
阅读量:1
GEO数据库可以说是大家使用频率贼高的数据库啦!那它里面的数据怎么下载大家知道嘛!今天给大家展示一种快速获取它的表达矩阵和临床信息的方法!
话不多说!咱们直接开始!
GEO编号获取
在GEO数据库中,你找到了你需要的数据,接下来怎么办嘞!下载它!处理它!
比如,咱们今天需要的数据是这个:
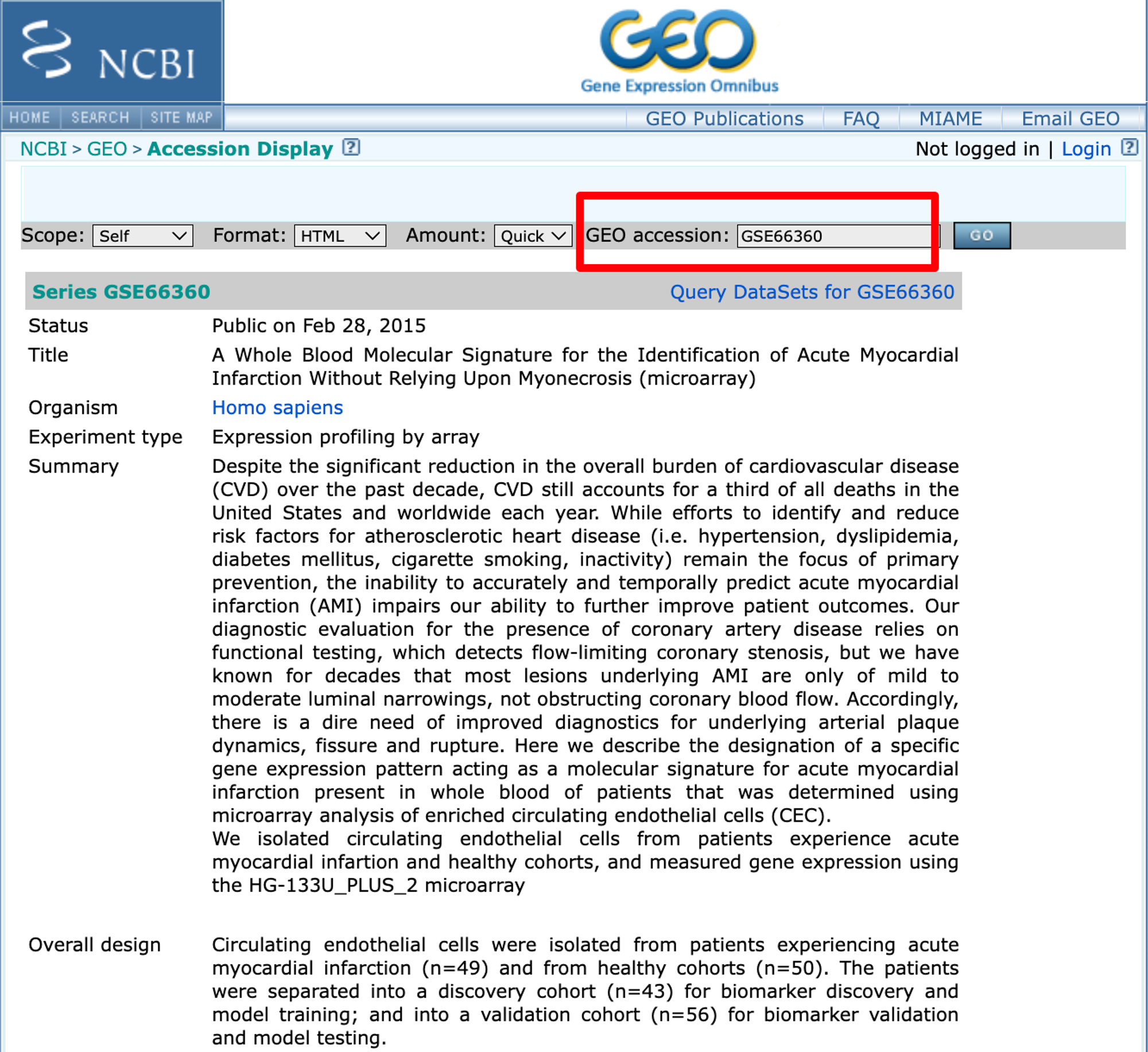
GEO编号这不就有咯!咱们开始下载!噢对,提前吱一声,芯片数据和非芯片数据进行ID转换的时候方法不太一样,大家要注意噢!我今天会都给大家演示一下!
