
阅读量:2
本次使用kubeadm方式,部署1.23.17版本
安装包百度云盘地址:
链接:https://pan.baidu.com/s/1UrIotP253DoyDIYB7G1C0Q
提取码:8q6a
集群所需虚拟机环境
| 主机名称 | IP | 资源 |
| harbor | 10.0.0.230 | 1c2g |
| master | 10.0.0.231 | 2c4g |
| worker1 | 10.0.0.232 | 2c4g |
| worker2 | 10.0.0.233 | 2c4g |
节点环境准备
1.所有节点hosts解析
cat >> /etc/hosts <<EOF 10.0.0.230 harbor harbor.test.com 10.0.0.231 master 10.0.0.232 worker1 10.0.0.233 worker2 EOF2.harbor节点部署harbor镜像仓库(之前的博客有)
3.每个节点安装docker
yum -y install lrasz 然后将安装包拖进去获取rz -E 上传就好了
· 上传后解压安装
tar xf docker.tar.gz ./install-docker.sh install· 配置内核转发
[root@master ~]# echo 'net.ipv4.ip_forward = 1' >> /etc/sysctl.conf [root@master ~]# sysctl -p net.ipv4.ip_forward = 1· k8s三个节点每个节点配置docker
vim /etc/docker/daemon.json { "registry-mirrors": ["https://tuv7rqqq.mirror.aliyuncs.com"], "insecure-registries": ["harbor.test.com"], "exec-opts": ["native.cgroupdriver=systemd"] } · 解析
"insecure-registries": ["harbor.test.com"], #允许拉取自建仓库harbor仓库的镜像; "exec-opts": ["native.cgroupdriver=systemd"] #kubeadm去寻找的cgroup默认是systemd,而docker不配置的话,默认是cgroupfs,不配置这个,部署k8s时会报错; · 配置完成后重启docker服务
systemctl restart docker4.三个节点关闭swap分区
· 查看swap
[root@master ~]# free -h total used free shared buff/cache available Mem: 3.8G 275M 2.7G 19M 896M 3.3G Swap: 2.0G 0B 2.0G · 关闭swap
