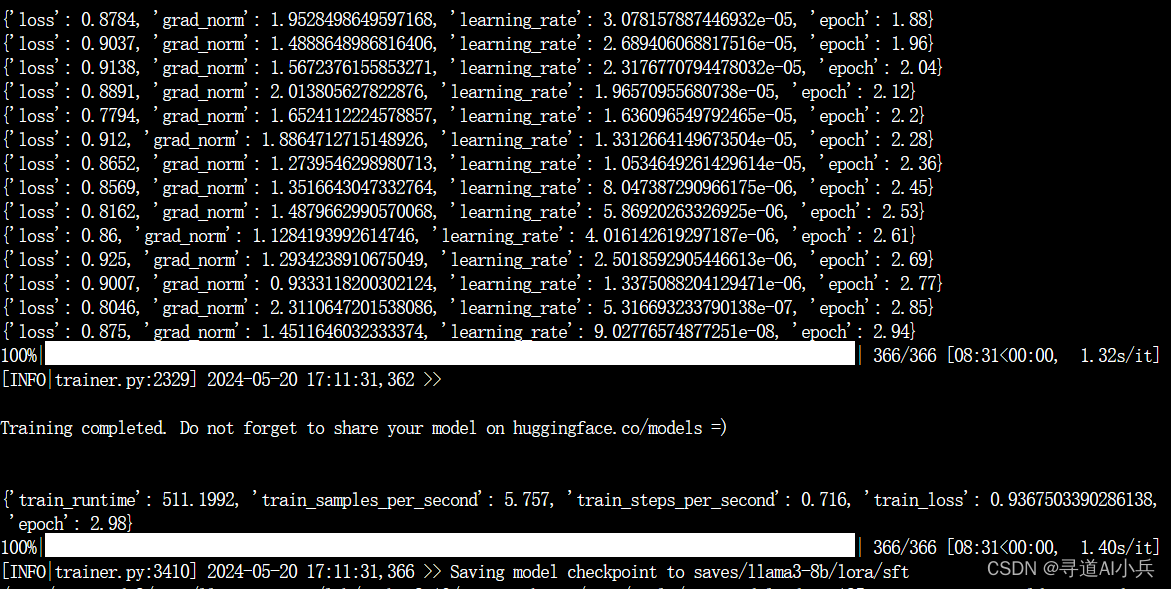
3)模型推理
执行命令:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat examples/inference/llama3_lora_sft.yaml 使用浏览器界面风格推理
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat examples/inference/llama3_lora_sft.yaml 启动 OpenAI 风格 API推理 CUDA_VISIBLE_DEVICES=0 llamafactory-cli api examples/inference/llama3_lora_sft.yaml 推理如下: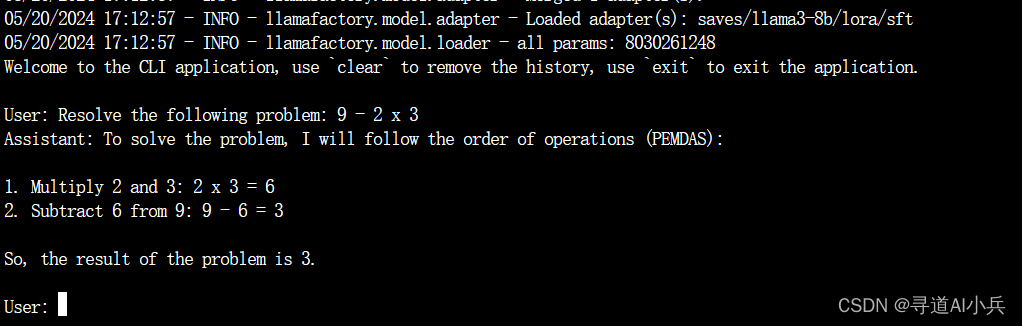
4)模型合并
执行命令:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml 合并结果:
/root/autodl-tmp/LLaMA-Factory/models/llama3_lora_sft
八、基于模型问题本地知识库
1、环境映射配置
1)AutoDL配置
(注:仅限于跟我一样用的AutoDL平台的场景)
如果您正在使用 AutoDL,先修改AutoDL的默认对外开放的端口:
export GRADIO_SERVER_PORT=6006 2)启动web UI界面
