
阅读量:3
一、定义
- 定义
- 案例
二、实现
定义
- rank:进程号,在多进程上下文中,我们通常假定rank 0是第一个进程或者主进程,其它进程分别具有1,2,3不同rank号,这样总共具有4个进程
- node:物理节点,可以是一个容器也可以是一台机器,节点内部可以有多个GPU;nnodes指物理节点数量, nproc_per_node指每个物理节点上面进程的数量
- local_rank:指在一个node上进程的相对序号,local_rank在node之间相互独立
- WORLD_SIZE:全局进程总个数,即在一个分布式任务中rank的数量
- Group:进程组,一个分布式任务对应了一个进程组。只有用户需要创立多个进程组时才会用到group来管理,默认情况下只有一个group
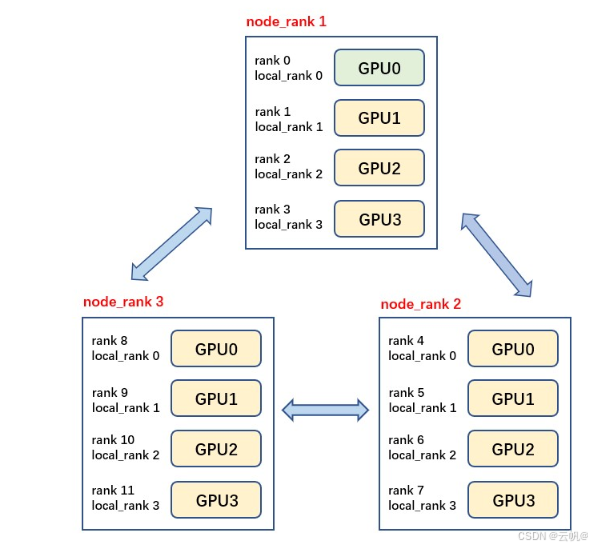
共有3个节点(机器),每个节点上有4个GPU,每台机器上起4个进程,每个进程占一块GPU,那么图中一共有12个rank,nproc_per_node=4,nnodes=3,每个节点都一个对应的node_rank。
案例1
- 使用torch.multiprocessing(python的multiprocessing的封装类) 来自动生成多个进程.
mp.spawn(fn, args=(), nprocs=1, join=True, daemon=False) #自动生成多个进程 fn: 进程的入口函数,该函数的第一个参数会被默认自动加入当前进*程的rank, 即实际调用: fn(rank, *args) nprocs: 进程数量,即:world_size args: 函数fn的其他常规参数以tuple的形式传递 import torch import torch.distributed as dist import torch.multiprocessing as mp def fn(rank, ws, nums): dist.init_process_group('nccl', init_method='tcp://127.0.0.1:28765', rank=rank, world_size=ws) rank = dist.get_rank() print(f"rank = {rank} is initialized") torch.cuda.set_device(rank) tensor = torch.tensor(nums).cuda() print(tensor) if __name__ == "__main__": ws = 2 mp.spawn(fn, nprocs=ws, args=(ws, [1, 2, 3, 4])) # python test.py 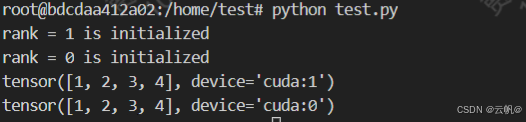
2. 使用torchrun 启动
import torch import torch.distributed as dist import torch.multiprocessing as mp import os dist.init_process_group('nccl', init_method='env://') rank = dist.get_rank() local_rank = os.environ['LOCAL_RANK'] master_addr = os.environ['MASTER_ADDR'] master_port = os.environ['MASTER_PORT'] print(f"rank = {rank} is initialized in {master_addr}:{master_port}; local_rank = {local_rank}") torch.cuda.set_device(rank) tensor = torch.tensor([1, 2, 3, 4]).cuda() print(tensor) #torchrun --nproc_per_node=2 test.py --nnodes: 使用的机器数量,单机的话,就默认是1了 --nproc_per_node: 单机的进程数,即单机的worldsize --master_addr/port: 使用的主进程rank0的地址和端口 --node_rank: 当前的进程rank 
参考:
