阅读量:2
摘要 :本文整理自 Apache Paimon Committer 闵文俊老师在5月16日 Streaming Lakehouse Meetup · Online 上的分享。内容主要分为以下四个部分:
- 什么是 Paimon
- 蚂蚁 Paimon 应用场景
- 蚂蚁 Paimon 功能改进
- 未来规划
一、什么是 Paimon
1. 实时更新
Paimon 是一种面向流而设计的实时数据湖格式。主要有以下特点:
支持高效的实时更新,是基于 LSM Tree 结构,整个流程基于 Append + Compaction 模型。LSM Tree是业界经过很多DB系统采纳的一种存储结构,写入和更新的吞吐可以得到较好保障。Paimon 也支持多种不同的 Changelog Producer,Changelog 类似于数据库里面的Binglog,是流式增量计算的核心。Paimon 支持多种不同的生产模式,用于生成 Paimon 表的 Changelog, 基于此可构建出 Paimon 表作为中间层的流式处理 Pipeline。Paimon 支持多种 Merge Engine,用户可以使用去重、聚合、Partial Update 等做 Paimon 表的 Merge Engine,数据合并的方式很灵活,可以满足不同业务场景的需要。在最新的 0.8 版本也支持了Deletion Vector,可以极大的提升查询性能。
2. 流批一体
Paimon 是一个流批一体的存储,支持流读、批读、Time Travel 的方式查询、维表点查、全增量一体消费,也支持流式写入和批式导入。总的来说,流批场景里都有它适用的场景。
3. OLAP友好
Paimon 是 OLAP 比较友好的存储。首先,它支持列式存储,默认它是基于 ORC 的存储格式。其次,Paimon 也会有丰富的 Statistics 来帮助 Plan 阶段做好 Data Skipping 之类的 Plan 优化。第三,Paimon 支持各种 DataLayout 优化,比如 Zorder 和 Hilbert 排序和数据重分布的优化,加速查询过程。
4. 生态丰富
Paimon 目前已经支持了市面上绝大部分的查询引擎,包括 Hive、Flink、Spark、Trino、Presto、Starrocks、Doris

二、蚂蚁Paimon应用场景
蚂蚁希望基于 Paimon 构建实时湖仓,统一实时和离线的开发模式。
在存储和计算侧实现流批一体,来达到降本增效的目标。接下来主要介绍 Paimon 在蚂蚁的应用场景。
1, 长周期累计去重
首先是最近的一次五福活动中所应用的长周期累计去重的场景。
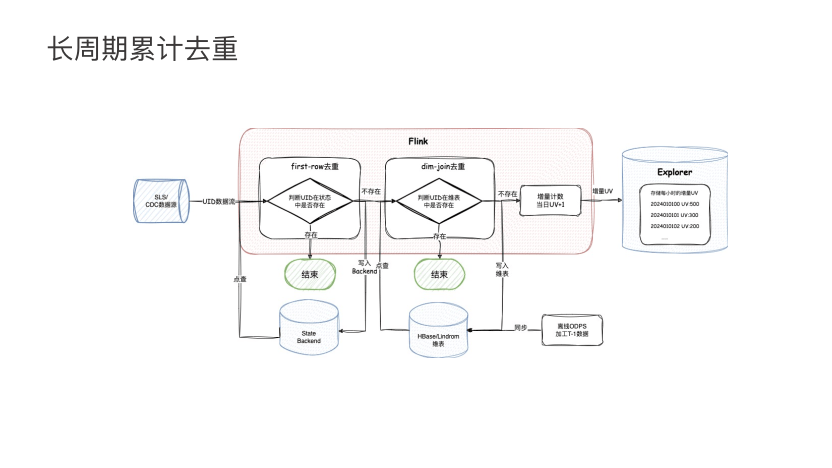
