
省流总结
优点:检索准确度高
缺点:单个19w字构建用时4分30s、gpt4 token花费12美元
概述
7 月 2 日,微软开源了 GraphRAG,一种基于图的检索增强生成 (RAG) 方法,可以对私有或以前未见过的数据集进行问答。在 GitHub 上推出后,该项目快速获得了 2700 颗 star!
开源地址:https://github.com/microsoft/graphrag
通过 LLM 构建知识图谱结合图机器学习,GraphRAG 极大增强 LLM 在处理私有数据时的性能,同时具备连点成线的跨大型数据集的复杂语义问题推理能力。普通 RAG 技术在私有数据,如企业的专有研究、商业文档表现非常差,而 GraphRAG 则基于前置的知识图谱、社区分层和语义总结以及图机器学习技术可以大幅度提供此类场景的性能。
微软在其博客上介绍说,他们在大规模播客以及新闻数据集上进行了测试,在全面性、多样性、赋权性方面,结果显示 GraphRAG 都优于朴素 RAG(70~80% 获胜率)。
与我们传统的 RAG 不同,GraphRAG 方法可以归结为:利用大型语言模型 (LLMs) 从您的来源中提取知识图谱;将此图谱聚类成不同粒度级别的相关实体社区;对于 RAG 操作,遍历所有社区以创建“社区答案”,并进行缩减以创建最终答案。
这个方法用微软高大上的说法是:
微软研究院于 4 月首次宣布推出 GraphRAG ,仅看到论文就让很多人有点等不及上手一试了,如今这项成果终于开源了,开发者们对此表现得超级兴奋:

太棒了,微软开源了 GraphRAG!看完演示视频后,我的脑海里充满了 GraphRAG 带来的各种可能性。我打算在 MacBook 上尝试使用 GraphRAG + Llama3,因为它有 96GB 的统一内存 (VRAM)。我认为这个工具绝对会带来颠覆性的改变。

从看了论文后,我就一直期待着能玩玩它。我曾想过根据论文自己实现它,不过我想官方的代码应该只会晚几周发布,事实证明我的耐心确实得到了回报 😃

我一直在等这一天!知识图谱并不是传统语义搜索的替代品,但它们确实在执行 RAG 操作时解锁了一系列全新能力,例如既可以沿着非常长的上下文向下遍历,又可以以一种连贯、高效的方式跨越不同的上下文进行遍历。
但值得一提的是,所有性能改进技术都有一个缺陷:token 的使用和推理时间都会增加…
解锁 LLM 在私有数据集中的探索能力
大语言模型最大的挑战和机遇或许在于如何将其强大的能力,应用到训练数据以外的问题解决中,利用大语言模型没有见过的数据取得可对比的结果。这将为数据调查开拓新的可能性,例如根据数据集的上下文和 ground 确定其主题和语义概念。
下面我们将具体介绍下微软研究院创建的 GraphRAG,这是增强大语言模型能力的一大进步。
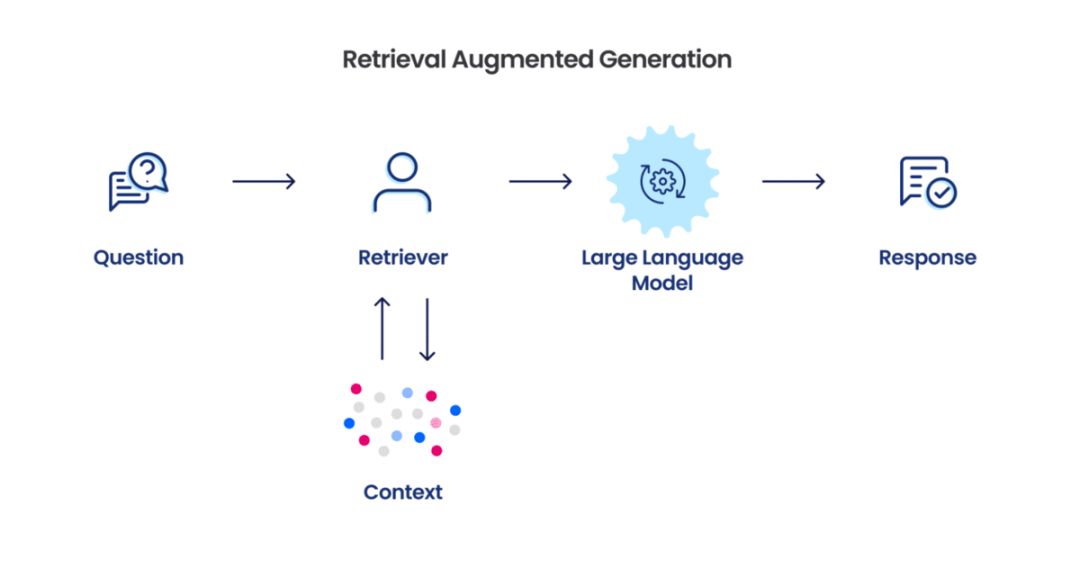
检索增强生成(RAG)是一种根据用户的查询语句搜索信息,并以搜索结果为 AI 参考从而生成回答。这项技术是多数基于 LLM 工具的重要组成部分,而多数的 RAG 都采用向量相似性作为搜索的技术。在文档中复杂信息的分析时,GraphRAG 利用 LLM 生成的知识图谱大幅提升了问答的性能,这一点是建立在近期关于私有数据集中执行发现时提示词增强能力的研究之上。微软将私有数据集定义为未被 LLM 训练使用,且 LLM 从未见过的数据,例如某企业的专有研究、商业文件或通讯。
-
基线 RAG(Baseline RAG)因此而生,但基准 RAG 在某些情况下表现非常差,例如:基线 RAG 很难连点成线。这种情况出现在问题的回答需要通过共用属性遍历不同信息片段以提供新的综合见解时。
