
阅读量:1
一 前言
上一篇介绍了通过AF-PACKET的V1 版本进行网络包的捕获,比较新的Linux内核是支持V3版本的,相对于前两个版本(V2和V1比较相似,V2版本的时间精度从微秒提升到纳秒。)V3版本,具有以下的提升:
CPU使用率降低约15-20%
数据包捕获率提高约20%
数据包的密度提升2倍(不知道什么意思, 如 ~2x increase in packet density)
端口聚合分析
非静态数据帧大小,可以保存整个数据包。
所以这次就学习V3版本的用法,和其他能提示AF-PACKET抓包性能的均衡策略和方法。
二 V3版本的实战
V3的版本结构每次遍历和以前的不同是按照block遍历,当然下一层再按照frame遍历。
V3的时间戳精确度到纳秒。
struct tpacket_req3 { unsigned int tp_block_size; // 每个连续内存块的最小尺寸(必须是 PAGE_SIZE * 2^n ) unsigned int tp_block_nr; // 内存块数量 unsigned int tp_frame_size; // 每个帧的大小(虽然V3中的帧长是可变的,但创建时还是会传入一个最大的允许值) unsigned int tp_frame_nr; // 帧的总个数(必须等于 每个内存块中的帧数量*内存块数量) unsigned int tp_retire_blk_tov; // 内存块的寿命(ms),超时后即使内存块没有被数据填入也会被内核停用,0意味着不设超时 unsigned int tp_sizeof_priv; // 每个内存块中私有空间大小,0意味着不设私有空间 unsigned int tp_feature_req_word;// 标志位集合(目前就支持1个标志 TP_FT_REQ_FILL_RXHASH) } // TPACKET_V3环形缓冲区每个帧的头部结构 struct tpacket3_hdr { __u32 tp_next_offset; // 指向同一个内存块中的下一个帧 __u32 tp_sec; // 时间戳(s) __u32 tp_nsec; // 时间戳(ns) __u32 tp_snaplen; // 捕获到的帧实际长度 __u32 tp_len; // 帧的理论长度 __u32 tp_status; // 帧的状态 __u16 tp_mac; // 以太网MAC字段距离帧头的偏移量 __u16 tp_net; union { struct tpacket_hdr_variant1 hv1; // 包含vlan信息的子结构 }; __u8 tp_padding[8]; }下面是内核文档中的收包例子,代码如下:
/* Written from scratch, but kernel-to-user space API usage * dissected from lolpcap: * Copyright 2011, Chetan Loke <loke.chetan@gmail.com> * License: GPL, version 2.0 */ #include <stdio.h> #include <stdlib.h> #include <stdint.h> #include <string.h> #include <assert.h> #include <net/if.h> #include <arpa/inet.h> #include <netdb.h> #include <poll.h> #include <unistd.h> #include <signal.h> #include <inttypes.h> #include <sys/socket.h> #include <sys/mman.h> #include <linux/if_packet.h> #include <linux/if_ether.h> #include <linux/ip.h> #ifndef likely # define likely(x) __builtin_expect(!!(x), 1) #endif #ifndef unlikely # define unlikely(x) __builtin_expect(!!(x), 0) #endif struct block_desc { uint32_t version; uint32_t offset_to_priv; struct tpacket_hdr_v1 h1; }; struct ring { struct iovec *rd; uint8_t *map; struct tpacket_req3 req; }; static unsigned long packets_total = 0, bytes_total = 0; static sig_atomic_t sigint = 0; static void sighandler(int num) { sigint = 1; } static int setup_socket(struct ring *ring, char *netdev) { int err, i, fd, v = TPACKET_V3; struct sockaddr_ll ll; unsigned int blocksiz = 1 << 