
阅读量:0
一、前言
本文将介绍GPGPU中线程束的调度方案、记分牌方案和线程块的分配与调度方案。
二、线程束调度
在计算机中有很多资源,既可以是虚拟的计算资源,如线程、进程或数据流,也可以是硬件资源,如处理器、网络连接或 ALU 单元。调度的目的是使得所有资源都处于忙碌状态,从而允许多个工作可以有效地同时共享资源,或达到指定的服务质量。
当 SM 中有众多线程束且处于就绪态(或活跃)时,需要调度器从其中挑选出一个。这个被选中的线程束会在接下来的执行周期中根据它的 PC 发射出一条新的指令来执行。从整个 SM 角度看,由于调度器每个周期都可以切换它所选择的线程束,不同线程束的不同指令可能会细粒度地交织在一起,而同一个线程束的指令则是顺序执行的,如下图所示:
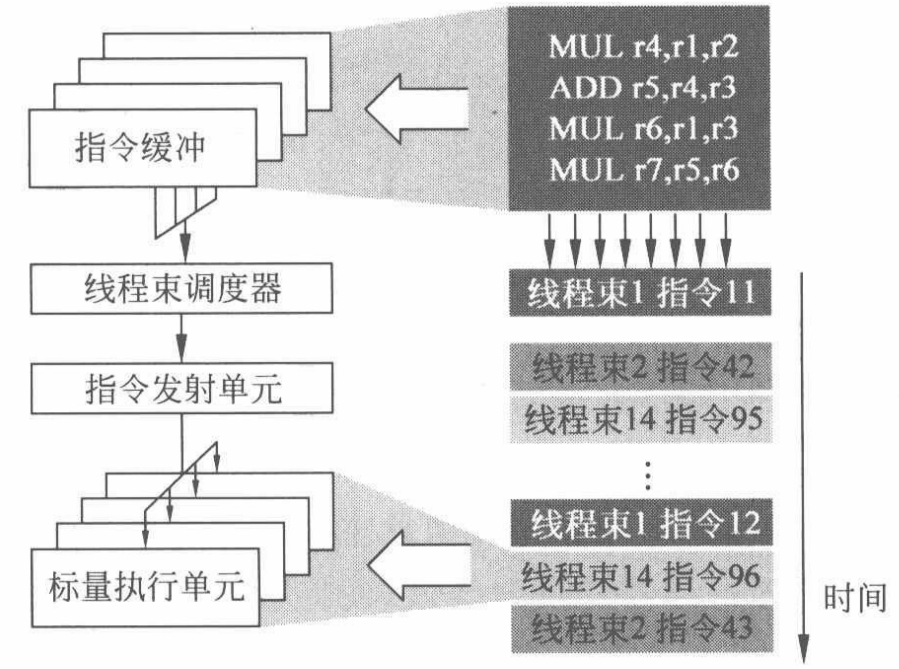
2.1 基本的调度策略
GPGPU 线程束调度器的职责是从就绪的线程束中挑选一个或多个线程束发送给空闲的执行单元。这个过程看似简单,但由于连接了指令取指和执行两个关键步骤,调度器的选择会涉及整个GPGPU 执行过程的多方面,对 GPGPU 的性能有着重要的影响。
如何判断线程束是否“就绪”呢?在 GPGPU 架构中,NVIDIA 对发射停顿的原因有如下描述:
(1) Pipeline busy,指令运行所需的功能单元正忙;
(2) Texture 单元正忙;
(3) Constant 缓存缺失,一般说来会在第一次访问时缺失;
(4) Instruction Fetch,指令缓存缺失,一般只有第一次运行访问容易缺失;
(5) Memory Throttle,有大量存储访问操作尚未完成,为了不加剧性能损耗导致存储指令无法下发。这种原因造成的停顿可以通过合并存储器事务来缓解;
(6) Memory Dependency,由于请求资源不可用或满载导致 load/store 无法执行,可以通过存储访问对齐和改变访问模式来缓解;
(7) Synchronization,线程束在等待同步指令,如 CUDA 中的_syncthreads() 要求线程块中的所有线程都到达后才能统一继续执行下一条指令;