GEO数据库今天咱就不介绍了哈!我后面再专门出一期超级详细地介绍它!迫切的小伙伴可以在后台或群里催我哈哈哈哈哈哈哈哈!
另外注意:不是所有的GEO数据集都可以使用这种方法下载。不过通常来说,大部分的GEO数据集都可以通过
getGEO函数进行下载,但也有一些例外情况,特别是单细胞数据[无奈脸]!多数情况下,应该是数据集可能不是以类似的格式存储,或者有的作者上传格式不对等等,所以就需要找其他办法或者手动下载啦!建议就是先试试这种方法,要是里面是空的,就去手动或者其他!
数据下载
芯片数据
#################### GEO数据下载及表达矩阵与临床信息获取 ####################### # 加载包,没有安装的记得安装一下哟! library(tidyverse) library(GEOquery) library(tinyarray) # 芯片数据 # GEO编号,替换成你自己的就好啦! geo_number = "GSE66360" # 这一步啊,看运气!网络时好时坏,是个玄学!一次不行不要慌!咱多跑几次!总会成功的! geo_data <- getGEO(geo_number, destdir = './', getGPL = F) # 自己设置想保存的路径 geo_data0 <- geo_data[[1]] 数据长这样!
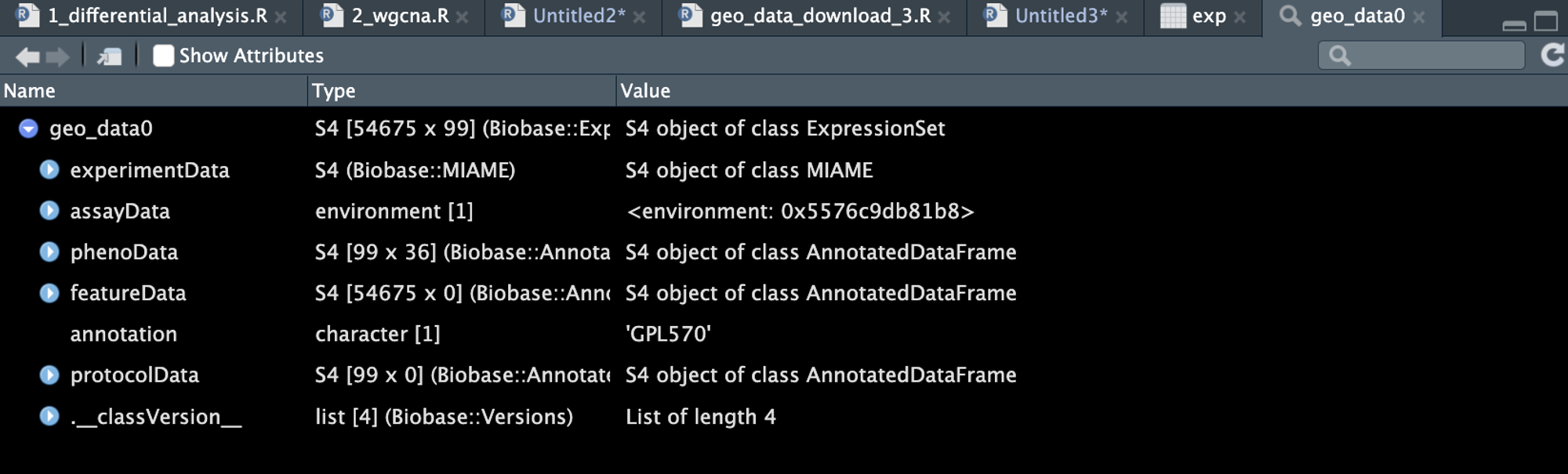
# 提取表达矩阵 exp <- exprs(geo_data0) dim(exp) # [1] 54675 99 exp[1:4, 1:4] # GSM1620819 GSM1620820 GSM1620821 GSM1620822 # 1007_s_at 5.866378 4.948736 5.148384 5.064419 # 1053_at 8.225790 7.525865 7.764637 7.198461 # 117_at 6.179732 6.628137 5.859151 5.974135 # 121_at 6.179478 6.582889 6.602135 6.545905 # 可以看到这里还是探针ID,咱们后给它面转换为基因symbol! # 可以自行判断是否需要log exp <- log2(exp + 0.01) # 接下来我们进行ID转换 # 探针注释获取 gpl_number <- geo_data0@annotation ids <- AnnoProbe::idmap(gpl_number) head(ids) # probe_id symbol # 193731 1053_at RFC2 # 193732 117_at HSPA6 # 193733 121_at PAX8 # 193734 1255_g_at GUCA1A # 193735 1316_at THRA # 193736 1320_at PTPN21 # ID转换 exp <- as.data.frame(exp) exp$probe_id <- rownames(exp) exp <- inner_join(ids, exp, by = "probe_id") exp <- exp[!duplicated(exp$symbol), ] # 关于重复基因去重的问题,咱们后面专门出一期介绍!