
号称世界上第一个开源实时翻译的 App,微软开源GraphRAG:极大增强大模型问答、摘要、推理,以及开源基于ChatGPT的超级文本代码智能体(附代码地址)
在「端侧」上实现可离线的「实时同传」翻译,支持 29+ 语言的 RTranslator 开源 一天飙升 1700 Star - 号称世界上第一个开源实时翻译的 App
- Onnxruntime 端侧运行,Meta 开源的 SOTA NLLB 跑翻译,Whisper 244M 做 TTS/STT
- 3种模式解决快速、长对话、简单文本翻译
连接到拥有该应用程序的人,连接蓝牙耳机,将手机放入口袋中,然后您就可以像对方说您的语言一样进行对话。
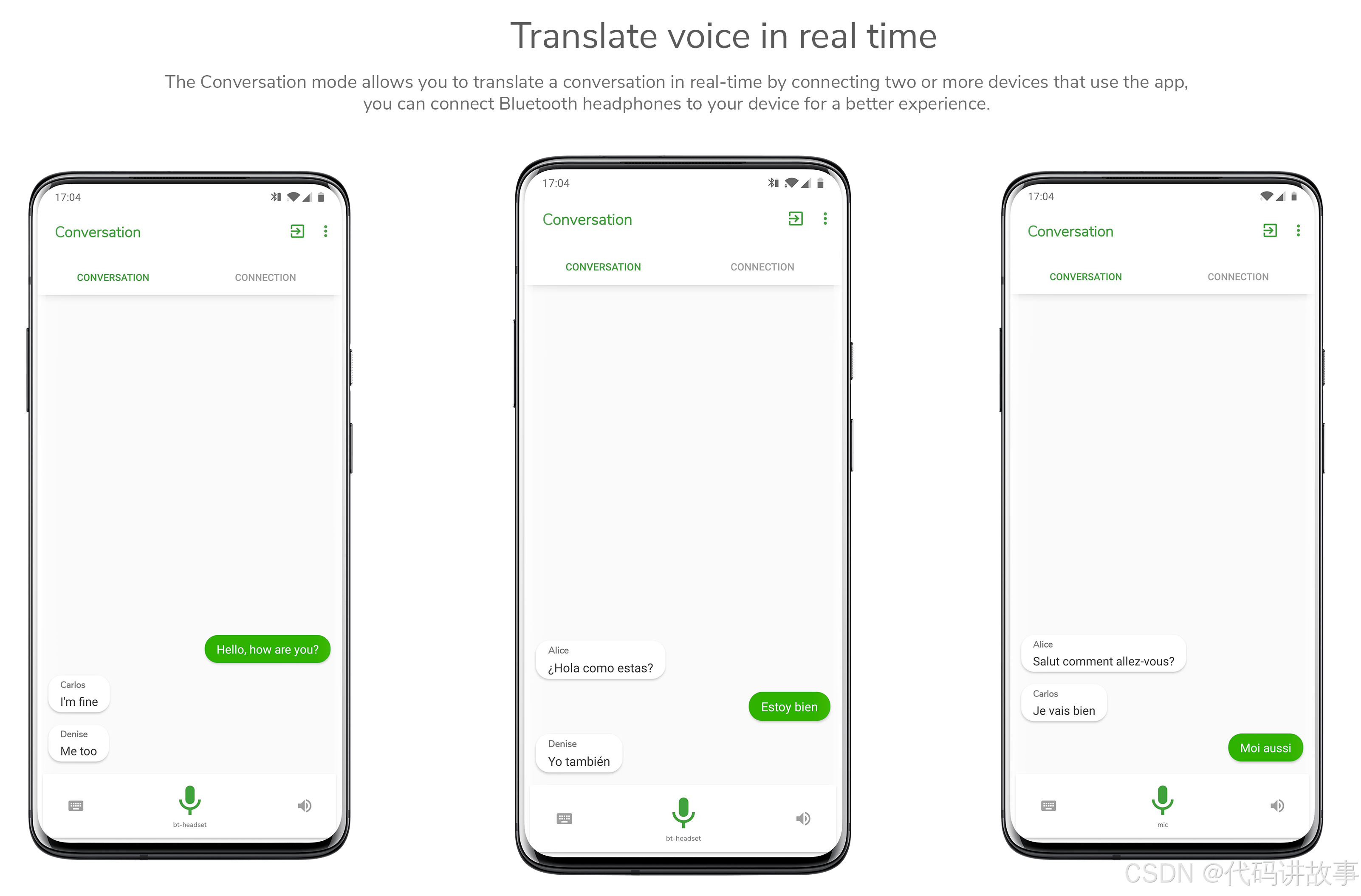
对话模式
对话模式是RTranslator的主要功能。在此模式下,您可以与使用此应用程序的另一部手机连接。如果用户接受您的连接请求:
当您说话时,您的手机(或蓝牙耳机,如果已连接)将捕获音频。
捕获的音频将转换为文本并发送到对话者的手机上。
对话者的手机会将收到的文本翻译成他的语言。
对话者的手机会将翻译后的文本转换为音频,并从扬声器中再现它(或者通过对话者的蓝牙耳机,如果连接到他的手机)。
所有这一切都是双向的。
每个用户可以拥有多个已连接的电话,以便您可以翻译两个以上的人之间以及任意组合的对话。
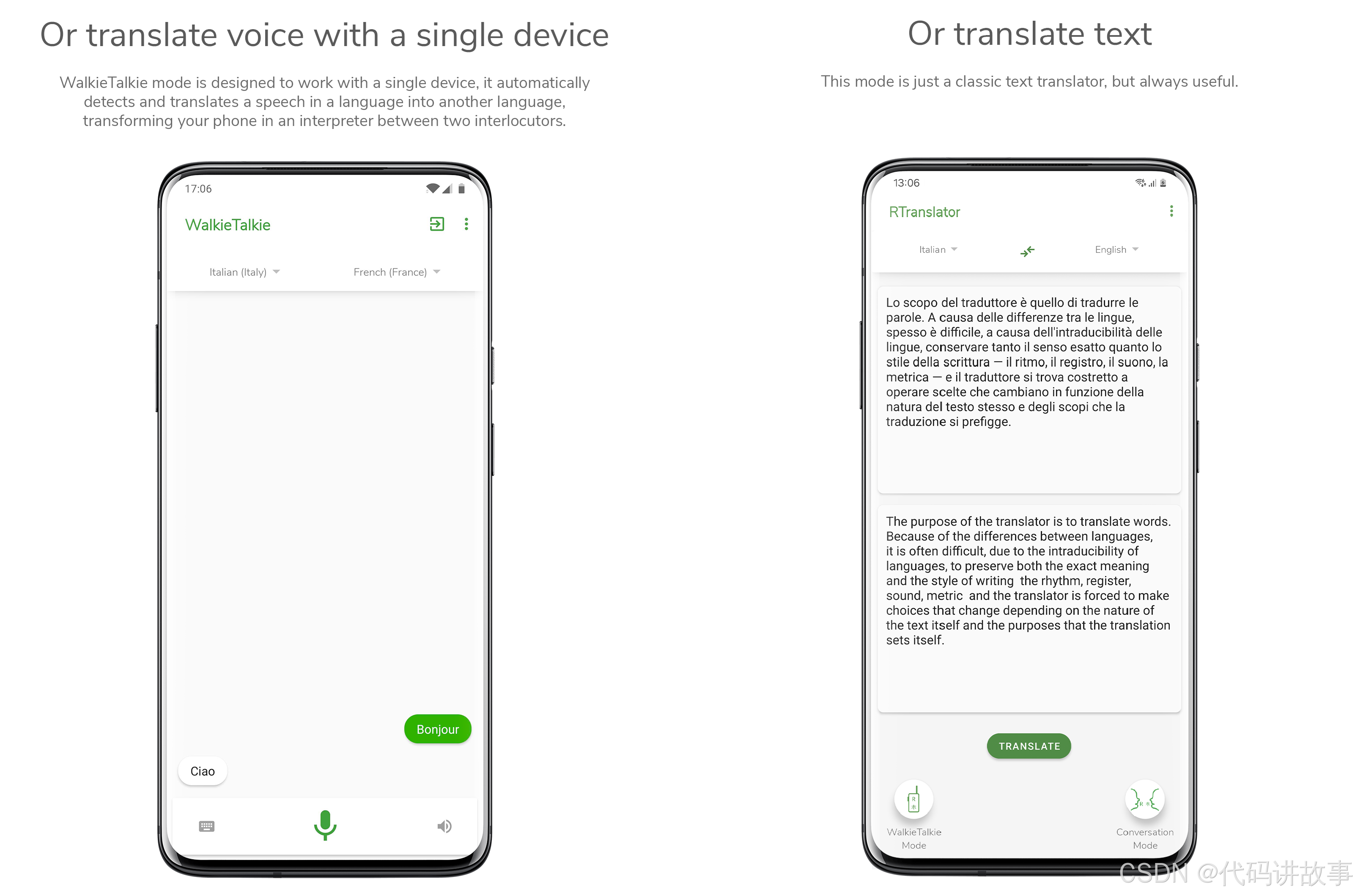
对讲机模式
如果对话模式适用于与某人进行长时间对话,那么该模式则专为快速对话而设计,例如在街上询问信息或与店员交谈。
该模式只能翻译两个人之间的对话,不适用于蓝牙耳机,而且必须轮流说话。这不是真正的同声翻译,但它只能在一部手机上使用。
在此模式下,智能手机麦克风将同时以两种语言收听(可在对讲机模式的同一屏幕中选择)。
该应用程序将检测对话者使用哪种语言,将音频翻译成另一种语言,将文本转换为音频,然后从手机扬声器中再现。TTS 结束后,它将自动恢复收听。
文本翻译模式
这种模式只是一个经典的文本翻译器,但总是有用的。
一般的