-
基线 RAG 在需要全面地理解大型数据集或单一大型文档的语义概念时,表现会很差。
为解决这一问题,业界正在努力开发扩展和增强 RAG 的方法(如 LlamaIndex)。微软研究院的新方法 GraphRAG 便是基于私有数据集创建知识图谱,并将图谱与机器学习一同用于在查询时执行提示词的增强。在回答上述两类问题情况时,GraphRAG 展示了显著的改进,其智能或者说精通的程度远超先前应用私有数据集的其他方法。
应用 RAG 于私有数据集
为证明 GraphRAG 的有效性,GraphRAG 先以新闻文章中暴力事件信息(VIINA)数据集为例,该数据集复杂且存在相左的意见和不完整的信息,是一个现实世界中杂乱的测试示例,又因其出现时间过于近期,所以并未被纳入 LLM 基础模型的训练中。
在这项研究中,微软采用了俄罗斯和乌克兰双方新闻来源在 2023 年 6 月中的上千篇新闻报道,将其翻译为英文后建成了这份将被用于基于 LLM 检索的私有数据集。由于数据集过大无法放入 LLM 上下文的窗口,因此需采用 RAG 方法。
微软团队首先向基线 RAG 系统和 GraphRAG 提出一个探索查询:
查询语句:“Novorossiya 是什么?”

通过结果可以看出,两个系统表现都很好,这是基线 RAG 表现出色的一类查询。然后他们换成了一段需要连点成线的查询:
查询语句:“Novorossiya 做了什么?”

基线 RAG 没能回答这一问题,根据图一中插入上下文窗口的源文件来看,没有任何文本片段提及“Novorossiya”,从而导致了这一失败。

图一:基线 RAG 检索到的上下文
相较之下,GraphRAG 方法发现了查询语句中的实体“Novorossiya”,让 LLM 能以此为基础建立图谱,连接原始支持文本从而生成包含出处的优质答案。举例来说,图二中展示了 LLM 在生成语句时所截取的内容,“Novorossiya 与摧毁自动取款机的计划有所关联。”可以从原始文本的片段(翻译为英文后)中看出,LLM 是通过图谱中两个实体之间的关系,断言 Novorossiya 将某一银行作为目标的。
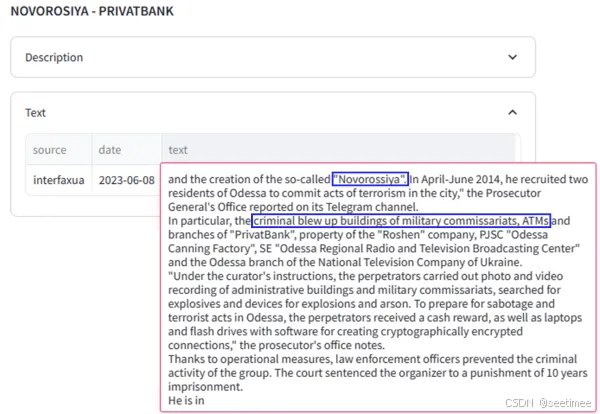
图二:GraphRAG 出处
通过 LLM 生成的知识图谱,GraphRAG 大幅改善了 RAG 的“检索”能力;在上下文窗口中填充相关性更高的内容、捕捉出处论据从而提供更为优质的答案。
信任和验证 LLM 所生成的结果始终是重要的。微软希望结果总是事实性正确、连贯一致,并且能准确地反映原始材料中的内容。GraphRAG 每次生成回答时总会提供出处或源基础信息,表明它的回答时以数据集为基础的。每个论断的引用来源都一目了然,人类用户能够直接对照原始材料,快速且准确地审核 LLM 的输出结果。
不过这还不是 GraphRAG 可以实现的全部功能。
完整数据集推理
基线 RAG 不擅长处理需要汇总全部数据集信息才能得出答案的查询。类似“数据中排行前五的主题是什么?”的查询表现不佳,是因为基线 RAG 依赖对数据集中语义相似文本内容的矢量搜索,而查询语句中却没有任何能引导它找到正确信息的关键词。
但 GraphRAG 却可以回答这类问题。LLM 生成的知识图谱结构给出了数据集的整体结构和其中主题,让私有数据集也能被组织成有意义的语义集群并对其进行预总结。在回应用户查询时,LLM 会使用这些聚类对主题进行总结。
通过下面这条语句,可以展示出两套系统对数据集整体的推理能力:
查询语句:“数据中排行前五的主题有哪些?”