CUDA_VISIBLE_DEVICES=0 GRADIO_SHARE=1 llamafactory-cli webui ---启动后页面打开展示不全 后改用了老版本的LLaMA-Factory
cd LLaMA-Factory pip install -r requirements.txt python src/train_web.py 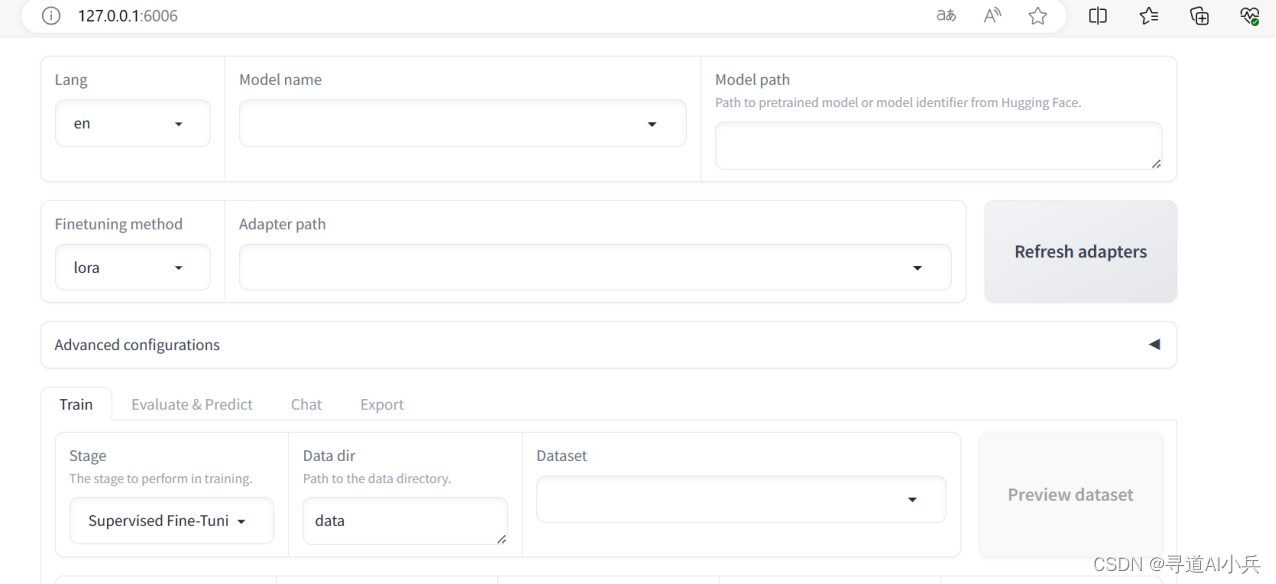
3)本地端口映射处理
(注:仅限于跟我一样用的AutoDL平台的场景)
ssh -CNg -L 6006:127.0.0.1:6006 root@123.125.240.150 -p 42151
其中root@123.125.240.150和42151分别是实例中SSH指令的访问地址与端口,请找到自己实例的ssh指令做相应替换。6006:127.0.0.1:6006是指代理实例内6006端口到本地的6006端口。
2、模型下载
1)下载模型(权重相关文件)
在autodl-tmp下新建model用于放模型文件
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
检查权重文件
对比modelscope上的文件列表和文件的大小,检查是否下载完整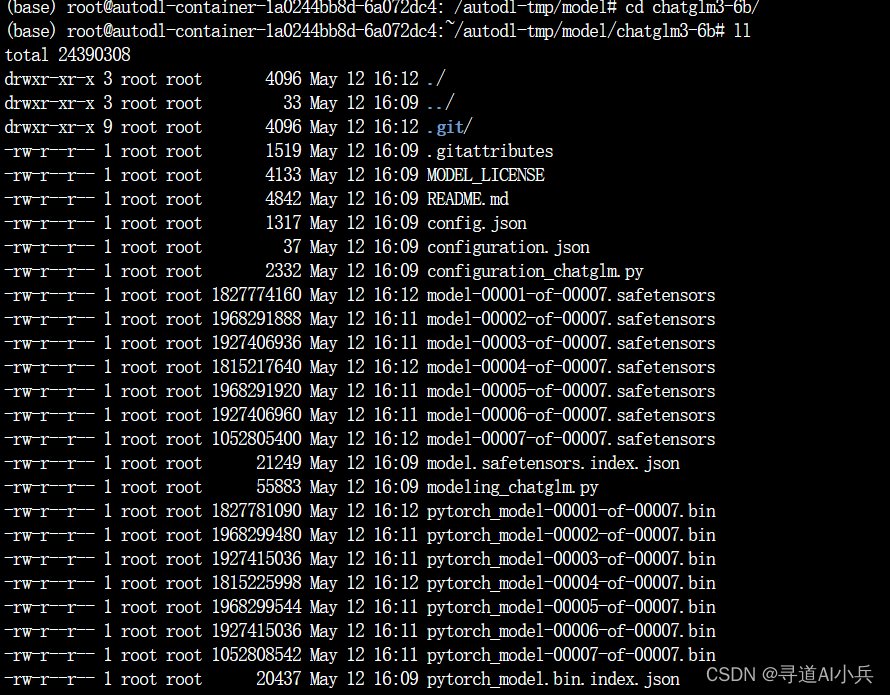
2)下载embedding模型
下载huggingface上的词嵌入模型