(8) Execution Dependency,输入依赖关系还未解决,即输入值未就绪。这与 CPU 中的数据相关是类似的。
只有消除了上述原因的线程束才可能被认为是可以发射的。
从指令缓存中读取到的指令一般会被存放在一个小的指令解码缓冲区中,指令缓冲区采用一个简单的表结构,表象数目与可编程多处理器所允许的最大线程ID数量相关。每个表项包含一个线程束的基本信息,如线程块ID,线程束ID和线程ID。
![]()
在众多就绪的线程束中,调度器根据不同的算法会有不同的选择策略。轮询(Round-Robin,RR)调度策略。如下图所示,它在调度过程中,对处于就绪状态的线程束0、1、3、4、5都赋予相同的优先级,并按照轮询的策略依次选择处于就绪状态的线程束指令进行调度,完成后再切换到下一个就绪线程束,如线程束0、1、3、4、5都执行完成指令0后再重复上述过程直到执行结束。与之相对应的另一种策略称为 GTO(Greedy-Then-Oldest)。 该策略允许一个线程束按照贪心策略一直执行到不能执行为止。下图 GTO 调度器首先选择了线程束0的前3条指令执行,直到无法继续执行指令,此时再切换到线程束1的前3条指令执行。GTO 调度与轮询调度可以认为是两种极端情况。
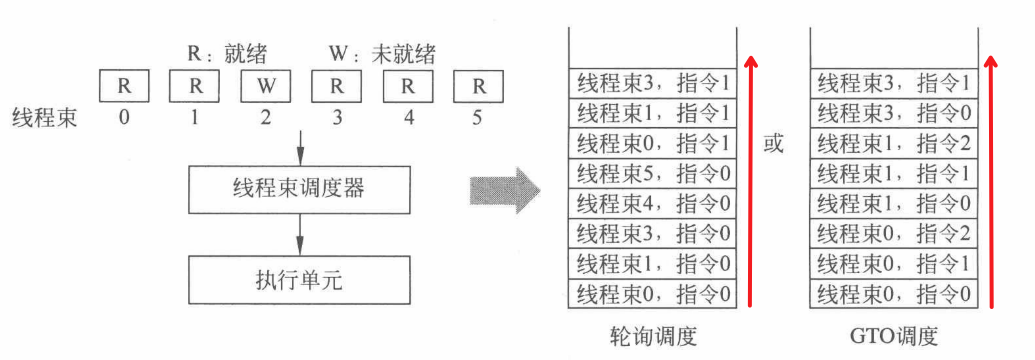
2.2 调度策略的优化
在 GPGPU 架构中,数据的访存延时仍然是影响性能的主要因素,而发掘数据的局部性则是改善访存延时最有效的手段之一。
由于 SIMT 架构的特点, 一般来讲内核函数中往往存在两种数据局部性:线程束内局部性(intra-warp locality)和线程束间局部性(inter-warp locality)。当数据被一个线程访问后,如果不久之后还会被同一线程束中的其他线程再次访问则称为线程束内局部性,而如果再次访问的是其他线程束中的线程则称为线程束间局部性。注意这里所谓的“再次访问”可能是这个数据本身,也可能是相邻地址的数据,因此是包含了时间和空间两种局部性而言的。
