
阅读量:1
DexIL:面向双臂灵巧手柔性操作的端到端具身执行模型
模型架构
输入:
观测Ot: RGB点云,使用PointNet进行编码;
状态St: 双臂末端7x2Dof位姿+16x2灵巧手关节位置,只进行归一化,无编码;
融合方式: 直接和点云特征进行concatenate组合。
输出: 未来d个时刻的动作(物理量与状态一样)
噪声预测网络: Unet
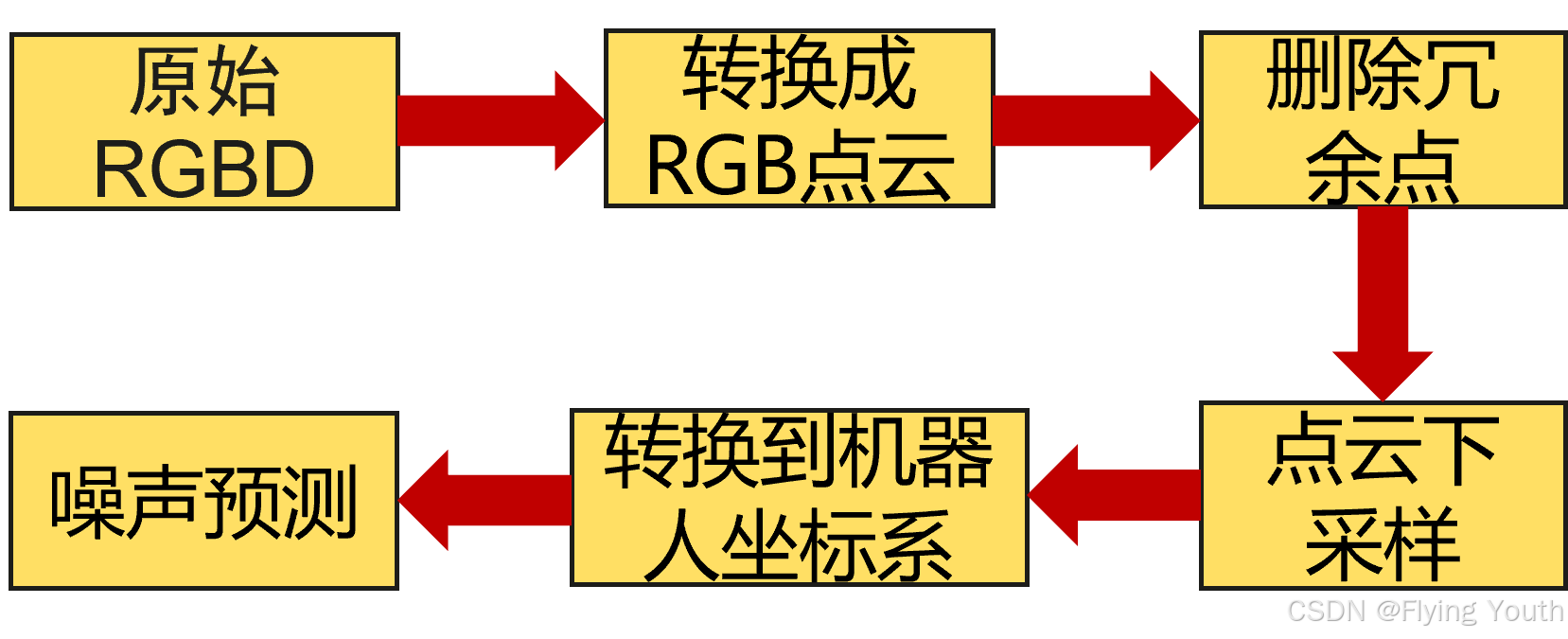
训练方式: Diffusion DDIM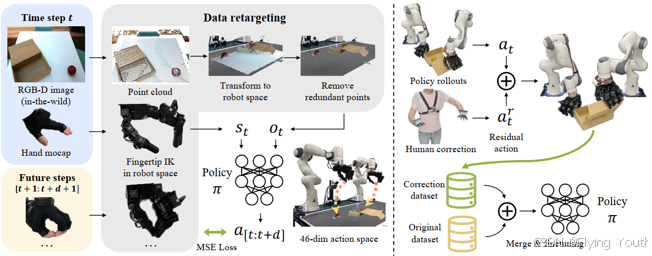
演示demo
dexil
实验
3D Diffuser Actor:基于3D感知引导的多任务具身执行大模型
摘要