RTranslator 使用 Meta 的 NLLB 进行翻译,使用 OpenAi 的 Whisper 进行语音识别,两者都是(几乎)开源且最先进的 AI,具有出色的质量并直接在手机上运行,确保绝对隐私,甚至可以在离线状态下使用 RTranslator。质量损失。
此外,RTranslator 甚至可以在后台运行、手机处于待机状态或使用其他应用程序时(仅当您使用对话或 WalkieTalkie 模式时)。然而,有些手机会限制后台的电量,因此在这种情况下,最好避免它并在屏幕打开的情况下保持应用程序打开。
项目链接
https://github.com/niedev/RTranslator
微软开源GraphRAG:极大增强大模型问答、摘要、推理
微软在官网开源了基于图的RAG(检索增强生成)——GraphRAG。
为了增强大模型的搜索、问答、摘要、推理等能力,RAG已经成为GPT-4、Qwen-2、文心一言、讯飞星火、Gemini等国内外知名大模型标配功能。
传统的RAG系统在处理外部数据源时,只是简单地将文档转换为文本,将其分割为片段,然后嵌入到向量空间中,使得相似的语义对应相近的位置。
但这种方法在处理需要全局理解的海量数据查询时存在局限,因为它过度依赖局部文本片段的检索,无法捕捉到整个数据集的全貌。
所以,微软在RAG基础之上通过“Graph”图的方式,例如,文本中的实体,人物、地点、概念等,构建了超大的知识图谱,帮助大模型更好地捕捉文本中的复杂联系和交互,来增强其生成、检索等能力。
开源地址:https://github.com/microsoft/graphrag?tab=readme-ov-file
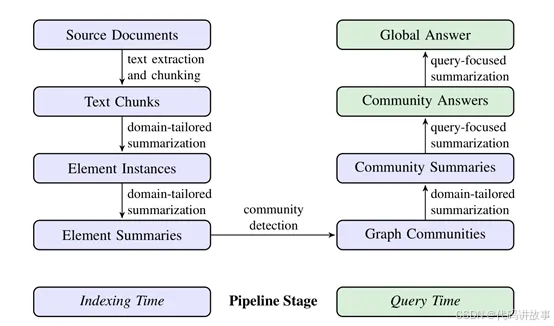
Graph RAG架构简单介绍
Graph RAG的核心是通过两阶段构建基于图谱的文本索引:首先,从源文档中衍生出实体知识图谱;然后,针对所有紧密相关的实体群组预生成社区摘要。
所以,Graph RAG的第一步就是将源文档分割成较小的文本块,这些文本块随后被输入到大模型中以提取关键信息。
在这个过程中,大模型不仅要识别文本中的实体,还要识别实体之间的关系,包括它们之间的相互作用和联系,用来构建一个庞大的实体知识图谱,其中包含了数据集中所有重要实体和它们之间的关系。