git clone https://huggingface.co/BAAI/bge-large-zh-v1.5
git clone https://huggingface.co/shibing624/text2vec-base-chinese
3、数据准备
{ "instruction": "朱利叶斯·凯撒是如何死亡的?", "input": "", "output": "朱利叶斯·凯撒,又称尤利乌斯·恺撒(Julius Caesar)是古罗马的政治家、军事家和作家。他于公元前44年3月15日被刺杀。 \n\n根据历史记载,当时罗马元老院里一些参议员联合起来策划了对恺撒的刺杀行动,因为他们担心恺撒的统治将给罗马共和制带来威胁。在公元前44年3月15日(又称“3月的艾达之日”),恺撒去参加元老院会议时,被一群参议员包围并被攻击致死。据记载,他身中23刀,其中一刀最终致命。" }, { "instruction": "法国的首都是什么?", "input": "", "output": "法国的首都是巴黎。" }, { "instruction": "生成一个人们去野营旅行可能需要的十件物品的清单。", "input": "", "output": "1. 帐篷: 帐篷是野营必备的物品,可以提供庇护,避免风吹日晒,还能够防止野生动物的干扰。\n2. 睡袋: 睡袋能够为您提供一个温暖舒适的睡眠环境,确保您在野外可以拥有一个良好的睡眠。\n3. 防水夹克: 在野外,天气变化无常,因此携带一件防水夹克十分必要,可以防止您被雨水淋湿。