我们把扩散策略和 3D 场景表示用在了机器人操作上。扩散策略通过条件扩散模型来学习基于机器人以及环境状态的动作分布。最近,它们被证明表现比确定性的还有其他基于状态条件的动作分布学习方法都要好。3D 机器人策略利用从单个或者多个摄像头视图通过感知深度聚合而来的 3D 场景特征表示。已经表明,在不同摄像头视角下,它们比 2D 的同类策略泛化能力更强。我们把这两方面的工作整合到一起,推出了 3D 扩散器执行者,这是一种神经策略架构,给它一个语言指令,它就能构建出视觉场景的 3D 表示,然后以此为条件,不断对机器人末端执行器的 3D 旋转和平移进行去噪。每次去噪迭代的时候,我们的模型把末端执行器的姿态估计表示成 3D 场景标记,并且通过用 3D 相对注意力对其他 3D 视觉和语言标记进行特征提取,来预测每个标记的 3D 平移和旋转误差。3D 扩散器执行者在 RLBench 上达到了新的顶尖水平,在多视图设置下比当前最顶尖水平的绝对性能提高了 16.3%,在单视图设置下提高了 13.1%。在 CALVIN 基准测试中,在零样本未见场景泛化的设置里,它和当前最顶尖水平相当。它在现实世界中,从少量的演示里也能发挥作用。我们对模型的架构设计选择做了消融研究,像 3D 场景特征化和 3D 相对注意力,结果表明这些都有助于泛化。我们的结果显示,3D 场景表示和强大的生成模型是从演示中让机器人高效学习的关键。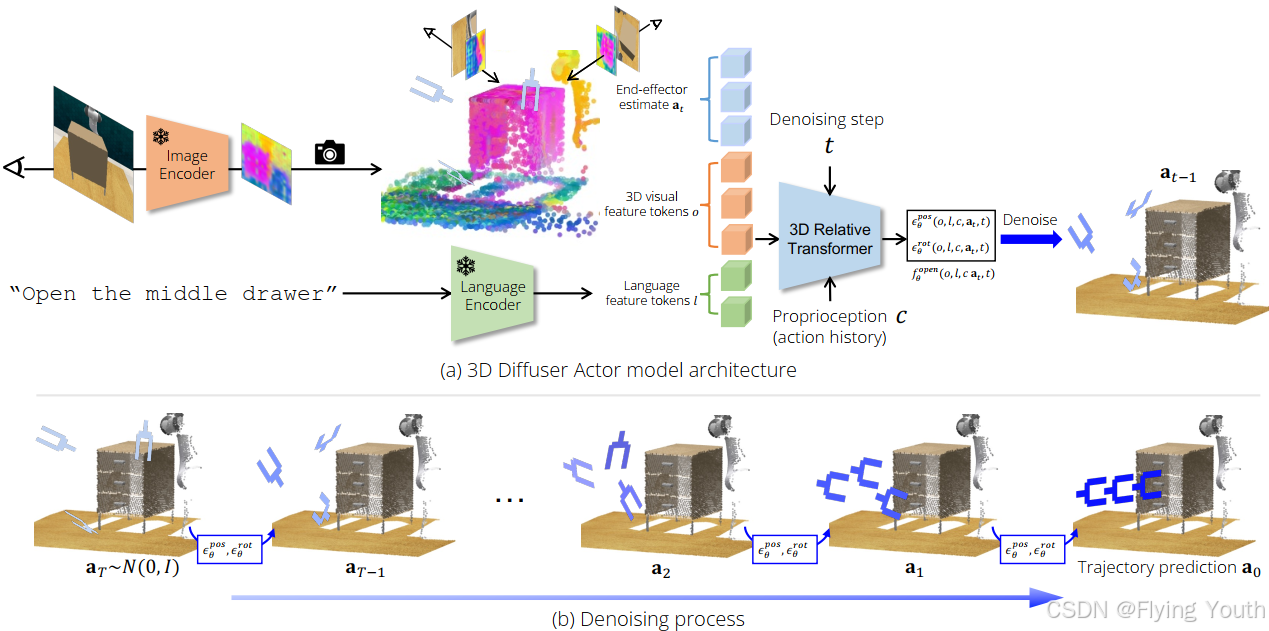
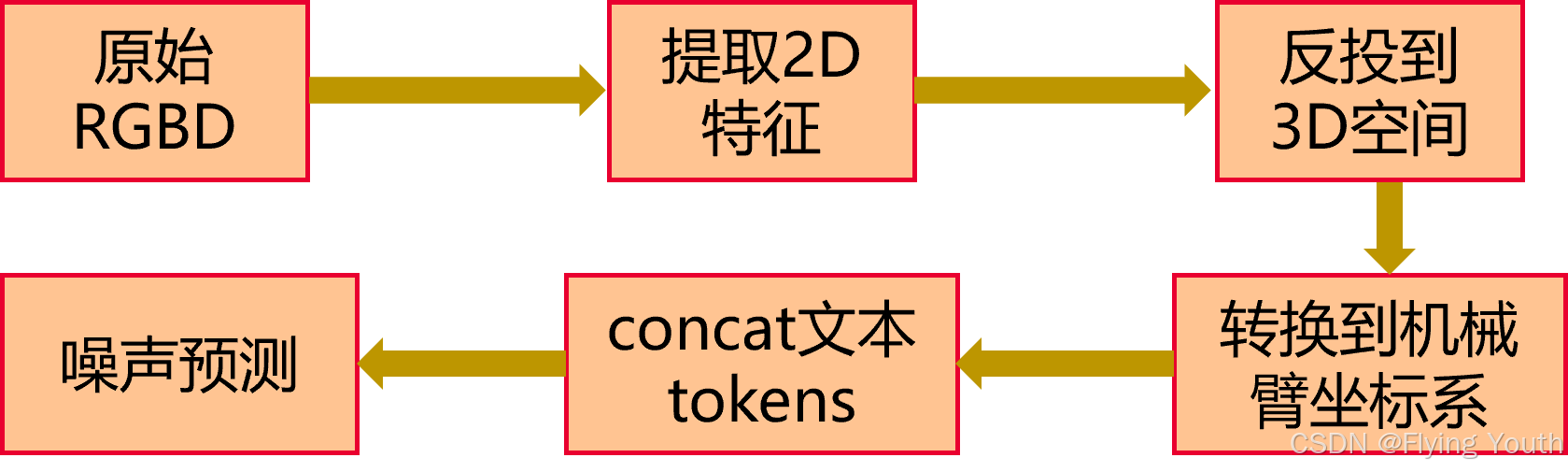
模型架构
输入:
图像编码器: CLIP ResNet50 2D image encoder
文本编码器: CLIP language encoder
自 身 信 息: 机械臂末端位姿
输 出 动 作: 末端位姿(6D旋转+3D位置)+1D夹爪闭合,可预测全部轨迹点,或者关键位姿。
