
阅读量:2
目录
本文主要介绍SAM模型的使用方法:如何使用不同的提示进行目标分割。而且该模型在CPU的环境下就可以快速运行,真心不错~,赶紧来试试吧
关于Segment-Anything模型的相关代码、论文PDF、预训练模型、使用方法等,我都已打包好,供需要的小伙伴交流研究,获取方式如下:
关注文末名片GZH:阿旭算法与机器学习,回复:【SAM】即可获取SAM相关代码、论文、预训练模型、使用方法文档等
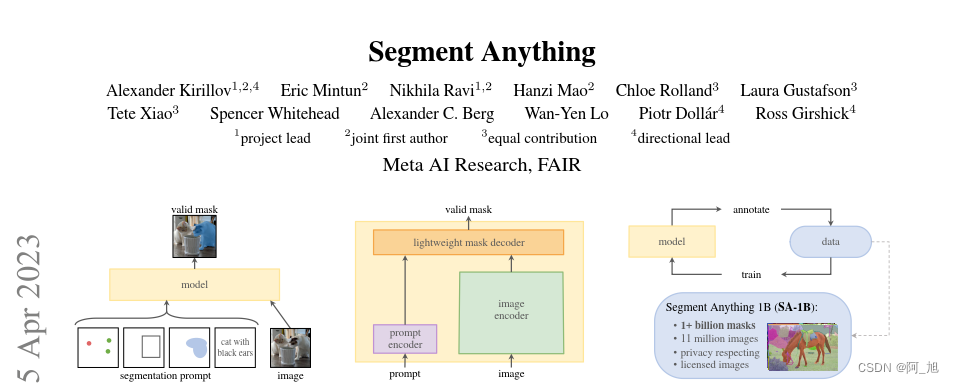
前言
最近GPT一直都被炒的火热,没想到这么快就见到了CV的大模型,而且拥有新数据集+新范式+超强零样本泛化能力。
虽然此次出现的CV大模型没有NLP中的GPT那么强大的效果:用一个模型就可以处理N多下游任务。但这也是一个很好的开始,也应该是CV未来的发展趋势。
SAM(Segment-Anything Model)的出现统一了分割这个任务(CV任务的一个子集)的下流应用,说明了CV的大模型是可能存在的。其肯定会对CV的研究带来巨大的变革,很多任务会被统一处理,可能再过不久,检测、分割和追踪也会被all in one了。
项目地址:https://github.com/facebookresearch/segment-anything
Demo:https://segment-anything.com/
安装运行环境
运行需要python>=3.8, 以及pytorch>=1.7和torchvision>=0.8。
安装依赖库:
pip install git+https://github.com/facebookresearch/segment-anything.git SAM模型的使用方法
导入相关库并定义显示函数
下面导入了运行所需的第三方库,以及定义了用于展示点、方框以及分割目标的函数。
import numpy as np import torch import matplotlib.pyplot as plt import cv2 def show_mask(mask, ax, random_color=False): if random_color: color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0) else: color = np.array([30/255, 144/255, 255/255, 0.6]) h, w = mask.shape[-2:] mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1) ax.imshow(mask_image) def show_points(coords, labels, ax, marker_size=375): pos_points = coords[labels==1] neg_points = coords[labels==0] ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25) ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25) def show_box(box, ax): x0, y0 = box[0], box[1] w, h = box[2] - box[0], box[3] - box[1] ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0,0,0,0), lw=2)) 导入待分割图片
image = cv2.imread('images/truck.jpg') image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) plt.figure(figsize=(10,10)) plt.imshow(image) plt.axis('on') plt.show() 
使用不同提示方法进行目标分割
首先,加载SAM预训练模型。【文末已将所有文件打包,感兴趣的小伙伴可自行获取】
import sys sys.path.append("..") from segment_anything import sam_model_registry, SamPredictor sam_checkpoint = "./models/sam_vit_b_01ec64.pth" model_type = "vit_b" device = "cpu" # or "cuda" sam = sam_model_registry[model_type](checkpoint=sam_checkpoint) sam.to(device=device) predictor = SamPredictor(sam) 通过调用SamPredictor.set_image函数,将输入的图像进行编码,SamPredictor 会使用这些编码进行后续的目标分割任务。