“五福”的长周期累计去重的简单意思是计算半个月或者一个月的累计活动参与 UV 数据。在引入 Paimon 前的链路如上图所示,主要借助两部分完成去重功能。首先,当数据进入时,借助 Flink 的 First-row 算子做短周期的去重,去重语义是基于 Flink 的状态完成的。一般在线上会保存一天左右的 Flink 状态来做去重。First-row 后,经过 Dim-join 通过维表加载离线的 T+1 清洗过的离线表做进一步去重。
在这个链路里为什么不完全依赖于 Flink 的状态来完成去重动作呢?会有两点的考虑:第一是状态,如果缓存全量的用户数据,对Flink作业的本地存储和计算性能都会有比较大的挑战。第二,从任务的鲁棒性角度考虑。一旦数据出现错误,需要回拉重算时,因为上游的流数据无法保存完整活动周期的全量数据,所以它的状态无法全量重建。一旦出现数据回刷,如果完全依赖 Flink 更新状态,会无法满足要求。
这个链路主要缺点有几点:第一,依赖实时和离线两个部分,链路的复杂性较高,需要用户周期性的维护它的维表数据,以及在开发的业务逻辑中,需要做实时的去重以及离线的维表加载、去重之类的逻辑。
引入 Paimon 后,链路如下图所示。
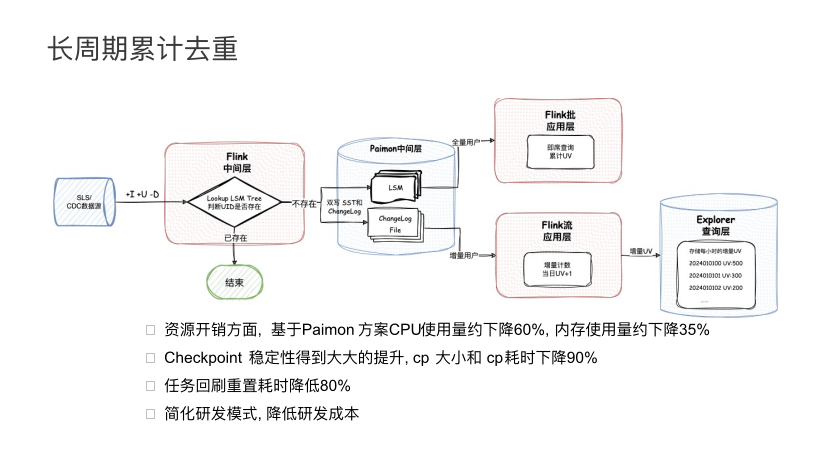
当一条数据写入后,利用 Paimon 的 First-row 就可达到类似于 Flink First-row 的去重效果,如果这条数据已出现过,那就不会下发新的数据。如果这条数据没有出现过,那就下发一条新增的映射的数据到下游。在下游,同时会产生它的 LSM Tree 的数据文件,以及Changelog 文件,通过一个 Flink 流任务去读取这张表,就可实时拿到该表增量用户的数据。然后在下游累加,累加后配置相应的报表就可完成链路开发。总体来说,引入 Paimon 后有几点好处:
第一,资源开销方面,基于 Paimon 方案 CPU 使用量约下降 60%, 内存使用量约下降 35%。第二,Checkpoint 稳定性得到大大的提升,Checkpoint 大小和耗时下降 90%,任务回刷重置耗时降低 80%。最后是通过简化研发模式, 降低研发成本,用户只要定义 Paimon 表、插入 Paimon 表、消费 Paimon 表,下游做累积聚合,就可完成原来这套业务语义的开发。
这样的流程主要利用 Paimon 的两个特性:
首先,利用了 Paimon 的 First-row 的 Merge Engine 。
第二,利用 Paimon 的 Changelog 生成增量的流消息,用于下游的二次聚合计算。
2. 极速核对场景
在蚂蚁的业务场景里会有一些类似于发奖、活动之类的业务。这些业务的特点就是与钱相关,通常需要有质量同学去做业务保障。
