
阅读量:2
3DS-SLAM: A 3D Object Detection based Semantic SLAM towards Dynamic Indoor Environments
摘要: 环境中可变因素的存在可能会导致相机定位精度下降,因为它违反了同步定位与建图(SLAM)算法中静态环境的基本假设。最近针对动态环境的语义 SLAM 系统要么仅依赖于 2D 语义信息,要么仅依赖于几何信息,或者以松散集成的方式组合它们的结果。在这篇研究论文中,介绍了 3DS-SLAM(3D 语义 SLAM),专为具有视觉 3D 对象检测的动态场景而定制。 3DS-SLAM 是一种紧耦合算法,可依次解决语义和几何约束。本文设计了一个 3D 部分感知混合transformer,用于基于点云的对象检测来识别动态对象。随后,提出了一种基于 HDBSCAN 聚类的动态特征过滤器来提取具有显着绝对深度差异的对象。与 ORB-SLAM2 相比,3DS-SLAM 在 TUM RGB-D 数据集的动态序列上平均提高了 98.01%。此外,它超越了其他四种专为动态环境设计的领先 SLAM 系统的性能。
引言:
适用于室内动态环境的 3D 视觉 SLAM 系统。现有的 ORB-SLAM2 由于移动人员的动态特征而失败,导致估计的轨迹无法使用。 3DS-SLAM采用HTx架构进行3D物体检测,并利用HDBSCAN提取动态特征(红点)并提高整体稳定性。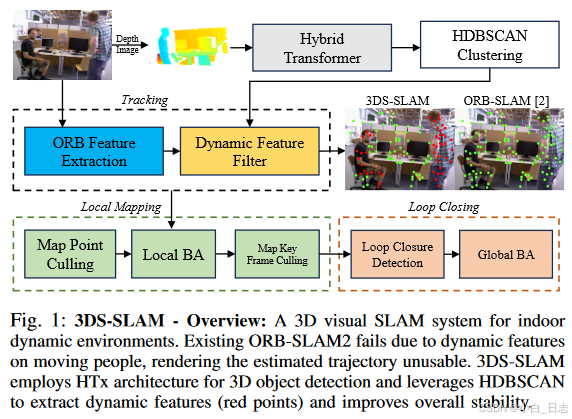
3DS-SLAM 建立在 ORB-SLAM2的基础上,提出了用于语义信息(3D 对象检测)的混合Transformer架构(HTx),并使用 HDBSCAN(基于分层密度的空间聚类)来解决几何约束,HTx 结果如图所示如图 1 所示。在 SLAM 中使用 3D 对象检测而不是 2D 对象检测可以改善空间理解、更好的遮挡处理、准确的尺度估计和增强的运动跟踪功能。
- 贡献:
- 轻量级 3D HTx 对象检测架构集成了本文的视觉 SLAM 系统,可为动态环境提供 3D 语义空间信息。
- 集成HTx 和HDBSCAN 的新型端到端管道,可有效解决语义和几何约束,优化整体性能。
- 实验验证表明,3DS-SLAM 增强了动态场景中的姿态准确性和稳定性,优于现有方法。
方法:
它主要分为三个部分:1.) 3D 对象检测线程。 2.) 动态特征去除线程。 3.) 跟踪、局部建图、局部闭环线程改编自 ORB-SLAM2。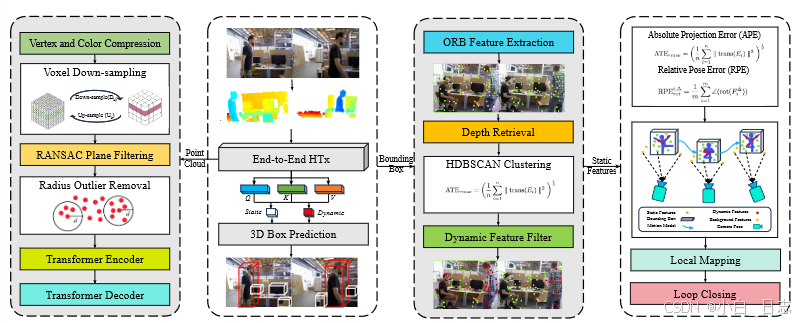
所提出的 3DS-SLAM 通过合并两个附加线程(3D 对象检测和动态特征过滤器)扩展了最初为静态环境设计的 ORB-SLAM2 的功能。这些线程有效地过滤动态点,确保精确的相机轨迹估计。对于语义信息,3D 对象检测线程采用轻量级 HTx 架构,而动态特征过滤线程利用基于几何深度的 HDBSCAN 聚类来区分动态点。该系统利用 HTx 架构从 RGB 和深度图像提取的点云中提取语义信息。