predictor.set_image(image) 在上图车的图片上,选择一个点。点的输入格式为(x, y)和并表示出点所带有的标签1(前景点)或0(背景点)。可以输入多个点,在这里我们先只用一个点,选择的点会显示为一个五角星的标记。
方法一:使用单个提示点进行目标分割
input_point = np.array([[500, 375]]) # 标记点 input_label = np.array([1]) # 点所对应的标签 plt.figure(figsize=(10,10)) plt.imshow(image) show_points(input_point, input_label, plt.gca()) plt.axis('on') plt.show() 
用 SamPredictor.predict进行分割,模型会返回这些分割目标对应的置信度。
masks, scores, logits = predictor.predict( point_coords=input_point, point_labels=input_label, multimask_output=True, ) 参数说明:
point_coords: 提示的坐标点位置
point_labels: 提示点对应的类型,1前景,0背景
boxes: 提示的方框
multimask_output: 多目标输出还是但目标输出True or False
multimask_output=True (默认),SAM模型会输出3个分割目标和对应的置信度scores。这个设置主要是用于面对歧义的提示点,因为一个提示点可能在多个分割的目标内部,multimask_output=True 能够将包含该提示点的所有目标都分割出来。
如下面示例所示:2种车窗户、还有整个车均包含了五角星的提示点。
masks.shape # (number_of_masks) x H x W (3, 1200, 1800) for i, (mask, score) in enumerate(zip(masks, scores)): plt.figure(figsize=(10,10)) plt.imshow(image) show_mask(mask, plt.gca()) show_points(input_point, input_label, plt.gca()) plt.title(f"Mask {i+1}, Score: {score:.3f}", fontsize=18) plt.axis('off') plt.show() 


方法二:使用多个提示点进行目标分割
单个提示点通常会存在歧义的影响,因为可能多个目标均包含该点。为了得到我们想要的单个目标,我们可以在目标上进行多个点的提示,以获取该目标的分割结果。
例如下面在卡车上用2个提示点,从而直接提取出整个车的分割结果,而不是窗户。这是需要设置multimask_output=False,用于提取单个目标分割结果。
input_point = np.array([[500, 375], [1125, 625]]) input_label = np.array([1, 1]) mask_input = logits[np.argmax(scores), :, :] # Choose the model's best mask masks, _, _ = predictor.predict( point_coords=input_point, point_labels=input_label, mask_input=mask_input[None, :, :], multimask_output=False, ) masks.shape (1, 1200, 1800) plt.figure(figsize=(10,10)) plt.imshow(image) show_mask(masks, plt.gca()) show_points(input_point, input_label, plt.gca()) plt.axis('off') plt.show() 
如果我们仅想得到窗户的分割结果,我们可以使用背景点(label=0,下图红的五角星)将车子的其他部分剔除掉。
