
阅读量:0
导读
在深度学习领域,训练大型语言模型(LLMs)一直是一项极具挑战性的任务,它不仅需要巨大的计算资源,同时对内存的消耗也非常巨大。近期,快手大模型团队提出了创新的方法,包括感知流水并行的激活值卸载以及计算-内存均衡的检查点策略,该方法旨在无损地加速大型语言模型的训练过程。目前论文入选ATC 2024大会,代码已开源。

论文题目:
Accelerating the Training of Large Language Models using Efficient Activation Rematerialization and Optimal Hybrid Parallelism
论文地址:
https://www.usenix.org/conference/atc24/presentation/yuan
代码地址:
https://github.com/kwai/Megatron-Kwai
论文核心贡献:
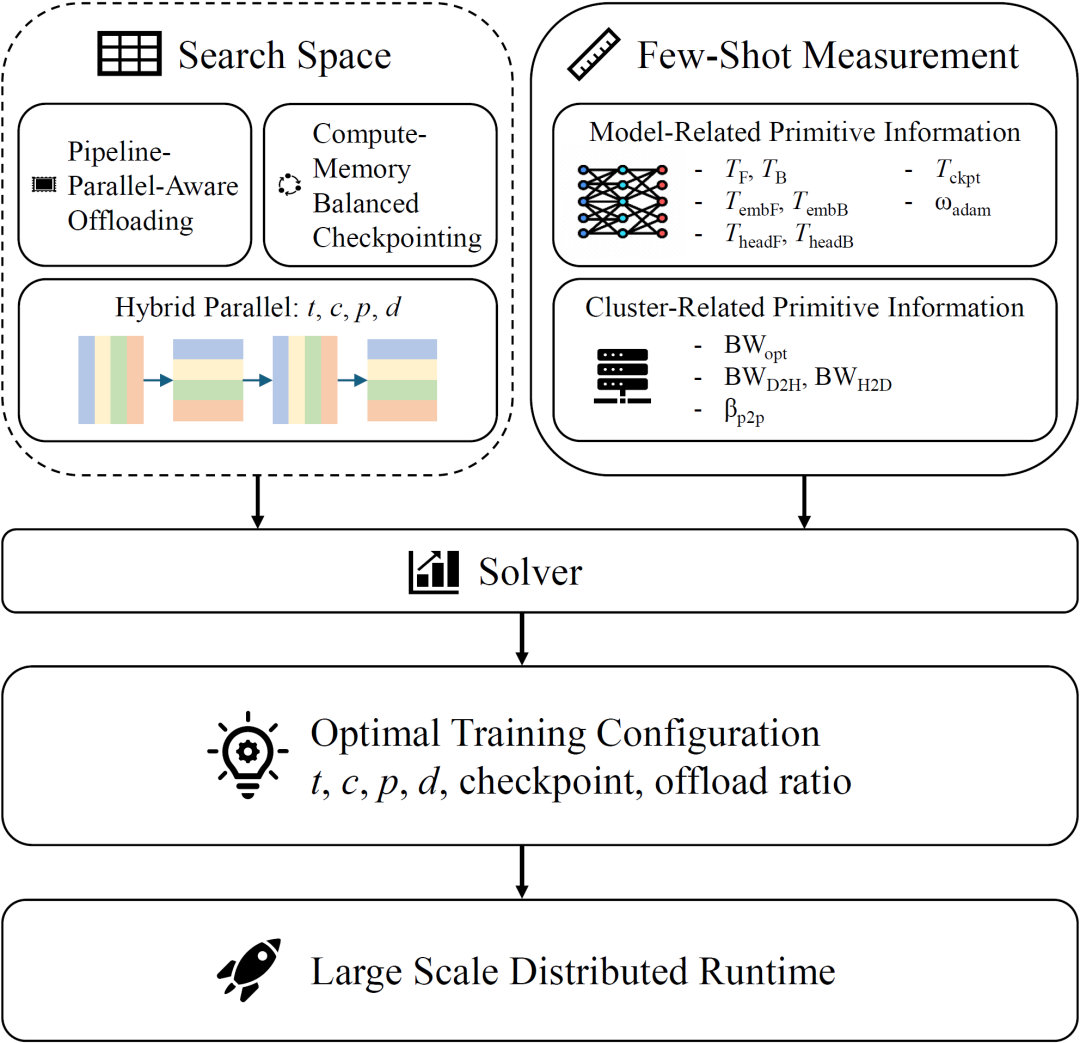
1. 感知流水并行的激活值卸载(Pipeline-Parallel-Aware Offloading):针对流水并行产生的激活值,设计卸载和重载的调度策略,充分利用主机内存(主存)来存储激活,且时间开销可以忽略不计。
2. 计算-内存均衡的检查点策略(Compute-Memory Balanced Checkpointing):平衡内存成本和计算成本,以达到帕累托最优,在激活值大小和计算效率之间达到一个实用的平衡点。
3. 性能建模与并行配置调优:针对混合并行配置(张量并行、上下文并行、流水并行、数据并行)搜索空间大的问题,提出了一种性能建模方法,通过测量模型相关元信息、集群相关元信息,就能求解出最优并行配置。
