
阅读量:0
Selenium的CSS层叠样式表选择器(二)
目的:了解CSS Selector的选择语法的联合使用方法,掌握组选择、按顺序选择子节点和兄弟节点选择的方法。能够使用CSS 选择器选择语法的联合使用完成要求的元素定位。
要求:在pycharm 环境下完成上述各项任务
条件:win7/10、pycharm、selenium4.4.0
内容及步骤:
使用CSS选择器选择元素时,是具有很强的灵活性的。比如,要选择界面中的一个元素,既可以使用它的某个唯一的属性值,也可以根据父子关系按照层级定位它。CSS选择器除了具有灵活性外,另一个强大之处在于:选择语法可以联合使用。
一、 组选择:同时选择多个元素,各个选择条件用逗号(,)隔开,允许逗号两端的属性不一致
如果要同时选择所有class名 为 plant 和 animal 的元素,则应写为:
find_element(By.CSS_SELECTOR, '.plant, .animal')
注意:通过组选择能够完成同时选择多个元素的工作,其选中元素不是按照组表达式的次序排序的,而是先选择出符合这些表达式的元素,然后按照它们在HTML文档中的出现的次序排列。
- 在浏览器中打开百度新闻https://news.baidu.com/网站,选择“热点要闻”栏目中的class名 为 focuslistnews 和 hotnews的元素,计算满足此条件的元素共有多少项,输出:“热点要闻栏目中有XX项焦点列表和热点新闻项”。使用
qiut()关闭浏览器。
二、 按次序选择子节点:(练习网页:https://cdn2.byhy.net/files/selenium/sample1b.html )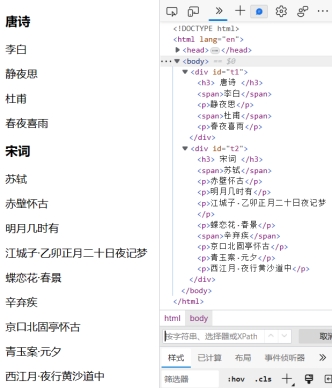
指定选择的元素是父元素的第几个子节点,语法为 :nth-child(),括号中填写第几个子节点的数字。
例如:要选择唐诗和宋词的第一个作者,也就是选择第2个子元素,且为span类型,CSS Selector表达式可写为:
span:nth-child(2)
或
\#t1 :nth-child(2) , #t2 :nth-child(2)
又或者
\#t1 > :nth-child(2) , #t2 > :nth-child(2)
指定选择的元素 是父元素的倒数第几个子节点,语法为 :nth-last-child(),括号中填写第几个子节点的数字。
例如:要选择最后一首唐诗和宋词的题目,CSS Selector表达式可写为:p:nth-last-child(1)
指定选择的元素是父元素第几个某类型的子节点,语法为 :nth-of-type(),括号中填写第几个子节点的数字。
例如:要使用类型限定选择唐诗和宋词的第一个作者,由于它们是父元素下第一个span类型的子元素,所以CSS Selector表达式可写为: span:nth-of-type(1)
指定选择的元素是父元素倒数第几个某类型的子节点,语法为 :nth-last-of-type(),括号中填写第几个子节点的数字。
例如:要选择唐诗和宋词的倒数第一个作者,CSS Selector表达式可写为: span:nth-last-of-type(1)
指定选择的元素是父元素的奇数或偶数的子节点,语法为 :nth-child(odd) 及 :nth-child(even)
例如:#t1 :nth-child(odd)
指定选择的元素 是父元素某种类型的奇数或偶数的子节点,语法为 :nth-of-type(odd) 及 :nth-of-type(even)
例如:#t2 p:nth-of-type(even)
- 在上个操作步骤的关闭浏览器之前,添加:按照次序选择子节点的任意两种不同的方式,完成对“热点要闻”栏目中的class名为hotnews的元素中的第四个新闻标题的获取,并输出显示文本信息。
三、 兄弟节点选择:
相邻兄弟节点选择,就是选择一个元素平级的后面紧跟着的兄弟节点,相邻关系语法用加号+表示。
例如:要选择唐诗和宋词的第一个作者,因为唐诗和宋词的标签名都是h3,紧跟着它的平级兄弟节点span就是作者,所以CSS Selector表达式可以写为:h3 + span
也就是选择紧跟 <h3> 元素的首个 <span> 元素
后续所有兄弟节点选择,用波浪线~表示。
例如:要选择唐诗和宋词的所有作者,CSS Selector表达式可以写为:h3 ~ span
- 在上个操作步骤的关闭浏览器之前,添加:按照兄弟节点选择方式,完成对“热点要闻”栏目中的class名为hotnews的元素的相邻兄弟节点的选择,并输出此兄弟节点的全部可见文本。
操作一:完成上述三个操作步骤(1,2,3)并提交代码
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() # 练习一 driver.get("https://news.baidu.com/") focuslistnews_items = driver.find_elements(By.CSS_SELECTOR,'.focuslistnews , .hotnews') # 计算满足条件的元素数量 total_items = len(focuslistnews_items) # 输出计算结果 print(f"热点要闻栏目中有{total_items}项焦点列表和热点新闻项") print("###################################") # 练习二 #1. 父元素的第几个子节点 hotnews_items = driver.find_element(By.CSS_SELECTOR, '.hotnews') title4_text = hotnews_items.find_element(By.CSS_SELECTOR, "ul>li:nth-child(4)").text # 输出第四个标题的文本信息 print(f"热点要闻中第四个新闻标题为:{title4_text}") #2.