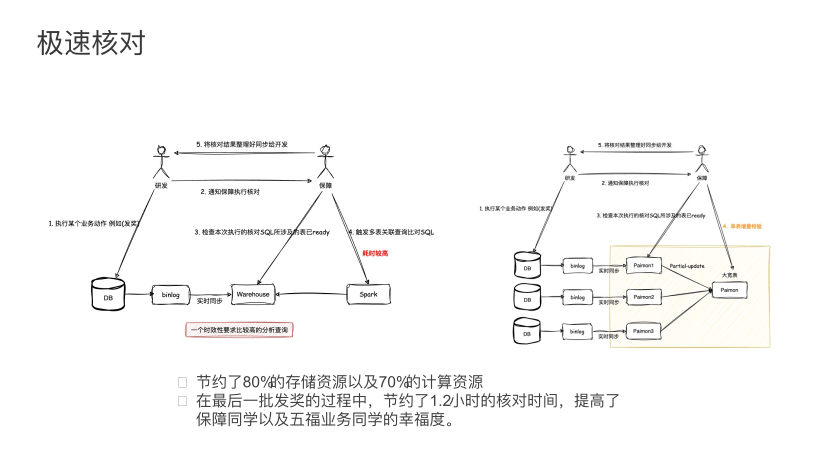
比如触发活动的发奖用户有这么多,发奖过程中是否有因为系统问题导致发奖出现错误,或者没发到奖给用户,或者给用户发奖发错了之类的情况。现在的这个做法一般是在业务研发去执行某个业务动作,比如发奖时候会操作 DB,产生的 Binlog 会同步到数仓。当研发同学执行完这次操作后,就会通知保障同学进行核对。保障同学首先检查本次测试执行核对的 SQL 所涉及的表,其数据已经完全准备好了,然后再触发多表关联查询,做多表 Join。由多表 Join 的结果核对,将核对结果整理好后同步给研发同学。整体来看,它是一个时效性要求较高的分析查询,涉及多表关联。然后在这个过程中,不断同步的数仓表是需要做全量关联的。
但通过 Paimon,利用 Paimon 的 Partial-update, 如上图右侧所示,在同步过程中,可直接将所需要校验的多个 DB 的数据打成一张大宽表。
可见,Paimon 的 Partial-update 是增量合并的过程。新写入的数据并不会全量的和各个表做 Join,只会在合并过程中修改增量的、更新的 key,这样计算量会大大降低。从真实的业务效果来看,大约节约了 80% 的存储资源以及 70% 的计算资源。从业务同学的直接反馈来说,能够大大降低核对时间,提高了保障同学以及五福业务同学的整体幸福度。
这个案例主要利用了 Paimon 的 Partial-update Merge Engine 实现增量的 Join,以及批式查询分析的能力来分析最终写入的这张大宽表里面的数据是否符合预期。
3. 离线分析查询加速
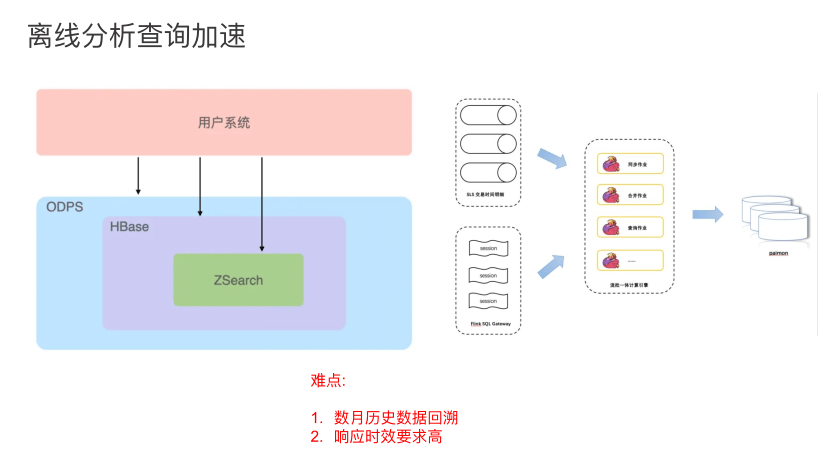
离线查询主要面向的场景是工单系统历史回溯的明细查询,工单系统中会有业务同学会根据用户ID查询用户的历史异常行为。他的查询主要有两个难点:
第一,查询范围可能会达到数月,每天的数据增量较大,Scan涉及到的数据量非常大。
第二,它类似于 ad-hoc 系统,对响应要求较高。之前链路为了加速过程,做了非常多缓存,包括利用 Elasticsearch(Zsearch)、 HBase 和 ODPS。ODPS 里会存储最终的明细数据,Elasticsearch、 HBase会存储各个层需加速的数据。目前这套体系已经改造成上图右侧Paimon的模式,业务数据会由Flink流任务实时同步写入 Paimon 分区表,并且周期性的提交 Sort Compact 调度任务,分区数据按指定的查询键排序。前台的工单系统经由 Flink SQL Gateway 提交查询任务,直接查询 Paimon 表的数据。
从总体业务效果来看:
- 存储成本更低, 使用 Paimon 作为统一存储,替换了昂贵的 Hbase 和 Elasticsearch 存储资源。
