
阅读量:0
了解WAV文件格式
WAV是一种波形音频文件格式(Waveform Audio File Format)。虽然是一种古老的格式(九十年代初开发),但今天仍然可以看到这种文件。
WAV具有简单、可移植、高保真等特点。
WAV的波形
声音是一种波,可以用3个属性描述:
- 振幅(Amplitude) 表示声波强度,可视为响度。
- 频率(Frequency),波长的倒数,对应音高。
- 相位(Phase)波开始时对应波周期中的位置。
如果你用音频软件(如Audacity)打开WAV文件,可能看到这样的波形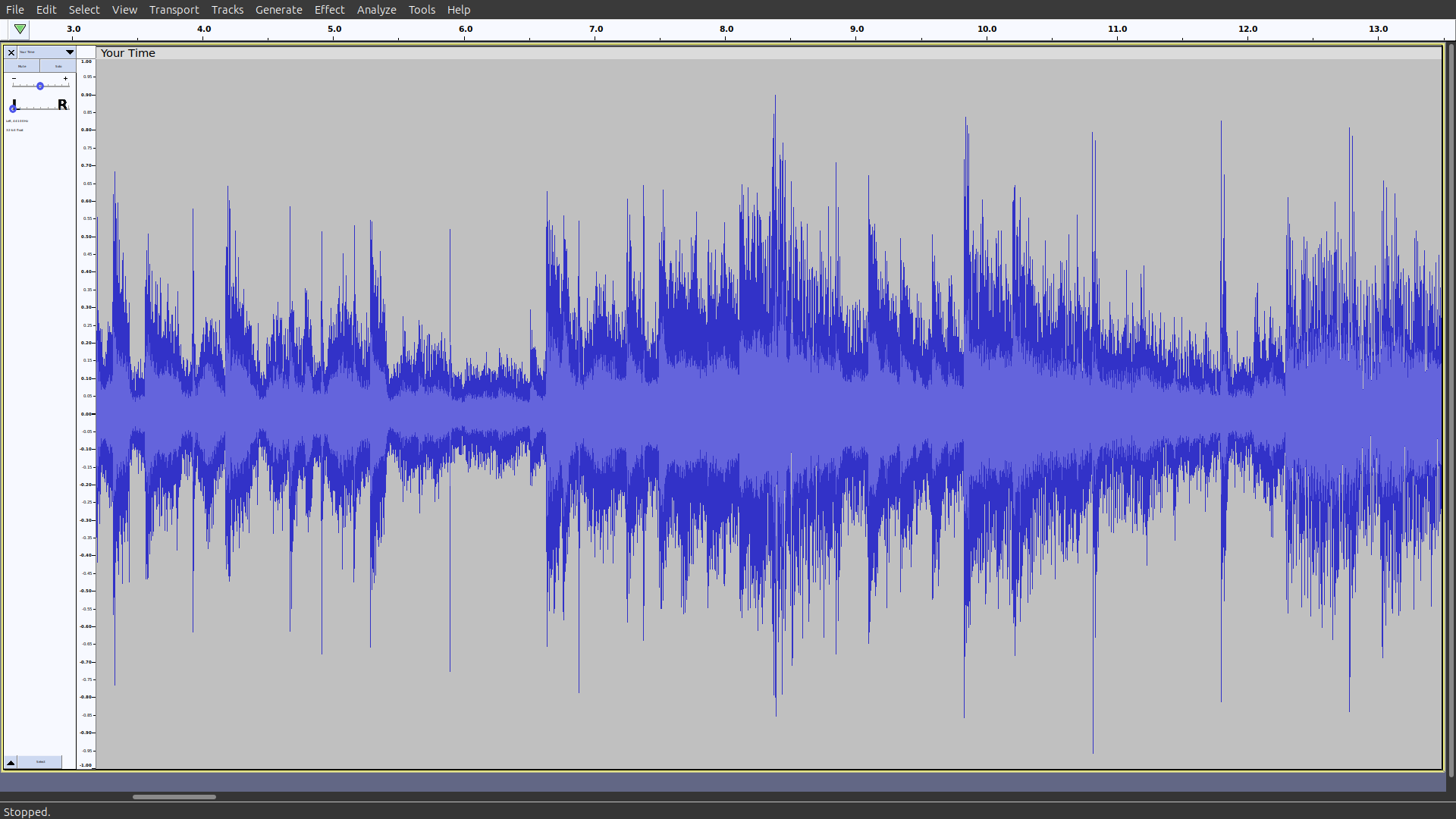
WAV 文件的结构
WAV 音频文件格式是一种二进制格式,结构如下:
Header 是一组元数据,描述了如何解释接下来的Frame。
Header中的参数说明:
- Encoding:编码。样音频信号的数字表示。可用的编码类型包括未压缩的线性脉冲编码调制 (PCM) 和一些压缩格式,如 ADPCM、A-Law 或 μ-Law。
- Channels:声道数。每帧中的声道数,对于单声道,通常等于 1 个,对于立体声音轨,通常等于 2 个,但对于环绕声录音,可能会更多。
- Frame Rate:帧速率。也称采样率。
- Bit Depth:位深度,每个音的比特位数。位深度越大,编码信号的动态范围越大,越能表现声音的细微差别。
为了忠实地表现音乐,大多数 WAV 文件使用立体声 PCM 编码,其中 16 位有符号整数以 44.1 kHz 采样。这些参数对应于标准 CD 质量的音频。巧合的是,这样的采样频率大约是大多数人能听到的最高频率的两倍。根据 Nyquist-Shannon 采样定理,这足以以数字形式捕获声音而不会失真。
Python的wave模块
wave 模块负责读取和写入 WAV 文件(但不能播放声音)。
使用wave.open 读取wav文件将返回一个 wave.Wave_read object。
import wave with wave.open("Bongo_sound.wav") as wav_file: print(wav_file) 可以使用该对象检索存储在 WAV 文件Header信息并读取编码的音频帧:
>>> with wave.open("Bongo_sound.wav") as wav_file: ... metadata = wav_file.getparams() # header ... frames = wav_file.readframes(metadata.nframes) # frame ... >>> metadata _wave_params( nchannels=1, sampwidth=2, framerate=44100, nframes=212419, comptype='NONE', compname='not compressed' ) >>> frames b'\x01\x00\xfe\xff\x02\x00\xfe\xff\x01\x00\x01\x00\xfe\xff\x02\x00...' >>> len(frames) 424838 读取的帧是原始比特(bytes),我们需要手动解码。从Header中我们看到,每个音占2个字节(16位)。
我们可以用array模块:
>>> import array >>> pcm_samples = array.array("h", frames) >>> len(pcm_samples) 212419 或者使用struct模块:
>>> import struct >>> format_string = "<" + "h" * (len(frames) // 2) >>> pcm_samples = struct.unpack(format_string, frames) >>> len(pcm_samples) 212419 <符号指示字节为小端格式(little-endian)。
numpy提供了更简单的方法:
>>> import numpy as np >>> pcm_samples = np.frombuffer(frames, dtype="<h") >>> normalized_amplitudes = pcm_samples / (2 ** 15) numpy简洁高效,后面都使用numpy进行处理。
写WAV文件
从数学上讲,您可以将任何复杂声音表示为多个不同频率、振幅和相位的正弦波的总和。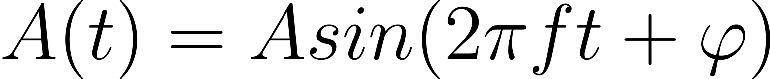
由于振幅A被缩放到[-1,1]之间,并且我们不关心相位,因此正弦波可以简化为:
import math FRAMES_PER_SECOND = 44100 def sound_wave(frequency, num_seconds): for frame in range(round(num_seconds * FRAMES_PER_SECOND)): time = frame / FRAMES_PER_SECOND amplitude = math.sin(2 * math.pi * frequency * time) yield round((amplitude + 1) / 2 * 255) 现在,我们可以生成声音了。
下面我们生成一个频率为440Hz、持续2.5s的声音:
import math import wave ... with wave.open("output.wav", mode="wb") as wav_file: wav_file.setnchannels(1) wav_file.setsampwidth(1) wav_file.setframerate(FRAMES_PER_SECOND) wav_file.writeframes(bytes(sound_wave(440, 2.5))) 使用声音软件打开生成的文件,听到嘟的一声。
混合和立体声
为了合成立体声,
我们需要制造左右两个声道的声音,并在每一帧交替播放。
import itertools import math import wave FRAMES_PER_SECOND = 44100 def sound_wave(frequency, num_seconds): for frame in range(round(num_seconds * FRAMES_PER_SECOND)): time = frame / FRAMES_PER_SECOND amplitude = math.sin(2 * math.pi * frequency * time) yield round((amplitude + 1) / 2 * 255) left_channel = sound_wave(440, 2.5) right_channel = sound_wave(480, 2.5) # 交替播放 两个声道 stereo_frames = itertools.chain(*zip(left_channel, right_channel)) with wave.open("output.wav", mode="wb") as wav_file: wav_file.setnchannels(2) # 2 channel wav_file.setsampwidth(1) wav_file.setframerate(FRAMES_PER_SECOND) wav_file.writeframes(bytes(stereo_frames)) 或者,与其为声波分配单独的声道,不如将它们混合在一起以创建有趣的效果。
混合两种声音的效果等同于将两个声音的振幅相加:
import math import wave FRAMES_PER_SECOND = 44100 def beat(frequency1, frequency2, num_seconds): for frame in range(round(num_seconds * FRAMES_PER_SECOND)): time = frame / FRAMES_PER_SECOND amplitude1 = math.sin(2 * math.pi * frequency1 * time) amplitude2 = math.sin(2 * math.pi * frequency2 * time) amplitude = max(-1, min(amplitude1 + amplitude2, 1)) yield round((amplitude + 1) / 2 * 255) with wave.open("output.wav", mode="wb") as wav_file: wav_file.setnchannels(1) wav_file.setsampwidth(1) wav_file.setframerate(FRAMES_PER_SECOND) wav_file.writeframes(bytes(beat(440, 441, 2.5))) 使用更高的位深度
到目前为止,您一直使用单个字节(8位)来表示每个音频样本,以保持简单。这为您提供了 256 个不同的振幅级别,足以满足您的需求。但是,您迟早会希望提高位深度,以实现更大的动态范围和更好的音质。
切换到更高的位深度时,必须相应地调整缩放和字节转换。您可以使用 NumPy 优雅地表达声波方程并有效地处理字节转换:
import numpy as np import wave FRAMES_PER_SECOND = 44100 def sound_wave(frequency, num_seconds): time = np.arange(0, num_seconds, 1 / FRAMES_PER_SECOND) amplitude = np.sin(2 * np.pi * frequency * time) return np.clip( np.round(amplitude * 32768), -32768, 32767, ).astype("<h") left_channel = sound_wave(440, 2.5) right_channel = sound_wave(480, 2.5) stereo_frames = np.dstack((left_channel, right_channel)).flatten() with wave.open("output.wav", mode="wb") as wav_file: wav_file.setnchannels(2) wav_file.setsampwidth(2) # 2 bytes == 16 bits wav_file.setframerate(FRAMES_PER_SECOND) wav_file.writeframes(stereo_frames) 