关键位姿: 重要的中间末端位姿,可以表征轨迹,可以使用一些简单的启发来提取,比如夹爪开闭或者局部速度、加速度极值处。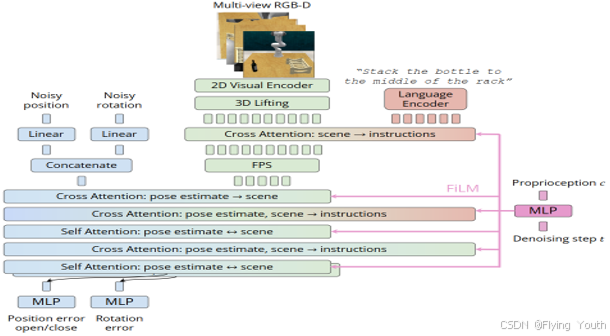
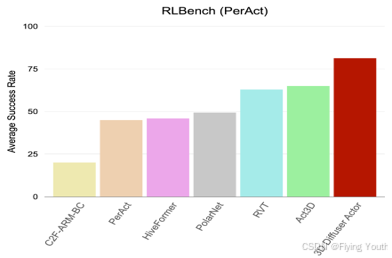
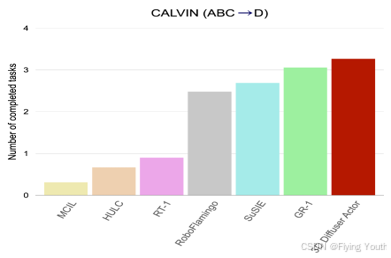
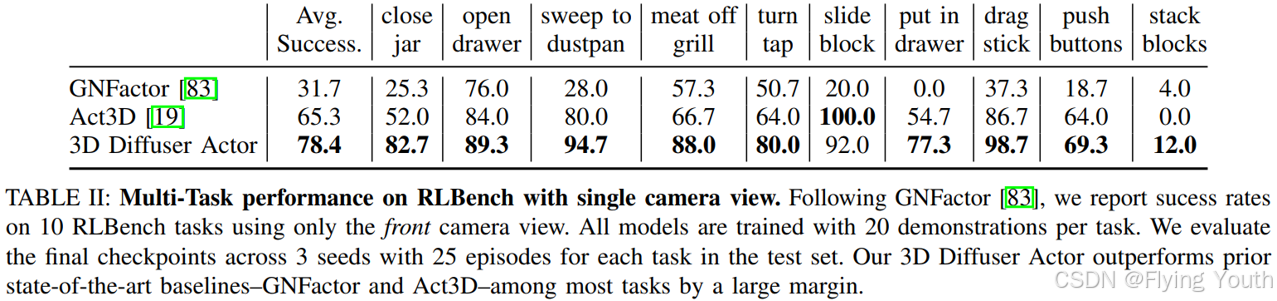
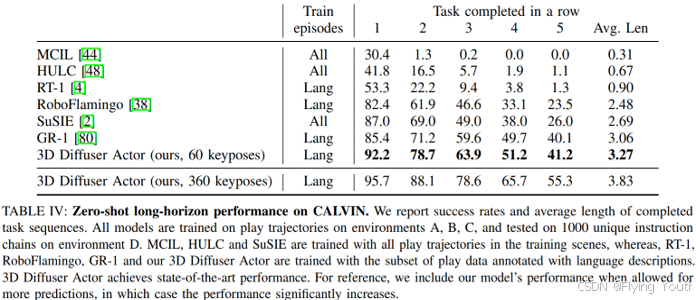
实验(在RLBench和Calvin Benchmark上达到SOTA)

3D Diffusion Policy:通过简单的3D表示进行通用的视觉运动策略学习
摘要
解决的问题: 如何使得模仿学习可以仅使用少量数据来学习鲁棒泛化的技能?