回顾轮询和 GTO 两种调度策略,其实两者就是发掘线程束内局部性和线程束间局部性的不同体现:轮询策略通过执行不同线程束的同一条指令,较好地获得了线程束间局部性;而GTO 策略则更多地考虑了线程束内的局部性。
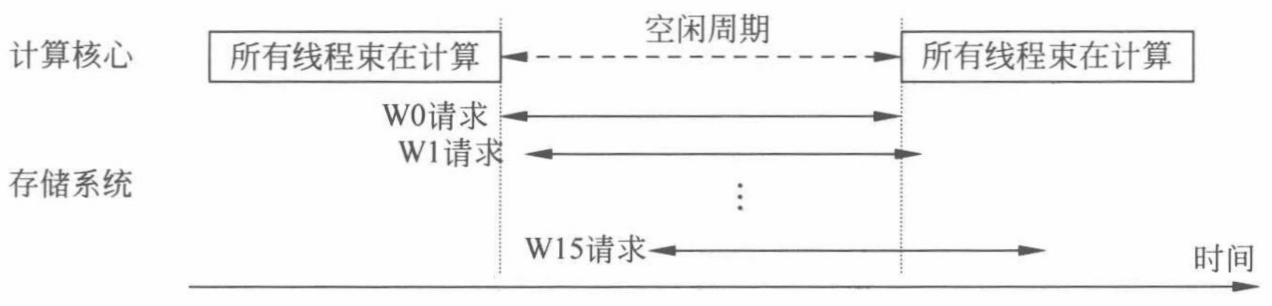
使用轮询策略对16个线程束W0,W1,…,W15进行调度,每 个线程束中 ~均为运算指令,为访存指令。调度器依次调度各线程束的指令,直到16×(k-1) 个周期后,所有线程束先后进入访存指令,执行长延时操作,假设相邻线程束执行指令仅相差一个周期,此时也没有更多可供调度的线程束来隐藏访存延迟,这导致流水线陷入了一段较长时间的空闲。
~均为运算指令,为访存指令。调度器依次调度各线程束的指令,直到16×(k-1) 个周期后,所有线程束先后进入访存指令,执行长延时操作,假设相邻线程束执行指令仅相差一个周期,此时也没有更多可供调度的线程束来隐藏访存延迟,这导致流水线陷入了一段较长时间的空闲。
GTO 策略则倾向于让一个线程束尽快执行。当遭遇了长延时操作时,其他线程束还可以有更多的指令用于掩藏延时,从而提供一定程度的改进。但GTO 策略可能会破坏线程间局部性,使得这些本来可以避免的访存缺失 反而需要更高的线程并行度来掩盖。
2.2.1 利用并行性掩藏长延时操作
(a)两级轮询调度
两级线程束调度(two-level warp scheduling)策略,它将所有线程束划分为固定大小的组(fetch group),组间基于优先级顺序的策略进行调度,但本质上还是轮询策略。16个线程束的例子,分为2组,每组包含8个线程束。第0组拥有较高优先级,第1组次之。调度器优先选取第0组调度,组内按照轮询策略依序执行各个线程束的指令、指令……直到组内8个线程束都执行完访存指令时,赋予第1组最高优先级并调度执行。此时还有8个线程束,每个线程束也有足够的指令(~) 可供调度,从而更好地掩藏第0组访存操作带来的长延时。
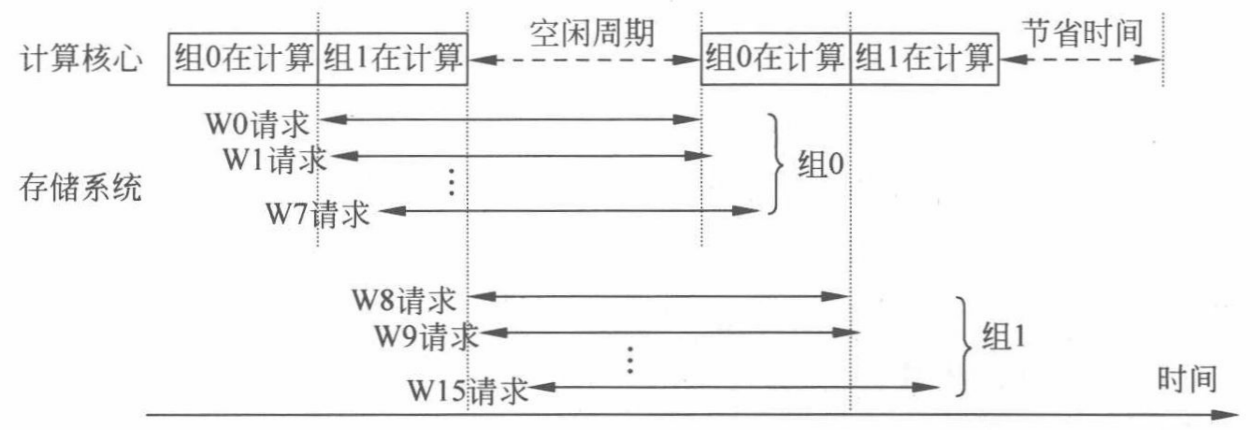
(b)线程块感知的两级轮询调度