\n4. 照明设备: 如手电筒、头灯等,在野外夜晚黑暗的情况下为您提供照明,确保您的安全。\n5. 烹饪用具: 如便携式炉灶、锅碗瓢盆等,方便您在野外烹饪食物。\n6. 刀具: 如多功能军刀、折叠刀等,能够满足您在野外的各种需求。\n7. 防蚊液: 在野外,蚊虫十分繁多,因此携带防蚊液能够有效避免蚊虫叮咬。\n8. 防晒霜: 日晒对皮肤有害,携带防晒霜能够有效防护紫外线,避免晒伤。\n9. 水壶: 在野外,水是必不可少的,携带一个水壶能够方便您随时饮用。\n10. 随身背包: 一个轻" }, { "instruction": "讨论大萧条的原因", "input": "", "output": "大萧条是20世纪初期发生在全球范围内的经济衰退现象,其中最为严重的地区当属美国。这场经济危机持续了近十年之久,它的起因较为复杂,涉及多方面因素。\n\n首先,我们要提到1929年的股市崩盘。股票价格大幅下跌,导致投资者损失惨重,进而影响了消费信心。\n\n其次,当时的金融政策也是一个重要因素。为了维持金本位制度,联邦储备系统采取紧缩政策,却进一步加剧了资金短缺的问题。\n\n此外,当时政府对失业率的应对不力,社会保障制度不健全,也为经济衰退的进一步恶化埋下了祸根。\n\n最后,国际贸易也受到了影响。由于当时许多国家采取贸易保护主义政策,全球贸易额大幅下降,给各国经济造成了巨大冲击。\n\n综上所述,大萧条的原因是多方面的,涉及到金融政策,国际贸易,社会保障制度等多个领域。它给全球经济发展带来了严重的挑战,也为我们提供了深刻的历史经验教训。" } 将数据集添加到数据集库中