[root@master ~]# sed -ni '/^[^#]*swap/s@^@#@p' /etc/fstab5.三个节点配置允许iptables桥接流量
cat > /etc/modules-load.d/k8s.conf << EOF br_netfilter EOF cat > /etc/sysctl.d/k8s.conf << EOF net.bridge.bridge-nf-call-ip6tables=1 net.bridge.bridge-nf-call-iptables=1 net.ipv4.ip_forward=1 EOF sysctl --system 6.关闭防火墙和selinux
· 关闭防火墙和selinux
systemctl stop firewalld systemctl disable firewalld· 关闭selinux
vi /etc/selinux/config 改成:SELINUX=disabledkubeadm方式部署k8s
1.上传解压软件包
tar xf kubeadm-kubelet-kubectl.tar.gz 2.本地化安装
yum -y localinstall kubeadm-kubelet-kubectl/*.rpm3.设置启动及开机自启动k8s
systemctl enable --now kubelet.service4.查看状态(此时启动失败,不用管,因为还没配置完成,配置完之后自动回启动)
systemctl status kubelet.service5.初始化master节点
kubeadm init --kubernetes-version=v1.23.17 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.100.0.0/16 --service-cidr=10.200.0.0/16 --service-dns-domain=test.com 参数解析
--pod-network-cidr=10.100.0.0/16 #pod的网段 --service-cidr=10.200.0.0/16 #service资源的网段 --service-dns-domain=test.com #service集群的dns解析名称 ·如果初始化失败,想要重新初始化
先执行:kubeadm reset -f 在执行: kubeadm init --kubernetes-version=v1.23.17 --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.100.0.0/16 --service-cidr=10.200.0.0/16 --service-dns-domain=test.com ·若k8s 初始化失败