线程块感知的两级线程束调度(Cooperative Thread Array aware two -level warp scheduling)利用线程块间的数据局部性,分组时将若干存在数据局部性的线程块分配到同一组中,程块内的线程束具有相等的优先级,线程束级同样按照轮询策略调度执行。
(c)结合数据预取的两级调度策略
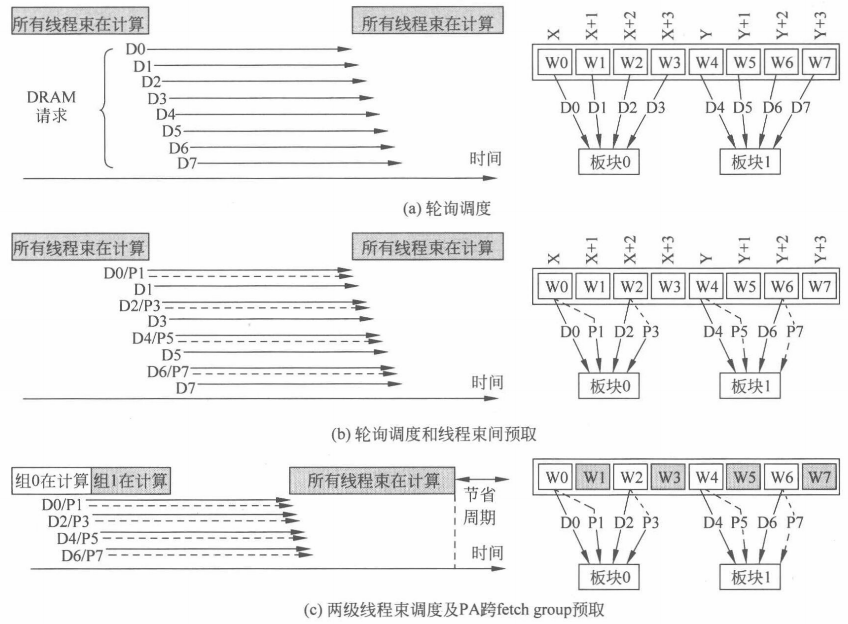
按照两级轮询优先调度第0组配合简单预取策略,如上图(c)所示,在W0请求访问全局存储器时,对 W1 的预取 P1 也一样被发出,而 W1 真正被调度时已经在组0的线程束全部进入停顿之后,一部分预取时间已经被执行时间掩盖,从而能够提高预取质量。等到组0的数据和预取数据返回后,所有的线程束都可以计算。
2.2.2 利用局部性提高片上数据复用
利用数据的局部性对提升性能来讲也至关重要,当数据被加载到片上存储尤其是 L1 数据缓存后,如果能有效地重用这些数据提高缓存的命中率,既可以减少访存的延时,又可以减少重复的访存操作,相当于减少了长延时访存操作的次数。
一个进度分化的原因在于单一线程块内的线程束由于存储系统访问的不确定性,即便采用轮询调度,不同线程束的执行进度也可能存在较大差异。另外一个进度分化的重要原因就是在线程同步栅栏处或在分支线程重聚的位置,执行快的线程束先到达,等待执行慢的线程束。
关键性感知的线程束协调加速(Coordinated criticality-Aware Warp Acceleration,CAWA),线程束的 “关键性”(criticality)反映的就是线程束执行时间的长短,执行时间最长的线程束为关键线程束,给予关键线程束最高调度优先级,分配更多硬件和时间资源以满足执行需求。
基于 GTO 的关键性感知线程束调度策略(gCAWS),改进了调度选取线程束的机制,每次选择关键度最高的一个线程束执行,当有多个关键度相同的线程束时,选择生命周期最长的线程束执行,在执行阶段不断更新关键度的值。
三、记分牌
在通用处理器中,寄存器数据可能存在三种类型的相关:写后读、写后写 和读后写,都可能会导致冒险。