4、UI界面微调演示和验证
通过界面进行微调测试、再通过界面进行模型推理、最后在界面上直接进行模型合并
1)微调
默认是在Train训练页面;且训练阶段为“Supervised Fine-Tuning”(SFT)微调阶段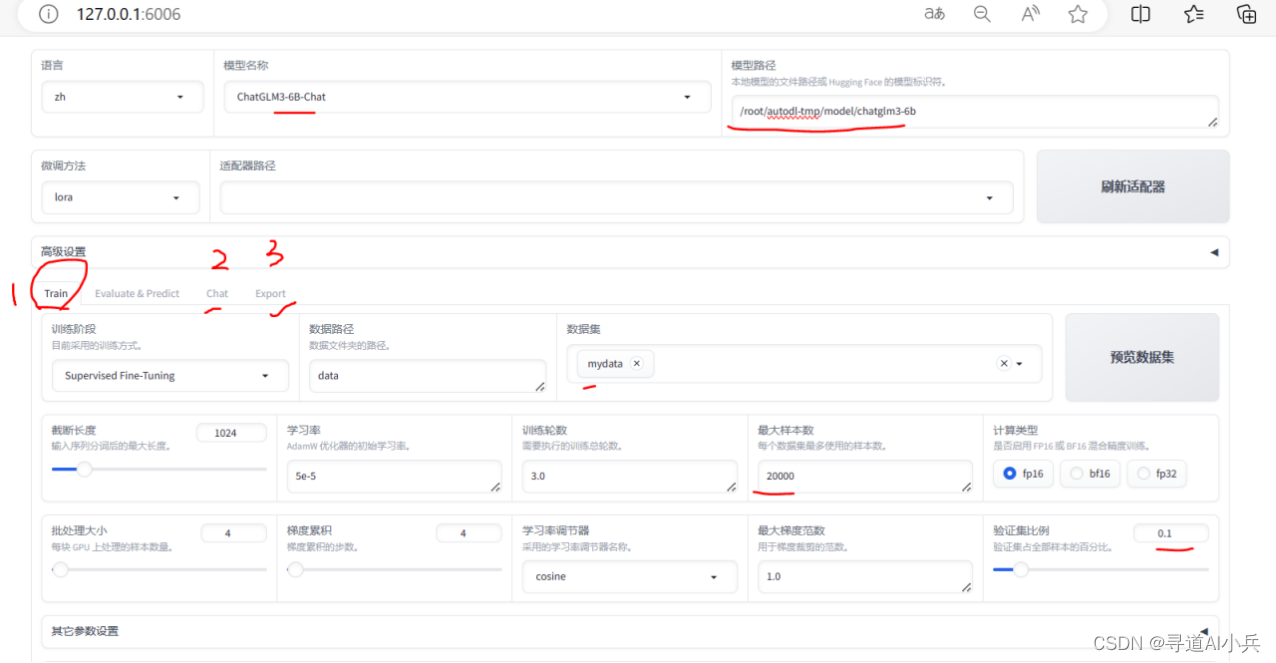
命令预览如下:
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \ --stage sft \ --do_train True \ --model_name_or_path /root/autodl-tmp/model/chatglm3-6b \ --finetuning_type lora \ --template chatglm3 \ --dataset_dir data \ --dataset mydata \ --cutoff_len 1024 \ --learning_rate 5e-05 \ --num_train_epochs 3.0 \ --max_samples 20000 \ --per_device_train_batch_size 4 \ --gradient_accumulation_steps 4 \ --lr_scheduler_type cosine \ --max_grad_norm 1.0 \ --logging_steps 5 \ --save_steps 