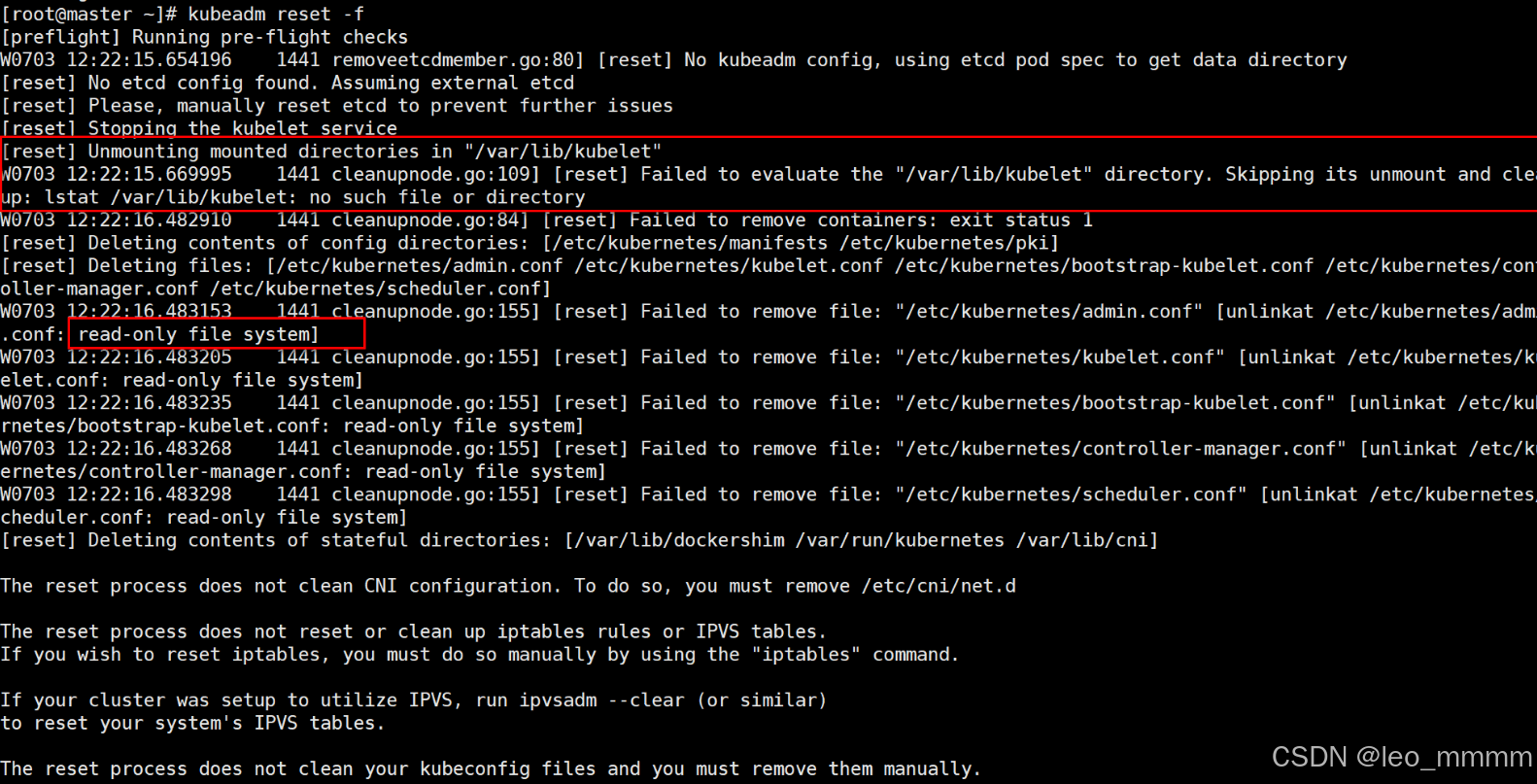
·然后查看docker服务,发现docker启动失败
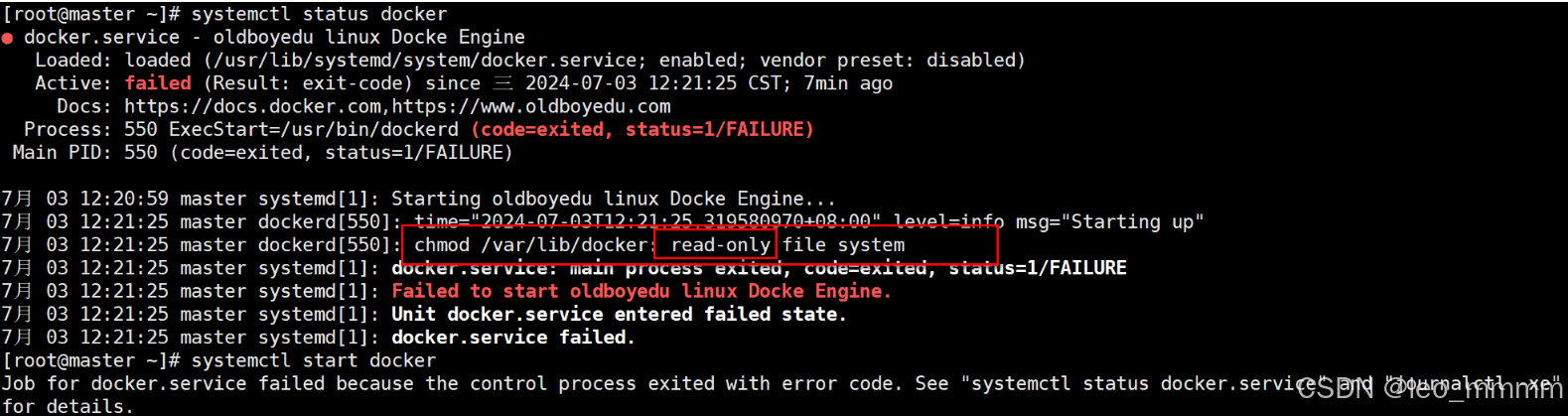
发现硬盘变为只读硬盘
·将只读文件系统变更为可写的
1.查找只读硬盘
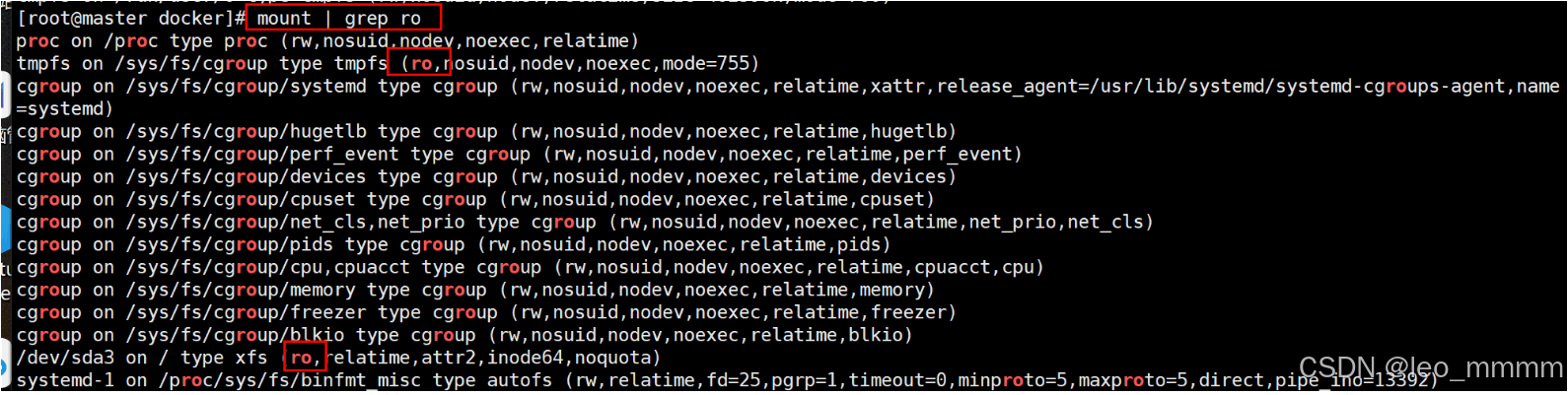
2.将硬盘重新挂载
mount -o remount,rw /sys/fs/cgroup mount -o remount,rw /重新初始化即可
6.初始化成功后按照提示执行
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config7.验证下master节点组件
·查看master组件
[root@master pod]# kubectl get cs Warning: v1 ComponentStatus is deprecated in v1.19+ NAME STATUS MESSAGE ERROR controller-manager Healthy ok scheduler Healthy ok etcd-0 Healthy {"health":"true","reason":""} ·查看集群节点,此时只有一个master节点
[root@master pod]# kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready control-plane,master 31h v1.23.17 8.将worker节点加入到集群中
·在两个worker节点上分别执行执行
kubeadm join 10.0.0.231:6443 --token 0he81g.kbo3vnqqmep9m33p --discovery-token-ca-cert-hash sha256:f865442d8659854db32f692d937c2d8b17e2a07942e8bd7d7bbb8a1d831b3fd1·若是初始化后很长时间没有将worker节点加入到集群中,token会失效,需要重新生成
token失效报错如下:
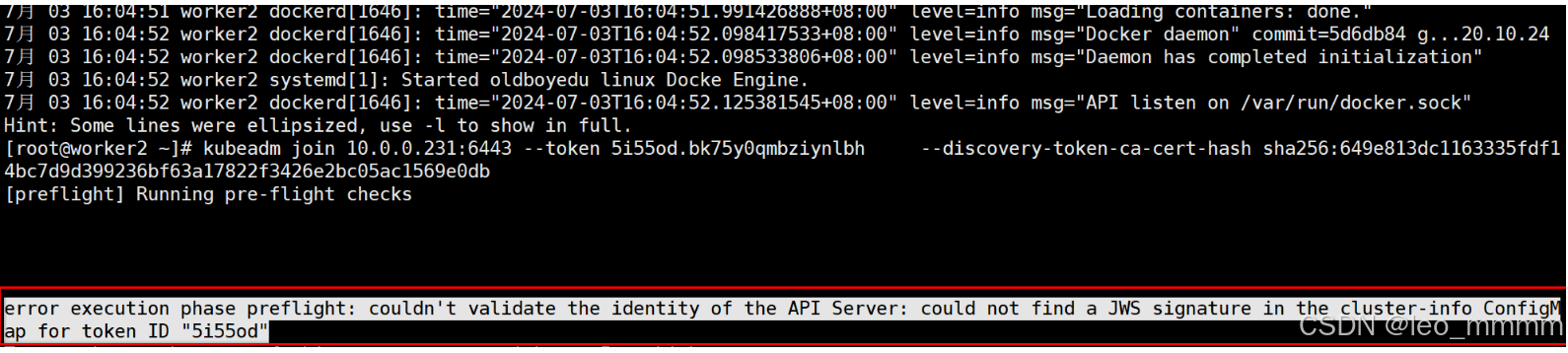
master节点重新生成
kubeadm token create --print-join-command然后在worker节点上分别执行生成的命令即可
9.查看集群状态
·master节点查看