实验结果令人瞩目。以 175B 模型、上下文窗口大小为 32,768 为例,在 256 个 NVIDIA H800 GPU 上,所提出的方法显著地将 MFU(Model FLOPs Utilization)从 32.3% 提高到了 42.7%
一、背景介绍
大模型训练的一个高效实现是 Megatron-LM 框架里的四维混合并行:张量并行(Tensor Parallelism,TP)、上下文并行(Context Parallelism,CP)、流水并行(Pipeline Parallelism,PP)和数据并行(Data Parallelism,DP)。丰富的并行维度带来了不错的性能收益,但也带来了两项挑战。
一、激活值显存瓶颈
随着序列长度增加,每张显卡上的激活值大小等比例增大:例如 175B 模型 32k 序列长度,在不引入跨机 TP 和跨机 CP 的前提下,无论采用何种并行方案,每张显卡上的激活值大小至少是 171.5 GB,这超过了当前任何显卡的显存大小;如果引入跨机 TP 或跨机 CP,由于网络通信速度比 NVLink 低一个数量级,因此通信时间会大幅增加,训练吞吐断崖式下降。
二、并行配置调优困难
混合并行的五个参数(张量并行数 t、上下文并行数 c、流水并行数 p、数据并行数 d、pipeline stage 层数 l)组合空间庞大,例如用 192 卡训练 175B 模型有 287 种能够整除的并行配置。如果手工调优并行参数,则需要消耗大量人力和机器时间,而且当卡数变化、global batch size 变化后需要重新调优。
