阅读量:1
K近邻算法实现红酒聚类
现在数据集这个就是红酒的分类的数据集红酒每一个都会有很多的属性有三个属性下载数据集,这个是红酒的分类的数据集,红酒每一个都会有很多的属性,有三个属性。这十三个属性就可以用来分辨它是哪一个13个属性就可以用来分辨它是哪一个红酒。  由于这个数据比较简单比较少不需要显卡直接使用cpu进行
由于这个数据比较简单比较少不需要显卡直接使用cpu进行
每一个红酒的数据大概就是这个样子 x_tile = ops.tile(x, (128, 1)) x是原来的tensor,128 是第一维度重复128次,1是表示第二维度只重复一次。
x_tile = ops.tile(x, (128, 1)) x是原来的tensor,128 是第一维度重复128次,1是表示第二维度只重复一次。 原始数据的y取出来可视化,就可以看到很多的分布
原始数据的y取出来可视化,就可以看到很多的分布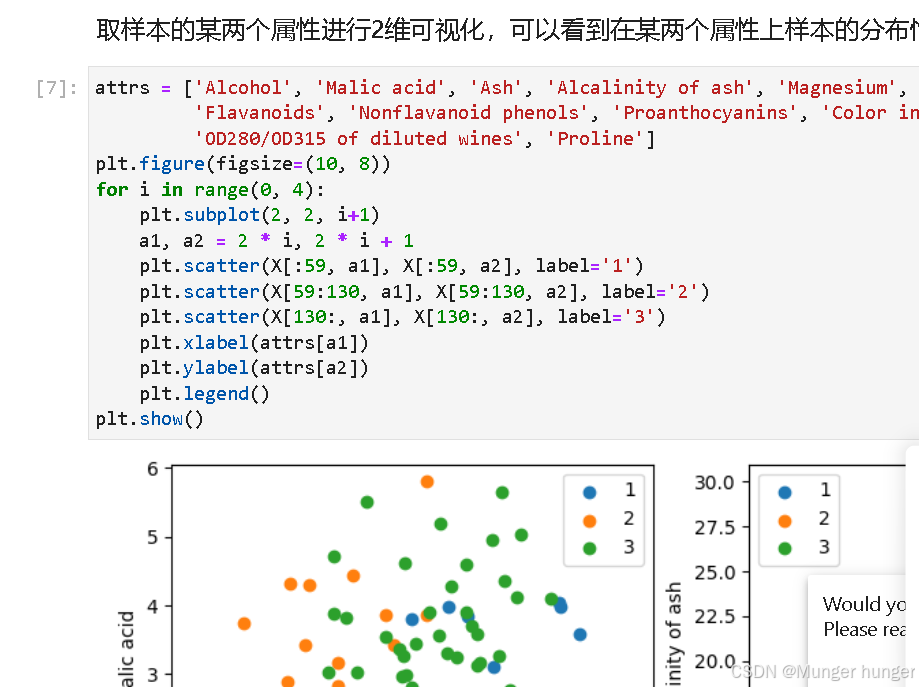 划分下数据集,准备开始物以类聚
划分下数据集,准备开始物以类聚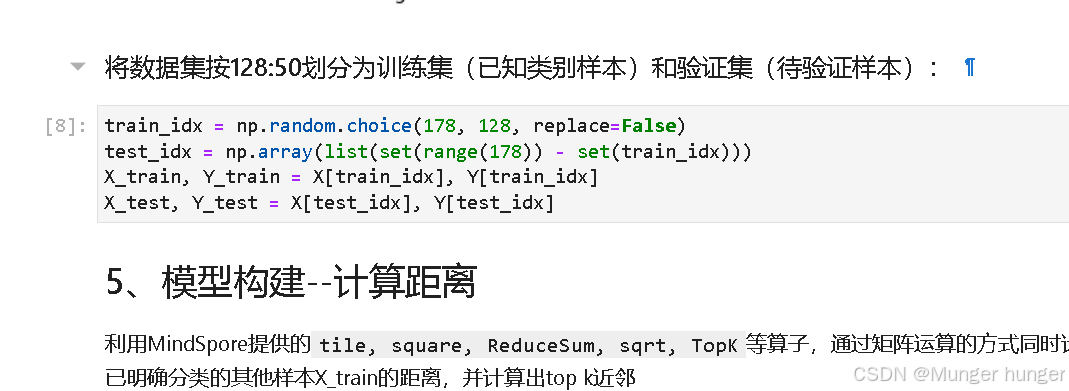
已经知道y,就可以把距离算出来,来使用knn模型。 直接算准确度了。
直接算准确度了。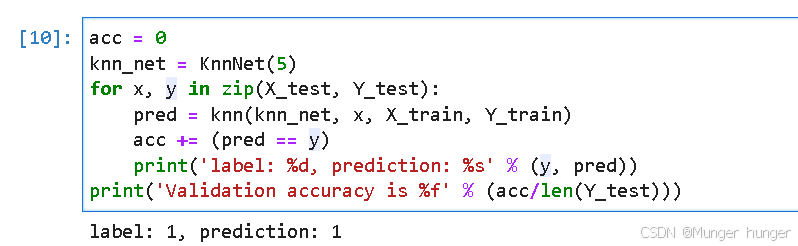
请添加图片描述