简单来说,这个过程就像杀鸡一样,当一整只鸡(数据)拿上来后,我们就要把它分解成腿、翅膀、胸肉等更细小的组成部分,同时会关注这些部位之间的关系方便后续的处理。

接着,Graph RAG使用社区检测算法来识别图谱中的模块化社区。这些社区由相关的节点组成,它们之间的联系比与图中其他部分的联系更为紧密。通过这种方式,整个图谱被划分为更小、更易于管理的单元,每个单元都代表了数据集中的一个特定主题或概念。
在基于图的索引之上,Graph RAG进一步生成社区摘要。这些摘要是对社区内所有实体和关系的总结,它们提供了对数据集中特定部分的高层次理解。
然后要求大模型对每个答案进行打分,分数在0—100之间,得分过低的将被过滤掉,高分则留下。将剩余的中间答案按照得分高低排序,逐步添加至新的上下文窗口中,直至词数限制。
例如,当用户提问“如何进行有效减肥时?”,系统会利用与问题相关的社区摘要来生成部分答案。这些部分答案随后被汇总并精炼,以形成最终答案。
Graph RAG对大模型的好处
与传统RAG相比,Graph RAG的全局检索能力非常强,所以很擅长处理大规模数据集,以下是对大模型的主要帮助。
扩展上下文理解能力:通常大模型受限于其上下文窗口的大小,这限制了它们理解和生成基于长文本的能力。Graph RAG通过构建基于图的索引,将整个文本集合分解成更小、更易于管理的社区模块,从而扩展了模型的理解和生成能力。
增强全局查询:传统的RAG方法在处理全局数据的查询时表现不佳,因为依赖于局部文本片段的检索。Graph RAG通过生成社区摘要,使得模型能够从整个数据集中提取相关信息,生成更加全面和准确的答案。
提高摘要的质量和多样性:Graph RAG方法通过并行生成社区摘要,然后汇总这些摘要来生成最终答案,能帮助大模型从不同的角度和社区中提取信息,从而生成更丰富的摘要。
优化算力、资源利用率:在处理大规模文本数据集时,资源的有效利用至关重要。Graph RAG通过模块化处理,减少了对算力资源的需求。与传统的全文摘要方法相比,Graph RAG在生成高质量摘要的同时,显著降低了对token的需求。