Hybrid Transformer:轻量级 3D 物体探测器
在视觉 SLAM 中,传感器捕获的帧通常表现出不完整的前景物体,这可能会导致物体检测受损。这就需要开发能够意识到这些不完整的对象部分表示的部分对象定位方法。所提出的 HTx 架构将输入作为 3D 点云来预测对象位置,包括对象的深度、方向和位置。我们提出的 HTx 架构是基于(From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network.)的部分感知对象定位和(An end-to-end transformer model for 3d object detection.)的类感知对象定位的构建块而设计的。 HTx 架构在数据层面与现有的 Transformer 架构不同,它结合了点云预处理并利用点和体素特征进行零件感知对象定位。
点云由一组无序的 N 个点组成,每个点都与其 3 维 XYZ 坐标无缝关联。由于与图像相比,它们的计算复杂性增加,因此本研究努力进行广泛的预处理以有效压缩点云。此外,点云固有的排列不变性,加上颜色信息和点法线的包含,也会导致 3D 对象检测的大量计算开销。受先前工作的启发,HTx 架构通过放弃使用颜色和点法线信息进行对象检测来优先考虑实时效率。此外,还执行了重要的数据预处理技术,例如体素下采样、平面滤波、基于半径的异常值去除。

Transformer 架构:3DS-SLAM 采用 3D 对象检测框架,该框架基于 Facebook AI Research的开创性 3DETR 架构构建。本文对该架构进行了重大修改,以增强其与视觉 SLAM 系统的兼容性,特别是通过增强中引入的局部感知对象检测层。这解决了现有视觉 SLAM 系统中的一个关键缺陷,即由于部分可见的物体、相机旋转和其他环境因素,该系统无法解决关键机器人应用中的物体检测问题。由于为部分感知和类感知对象定位设计损失函数的复杂性,开发了两个单独的损失函数。
预测 MLP(多层感知器)生成 3D 边界框 b ^ \hat{b} b^ ,并使用实际框 b 进一步评估。每个预测框 b ^ = [ c ^ , d ^ , a ^ , s ^ ] \hat{b}=[\hat{c},\hat{d},\hat{a},\hat{s}] b^=[c^,d^,a^,s^]ˆ包括 (1) 定义框中心和尺寸的几何元素 c ^ , d ^ ∈ [ 0 , 1 ] 3 , a ^ = [ a ^ c , a ^ r ] \hat{c},\hat{d} ∈ [0, 1]^3,\hat{a}= [\hat{a}_c , \hat{a}_r] c^,d^∈[0,1]3,a^=[a^c,a^r] 表示类别和方向残差,以及 (2) 语义项 s ^ = [ 0 , 1 ] K + 1 \hat{s}= [0, 1]^{K+1} s^=[0,1]K+1 包含 K 个语义对象类和“背景”类的概率分布。我们对中心和框尺寸采用L1 回归损失,对角度残差采用 Huber 回归损失,对角度和语义分类采用交叉熵损失,如下所示: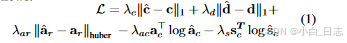