从基线 RAG 的结果来看,列出的主题中没有一个提及两者之间的纷争。正如预期,矢量搜索检索到了无关的文本,并将其插入 LLM 的上下文窗口中。生成的结果很可能是根据关键词“主题”进行搜索,导致了其对数据集内容的评估不够有用。
再看 GraphRAG 的结果,可以清楚看到其生成的结果与数据集整体内容更为吻合。回答中提供了五大主题及其在数据集中观察刀的辅助细节。其中参考的报告是由 LLM 为 GraphRAG 根据每个语义集合预先生成,提供了对原始材料出处的对照。
创建 LLM 生成的知识图谱
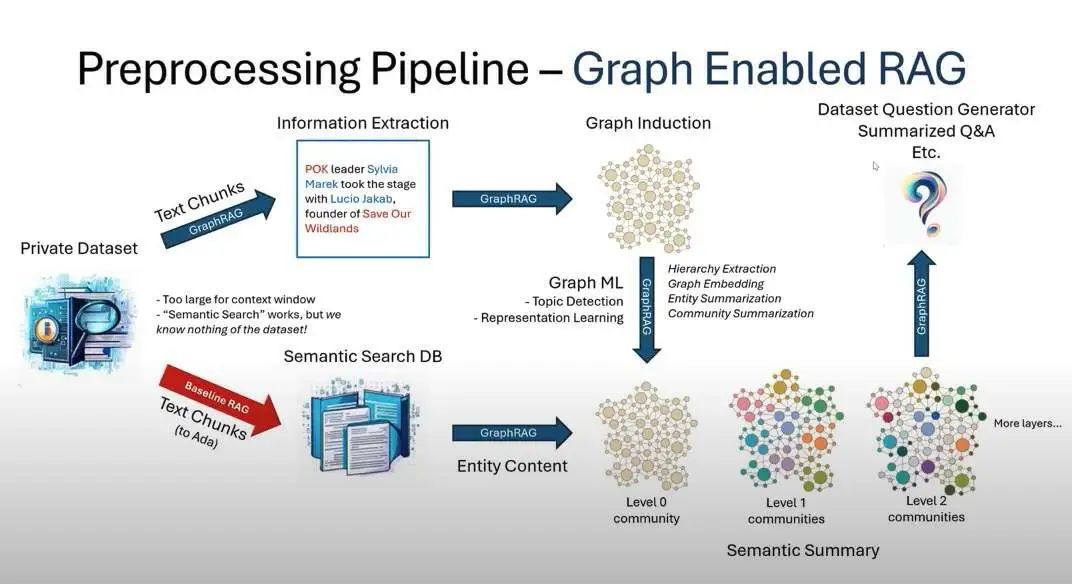
支持 GraphRAG 的基本流程是建立在先前对图机器学习的研究和代码库上的:LLM 处理全部私有数据集,为源数据中所有实体和关系创建引用,并将其用于创建 LLM 生成的知识图谱。利用生成的图谱创建自下而上的聚类,将数据分层并组织成语义聚类(在图三中由颜色标识)。这种划分让预先总结语义概念和主题成为可能,从而更全面地理解数据集。在查询时,两种结构均被用于填充 LLM 回答问题时的上下文窗口。
图三为图谱可视化的示例,每个圆圈都代表一个实体(如人物、地点或组织),圆圈大小代表该实体拥有的关系数量,颜色代表相似实体的分组。颜色分区时建立在图结构基础上的一种从下至上的聚类方法,让 GraphRAG 能回答不同抽象程度的问题。

图三:利用 GPT-4 Turbo 和私有数据集创建 LLM 生成的知识图谱
结果指标
上述示例中表现了 GraphRAG 在多个跨领域数据集上的持续改进。微软采用 LLM 的一个评分器给 GraphRAG 和基线 RAG 的表现进行评估和对比,设定了一系列定性指标,其中包括全面性(问题指向背景框架内的完整性)、人性化(提供辅助原始材料或其他背景信息),以及多样性(提供问题回答的不同角度或观点)。初步结果显示,GraphRAG 在这些指标上始终优于基线 RAG。
除了对比评估,他们还采用 SelfCheckGPT 对 GraphGPT 进行了忠实性的测试,以验证其基于原始材料的真实且连贯的生成结果。结果显示,GraphRAG 达到了与基线 RAG 相似的忠实度水平。
通过将 LLM 生成的知识图谱与图机器学习相结合,GraphRAG 能回答重要的问题类别,而这些问题是无法单独使用基线 RAG 完成的。在将这项技术应用于社交媒体、新闻文章、工作中生产力及化学等场景后,微软已经观察到了可喜的成果,未来他们将继续在各类新领域中应用这项技术。
问题1:先看微软GraphRAG的实际应用意义
昨天我们看过这个工作,GraphRAG是微软的一个项目,旨在通过文本分析生成知识图谱。这个知识模型包括多种实体类型,例如Document、TextUnit、Entity、Relationship、Covariate、Community Report和Node等,它们分别代表输入文档、文本块、提取的实体、实体间的关系、提取的声明信息、社区检测报告以及布局信息等。