- 数据时效性高,近线数据实时同步,分钟级对用户可见(取决于Checkpoint 间隔),天级离线数据同步也从 19 小时降低到不足 1 小时。
- 运维成本低, 使用 Flink 作为统一计算引擎,使用 Paimon 作为通用存储,运维更高效。
- 根治了交易分析数据不准确的老大难问题。原方案数据在 ODPS、Hbase、Elasticsearch 存储多份,数据一致性难以保证,使用 Flink + Paimon 架构保证了查询的准确性。
- 通过 Sort Compact + BloomFilter 索引的优化,在查询阶段可以过滤大量的数据, 基本可以达到 5-10s 以内的查询耗时, 在极低的存储成本上满足业务的查询的需求。
三、蚂蚁 Paimon 功能改进
接下来主要介绍一下蚂蚁在 Paimon 上的功能改进。
1. Lookup Join
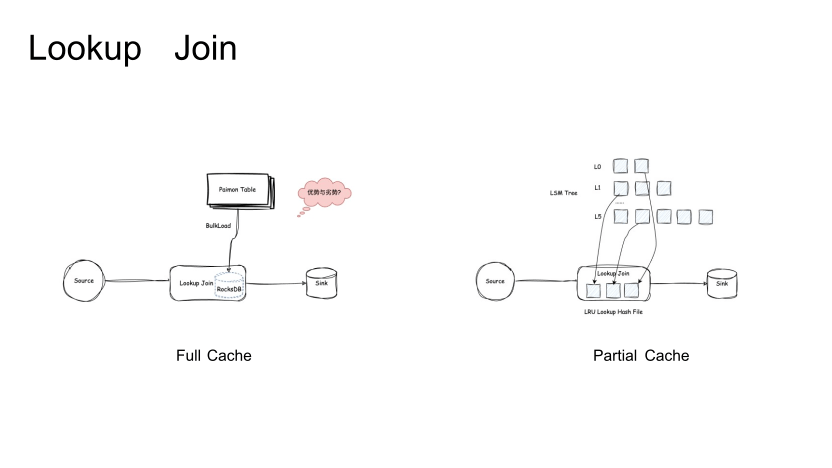
Lookup Join 是 Paimon 上支持维表点查的能力。之前主要只支持 Full Cache 模式,即 Paimon 表在不支持点查方式的情况下,只能将表在启动时直接加载到本地 RocksDB,通过本地 RocksDB 的点查能力来满足维表关联的过程。它的优点是能够去满足各种 Join Pattern。因为Join的时候并不一定仅仅是主键,可能会有非主键关联,Append 表关联。当加载到本地时,可在本地构建,如果是主键可以直接存储到主键到 Value 的映射关系。如果是非主键会存储二级索引。依赖于本地的 RocksDB 可以构建本地的关联索引,在关联的 Pattern 上可以比较灵活。
第二,当数据完全加载完成后,后续的关联效率是比较高的,因为后续的数据都是基于本地的 RocksDB 直接 Lookup,虽然后续增量数据读取的过程,但整体的增量数据不会特别影响 Lookup Join 的整体耗时。
但它有两个缺点:第一,对于本地的存储资源要求较高,对于磁盘比较受限的云化环境不太友好。第二,因为存在初始化加载的过程,初始化会比较慢,这个问题在后续版本里有了一定优化,比如并行加载以及 SDE Ingest 之类的。在此之上,做了 Partial Cache,思路是利用 LSM Tree 的有序性,由数据触发数据文件的 Load 。当接收到数据,根据 Join key 分析 key 所属的 Partition 和 Bucket,然后基于 LSM Tree 的有序性进行文件的定位和查找。当命中这个文件时,将文件 Load 到本地转化为 Lookup file。这个过程其实会跟 Changelog Producer 里的 Lookup Compaction 会比较类似。在经过 POC 验证后,在性能上是不满足要求的,它的数据 Lazy 下载和 Build 本地索引的过程耗时较高,查询的耗时会达到几百毫秒级别。主要原因在于数据到达 Lookup Join 的算子比较随机,导致后续每个并发的数据需要不断缓存不同的文件数据,缓存效率比较差。
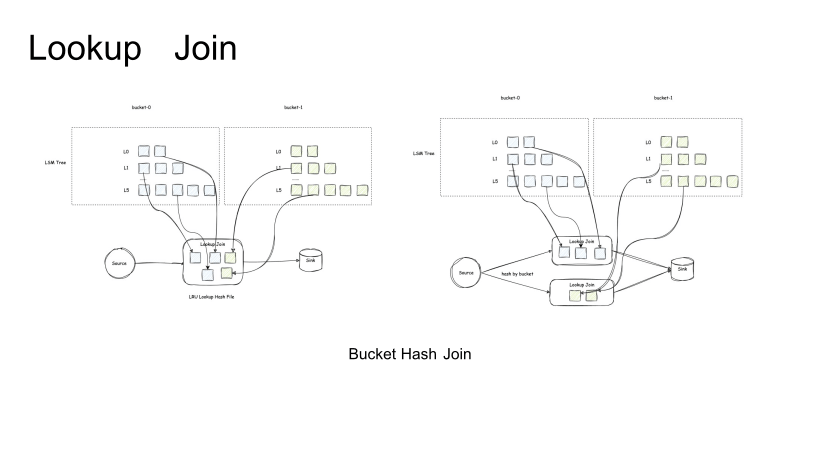
在 Flink 社区也有类似于 Partition Lookup Join 的方式来提高缓存命中率。不过实际验证下来,这种优化模式的效果还是不行,主要是原因是按照 Join key 的这种策略和数据分布不是一一对应的,Paimon 表中的数据是按照 Bucket 来分布的,因此能够提高 Paimon Lookup Join 缓存效率的方式应该是 Bucket Hash Join,也就是类似于上图中所示的左右两种方式。
左边的方式类似于 Lookup Partition Join 的方式,在加载时不涉及 Bucket 的信息。而右边的图则有 Bucket-0、Bucket-1,按照 Bucket shuffle 的话,Task0 只会加载 Bucket-0,这样数据加载缓存的效率会大大提高。
通过在 Flink 侧支持 Lookup Join 在前面插入 Custom Shuffle 的策略,经过测试这样优化后的维表查询效率能够达到1-2毫秒的 RT,能够极大提升维表的可用性。当然 Partial Cache 的这种模式对于数据分布有一定限制,无法像 Full Cache 达到各种模式。首先,仅支持 Fixed Bucket 的即固定 Bucket 的模式。在 Dynamic Bucket 的模式下,目前无法直接根据 Key 定位到所处的 Bucket,因为 Dynamic Bucket 有一个自动扩缩 Bucket 的过程。另外也只支持去重 Merge Engine 或者其它使用 Lookup Change Producer 的表。因为只有这种表才可以保证 LSM Tree 的最高层的数据文件是最新的。另外一点,它还依赖于 Flink 侧的改动,因此在社区版本的 Partial Cache 的缓存效率依然不高。Paimon 社区后续也会有计划去推进 Flink 社区去支持,Lookup Join 支持定制的Shuffle的策略。
2. Lookup BloomFilter Index
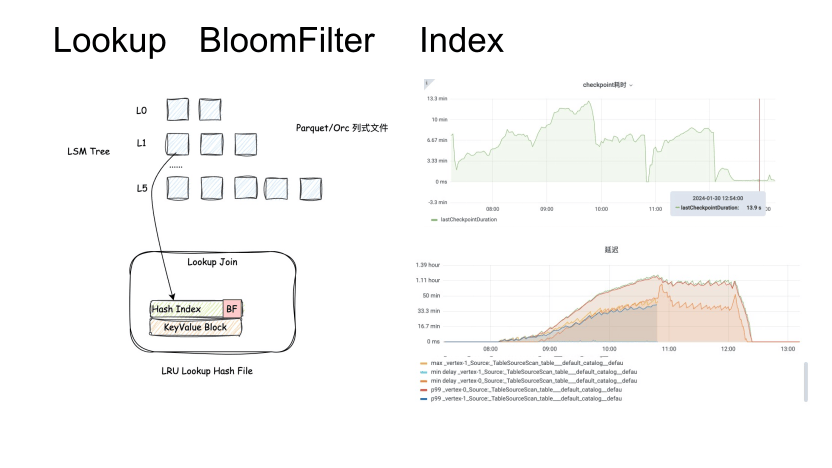
Lookup 上的另一个优化是支持本地 Lookup file 的 BloomFilter 索引。在 RockDB 查找的过程中,通过二分查找定位到文件后,利用 BloomFilter 来判断对应的key是否在文件中。如果判断存在,才会真正读取。而在 Paimon 中,由于也是多层的 LSM Tree,也可以利用这样的优化加速查找。主要场景有两个:一是 Lookup Join, 另一个就是 Lookup Change Producer。