worker节点加入集群后,在master节点上查看,此时发现,状态显示“NotReady,是因为未有CNI网络组件
[root@master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s231 NotReady control-plane,master 13m v1.23.17 k8s232 NotReady <none> 40s v1.23.17 k8s233 NotReady <none> 18s v1.23.17 10.master节点部署网络组件
·上传flannel组件(kube-flannel.yml)
·修改配置文件信息(修改网段信息--net-conf.json)
net-conf.json: | { "Network": "10.100.0.0/16", "Backend": { "Type": "vxlan" } }·部署flannel组件
kubectl apply -f kube-flannel.yml·查看flannel组件是否成功创建pod(每个节点是否都有)
[root@master pod]# kubectl get pods -A -o wide | grep flannel 
问题:镜像拉不下来,imagebackoff
这里,如果未更改配置文件中的镜像下载地址,【running】那里会显示【imagebackoff】,这是因为国内把docker给禁了,无法直接从docker官网拉镜像了,可以先把镜像上传到harbor,将镜像下载地址变更为harbor的就好了(进入文件,输入/,然后输入image,将镜像地址变更为harbor地址)
1.修改flannel配置文件
这里是我自己的配置的地址,这个要根据自己配置的来
image: harbor.test.com/k8s/flannel/flannel:v0.22.2 image: harbor.test.com/k8s/flannel/flannel-cni-plugin:v1.2.0 image: harbor.test.com/k8s/flannel/flannel:v0.22.2配置完成后
2.先删除部署flannel组件
kubectl delete -f kube-flannel.yml3.重新部署
kubectl apply -f kube-flannel.yml4.再次查看节点状态
[root@master pod]# kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready control-plane,master 31h v1.23.17 worker1 Ready <none> 30h v1.23.17 worker2 Ready <none> 30h v1.23.17 至此,k8s集群搭建完毕