100 \ --warmup_steps 0 \ --lora_rank 8 \ --lora_dropout 0.1 \ --lora_target query_key_value \ --output_dir saves/ChatGLM3-6B-Chat/lora/train_2024-05-20-21-25-48 \ --fp16 True \ --val_size 0.1 \ --evaluation_strategy steps \ --eval_steps 100 \ --load_best_model_at_end True \ --plot_loss True 微调结束: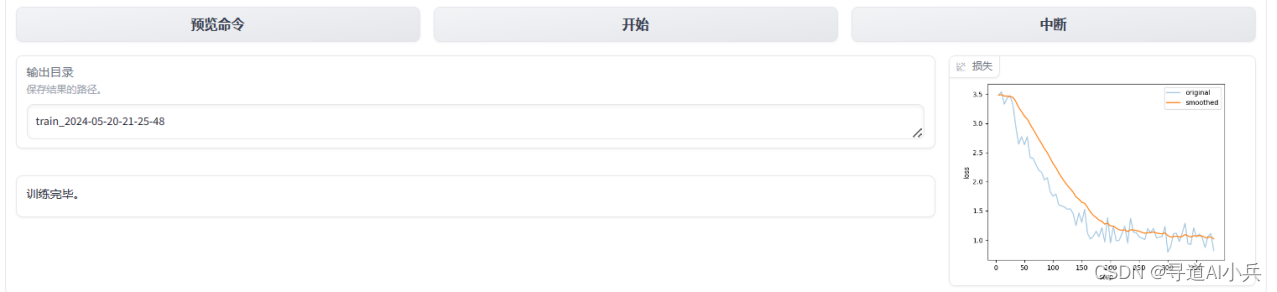
输出文件如下: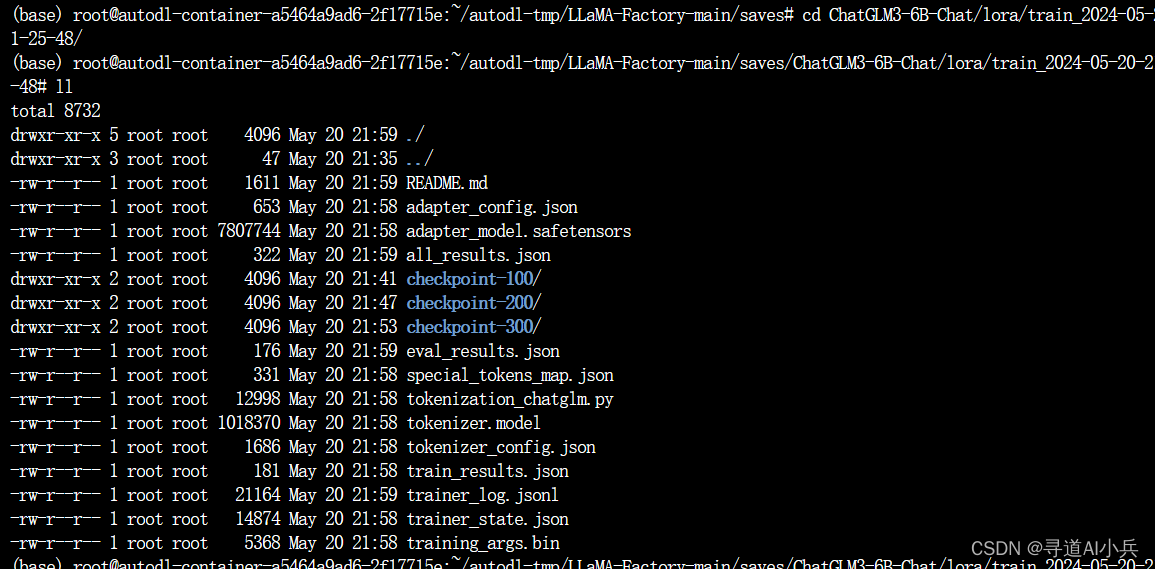
2)推理
切换到聊天模式,加载模型之后即可进行聊天提问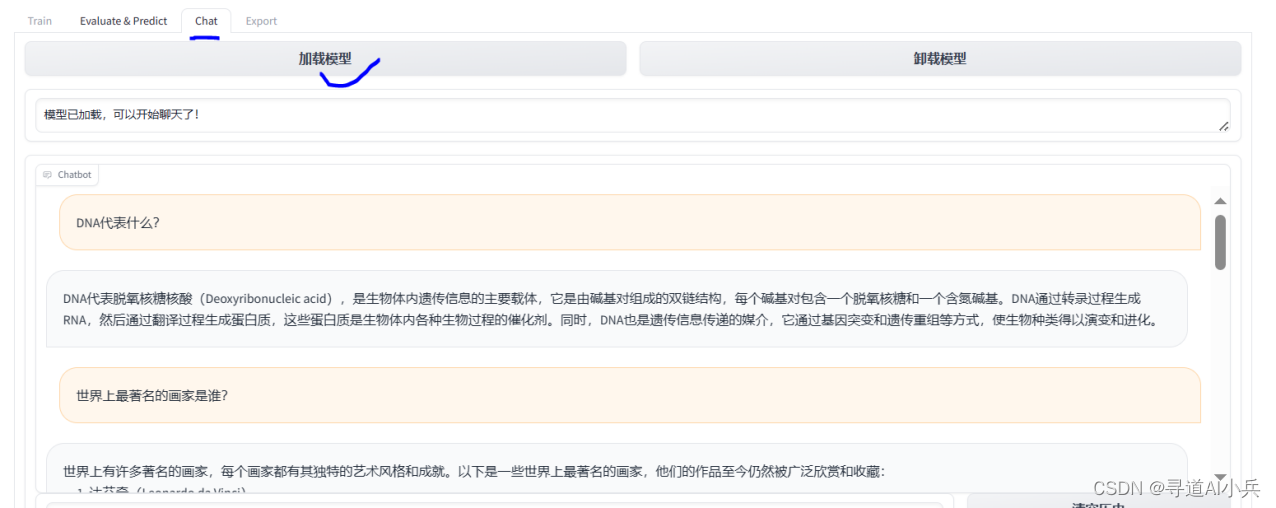
3)模型合并
先刷新适配器,再选择微调时输出的目录;设置最大的块大小;设置合并后导出的模型目录,进行导出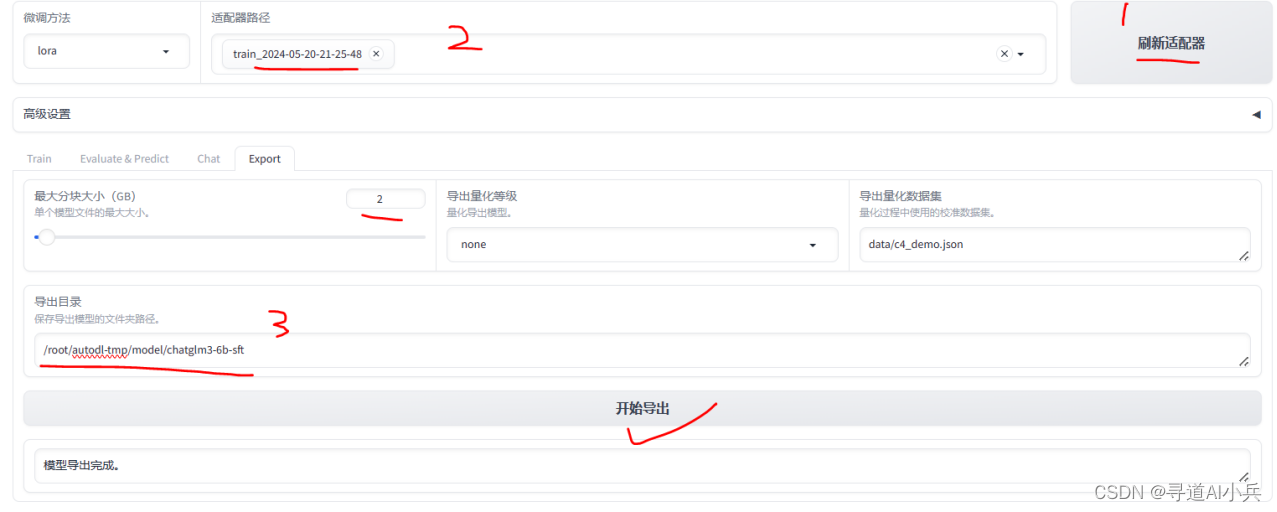
5、代码微调演示和验证
基于代码调用合并后的模型,进行推理验证,样例如下: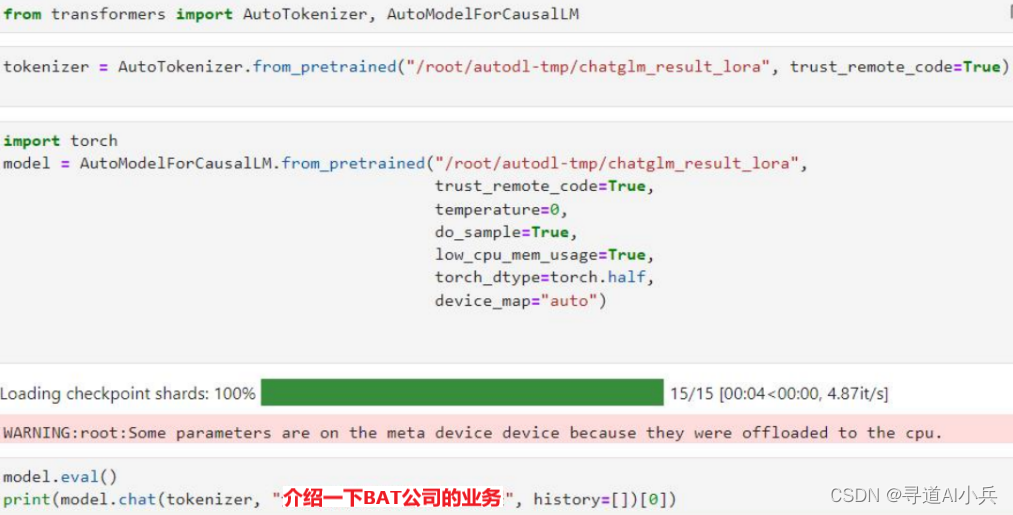
6、本地知识库代码改造