局部对象定位: 我们通过将每个点表示为其在所分配的真实对象的 3D 边界框中的相对位置来定义每个点的对象内部分位置。我们使用三个连续值表示该目标对象内部分位置,表示为 ( x f , y f , z f ) (x^f , y ^f , z^f ) (xf,yf,zf),每个点 ( x p , y p , z p ) (x^p, y^p, z^p) (xp,yp,zp)为: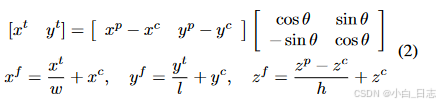
HDBSCAN 聚类和动态特征过滤器
物体检测方法可能无法准确地提供物体遮罩,尤其是在处理占据相机视野大部分的非刚体时。这通常会导致大量背景点云包含在对象的边界框中。为了解决这个问题,文章重点关注人体作为非刚性前景物体 的例子。人类通常表现出深度连续性和与背景的显着深度差异。因此,当人的边界框占据相机视野时,优化原生 HDBSCAN 密度聚类算法,以区分边界框中前景中的点和背景中的点。通过组合浅深度的点组,本文识别前景(动态关键点)。这种自适应方法增强了 HDBSCAN 算法的鲁棒性,并有效处理人被其他物体部分遮挡的情况。此外,与 DBSCAN相比,HDBSCAN 对参数选择更加鲁棒,并且可以有效地处理变化密度的多维数据。
实验
- 3D目标检测和HDBSCAN的性能
3DS-SLAM是针对关键机器人应用而开发的,采用基于点云的混合3D目标检测方法。HTx架构是在SUNRGB-D数据集上训练的,该数据集包含室内环境中的700个标记对象,并考虑到未来在标准工业机器人应用中的影响,如伸手、抓握和拾取和放置。SUNRGB-D中的对象类别数量几乎是YOLO使用的coco数据集中的类别数量的九倍。
HTx架构实现了57.85的mAP25值,与性能最好的3D目标检测模型相当。此外,它与动态特征过滤器的紧密集成增强了SLAM的整体视觉性能。图3(a)-(e)直观地描述了类感知HTx在各种场景中的结果,并将其性能与部分感知对象定位进行了比较(第二行)。
部分感知对象定位显著增强了3DS-SLAM的性能,在TUM RGB-D序列中尤为明显。 3D目标检测结果在所有帧中保持一致的准确性,与现有的缺乏多个帧的漏检测补偿的2D目标检测架构相比,产生了显著更平滑的3DS-SLAM体验。图4表示3DS-SLAM的综合结果,显示了时间连续检测。三维边界框和动态点用红色表示,而静态点用绿色表示。
3D目标检测结果在所有帧中保持一致的准确性,与现有的缺乏多个帧的漏检测补偿的2D目标检测架构相比,产生了显著更平滑的3DS-SLAM体验。图4表示3DS-SLAM的综合结果,显示了时间连续检测。三维边界框和动态点用红色表示,而静态点用绿色表示。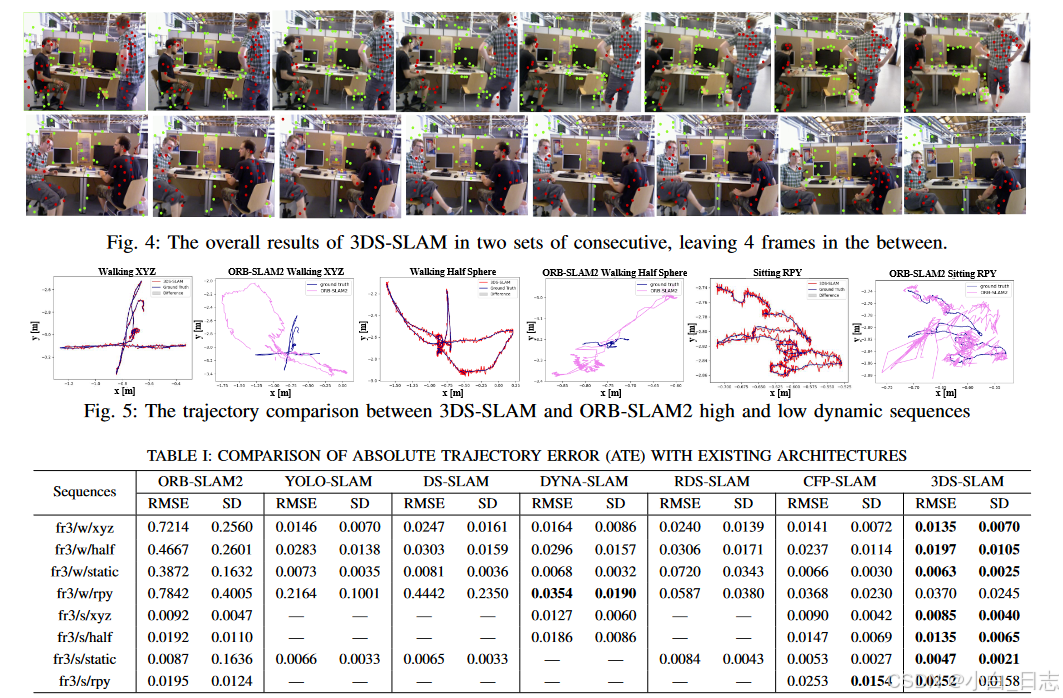
- SLAM与SOTA框架的性能比较