提升信息检索和生成的协同:Graph RAG方法通过结合检索增强和生成任务,实现了两者之间的协同工作,提高了生成内容的准确性和相关性。
增强了对数据集结构的理解:通过构建知识图谱和社区结构,Graph RAG不仅帮助模型理解文本内容,还能理解数据集的内在结构。
提高对复杂问题的处理能力:在处理需要多步骤推理或多文档信息整合的复杂问题时,Graph RAG能够通过检索和摘要不同社区的信息,提升对问题更深层次的理解。尤其是在解读PDF、Word等文档时非常有用。
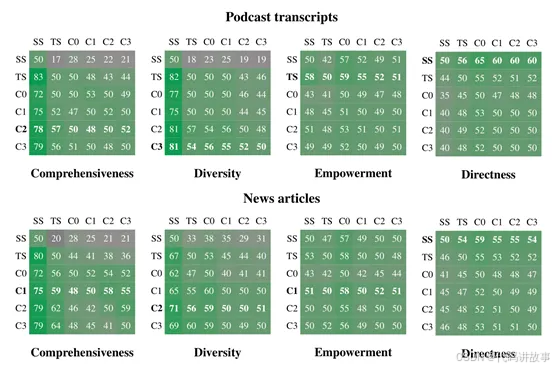
为了评估Graph RAG的性能,微软在一个100万tokens、超复杂结构的数据集上,包含娱乐、播客、商业、体育、技术、医疗等内容,进行了综合测试。

结果显示,全局检索方法在全面性和多样性测试上,超越了Naive RAG等方法。特别是,Graph RAG方法在播客转录和新闻文章数据集上都显示出了超高的水准,多样性也非常全面,是目前最佳的RAG方法之一。
同时Graph RAG对tokens的需求很低,也就是说可以帮助开发者节省大量成本。
微软开源基于ChatGPT的,超级文本代码智能体
随着ChatGPT等生成式AI产品的出现,大语言模型在应用、商业化落地等方面获得了巨大进展。但在处理数据分析时表现不佳,例如,像DataFrame这类复杂的数据格式很难直接用文本的方式表示出来,无法灵活地满足不同用户需求。
为了解决这些难题,微软的研究人员提出了“Code-First”的技术概念,并基于ChatGPT(GPT-3.5以上版本,作者推荐使用GPT-4)开发了超级代码智能体——TaskWeaver。
TaskWeaver可以将用户的自然语言文本请求转化为Python代码在后台运行,并且这些代码可以任意调用功能插件,完成数据读取、分析、模型训练等专业任务。
开源地址:https://github.com/microsoft/TaskWeaver
论文地址:https://arxiv.org/abs/2311.17541