为什么不直接利用远程文件的 BloomFilter 索引的主要原因有两个:
第一,远程文件的 BloomFilter 是一个对应文件格式,内部 SDK 写入,一般是由 BloomFilter 下推的方式判断,并无直接的判断方式,相对不可控 。
第二,远程文件判断需要不断读取文件的 File footer 的。频繁的 Seek 操作对 HDD 磁盘不友好。在最新的 Paimon 0.8 版本中,也开始在 Append 表上支持 File Index,也支持 File BloomFilter 索引,后续可以基于这些文件索引进一步加速文件查找的过程,以后把文件下载到本地这个过程可能都不需要了。因此在读取远程文件、本地 Build 时构建 BloomFilter 索引,后续二分查找命中此文件时,先进行 BloomFilter 索引判断,命中后再进行查找,从而节约了本地查找文件的过程。
上图右侧所示是first-row场景,也需要通过 Lookup 来做 Changelog 的生成,上线 BloomFilter 索引后,延迟和 Checkpoint 耗时下降明显,整体 Checkpoint更加稳定。
3. Merge Engine 拓展
- 支持 First Row Merge Engine (支持 Event Time/Process Time 去重), 但和社区的同学讨论下来,Event Time 的性能不如直接基于Process Time 语义的模式。
- 支持 Partial-update with Aggregation。
- 支持 Roaring Bitmap / Theta Sketch 等常用计算 UV 聚合函数和分析函数,好处是可在 Paimon 表上直接定义一列存储 RBM 的数据,可以去对写入数据做上传下载的 操作,计算不同维度UV的合并值。这种场景在很多 BI 报表里使用会比较频繁。
- 支持 Exclusive Sequence 解决 last_non_null_value / first_non_null_value 聚合函数等对独立版本号更新的需求,即当前数据里的同一列数据、同一行数据的 Sequence 更新的默认更新策略是 Sequence 不断递增。但这样会存在的问题是比如 last_non_null_value / first_non_null_value 函数保留的数据和它的版本号是不对应的,易导致计算结果和预期不符。使用 Exclusive Sequence 的问题在于它使用不灵活,需要显示的定义各个聚合列的 Sequence。虽然使用灵活度会降低,但准确性是可以得到保障的。