,我们可以在:https://microsoft.github.io/graphrag/posts/index/1-default_dataflow/ 中找到一些认知,其给出了整个的详细细节,我们来看看。
其意义到底是什么,其实也有讲。

一句话说就是,就是chunk之间的关联,他能搞,怎么搞,通过图谱来搞。另一个是能够做多文档摘要,怎么搞,通过层次化摘要搞。
应用包括两个:
1、Global Search全局搜索
**Global Search:for reasoning about holistic questions about the corpus by leveraging the community summaries.**:https://microsoft.github.io/graphrag/posts/query/0-global_search/
全局搜索:通过利用社区摘要,对整个语料库进行整体问题的推理,利用大型语言模型(LLM)生成的知识图谱来组织和聚合信息,以回答需要跨数据集聚合信息的查询。
传统的RAG(Retrieval-Augmented Generation)模型在处理需要跨数据集聚合信息的查询时表现不佳,例如“数据中的前5个主题是什么?”这类问题。这是因为传统RAG模型依赖于向量搜索来找到语义上相似的文本内容,而没有明确的查询来指导它找到正确的信息。
GraphRAG可以回答这类问题,因为由LLM生成的知识图谱的结构告诉我们整个数据集的结构(以及主题)。这允许私有数据集被组织成有意义的语义集群,这些集群是预先总结过的。
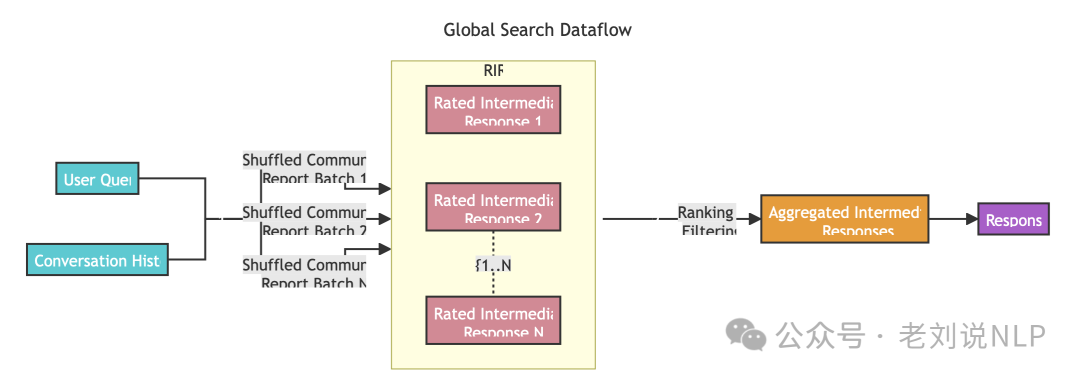
在具体实现上,Global Search方法使用LLM生成的社区报告集合作为上下文数据,以map-reduce方式生成响应。在map步骤中,社区报告被分割成预定义大小的文本块。每个文本块用于生成包含点列表的中间响应,每个点都有相应的数值评分,表示该点的重要性。在reduce步骤中,从中间响应中筛选出最重要的点,并将它们聚合起来,作为生成最终响应的上下文。
2、Local Search局部搜索
Local Search: for reasoning about specific entities by fanning-out to their neighbors and associated concepts. 通过扩展到特定实体的邻居和相关概念,对特定实体进行推理。**:https://microsoft.github.io/graphrag/posts/query/1-local_search/
这种场景旨在通过结合知识图谱中的结构化数据和输入文档中的非结构化数据,增强大型语言模型(LLM)在查询时的上下文,从而更好地回答涉及输入文档中特定实体的问题。