对方法与几种最先进的动态SLAM方法进行了比较分析,包括ORB-SLAM2、YOLO-SLAM、DS-SLAM、DYNA-SLAM、RDS-SLAM和CFP-SLAM,与ORB-SLAM相比,这些方法也表现出了优越的性能。定量评估结果可在表I、表II和表III中找到,其显示了所有八个TUM RGB-D序列的ATE、翻译RPE和旋转RPE。
图4. 3DS-SLAM在两组连续图像中的总体结果,中间留下4帧。
图5. 3DS-SLAM和ORB-SLAM2高低动态序列的轨迹比较
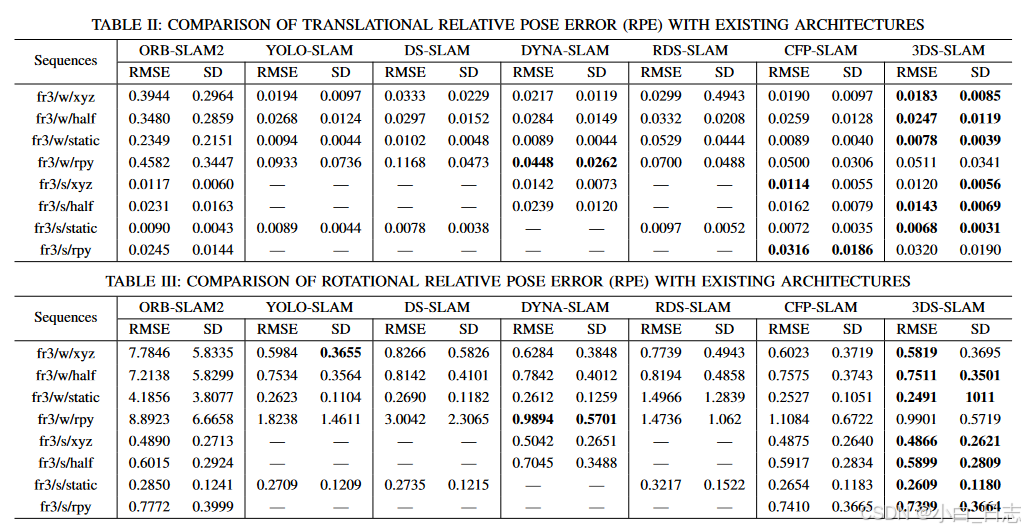
在rpy序列中,大量的相机角度变化和与动态目标的大距离可能会导致点云中对象的遗漏,这主要是由于深度相机的范围有限。
因此,特征匹配中的这种不足略微影响了方法的性能。图5表示3DS-SLAM和ORB-SLAM2的3D轨迹的2D投影。在高动态序列和低动态序列中,提出的3DS-SLAM轨迹都与地面实况密切匹配,而ORB-SLAM2估计的轨迹与地面实况存在显著偏差。总体而言,在来自TUM RGB-D数据集的动态序列中,3DS-SLAM比ORB-SLAM2表现出98.01%的显著平均改进。
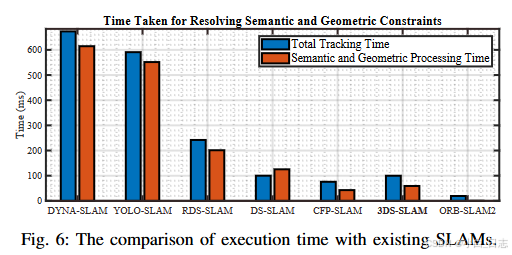
实时性能和计算效率对于快速准确的可视化SLAM框架至关重要。图6展示了现有架构之间处理时间的比较,其中语义和几何约束的处理包括3D目标检测和动态特征过滤。姿态估计和ORB特征提取有助于整个跟踪持续时间。虽然DYNA-SLAM和YOLO-SLAM表现出强大的跟踪能力,但由于分别使用Mask R-CNN和Darknet19-YOLOv3,它们的处理时间延长。
DS-SLAM和CFP-SLAM快速处理帧,但难以处理具有快速相机旋转功能的序列。与现有的SLAM系统相比,3DS-SLAM不仅满足实时性要求,而且保持了高精度水平。为了提高其计算效率,实现了关键措施:1)通过连续帧的ORB特征提取并行执行语义和几何线程。2) 点云预处理消除了不必要的数据,从而提高了速度和准确性。
讨论
在实时场景中,现有的2D视觉SLAM框架面临挑战,尤其是在检测丢失对象和定位动态目标方面。在动态环境中,物体运动、相机视野内的部分物体可见性、图像模糊、变化的照明条件以及由于旋转而导致的独特相机角度等因素,对关键机器人应用中的目标检测构成了重大障碍。因此,需要开发明确应用于目标检测器的用于丢失目标检测和动态目标定位的方法。然而,这些方法显著增加了现有视觉SLAM系统所需的计算时间。
例如,CFP-SLAM通过将扩展卡尔曼滤波器和匈牙利算法与YOLOv5明确结合来解决丢失物体的挑战,但缺乏计算效率。相比之下,3DS-SLAM主要旨在通过隐式地将部分感知对象定位与目标检测相结合,以便解决视觉SLAM中的动态目标缺失问题。
与现有视觉SLAM实践中看到的深度图与RGB图像的手动参数融合相比,将点云合并到框架中改进了动态目标定位。它还克服了由于环境因素和关键机器人环境而导致的与2D目标检测相关的限制。3DSSLAM系统提供了几个优势和未来的潜力,包括增强对物体识别的3D场景理解,在具有挑战性的照明和纹理条件下增强鲁棒性,以及有效处理桌子和床等悬挂结构。