只需要将原来中直接引入"THUDM/chatglm3-6b"的地址,改为本地合并后的模型地址 “/root/autodl-tmp/model/chatglm3-6b-sft” 即可;
修改llm_model.py中的get_chatglm3_6b_model方法
def get_chatglm3_6b_model(model_path=keys.Keys.CHATGLM3_MODEL_PATH): MODEL_PATH = "/root/autodl-tmp/model/chatglm3-6b-sft" #"THUDM/chatglm3-6b" llm = chatglm3( llm.load_model(model_name_or_path=MODEL_PATH) return llm 其他内容和前面AI大模型探索之路-实战篇3基于私有模型GLM-企业级知识库开发实战中一样
启动运行测试: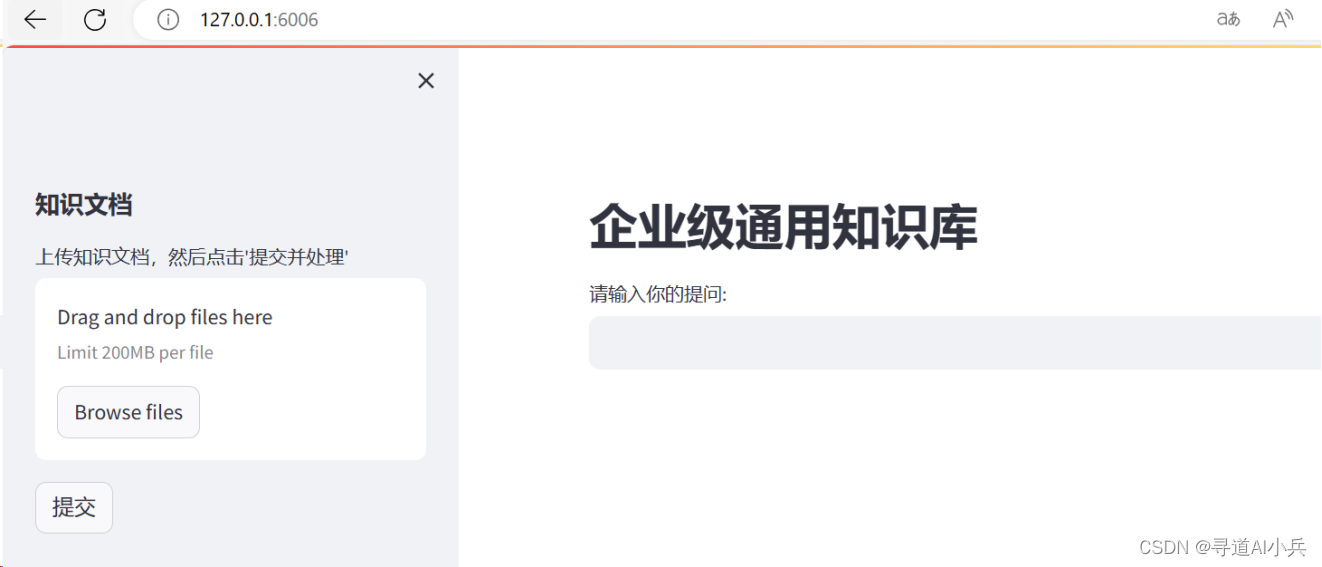
总结
通过本文的深入分析和实践,我们成功地实现了一种基于微调技术的企业级知识库改造落地方案。这一方案充分结合了自然语言处理技术和企业的实际需求,不仅提高了知识库构建的效率,还确保了数据的安全性和隐私性。在实践中,我们采用了开源的ChatGLM3-6B模型作为基础,通过微调技术对其进行优化,使其更加适应企业的应用场景。同时,我们还探讨了不同的知识库架构方案,为企业提供了更多的选择空间。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