这里先用最大道至简的方法! rownames(exp) <- exp$symbol exp <- exp[ , -c(1,2)] head(exp)[1:4, 1:4] # GSM1620819 GSM1620820 GSM1620821 GSM1620822 # RFC2 3.041907 2.913773 2.958775 2.849691 # HSPA6 2.629877 2.730778 2.553152 2.581143 # PAX8 2.629818 2.720911 2.725116 2.712795 # GUCA1A 1.486482 1.436010 1.373053 1.444733 # 提取临床信息 cli <- pData(geo_data0) head(cli)[1:4, 1:6] # title geo_accession status submission_date last_update_date type # GSM1620819 Muse_1_DISCOVERY_Control GSM1620819 Public on Feb 28 2015 Feb 27 2015 Feb 28 2015 RNA # GSM1620820 Muse_2_DISCOVERY_Control GSM1620820 Public on Feb 28 2015 Feb 27 2015 Feb 28 2015 RNA # GSM1620821 Muse_3_DISCOVERY_Control GSM1620821 Public on Feb 28 2015 Feb 27 2015 Feb 28 2015 RNA # GSM1620822 Muse_4_DISCOVERY_Control GSM1620822 Public on Feb 28 2015 Feb 27 2015 Feb 28 2015 RNA # 为了后续分析,咱还可以给它进一步调整,使表达矩阵列名和临床信息的行名完全一致 p <- identical(rownames(cli), colnames(exp)) p # [1] TRUE # 噢啦! # 噢不!还没结束!那万一不是芯片数据怎么办呢!咱们再演示一个! 非芯片数据
# 非芯片数据 # 比如这个GEO数据集 geo_number = "GSE16561" # 这一步啊,看运气!网络时好时坏,是个玄学!一次不行不要慌!咱多跑几次!总会成功的! geo_data <- getGEO(geo_number, destdir = './', getGPL = F) geo_data0 <- geo_data[[1]] # 提取表达矩阵 exp <- exprs(geo_data0) dim(exp) # [1] 54675 99 exp[1:4, 1:4] # GSM416528 GSM416529 GSM416530 GSM416531 # ILMN_1343291 0.22550488 0.7348099 0.7431908 0.63261986 # ILMN_1651209 -0.03326082 0.5184302 0.5990343 0.25144434 # ILMN_1651228 -0.20895290 -0.9036322 -0.3511963 -0.06179523 # ILMN_1651229 0.18835354 0.3693209 0.3938241 0.14767408 # # 可以自行判断是否需要log # exp <- log2(exp + 1) # 大家可以看到这玩意儿不是探针,那咱们怎么办呢! 接下来我们进行非芯片数据的ID转换!