(1) 写后读(Read After Write,RAW),也称真数据相关(true dependence)。按照程序顺序,某个特定寄存器的写指令后面为该寄存器的读指令。若读指令先于写指令执行,则读指令只能访问到未被写指令更新的寄存器旧值,从而产生错误的执行结果。
(2) 写后写(Write After Write,WAW),也称名称相关(name dependence)。按照程序顺序,写指令1后为写指令2,并且都会更新同一个目的寄存器。若写指令2先于写指令1执行,则最后保留在目的寄存器中的是写指令1的结果,这与程序顺序执行的语义不符。
(3) 读后写(Write After Read,WAR),也称反相关(anti-dependence)。 按照程序顺序,对某个特定寄存器的读指令后面为该寄存器的写指令。若写指令先于读指令执行,则读指令将获取到更新后的寄存器值,产生错误的执行结果。
经典的记分牌技术通过标记指令状态、功能单元状态和寄存器结果状态,控制数据寄存器与功能单元之间的数据传送,实现了乱序流水线下指令相关性的检测和消除,保证了程序执行的正确性,同时提高了程序的执行性能。
3.1 GPGPU中的记分牌
为了提高 SIMT 运算单元的硬件效率,GPGPU 一般会采用顺序执行的方式,避免乱序流水线带来的指令管理开销。但 GPGPU 指令的执行仍然可能需要多个周期才能完成,而且不同指令存在不等长执行周期的情况。因此,为了让同一线程束的后续指令在发射时减少等待时间而尽早发射,仍然要保证前后指令之间不存在数据相关,从而提高指令的发射和执行效率。
记分牌的机制可以避免由数据相关导致的冒险情况发生。记分牌为每个线程束寄存器分配1个比特用于记录相应寄存器的写完成状态。如果正在执行的线程束指令将要写回的目标寄存器为Rx, 则在记分牌中将寄存器对应的标识置为1,表示该指令尚未写回完成。在此之前,如果同一线程束中的后续指令不存在数据相关,则可以尽早进入流水线执行。否则,指令不能发射。
记分牌设计方案虽然简单,但主要存在两方面的问题:
(1)若每个寄存器都分配1bit标识,记分牌将占用大量空间;
(2)所有待发射线程束指令在调度时需要一直查询记分牌,直到所依赖的指令执行完毕,更新寄存器标识位,才能发射后续指令,这会带来巨大开销。
3.2 记分牌设计优化
3.2.1 基于寄存器编号索引的记分牌设计
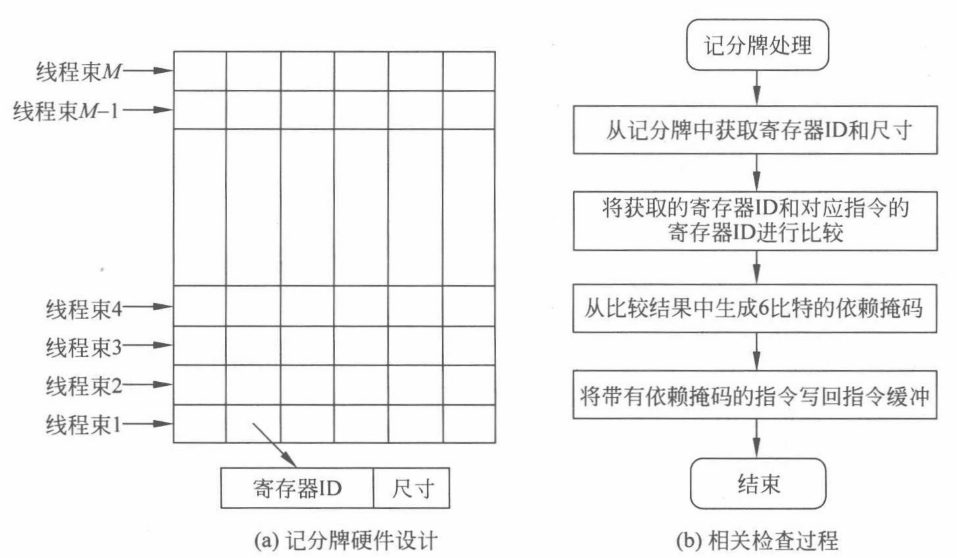
考虑到记分牌主要是对指令缓冲(I-Buffer) 中已解码的指令进行相关性检查才可能发射,因此可以将记分牌存储空间划分为与指令缓冲中指令数目相同的区域。
每个区域中包含若干条目,每个条目包含两个属性:寄存器RID(Register ID)和尺寸指示器。寄存器 RID 记录了该区域所对应的线程束目前正在执行的若干指令中,将要写回的目的寄存器编号。如果指令中将要写回的寄存器为一个序列,尺寸指示器则负责记录该寄存器序列的长度,而 RID 只需要记录这个序列中的第一个寄存器 RID。相关检查过程如下图(b)所示。
3.2.2 基于读写屏障的软件记分牌设计
软件记分牌设计:首先设计一定量的读写屏障,借助编译器分析,显式地将存在相关性的寄存器绑定到某个读写屏障上,在运行时,目的寄存器的写操作可以直接设定绑定的读写屏障,而源寄存器的读操作需要读取绑定的读写屏障来获知寄存器的写操作是否写完。这些信息由编译器提供,可以节省硬件开销,降低搜索代价,从而快速定位到绑定的读写屏障。
四、线程块分配与调度
线程块的分配和调度是 GPGPU 硬件多线程执行的前提。线程块的分配决定了哪些线程块会被安排到哪些 SM 上执行,而线程块的调度决定了已分配的线程块按照什么顺序执行。两者关系密切,对于 GPGPU 的性能有着直接的影响。
4.1 线程块的基本分配策略
在线程块分配方面,GPGPU 通常采用轮询作为基本策略。首先,线程块调度器将按照轮询方式为每个可编程多处理器分配至少一个线程块,若第一轮分配结束后可编程多处理器上仍有空闲未分配的资源(包括寄存器、共享存储器、线程块分配槽等),则进行第二轮分配,同理,若第二轮分配后仍有资源剩余,可以开始下一轮资源分配,直到所有可编程多处理器上的资源饱和为止。对于尚未分配的线程块,需要等待已分配的线程块执行完毕并将占有的资源释放后,才可以分配到可编程多处理器上执行。