换句话说,就是用的图谱数据跟非结构化文本进行的增强,做的基于实体的推理,利用知识图谱中的结构化数据和输入文档中的非结构化数据,以在查询时为LLM提供与查询相关的实体信息。
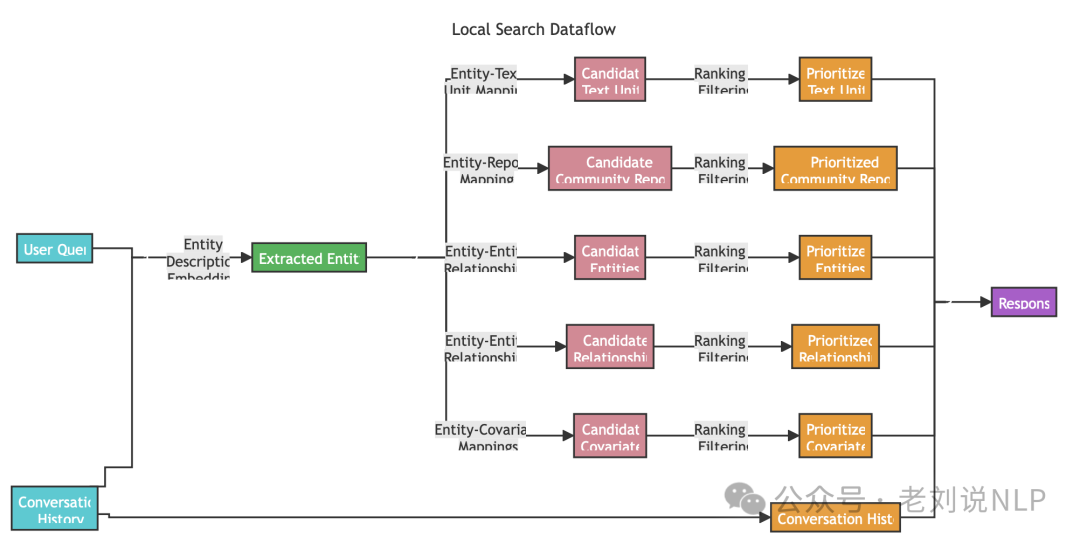
在具体实现上,其首先识别与用户输入语义相关的知识图谱中的实体集合。这些实体作为访问知识图谱的入口,可以提取更多相关信息,如相关实体、关系、实体协变量和社区报告。
此外,还从原始输入文档中提取与已识别实体相关联的相关文本块。然后,这些候选数据源将被优先排序和过滤,以适应预定义大小的单个上下文窗口,用于生成对用户查询的响应。
问题2:再看GraphRAG的具体索引执行思路
整个部分其实包括index索引部分以及搜索query两个部分,我们先看怎么建索引,搜索部分就是第一部分,这里不讲了。
有几个点可以关注:
1、GraphRAG Knowledge Model文档指示模型
GraphRAG的核心就是两个图,一个是文档图谱,一个是文档内部的实体关系图谱。
文档(Document)表示系统输入的文档。这些可以代表CSV中的单独行或单独的.txt文件;
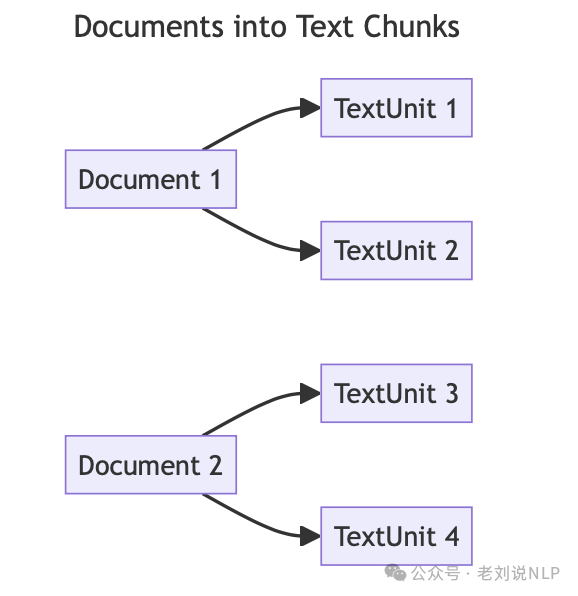
文本单元(TextUnit)表示待分析的文本块。这些块的大小、重叠以及是否遵守任何数据边界可以进行配置。一种常见的用例是将CHUNK_BY_COLUMNS设置为id,以便文档和文本单元之间存在1对多的关系,而不是多对多。
实体(Entity)表示从文本单元中提取的实体。这些代表人、地点、事件或您提供的其他实体模型;
关系(Relationship)表示两个实体之间的关系;
协变量(Covariate)表示提取的声明信息,其中包含可能有时间限制的关于实体的陈述;
社区报告(Community Report)表示一旦生成实体,会对它们执行层次化的社区检测,并为这个层次结构中的每个社区生成报告;
节点(Node):包含已嵌入和聚类的实体和文档的渲染图视图的布局信息。
2、具体执行过程
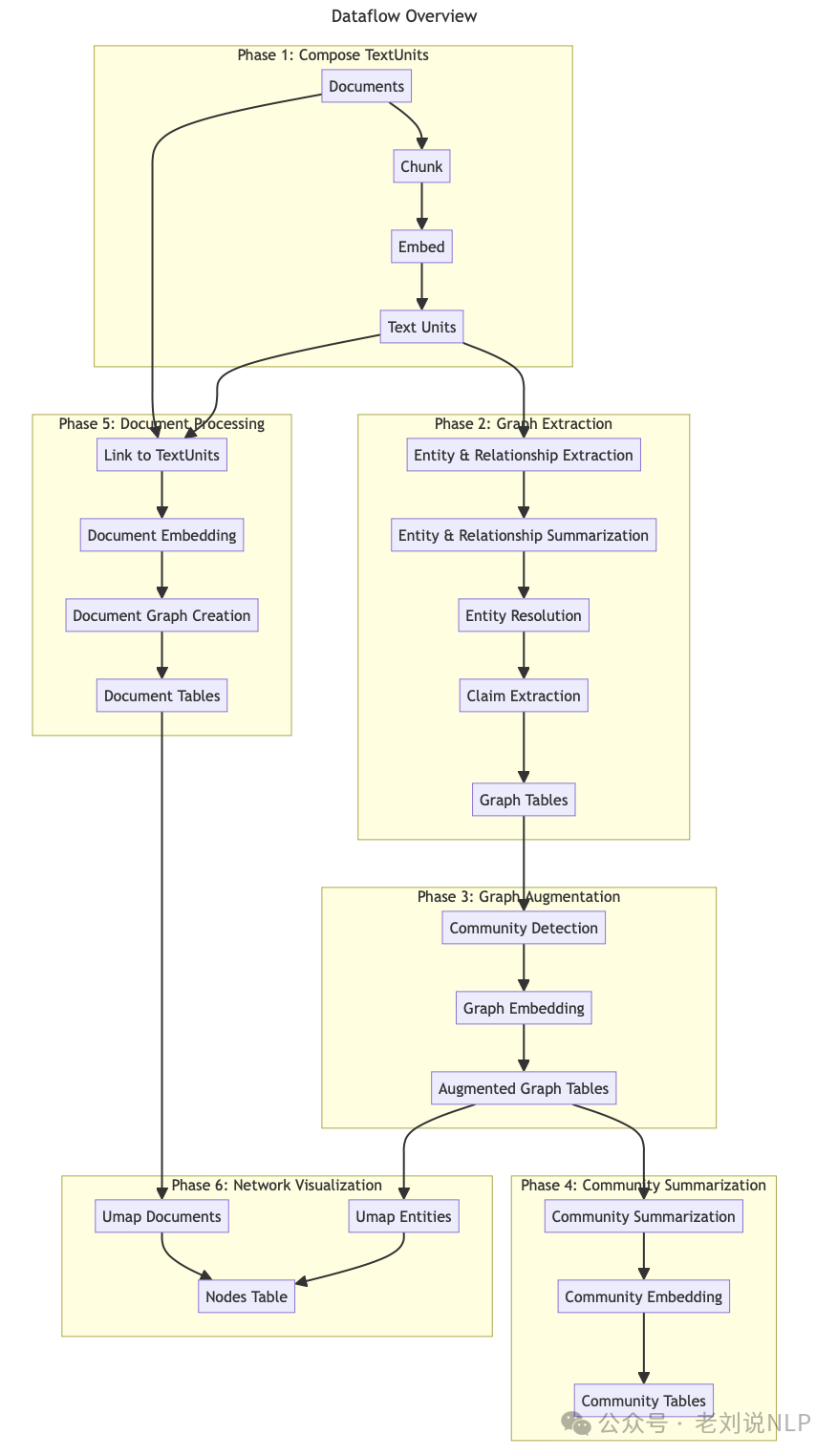
在默认配置工作流程中,文本文档被转换为GraphRAG知识模型,这个过程包括以下几个主要阶段:
1)文本单元切分(Compose TextUnits):输入文档被转换为文本单元,这些文本单元用于图提取技术,并作为提取知识项的源引用。
2)图谱抽取(Graph Extraction):分析每个文本单元,提取实体、关系和声明
图谱提取阶段包括多个步骤,包括Entity & Relationship Extraction(其实就是让大模型进行实体和关系提取,用prompt)、Entity & Relationship Summarization、Entity Resolution (实体消歧,这个是图谱构建的一个重头戏)、Claim Extraction & Emission