在你的GEO数据集的主页,可以看见下面这个红框框的地方!这里代表测序平台(咱们后面会在超详细介绍GEO数据库的时候给大家进行介绍这部分内容),直接点进去就好!

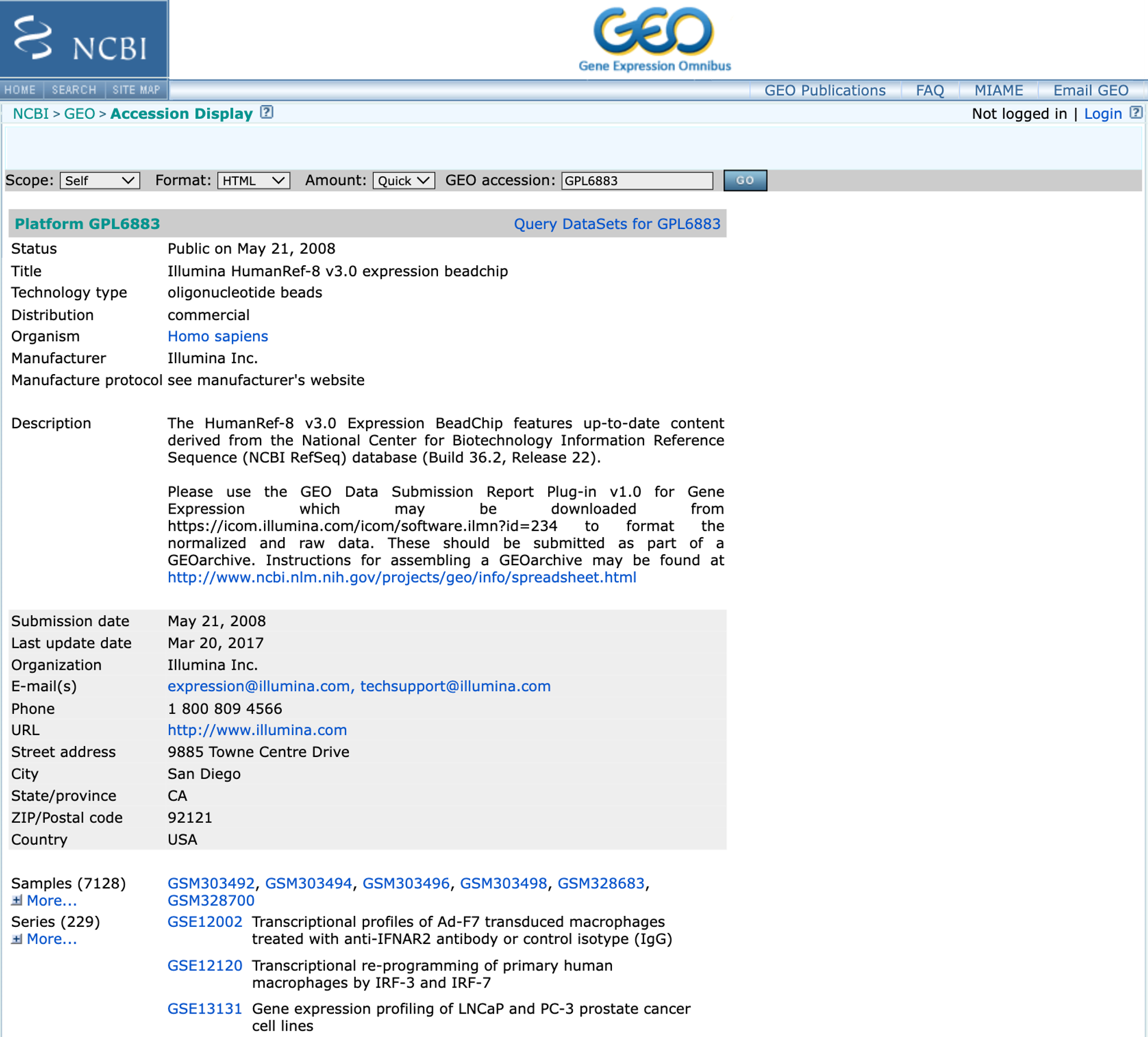
长这样!别急!往下滑滑!