针对这些问题,论文提出了两种减少显卡上激活值的方法,不仅显著提升了长序列训练吞吐,而且提升了常规序列长度的训练吞吐。还提出了一种最优并行配置求解方法,通过测量少量基本性能数据来构建 cost model,使得在任意规模的集群上都能迅速找到最优并行配置。
二、方法概览
感知流水并行的激活值卸载
流水并行分为三个阶段:warm-up 阶段只包含前向计算,steady 阶段前向计算和反向计算交替进行,cooldown 阶段只包含反向计算。由于流水并行的特点,前向计算产生的激活值不会立即被反向计算使用,而这些激活值会持续占用显存。在这段间隔内将激活值卸载到主存,能够减轻显存压力。
感知流水并行的调度方案遵循两个原则:
1) offload 在每个 micro-batch 前向计算结束之后尽快开始;
2) reload 在前一个 micro-batch 反向计算开始时启动。
该方案以 pipeline stage 为调度粒度,不受个别算子计算速度差异、个别激活值大小差异的影响,因此计算与传输能够充分重叠,避免计算与传输相互等待。
整体调度方案如图所示:
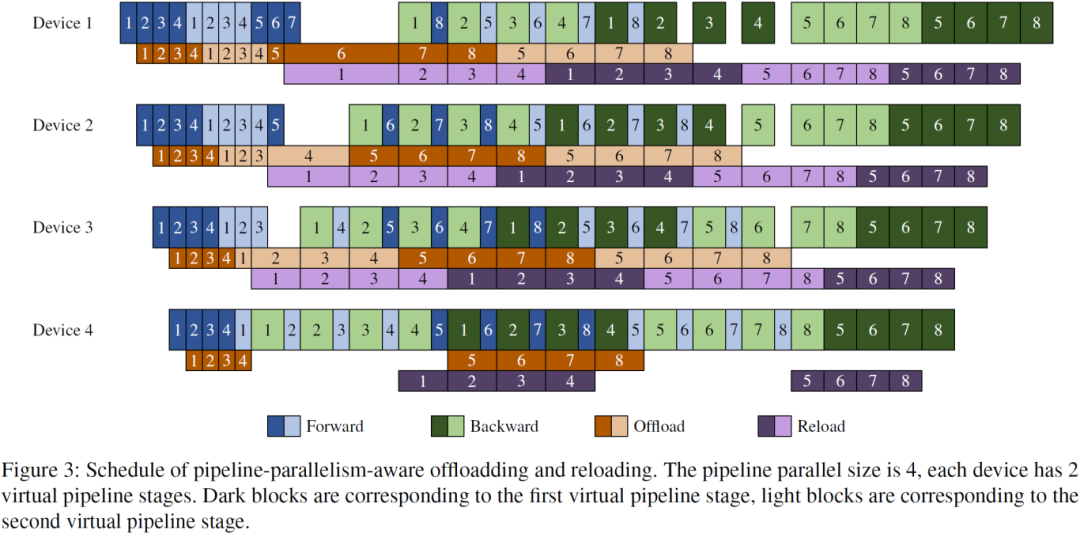
在具体实现上,作者采用了以下技术来提高性能:
1)双工传输:在 steady 阶段,卸载和重载同时进行,这有助于利用 PCIe 双向带宽缩短传输时间,减小传输时间无法被掩盖的可能性。
2)乒乓重载:在 GPU 上开辟两块缓冲区,一块缓冲区作为 reload 的目标地址,另一块缓冲区以零拷贝的方式构建激活值提供给反向计算使用;在下一次调度时,两块缓冲区的角色会交换。
3)传输增强:绑定 NUMA(Non-Uniform Memory Access)节点,并使用锁页内存(page-locked memory)来提升传输性能。