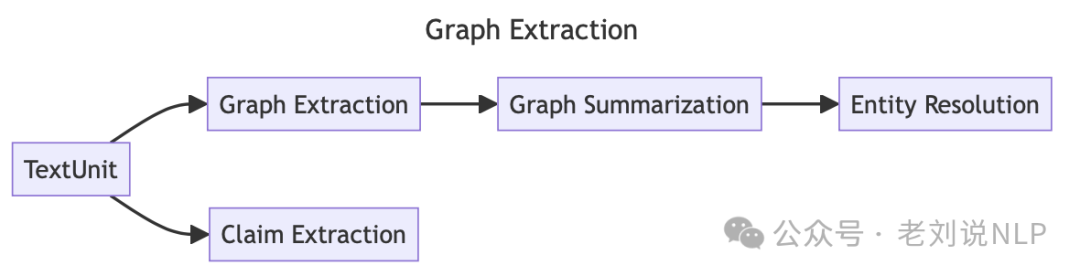
其中,实体和关系总结(Entity & Relationship Summarization)将实体及关系这些列表总结成一个实体和关系的单一描述,通过要求LLM提供一个简短的总结来完成,从而实现所有的实体和关系都有一个简洁的单一描述。
3)图增强(Graph Augmentation):理解实体的社区结构,并通过社区检测和图嵌入来增强图谱。
在有了一个可用的实体和关系图之后,希望理解它们的社区结构,并用额外的信息增强这张图,通过两个步骤来完成:社区检测和图嵌入。这些步骤提供了明确(社区)和隐含(嵌入)的方式来理解我们图的拓扑结构。
其中,
社区检测这一步,使用层次化的Leiden算法生成实体社区的层次结构,对上一步构建好的图应用递归的社区聚类,直到我们达到社区大小的阈值,可以提供一种在不同粒度级别上导航和总结图的方法。
这个好处在于,使用Node2Vec算法可以生成向量表示,可以在查询阶段提供一个额外的向量空间,用于搜索相关概念。

到此为止,就拥有了一个功能性的实体和关系图,实体的社区层次结构,以及node2vec嵌入。
4)社区摘要(Community Summarization):生成每个社区的报告,提供对图的高层次理解。

那么,接下来,可以对社区进行索引。即在社区数据的基础上进一步构建,并为每个社区生成报告。这为在图的不同粒度级别上提供了对图的高层次理解。例如,如果社区A是最高层级的社区,我们将得到一个关于整个图的报告。如果社区是低层级的,将得到一个关于本地集群的报告。
首先,生成社区报告,在这一步中,使用LLM为每个社区生成摘要,报告包含执行概览,并引用社区子结构中的关键实体、关系和声明。
其次,总结社区报告,每个社区报告随后通过LLM进行总结,以供简写使用。
最后,社区嵌入,通过生成社区报告、社区报告摘要和社区报告标题的文本嵌入来生成社区的向量表示。
5)文档处理(Document Processing):对文档进行表示,并形成文档图
这一块的目的是对文档进行表征。包括以下几个步骤:

首先是链接到文本单元,将每个文档与第一阶段创建的文本单元关联起来,能够理解哪些文档与哪些文本单元相关。
其次是文档嵌入,使用文档切片的平均嵌入来生成文档的向量表示。 具体地,重新分块文档,不重叠块,然后为每个块生成嵌入,创建这些块的加权平均值,按token计数加权,并将其用作文档嵌入,然后基于这种文档表示,能够理解文档之间的隐含关系,并帮助生成文档的网络表示。
6)网络可视化(Network Visualization):支持在现有图中对高维向量空间进行网络可视化。
这个一步,我理解是做的可解释性。在工作流程的这个阶段,执行一些步骤来支持我们现有图中高维向量空间的网络可视化。