简单来说,通过TaskWeaver一些没有编程能力的人员,也能执行专业的代码任务。例如,我们想做一个数据分析的项目,数据库里存放了一大堆时间序列数据,需要写程序从数据库里把数据取出来,并检查里面有没有异常值。
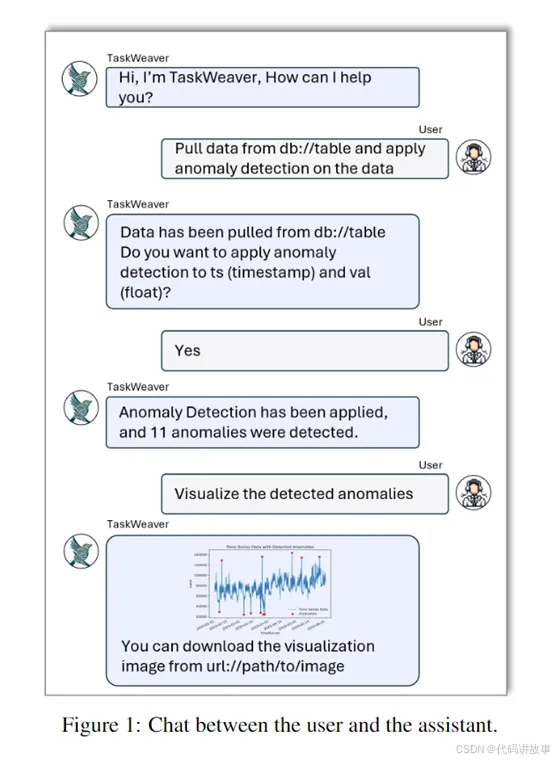
但是根本不会编程,借助TaskWeaver框架只需要向其用文本说明你的意图,智能体就能帮你完成那些繁琐的代码,并生成可视化图表。
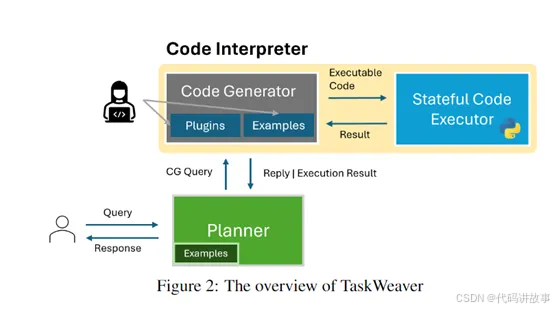
规划器
首先,用户提出数据分析等需求,会被送到TaskWeaver的规划器模块进行拆解。规划器就像一位总指挥,主要为整个任务制定执行计划。
会考量需求的复杂程度,把任务分解为简单直接的子步骤。比如从数据库取数据、画出结果图表等,还会分析步骤间的逻辑关联,标注出执行顺序。主要流程如下:

1)接收用户的文本查询,使用自身知识或增强示例生成初始执行计划,标明必要的子任务步骤。
2)优化初始计划,合并彼此依赖的子任务,减少调用次数,提高效率。最终形成执行计划。
3)遍历计划中的各个子任务,向代码生成器发送询问,获取执行代码。
4)观察代码执行结果,如有需要修改原计划,要求用户提供更多信息等。
5)重复第三和第四步,直到完成全部子任务。最后用自然语言响应用户的查询。
代码生成器
当规划完成后,计划中每个子步骤就会逐一送到代码生成器这里,由其汇报对应执行代码。代码生成器就像一位万能的“程序员”。
根据规划器下达的指令,自动设计出整个代码的执行逻辑并进行编写代码。为了减少重复轮子,还内置了插件、示例、代码校验、自动错误纠正等模块。
同时封装了数据读取、模型训练等常见功能,生成代码时就可以直接调用。
代码执行器
代码编写完成后,会将信息传输到代码执行器模块中。代码执行器主要负责加载代码并执行。插件在这一步也会发挥作用,使外部功能得以连接。执行器会详细记录这个过程的状态,例如变量值、编码日志、中间结果等,以方便进行多轮深度交互。
如果代码在执行过程中出现失败,会将错误信息报告给代码生成器进行自动修正,然后再次自动生成正确的代码。
在代码执行器执行完一轮任务后,会将结果发送给规划器,完成一次子步骤。再由规划器决定触发下一子步骤的执行任务,并重复以上流程。