22, framesiz = 1 << 11; unsigned int blocknum = 64; fd = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL)); if (fd < 0) { perror("socket"); exit(1); } err = setsockopt(fd, SOL_PACKET, PACKET_VERSION, &v, sizeof(v)); if (err < 0) { perror("setsockopt"); exit(1); } memset(&ring->req, 0, sizeof(ring->req)); ring->req.tp_block_size = blocksiz; ring->req.tp_frame_size = framesiz; ring->req.tp_block_nr = blocknum; ring->req.tp_frame_nr = (blocksiz * blocknum) / framesiz; ring->req.tp_retire_blk_tov = 60; ring->req.tp_feature_req_word = TP_FT_REQ_FILL_RXHASH; err = setsockopt(fd, SOL_PACKET, PACKET_RX_RING, &ring->req, sizeof(ring->req)); if (err < 0) { perror("setsockopt"); exit(1); } ring->map = mmap(NULL, ring->req.tp_block_size * ring->req.tp_block_nr, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_LOCKED, fd, 0); if (ring->map == MAP_FAILED) { perror("mmap"); exit(1); } ring->rd = malloc(ring->req.tp_block_nr * sizeof(*ring->rd)); assert(ring->rd); for (i = 0; i < ring->req.tp_block_nr; ++i) { ring->rd[i].iov_base = ring->map + (i * ring->req.tp_block_size); ring->rd[i].iov_len = ring->req.tp_block_size; } memset(&ll, 0, sizeof(ll)); ll.sll_family = PF_PACKET; ll.sll_protocol = htons(ETH_P_ALL); ll.sll_ifindex = if_nametoindex(netdev); ll.sll_hatype = 0; ll.sll_pkttype = 0; ll.sll_halen = 0; err = bind(fd, (struct sockaddr *) &ll, sizeof(ll)); if (err < 0) { perror("bind"); exit(1); } return fd; } static void display(struct tpacket3_hdr *ppd) { struct ethhdr *eth = (struct ethhdr *) ((uint8_t *) ppd + ppd->tp_mac); struct iphdr *ip = (struct iphdr *) ((uint8_t *) eth + ETH_HLEN); if (eth->h_proto == htons(ETH_P_IP)) { struct sockaddr_in ss, sd; char sbuff[NI_MAXHOST], dbuff[NI_MAXHOST]; memset(&ss, 0, sizeof(ss)); ss.sin_family = PF_INET; ss.sin_addr.s_addr = ip->saddr; getnameinfo((struct sockaddr *) &ss, sizeof(ss), sbuff, sizeof(sbuff), NULL, 0, NI_NUMERICHOST); memset(&sd, 0, sizeof(sd)); sd.sin_family = PF_INET; sd.sin_addr.s_addr = ip->daddr; getnameinfo((struct sockaddr *) &sd, sizeof(sd), dbuff, sizeof(dbuff), NULL, 0, NI_NUMERICHOST); printf("%s -> %s, ", sbuff, dbuff); } printf("rxhash: 0x%x\n", ppd->hv1.tp_rxhash); } static void walk_block(struct block_desc *pbd, const int block_num) { int num_pkts = pbd->h1.num_pkts, i; unsigned