此时有两个逻辑图在起作用:实体-关系图和文档图。对于每个逻辑图,执行UMAP降维以生成图的2D表示,这样以来,可以通过2D空间中可视化图,并理解图中节点之间的关系。
快速部署
安装 GraphRAG
要求python=3.10
pip install graphrag mkdir -p ./ragtest/input #下载例子,也可以将你自己的txt文件放在./ragtest/input目录下 curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt > ./ragtest/input/book.txt #初始化配置 python -m graphrag.index --init --root ./ragtest 初始化配置将在目录中创建两个文件:.env和。settings.yaml``./ragtest
.env包含运行 GraphRAG 管道所需的环境变量。如果检查文件,您将看到已定义的单个环境变量。GRAPHRAG_API_KEY=<API_KEY>这是 OpenAI API 或 Azure OpenAI 端点的 API 密钥。您可以将其替换为您自己的 API 密钥。settings.yaml包含管道的设置。您可以修改此文件以更改管道的设置。
OpenAI 和 Azure OpenAI
要在 OpenAI 模式下运行,只需确保使用 OpenAI API 密钥更新文件GRAPHRAG_API_KEY中的值。.env
Azure OpenAI
此外,Azure OpenAI 用户应在 settings.yaml 文件中设置以下变量。要找到适当的部分,只需搜索配置llm:,您应该会看到两个部分,一个用于聊天端点,一个用于嵌入端点。以下是如何配置聊天端点的示例:
<span class="token key atrule">type</span><span class="token punctuation">:</span> azure_openai_chat <span class="token comment"># Or azure_openai_embedding for embeddings</span> <span class="token key atrule">api_base</span><span class="token punctuation">:</span> https<span class="token punctuation">:</span>//<instance<span class="token punctuation">></span>.openai.azure.com <span class="token key atrule">api_version</span><span class="token punctuation">:</span> 2024<span class="token punctuation">-</span>02<span