父元素第几个某类型的子节点 hotnews_items = driver.find_element(By.CSS_SELECTOR, '.hotnews') title4_text = hotnews_items.find_element(By.CSS_SELECTOR, "ul > li:nth-of-type(4)").text # 输出第四个标题的文本信息 print(f"热点要闻中第四个新闻标题为:{title4_text}") #3.通过子元素类型,父元素获取子元素的方法 hotnews_items = driver.find_elements(By.CSS_SELECTOR, '.hotnews') hotnews_element = hotnews_items[0] hotnews_titles = hotnews_element.find_elements(By.TAG_NAME, "li") title4_text = hotnews_titles[3].text # 输出第四个标题的文本信息 print(f"热点要闻中第四个新闻标题为:{title4_text}") #4.通过索引获取子元素的方法 hotnews_element = hotnews_items[0] title4_text = hotnews_element.find_element(By.XPATH, "./ul/li[4]").text # 输出第四个标题的文本信息 print(f"热点要闻中第四个新闻标题为:{title4_text}") print("###################################") # 练习三 # 查找热点要闻元素的相邻兄弟元素 # 使用CSS选择器(元素+元素) sibling_element = driver.find_element(By.CSS_SELECTOR, '.hotnews+ul') # 输出相邻的兄弟元素的全部可见文本 print(sibling_element.text) # 使用XPATH # hotnews_element = driver.find_element(By.CSS_SELECTOR, '.hotnews') # sibling_element = hotnews_element.find_element(By.XPATH, "./following-sibling::*[1]") # 输出相邻兄弟元素的全部可见文本 # print(f"热点要闻元素的相邻兄弟元素的全部可见文本为:{sibling_element.text}") # 关闭浏览器 driver.quit() 操作二: 在浏览器中打开:京东商城网页https://www.jd.com/,应用按照次序选择元素的方法去检查页面左侧导航栏中是否有如下菜单:“家用电器|电脑 / 办公|男装 / 女装 / 童装 / 内衣|女鞋 / 箱包 / 钟表 / 珠宝|房产 / 汽车 / 汽车用品|食品 / 酒类 / 生鲜 / 特产|医药保健 / 计生情趣|机票 / 酒店 / 旅游 / 生活|安装 / 维修 / 清洗 / 二手”,再使用兄弟节点选择方法定位页面头部导航栏中“京东超市”后三项菜单是否为“秒杀”、“便宜包邮”、“京东生鲜”,输出检查结果。关闭浏览器。
提交代码
import time from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.jd.com/') # 1:检查左侧导航栏中是否有指定菜单 menu_list = ["家用电器", "电脑", "男装", "女装", "童装", "内衣", "女鞋", "箱包", "钟表", "珠宝", "房产", "汽车", "汽车用品", "食品", "酒类", "生鲜", "特产", "医药保健", "计生情趣", "机票", "酒店", "旅游", "生活", "安装", "维修", "清洗", "二手"] for item in menu_list: try: element = driver.find_elements(By.CSS_SELECTOR, f"#J_cate > ul> li[title='{item}']") # J_cate//*[@id="J_cate"]/ul print(f"找到菜单:{item}") except: print(f"未找到菜单:{item}") print("##############################################################") # 2:检查头部导航栏中指定菜单后三项是否正确 #CSS后兄弟节点选择 brother_menus = ["秒杀", "便宜包邮", "京东生鲜"] array=[] target_element = driver.find_elements(By.CSS_SELECTOR, "#navitems-group1 > li.fore1~li") for element in target_element: array.append(element.text) for i in range(3): if array[i] == brother_menus[i]: print(f"第{i+1}个:{brother_menus[i]}检查通过!") else: print("检查未通过") # XPATH # try: # target_element = driver.find_element(By.XPATH, "//a[contains(text(), '京东超市')]/following-sibling::a[1]") # for