
阅读量:1
一、数据倾斜
什么是数据倾斜?
学过Redis集群的都知道数据倾斜这个问题。
就是大量数据,分配不均匀的现象。
二、MR数据倾斜
1、怎么判断出现数据倾斜?
数据频率倾斜——某一个区域的数据量要远远大于其他区域。
数据大小倾斜——部分记录的大小远远大于平均值。
如下图的一个案例:
所有进程都已经完成,MR程序完成度达到99%,只剩下2个Reduce程序还在运行。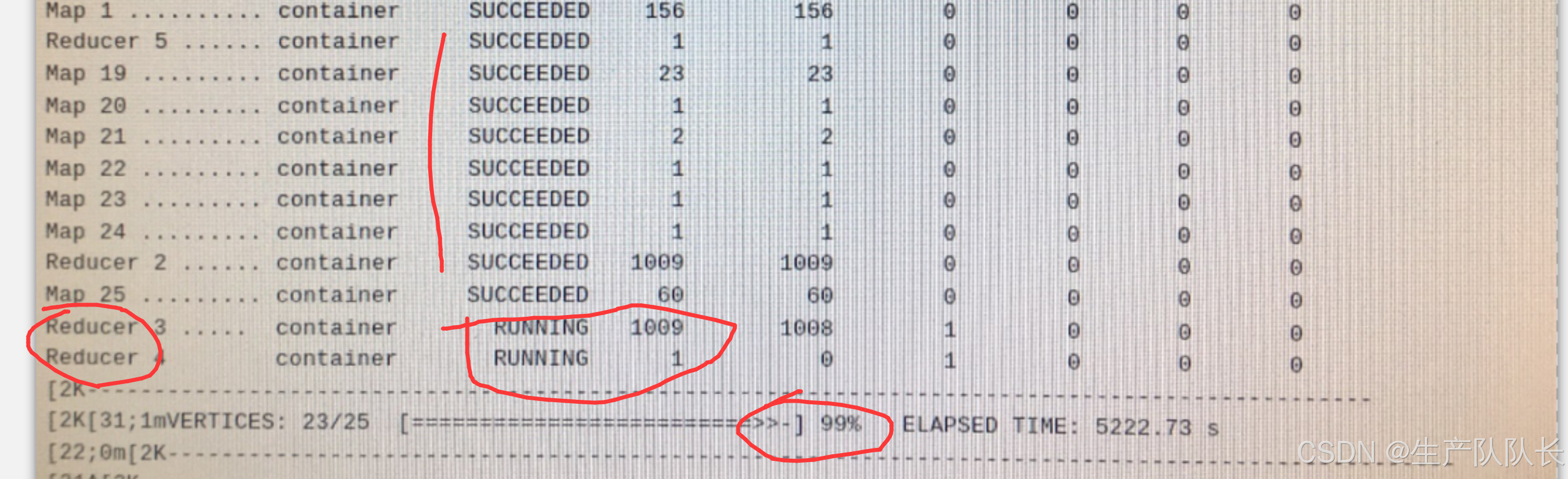
2、解决办法
1、首先检查是否是空值过多造成的数据倾斜
生产环境,可以直接过滤掉空值;如果想保留空值,就自定义分区,将空值加随机数打散。最后再二次聚合。
2、能在map阶段提前处理,最好先在Map阶段处理。如:Combiner、MapJoin
3、设置多个reduce个数。