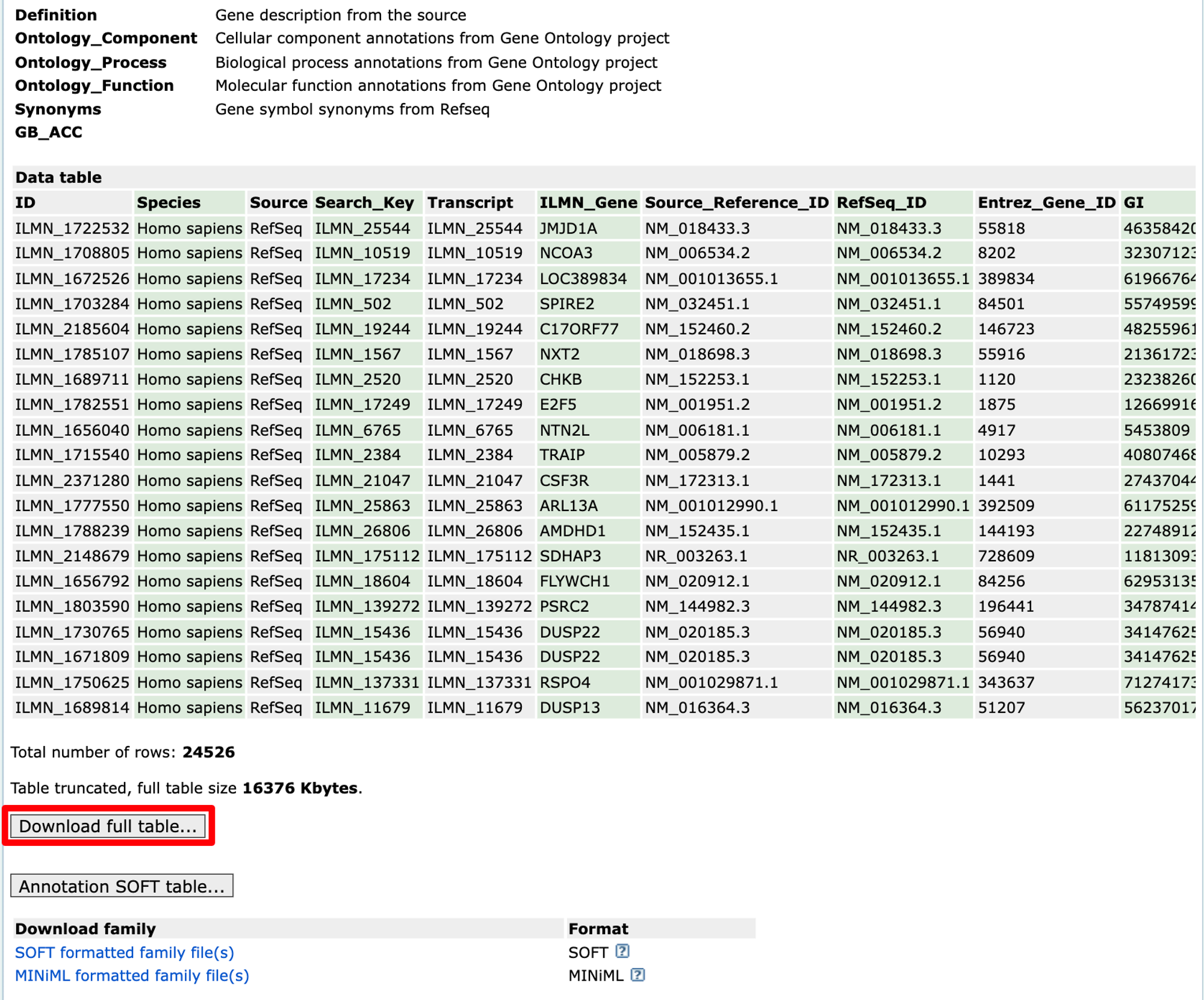
哎对!就是这里!点红框框的地方!下载下来!