i in range(3): # element_text = target_element.get_attribute("text") # if element_text == brother_menus[i]: # print(f"第{i + 1}个菜单:{element_text},检查通过!") # else: # print(f"第{i + 1}个菜单:{element_text},检查未通过!") # # target_element = target_element.find_element(By.CSS_SELECTOR, "+ li") # except: # print("找不到京东超市菜单!") # 关闭浏览器 driver.quit() 操作三: 应用选择语法的联合使用方法编写测试用例:以管理员身份登录 http://127.0.0.1:8047/mgr/sign.html,用户名 :byhy 密码: 88888888。点击添加药品,输入正确格式的药品名、编号和描述,点击创建。预期结果为:成功登录后,检查药品列表第一项结果中 药品名、编号和描述都是正确的。
提交代码
from selenium import webdriver from time import sleep from selenium.webdriver.common.by import By driver = webdriver.Chrome() # 打开待测试环境 driver.get('http://127.0.0.1:8047/mgr/sign.html') elementuser = driver.find_element(By.ID, 'username') elementuser.send_keys('byhy') elementpass = driver.find_element(By.ID, 'password') elementpass.send_keys('88888888') elementbutton=driver.find_element(By.TAG_NAME, 'button').click() sleep(3) # 创建药品 # 点击菜单栏药品,进入药品信息页面 medicines_menu = driver.find_element(By.XPATH, '//*[@id="root"]/aside/section/ul/li[3]/a').click() # 找到添加药品按钮并点击 medicines_button = driver.find_element(By.CSS_SELECTOR, '#root > div > section.content.container-fluid > div.col-lg-12.col-md-12.col-sm-12.add-one-area > button').click() # 输入药品信息,药品名,编号,描述 medicines_name = driver.find_element(By.CSS_SELECTOR,'.col-lg-8>:nth-child(1)>input').send_keys('阿莫西林') medicines_number = driver.find_element(By.CSS_SELECTOR,'.col-lg-8>:nth-child(2)>input').send_keys('CAS : 26787-78-0') medicines_describe = driver.find_element(By.CSS_SELECTOR,'.col-lg-8>:nth-child(3)>textarea').send_keys('阿莫西林片:0.125 g;0.25 g。') # 点击创建按钮 create_button = driver.find_element(By.CSS_SELECTOR,'.col-lg-12>.btn-xs:nth-child(1)').click() # 点击取消按钮 # sleep(1) # create_button = driver.find_element(By.CSS_SELECTOR, '.content>.col-lg-12>.col-lg-12 button:nth-child(2)') # create_button.click() # 实际结果 actual_result = [] # actual_result = '' # 定位左侧菜单栏 elements = driver.find_elements(By.CSS_SELECTOR, '#root > div > section.content.container-fluid > div:nth-child(3)> *') for element in elements: actual_result.append(element.text) actual_result.remove(actual_result[-1]) new_string_array = [s[3:] for s in actual_result] print(new_string_array) # 预期结果 expected_result = ['阿莫西林','CAS : 26787-78-0','阿莫西林片:0.125 g;0.25 g。'] print('预期结果为: ', expected_result) # 通过try抛出异常进行断言判断 try: assert expected_result == new_string_array print('PASS,实际结果与预期结果一致!') except Exception as e: print('FAIL,实际结果与预期结果不一致!', format(e)) # sleep(1) driver.quit() 