3DP相较2DP的优点:
- 高效与有效性。DP3不仅具有更高的精度,而且在示例数量和训练步骤上显著减少。
- 泛化能力。DP3的3D特性使其在多个方面具有泛化能力:空间、视角、实例和外观。
- 安全部署。我们在现实世界实验中观察到的一个有趣的现象是,DP3在实际任务中很少给出不稳定的命令,而基准2D方法却经常这样做,并表现出意想不到的行为,可能对机器人硬件造成潜在的损坏。
主要贡献:
- 我们提出了一种名为3D扩散策略(DP3)的有效视觉运动策略,可以在很少的示例下泛化到各种不同的方面。
- 为了减少基准和任务带来的方差,我们在广泛的模拟和真实世界任务中评估DP3,展示了DP3的通用性。
- 我们对DP3的视觉表征表示进行了全面分析,并发现一个简单的点云表示优于其他复杂的3D表示,更适合扩散策略而不是其他政策基线。
- 仅使用40个示例,DP3就能使用灵巧的手对具有可变形物体进行现实世界操作,这表明只需少量的人类数据就可以处理复杂的高维任务。
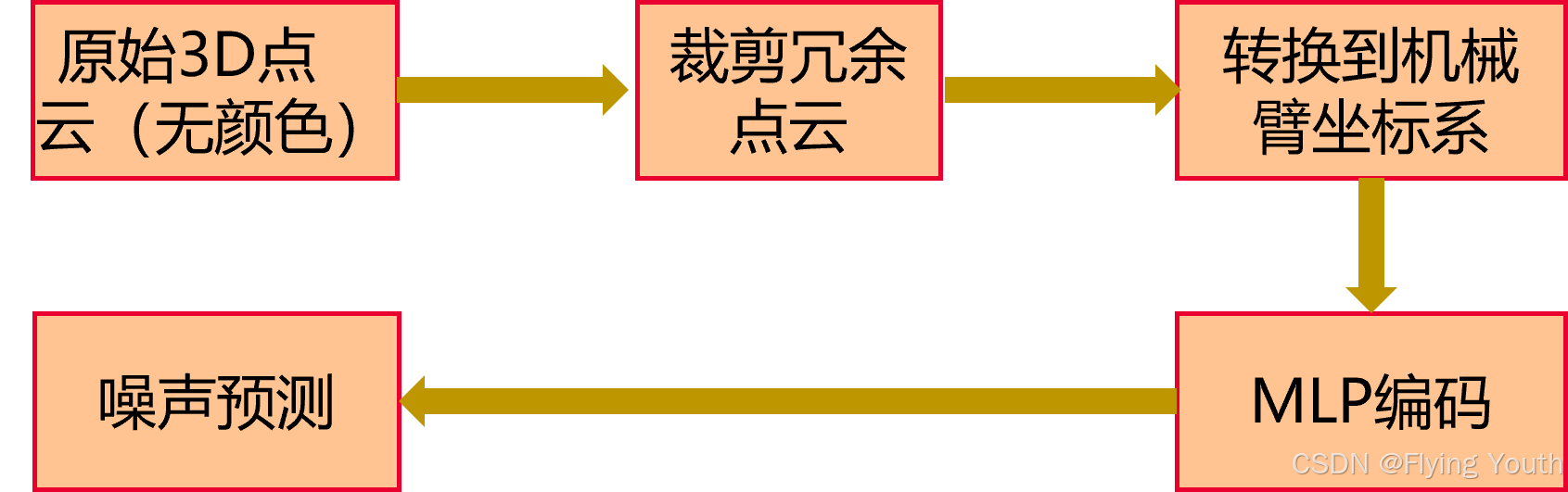
模型架构
输入:
点云编码器: MLP
自 身 信 息: 机械臂末端位姿,无编码