class="token punctuation">-</span>15<span class="token punctuation">-</span>preview <span class="token comment"># You can customize this for other versions</span> <span class="token key atrule">deployment_name</span><span class="token punctuation">:</span> <azure_model_deployment_name<span class="token punctuation">></span> 运行索引管道
最后我们将运行管道!
python <span class="token parameter variable">-m</span> graphrag.index <span class="token parameter variable">--root</span> ./ragtest 
此过程需要一些时间才能运行。这取决于输入数据的大小、使用的模型以及使用的文本块大小(这些可以在文件中配置.env)。管道完成后,您应该会看到一个名为的新文件夹,./ragtest/output/<timestamp>/artifacts其中包含一系列 parquet 文件。
使用查询引擎
全局搜索示例:
python -m graphrag.query \ --root ./ragtest \ --method global \ "What are the top themes in this story?" 本地搜索示例:
python -m graphrag.query \ --root ./ragtest \ --method local \ "Who is Scrooge, and what are his main relationships?" 总结
本文主要介绍了两个问题。一个是再看微软提出的GraphRAG的执行原理,来看看其具体执行步骤,其核心就是,围绕全局搜索跟局部搜索两个应用场景做的优化,但其中毛病很明显,就是其中的实体识别、实体关系抽取、社区聚类等都存在误差传播,并且为了做这种图谱需要花费很大精力,也不一定会奏效。
但其通过文档内部,文档外部做图谱的思路,以及基于此做的嵌入作为补充也是十分好的一点思路,感兴趣的可以尝试。
但是,最后的最后,RAG的花式策略十分多,但这个实际上是与业务强关联的,面向业务问题做RAG优化才有意义,空套一些新方法,没意义。
供大家一起参考并思考。
参考文献
1、https://arxiv.org/pdf/2404.16130
2、https://microsoft.github.io/graphrag/posts/index/1-default_dataflow/