4. Change log生命周期解耦
Paimon 0.8 上支持了Changelog 的生命周期解耦。
这个功能主要想解决的问题是想要在 Paimon 提供长周期流读的能力。当我们以流任务去消费 Paimon 表时,遇到的问题是在以往消费消息队列时,任务出现问题可以回拉重算,但是在 Paimon 表默认只保留1个小时的数据,如果要回答更久的数据,它就需要去调长 Snapshot 保存时长。虽然这可以临时满足业务需求,但在使用过程中发现如果保留太多版本的 Snapshot,会带来存储放大的问题。这中间会有很多自动 Compaction 的过程,并不是表面意义上的保留,它放大的数据量取决于 LSM Tree 数据结构本身的放大效应。
当前解决问题的思路是将 Changelog 和 Snapshot 的生命周期解耦,Snapshot 类似于数据库里的当前快照,Changelog 类似于数据库里的Binlog,在数据库里也可单独配置 Binlog 生命周期。当 Snapshot 过期时,其中的 Data files 就会被清理。如下图,当 Snapshot4 过期时,对应 Delta Manifest 里所指向 Delete 文件就会被自动清理。而其中 Changelog 部分就会被保留,Changelog 的原数据就会被额外的更新在新的 Changelog 元数据中,通过这样达到 Changelog 解耦的目的。对于没有 Changelog,如增量读取的 Delta 文件类型,通过标记文件的来源是 Compaction 还是 Append来判断在是否在 Snapshot 过期的时候要清理这些文件。大致思路就是由 Compaction 生成的文件是可被安全清理的,而 Append 新增的文件只有当对应的 Changelog 元数据过期时候才会被安全清理。Changelog 解耦已经随着 Paimon 0.8 版本发布,欢迎大家试用这个功能。Delta List 解耦的预计要下个版本才能使用。
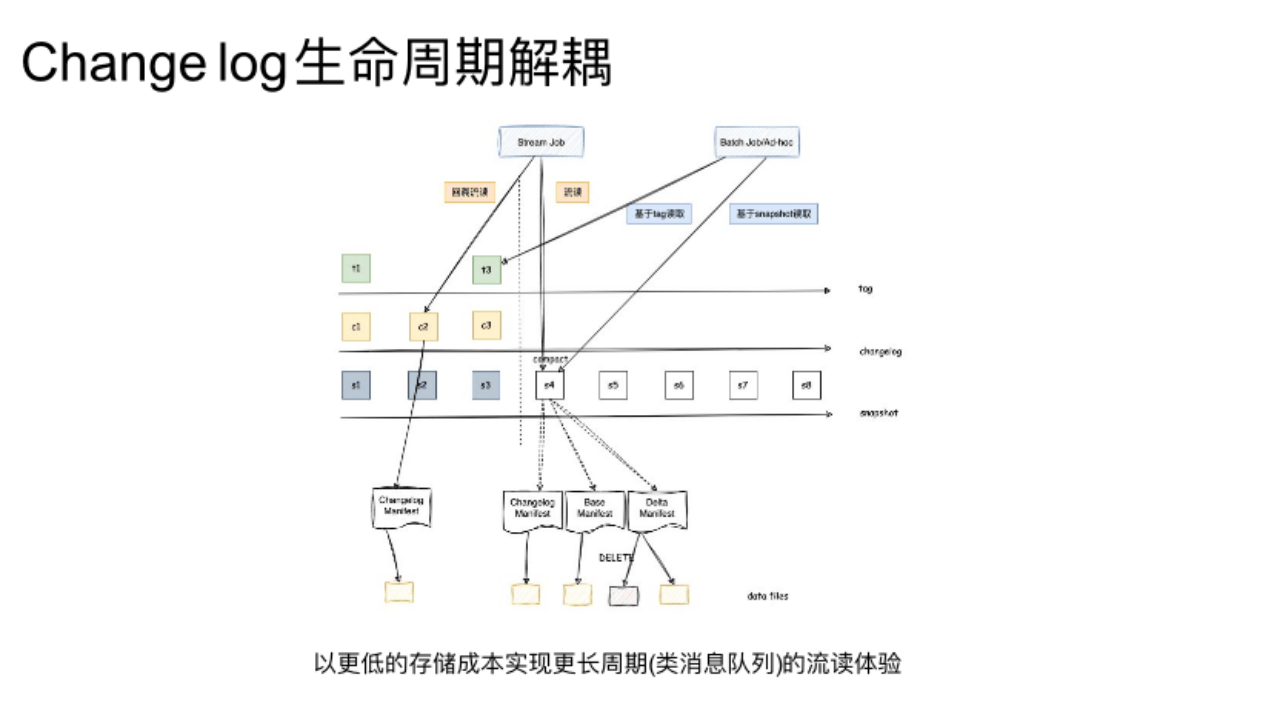
如图是解耦后 Paimon 元数据的大概结构。首先,Snapshot 会记录写入的快照,Tag 可以用于历史回溯、批读,常用于 Tag 定义分区,通过分区去读取某个历史快照的分区数据。同时,Changelog 用于增长流读周期、回溯周期的能力。
四、未来规划
未来规划主要分为四个部分。
包含进一步拓展数据湖的应用场景和规模,主要会包括流读和查询性能的优化,以及和现有的离线生态打通。这样就可以把现有生态结合起来,并且拓宽后续增量的场景。同时增强表管理, 运维, 元数据管理, 自优化服务。