来!咱们继续看看怎么搞!
# 文件下载地址:https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL6883 ids <- data.table::fread("./GPL6883-11606.txt") # ID转换 exp <- as.data.frame(exp) exp$ID <- rownames(exp) ids <- ids[ , c(1,12)] # 注意:这里选择的是与表达矩阵行名相匹配的列和基因symbol列 exp <- inner_join(ids, exp, by = "ID") exp <- exp[!duplicated(exp$Symbol), ] exp <- as.data.frame(exp) rownames(exp) <- exp$Symbol exp <- exp[ , -c(1,2)] head(exp)[1:4 ,1:4] # GSM416528 GSM416529 GSM416530 GSM416531 # JMJD1A -0.401840200 -0.2110777 -0.42790460 -0.4261866 # NCOA3 0.296299930 -0.3155098 -0.01228809 0.5331011 # LOC389834 -0.001213074 0.5300436 0.55930424 0.2009177 # SPIRE2 0.127047540 0.5759945 0.45181800 0.4050984 # 噢啦! # 老步骤! # 提取临床信息 cli <- pData(geo_data0) head(cli)[1:4, 1:6] # title geo_accession status submission_date last_update_date type # GSM416528 3100083_Stroke GSM416528 Public on Jun 01 2010 Jun 11 2009 Jun 11 2009 RNA # GSM416529 3100191_Stroke GSM416529 Public on Jun 01 2010 Jun 11 2009 Jun 11 2009 RNA # GSM416530 3100068_Stroke GSM416530 Public on Jun 01 2010 Jun 11 2009 Jun 11 2009 RNA # GSM416531 3100060_Stroke GSM416531 Public on Jun 01 2010 Jun 11 2009 Jun 11 2009 RNA # 为了后续分析,咱还可以给它进一步调整,使表达矩阵列名和临床信息的行名完全一致 p <- identical(rownames(cli), colnames(exp)) p # [1] TRUE 这回是真的噢啦!
一般使用GEO数据库很可能是多个数据集合并使用,那这个时候,由于数据来源不一样,肯定会有批次效应存在,那大家一定要记得进行批次处理噢!有兴趣的小伙伴们可以查看:数据挖掘 | 批次效应的鉴定与处理 | 附完整代码 + 注释 | 看完不会来揍我
在获取表达矩阵和临床信息后,我们还可以进行生存分析:看完不会来揍我 | 生存分析详解 | 从基础概念到生存曲线绘制 | 代码注释 + 结果解读
还有差异分析:看完还不会来揍/找我 | 差异分析三巨头 —— DESeq2、edgeR 和 limma 包 | 附完整代码 + 注释
还有富集分析:看完还不会来揍我 | GSEA富集分析详解(一)—— 代码实操 | MSigDB数据库介绍 | 附完整代码 + 注释
哎呀,还有好多好多!大家需要什么,都可以随时搜索!像这样:
暂时还没有的,也可以催更我!!!
文末碎碎念
那今天的分享就到这里啦!我们下期再见哟!
最后顺便给自己推荐一下嘿嘿嘿!
如果我的分享对你有用的话,欢迎关注点赞在看转发分享阿巴阿巴阿巴阿巴巴巴!这可是我的第一原动力!
蟹蟹你们的喜欢和支持!!!
如果小伙伴们有需求的话,可以加入我们的交流群:一定要知道 | 永久免费的生信交流群终于来啦!!在这里,你可以稍有克制地畅所欲言!
超级建议大家在入群前或入群后可以看一下这个:干货满满 | 给生信小白的入门小建议 | 掏心掏肺版!绝对干货满满!让你不虚此看!
如果有需要个性化定制分析服务的小伙伴,可以看看这里:你要的个性化生信分析服务今天正式开启啦!定制你的专属解决方案!全程1v1答疑!!绝对包你满意!
入群链接后续可能会不定期更新,主要是因为群满换码或是其他原因,如果小伙伴点开它之后发现,咦,怎么失效啦!不要慌!咱们辛苦一下动动小手去主页的要咨询那里,点击进交流群即可入群!