输 出 动 作: 末端位姿(3D旋转+3D位置)+1D夹爪闭合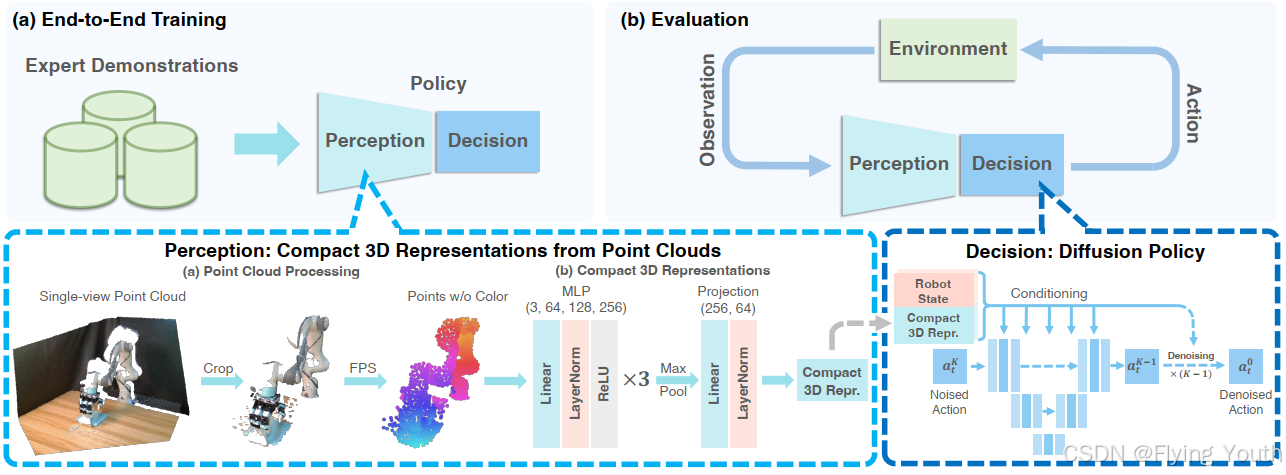
演示demos
实验
实验1:在现实实验中,我们惊讶地发现基于图像和深度的扩散策略在现实实验中往往会表现出不可预测的行为,这需要人类干预来确保机器人的安全。这种情况被称为安全违规。有趣的是,在我们的实验中,DP3很少违反安全规定,这表明DP3是一种适用于真实机器人学习的实用且硬件友好的方法。

实验2: DP3可以更好地在3D空间中进行插值泛化。实际测试发现基线不能推广到所有的测试位置,而DP3在5次试验中有4次成功。
实验3:DP3设计用于处理没有颜色信息的点云,固有地使其能够有效地泛化各种外观。如下所示,DP3始终显示出对不同颜色的立方体的成功泛化,而基线方法无法实现。值得注意的是,基于深度的扩散策略也没有将颜色作为输入。然而,由于其对训练对象的精度较低,泛化能力也受到限制

实验4:在不同的实例之间实现泛化,这些实例在形状、大小和外观上都不同,与单纯的外观泛化相比,提出了更大的挑战。如下所示,DP3可以有效地操作各种日常对象。这一成功主要归因于点云的固有特性,具体地说,点云的使用使得policy更鲁棒,特别是当这些点云被下采样时。