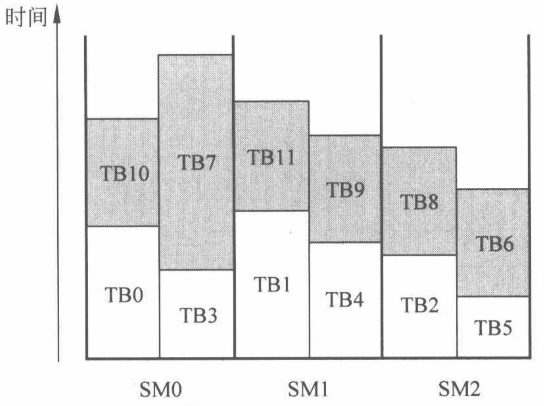
假设一个 GPGPU 中有3个SM,分别为SM0 、SM1 和 SM2,每个 SM 允许最多同时执行2个线程块。一个内核函数声明了12个线程块 TB0~TB11。根据轮询的原则,TB0~TB2被分配到 SM0~SM2。由于每个 SM 可以同时执行2个线程块 ,TB3~TB5 也被分配到 SM0~SM2 中 。此时,SM 的硬件资源已经被完全占用,剩下的线程块暂时无法分配到 SM 中执行,必须等待有线程块执行完毕释放硬件资源,才能继续分配。一段时间后,SM2 中 TB5 率先执行完毕释放硬件资源,TB6 被分配到 SM2中 执行。
初始一轮的线程块分配顺序是轮询的,但第二轮的线程块分配完全是按照执行进度安排的。
4.2 线程块的基本调度策略
线程块的调度与线程束的调度策略有很高的关联性。两者对 GPGPU 的执行性能都有着重要的影响,只是调度的粒度有所不同。
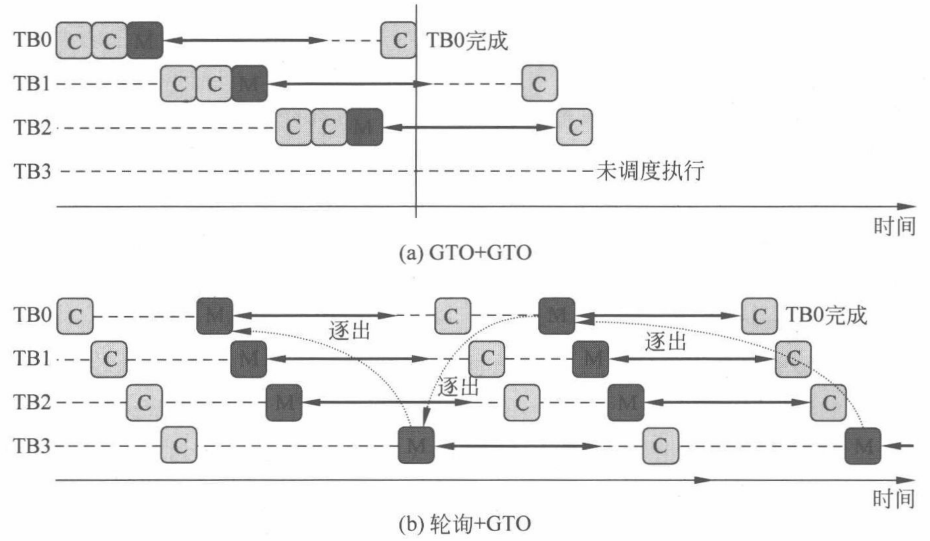
假设有4个线程块 TB0~TB3 被分配到一个可编程多处理器上。图(a)中线程块和各自的线程束都按照 GTO 的方式调度,最终TB3线程没有被使用到,造成了资源的浪费。如果改变线程块的调度策略为轮询策略也会有另外的问题,假设 TB3 和 TB0 读取的数据都存放在同一缓存行中,就会导致 TB3 和 TB0 在数据缓存上存在竞争,产生缓存抖动问题,增加了缓存缺失率和访问开销。因此独立的调度策略设计并不能解决这个问题,需要与线程块分配策略协同优化。
4.3 线程块分配与调度的优化策略
1. 感知空间局部性的调度策略
(a)感知 L1缓存局部性的块级线程块调度
(b)感知 DRAM 板块的线程块协同调度
2. 感知时间局部性的抢占调度策略
3. 限制线程块数量的怠惰分配和调度策略
4. 利用线程块重聚类感知局部性的软件调度策略