long bytes = 0; struct tpacket3_hdr *ppd; ppd = (struct tpacket3_hdr *) ((uint8_t *) pbd + pbd->h1.offset_to_first_pkt); for (i = 0; i < num_pkts; ++i) { bytes += ppd->tp_snaplen; display(ppd); ppd = (struct tpacket3_hdr *) ((uint8_t *) ppd + ppd->tp_next_offset); } packets_total += num_pkts; bytes_total += bytes; } static void flush_block(struct block_desc *pbd) { pbd->h1.block_status = TP_STATUS_KERNEL; } static void teardown_socket(struct ring *ring, int fd) { munmap(ring->map, ring->req.tp_block_size * ring->req.tp_block_nr); free(ring->rd); close(fd); } int main(int argc, char **argp) { int fd, err; socklen_t len; struct ring ring; struct pollfd pfd; unsigned int block_num = 0, blocks = 64; struct block_desc *pbd; struct tpacket_stats_v3 stats; if (argc != 2) { fprintf(stderr, "Usage: %s INTERFACE\n", argp[0]); return EXIT_FAILURE; } signal(SIGINT, sighandler); memset(&ring, 0, sizeof(ring)); fd = setup_socket(&ring, argp[argc - 1]); assert(fd > 0); memset(&pfd, 0, sizeof(pfd)); pfd.fd = fd; pfd.events = POLLIN | POLLERR; pfd.revents = 0; while (likely(!sigint)) { pbd = (struct block_desc *) ring.rd[block_num].iov_base; if ((pbd->h1.block_status & TP_STATUS_USER) == 0) { poll(&pfd, 1, -1); continue; } walk_block(pbd, block_num); flush_block(pbd); block_num = (block_num + 1) % blocks; } len = sizeof(stats); err = getsockopt(fd, SOL_PACKET, PACKET_STATISTICS, &stats, &len); if (err < 0) { perror("getsockopt"); exit(1); } fflush(stdout); printf("\nReceived %u packets, %lu bytes, %u dropped, freeze_q_cnt: %u\n", stats.tp_packets, bytes_total, stats.tp_drops, stats.tp_freeze_q_cnt); teardown_socket(&ring, fd); return 0; }代码说明:
使用的tpacket_req3 时候会有两个以前没有的变量赋值如下:
ring->req.tp_retire_blk_tov = 60; ring->req.tp_feature_req_word = TP_FT_REQ_FILL_RXHASH;tp_retrie_blk_tov 即超时值,单位是毫秒。当这个超时被触发时,内核会将该块的状态从 TP_STATUS_USER 改为 TP_STATUS_KERNEL,即超时触发后,会将缓存区释放给内核用来装数据了。
tp_feature_req_word 即功能值,tp_feature_req_word 被设置为 TP_FT_REQ_FILL_RXHASH。这个标志请求内核在每个数据包的头部填充接收哈希(RX hash)值。接收哈希通常用于负载均衡和流量分类等场景,它可以提供一种快速的方式来决定数据包应该如何被处理或路由。
v3版本来说,数据包帧的最小大小,不能低于这个大小。
mmap申请内核和用户空间共享的内存,注意设置MAP_LOCKED标识的意思,这个内存是不可以交换到磁盘上的,会被锁在物理内存中。
如果需要让内核设置包的时间,可以通过下面代码设置:
int req = SOF_TIMESTAMPING_RAW_HARDWARE; setsockopt(fd, SOL_PACKET, PACKET_TIMESTAMP, (void *) &req, sizeof(req));转换ip代码:
struct sockaddr_in ss, sd; char sbuff[NI_MAXHOST], dbuff[NI_MAXHOST]; memset(&ss, 0, sizeof(ss)); ss.sin_family = PF_INET; ss.sin_addr.s_addr = ip->saddr; getnameinfo((struct sockaddr *) &ss, sizeof(ss),sbuff, sizeof(sbuff), NULL, 0, NI_NUMERICHOST);这段代码是将获取的包的ip地址,其中:NI_NUMERICHOST: 直接返回主机的IP地址,而不是尝试查找主机名。
主循环:
while (likely(!sigint)) { pbd = (struct block_desc *) ring.rd[block_num].iov_base; if ((pbd->h1.block_status & TP_STATUS_USER) == 0) { poll(&pfd, 1, -1); continue; } walk_block(pbd, block_num); flush_block(pbd); block_num = (block_num + 1) % blocks; }在没有中断的情况下,获取block头部信息,根据头的block状态,如果不是TP_STATUS_USER情况下,继续进入poll等待。如果已经有数据了,则走walk循环,然后更改block状态,block指针后移,做循环队列,这个和原来v1版本的frame做循环。
代码如下:
// 调整block执行第一个packet包、下一个包是通过tp_next_offset 来指向的。 ppd = (struct tpacket3_hdr *) ((uint8_t *) pbd + pbd->h1.offset_to_first_pkt); for (i = 0; i < num_pkts; ++i) { bytes += ppd->tp_snaplen; display(ppd); ppd = (struct tpacket3_hdr *) ((uint8_t *) ppd + ppd->tp_next_offset); }代码里面数据结构示意图如下:
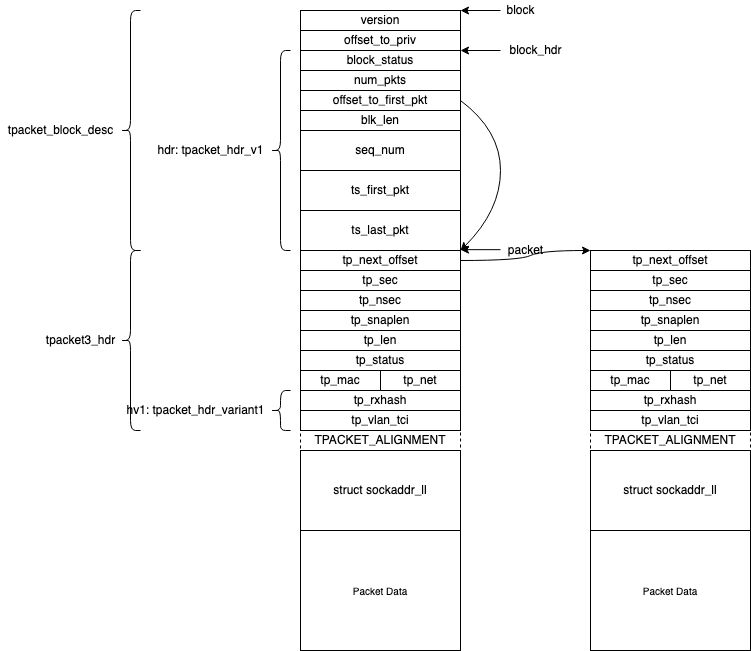
image.png
三 SOCKET的fanout
虽然V3版本相当于前面的版本来说,性能有所提升,但是在现在的多核环境下,如果只简单的用V3版本,仍然,不能达到捕获超大流量数据包情况下而不丢包。
AF-PACKET支持多核抓包,从内核3.1版本开始,AF-PACKET 可以将多个不同进程或线程的socket加入到一个fanout组中,并行一同抓包。内核会利用一定的算法对packet进行分组进入不同socket中,从而让包在多个线程或进程中进行处理,达到负载均衡的目的。
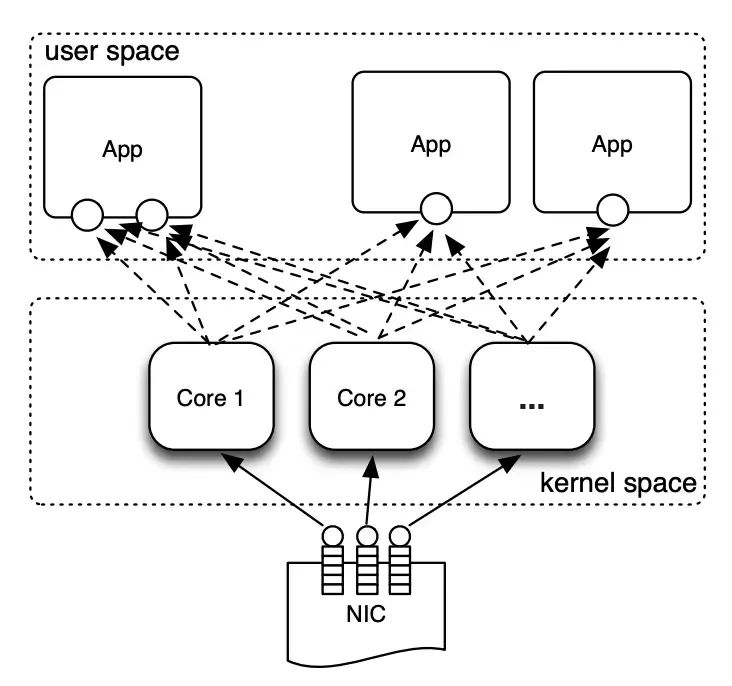
多socket收包
一个fanout组中最多可以支持65536个socket,通过setsockopt系统调用并指定PACKET_FANOUT选项来加入扇出组,当关闭一个组内socket的时候,就会从扇出组内扇出,如果组内的所有socket都退出了,组也会被内核销毁。这里面的fanout翻译成扇出组,想想挺形象,像扇子一样,扇子的头是一个,打开后分散了,扇出组也是这个目的,上图中NIC是有多队列的,所以本身就是分散进入的数据。
扇出有不同的算法,说明如下:
PACKET_FANOUT_HASH: 默认的扇出算法,通过计算ip地址和可选的tcp端口的哈希函数,将包发到不同的socket,且能保持同一个流的packet发到同一个socket,便于后续线程继续处理。
PACKET_FANOUT_LB: 简单的采用轮训的负载均衡算法,但是不能保证同一个流发送到同一个socket。
PACKET_FANOUT_RND :模式通过使用伪随机数生成器来选择目标套接字。同样,这种模式只允许进行无状态处理。
PACKET_FANOUT_CPU :模式根据接收到数据包的 CPU 来选择数据包套接字。
PACKET_FANOUT_ROLLOVER: 模式持续将所有数据发送到一个套接字,直到该套接字出现拥塞。然后,它转移到组内的下一个套接字,直到该套接字也耗尽,依此类推。
PACKET_FANOUT_QM : 模式选择与接收到数据包的硬件队列编号相匹配的数据包套接字。即RSS队列和socket对应,这种默认如果设置了RSS的均衡算法为对称哈希算法,则也能保证一个流的所有packet发送到同一个socket中去。Linux 3.14以后可用,以前版本不支持。
看下内核测试代码里面的例子如下:
#include <stddef.h> #include <stdlib.h> #include <stdio.h> #include <string.h> #include <sys/types.h> #include <sys/wait.h> #include <sys/socket.h> #include <sys/ioctl.h> #include <unistd.h> #include <linux/if_ether.h> #include <linux/if_packet.h> #include <net/if.h> static const char *device_name; static int fanout_type; static int fanout_id; #ifndef PACKET_FANOUT # define PACKET_FANOUT 18 # define PACKET_FANOUT_HASH 0 # define PACKET_FANOUT_LB 1 #endif static int setup_socket(void) { int err, fd = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_IP)); struct sockaddr_ll ll; struct ifreq ifr; int fanout_arg; if (fd < 0) { perror("socket"); return EXIT_FAILURE; } memset(&ifr, 0, sizeof(ifr)); strcpy(ifr.ifr_name, device_name); err = ioctl(fd, SIOCGIFINDEX, &ifr); if (err < 0) { perror("SIOCGIFINDEX"); return EXIT_FAILURE; } memset(&ll, 0, sizeof(ll)); ll.sll_family = AF_PACKET; ll.sll_ifindex = ifr.ifr_ifindex; err = bind(fd, (struct sockaddr *) &ll, sizeof(ll)); if (err < 0) { perror("bind"); return EXIT_FAILURE; } fanout_arg = (fanout_id | (fanout_type << 16)); err = setsockopt(fd, SOL_PACKET, PACKET_FANOUT, &fanout_arg, sizeof(fanout_arg)); if (err) { perror("setsockopt"); return EXIT_FAILURE; } return fd; } static void fanout_thread(void) { int fd = setup_socket(); int limit = 10000; if (fd < 0) exit(fd); while (limit-- > 0) { char buf[1600]; int err; err = read(fd, buf, sizeof(buf)); if (err < 0) { perror("read"); exit(EXIT_FAILURE); } if ((limit % 10) == 0) fprintf(stdout, "(%d) \n", getpid()); } fprintf(stdout, "%d: Received 10000 packets\n", getpid()); close(fd); exit(0); } int main(int argc, char **argp) { int fd, err; int i; if (argc != 3) { fprintf(stderr, "Usage: %s INTERFACE {hash|lb}\n", argp[0]); return EXIT_FAILURE; } if (!strcmp(argp[2], "hash")) fanout_type = PACKET_FANOUT_HASH; else if (!strcmp(argp[2], "lb")) fanout_type = PACKET_FANOUT_LB; else { fprintf(stderr, "Unknown fanout type [%s]\n", argp[2]); exit(EXIT_FAILURE); } device_name = argp[1]; fanout_id = getpid() & 0xffff; for (i = 0; i < 4; i++) { pid_t pid = fork(); switch (pid) { case 0: fanout_thread(); case -1: perror("fork"); exit(EXIT_FAILURE); } } for (i = 0; i < 4; i++) { int status; wait(&status); } return 0; }代码采用简单的方式演示了fanout代码,关键代码在于:
// fanout_arg 高16位存的是fanout的类型,低16位存的是fanout的id,即是fanout的组id。 fanout_arg = (fanout_id | (fanout_type << 16)); err = setsockopt(fd, SOL_PACKET, PACKET_FANOUT, &fanout_arg, sizeof(fanout_arg));四 参考
https://www.kernel.org/doc/Documentation/networking/packet_mmap.txt