input_point = np.array([[500, 375], [1125, 625]]) input_label = np.array([1, 0]) mask_input = logits[np.argmax(scores), :, :] # Choose the model's best mask masks, _, _ = predictor.predict( point_coords=input_point, point_labels=input_label, mask_input=mask_input[None, :, :], multimask_output=False, ) plt.figure(figsize=(10, 10)) plt.imshow(image) show_mask(masks, plt.gca()) show_points(input_point, input_label, plt.gca()) plt.axis('off') plt.show() 
方法三:用方框指定一个目标进行分割
SAM模型可以用一个方框作为输入,格式为[x1,y1,x2,y2]。来进行单个目标的分割,如下面所示,通过方框对车的轮子进行分割。
input_box = np.array([425, 600, 700, 875]) masks, _, _ = predictor.predict( point_coords=None, point_labels=None, box=input_box[None, :], multimask_output=False, ) plt.figure(figsize=(10, 10)) plt.imshow(image) show_mask(masks[0], plt.gca()) show_box(input_box, plt.gca()) plt.axis('off') plt.show() 
方式四:将点与方框结合,进行目标分割
如下示例:将轮胎的中心轮毂部分剔除,仅得到轮胎外部。
方框用于得到轮胎;点标记为背景(input_label = np.array([0])),起到剔除作用。
input_box = np.array([425, 600, 700, 875]) input_point = np.array([[575, 750]]) input_label = np.array([0]) masks, _, _ = predictor.predict( point_coords=input_point, point_labels=input_label, box=input_box, multimask_output=False, ) plt.figure(figsize=(10, 10)) plt.imshow(image) show_mask(masks[0], plt.gca()) show_box(input_box, plt.gca()) show_points(input_point, input_label, plt.gca()) plt.axis('off') plt.show() 
方法五:多个方框同时输入,进行多目标分割
通过同时输入多个方框,可用于分割不同方框中的目标。下面是对车的不同目标的分割效果。
input_boxes = torch.tensor([ [75, 275, 1725, 850], [425, 600, 700, 875], [1375, 550, 1650, 800], [1240, 675, 1400, 750], ], device=predictor.device) transformed_boxes = predictor.transform.apply_boxes_torch(input_boxes, image.shape[:2]) masks, _, _ = predictor.predict_torch( point_coords=None, point_labels=None, boxes=transformed_boxes, multimask_output=False, ) masks.shape # (batch_size) x (num_predicted_masks_per_input) x H x W torch.Size([4, 1, 1200, 1800]) plt.figure(figsize=(10, 10)) plt.imshow(image) for mask in masks: show_mask(mask.cpu().numpy(), plt.gca(), random_color=True) for box in input_boxes: show_box(box.cpu().numpy(), plt.gca()) plt.axis('off') plt.show() 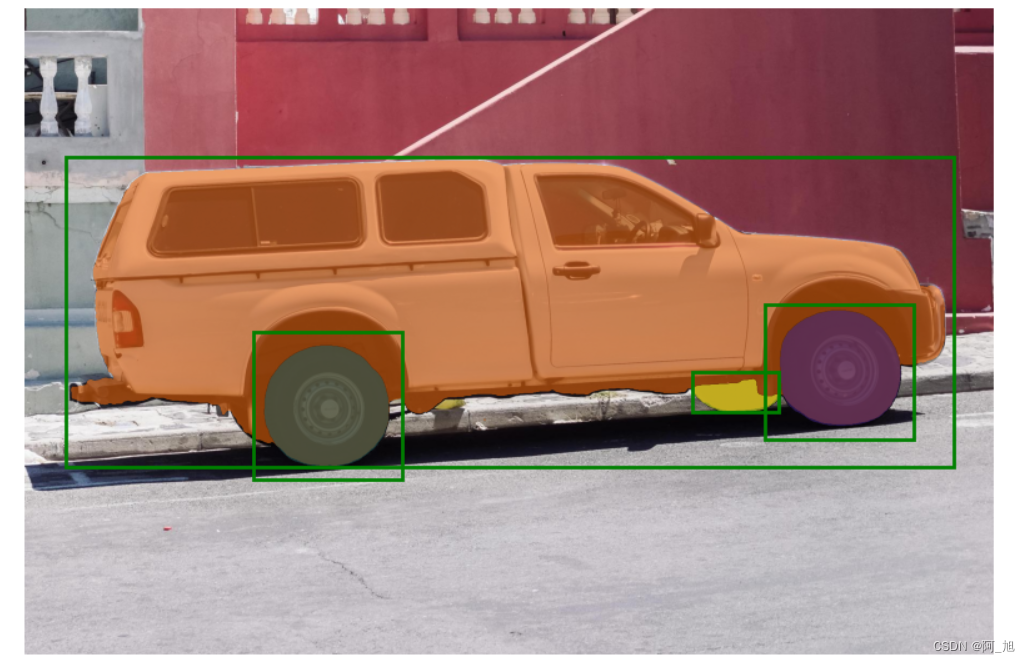
总结
以上便是SAM模型的使用方法,可以通过不同的提示方式得到不同的分割结果。总体来说,效果还是很不错的,关键是居然还可以在CPU环境下快速运行。感兴趣的小伙伴,也可以自己试试哦~
如果文章对你有帮助,感谢点赞+关注!
关注下方名片GZH:阿旭算法与机器学习,回复:【SAM】即可获取SAM相关代码、论文、预训练模型、使用方法文档等,欢迎共同学习交流