实验5:将基于图像的方法推广到不同视角是一个具有挑战性的问题,从多个视角获取训练数据可能耗时且成本高昂。我们证明,当摄像头视角稍有变化时,DP3可以有效地解决这一泛化问题。

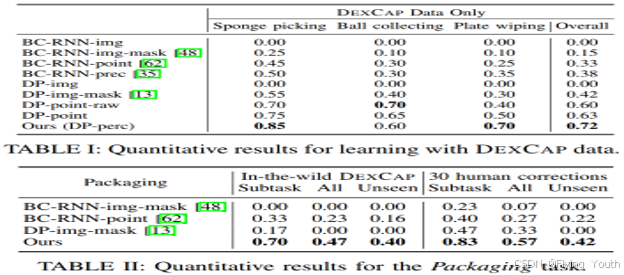
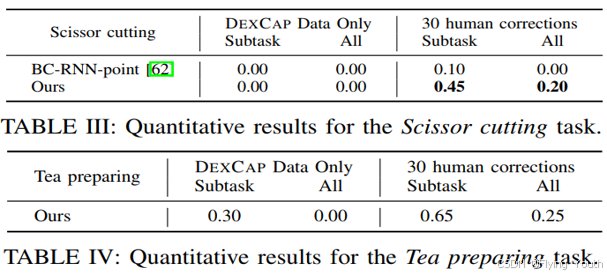
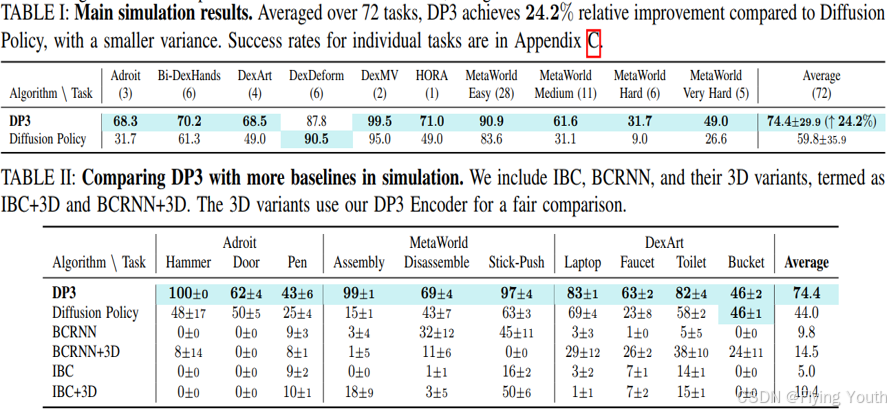
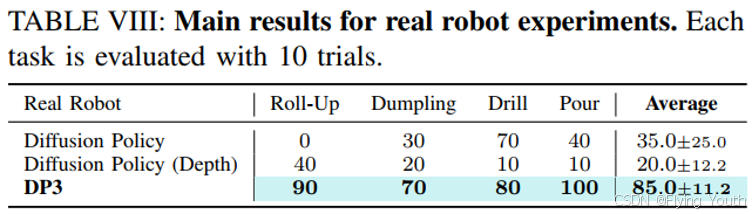
实验6:定量对比实验
实验7:消融实验
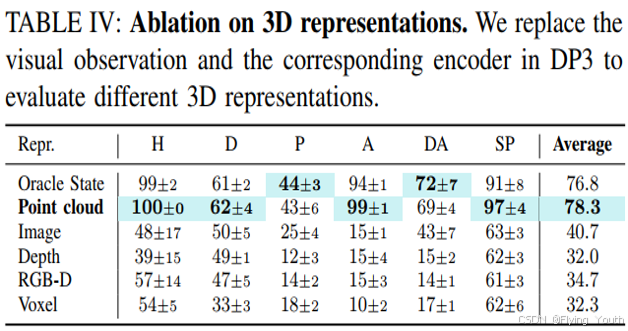
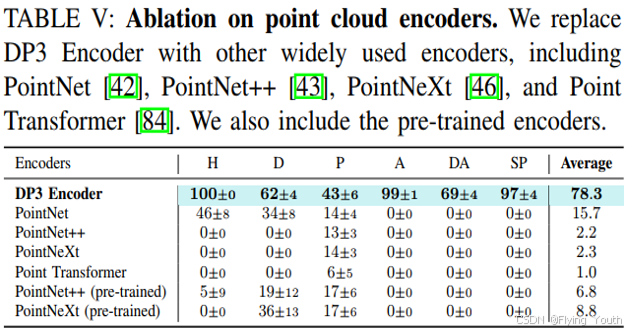
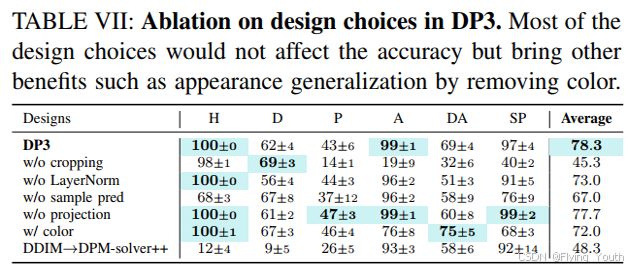
结论分析
- 3D相较2D,能直接提供空间信息,由此带来了对形状、视角等泛化性;
- 3D相较2D对光照颜色的泛化性更好;
- 通过模型设计,3D可以获得位置方向和尺度的泛化性;
- 3D相较2D,学习效率更高: 20 vs 100 ;
- 将3D信息转换到机器人坐标系,有望解决跨本体差异的能力。