主机与设备之间的传输会占用显存带宽,从而影响计算速度,因此传输的激活值越少越好。通过对显存大小建模,计算出最小卸载比例 α,将其余 1 - α 留在显存上,从而最小化传输量和主存占用。
计算-内存均衡的检查点策略
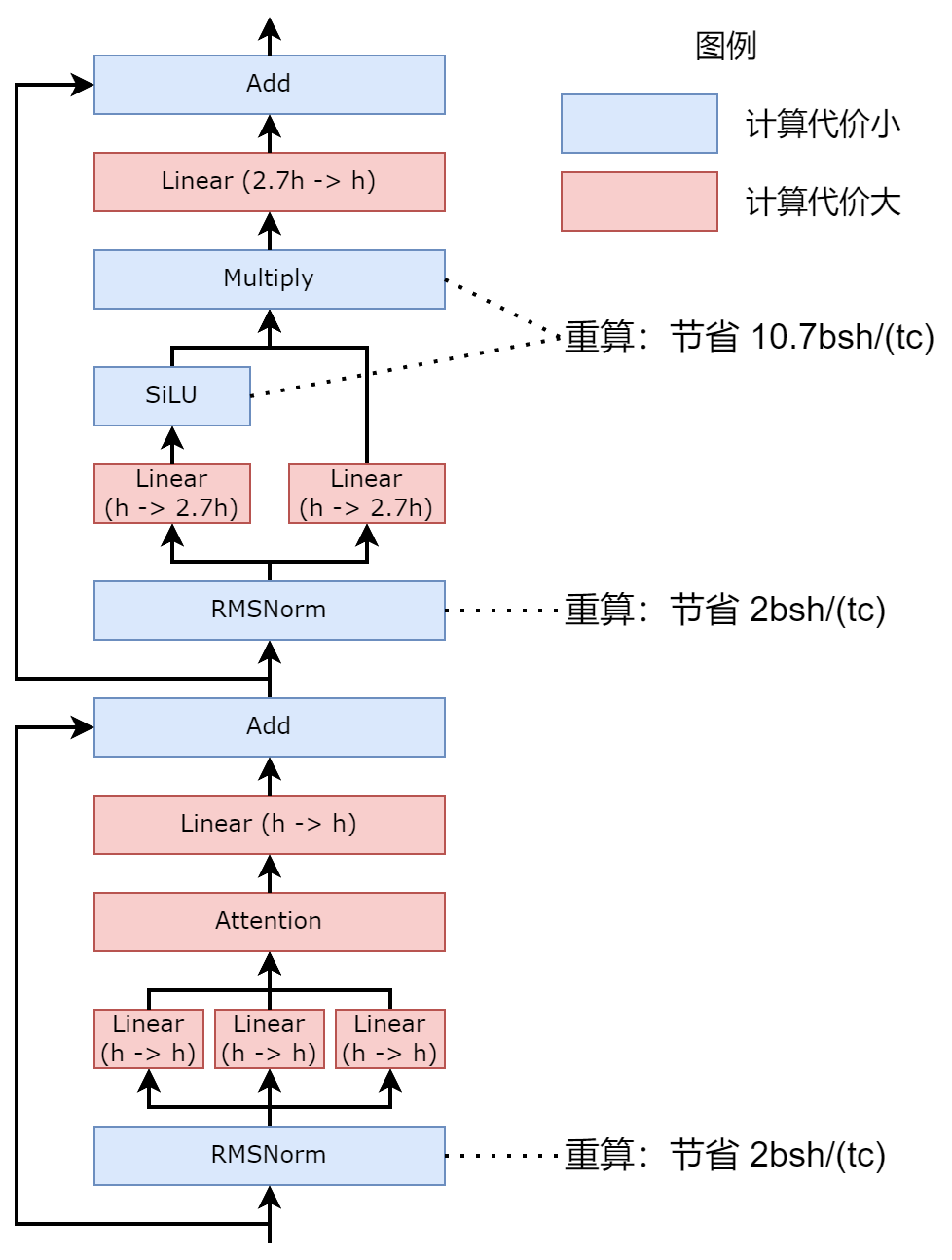
为了减小激活值大小,传统方法是 full checkpointing,即重算每层 transformer layer。这个检查点策略将显存大小减到了最低(仅保存输入张量),而计算代价是增加一倍前向计算量,即 1/3 整体计算量。
本文提出了一种重算代价与收益更加平衡的方法。通过枚举每个激活值所需重算的层,并进行实际测量,得到每个激活值的重算代价。然后枚举所有可能的重算方案,将激活值大小和计算代价画在同一张图上,得到所有重算方案的帕累托包络线。Compute-Memory Balanced Checkpointing 选取了包络线的拐点,将激活值大小的系数从 37.3 节省到 22.7(节省 39%),重算代价仅占总体计算的 1.5%。
具体重算的层如下图所示:
性能建模与并行配置调优
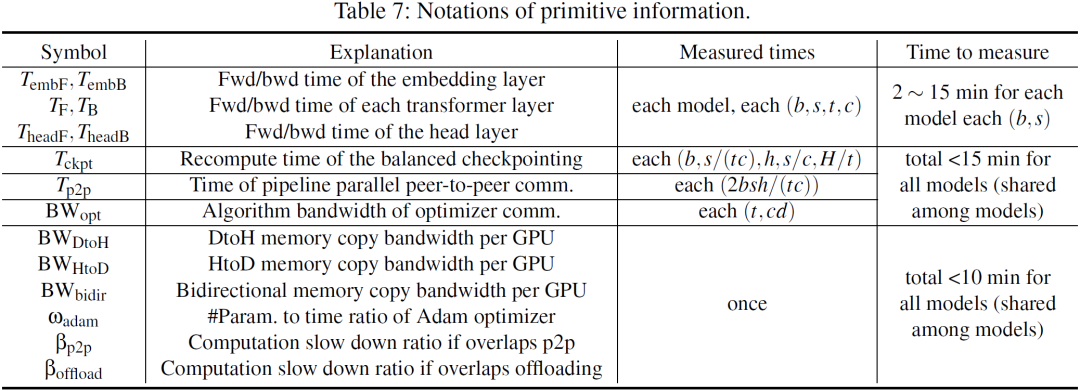
Few-shot 性能建模是一种用比较低的测量代价获取比较准确的时间估计的方案。它将每轮训练迭代的时间拆解成基本性能数据,并且考虑了流水线气泡、算子实现差异、重算时间、通信时间、通信对计算的影响等因素。

基本性能可分为与模型相关性能、集群固有性能两类。模型相关性能包括前向计算、反向计算、重算的时间等,需要为每个模型分别测量;集群固有性能包括 memcpy 传输带宽、DP 传输带宽等,测量一次后可用于所有模型。所有性能指标的测量次数和测量时间如下:
有了这些基本性能数据,预测训练迭代时间无需额外测量。为了得到最优训练配置,枚举所有并行配置,选取预测时间最短的配置即可,求解时间小于 0.001 秒。
三、实验设置
硬件:
实验使用了 32 个节点,每个节点 8 张 NVIDIA H800,主存 1 TB。节点内用 NVLink 连接,节点间用 100Gbps 网卡连接。
软件:
参与对比的最新 Megatron-LM 是 2024.01.01 版本(译者注:ATC '24 截稿日期是 2024.01.16)。Baseline 代码在 Megatron-LM 的基础上做了改进,包括更快的上下文并行实现、更快的 RoPE 实现等。论文代码则在 Baseline 上增加了新提出的 offloading 和 checkpointing 技术。
模型:
参与测试的模型包括 Llama-65B、Llama2-70B、Llama-175B,上下文长度为 4k ~ 128k,默认 global batch size 为 256。其中 Llama2-70B 是 GQA(grouped query attention)模型,其余两个模型是 MHA(multi-head attention)模型;Llama-175B 是指在 Llama-65B 基础上扩大层数和维度的模型。
四、实验结果
性能建模的准确性
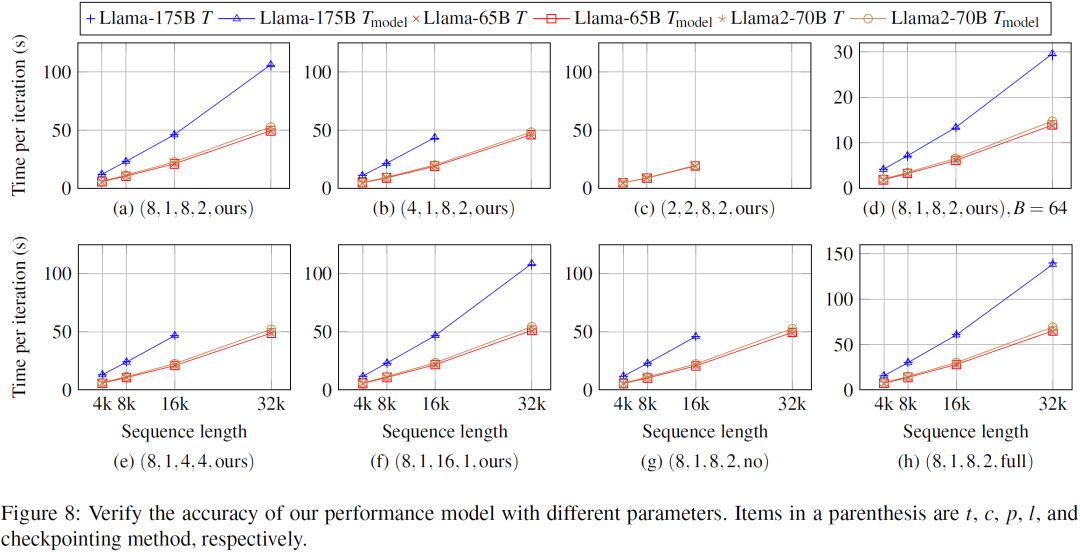
采用控制变量来衡量各种并行参数对性能模型的影响。图 8(a)(b)(c) 显示性能模型对于不同的 t 和 c 是准确的。图 8(a)(e)(f) 表明它对不同的 p 和 l 具有鲁棒性。图 8(a)(g) 表明性能模型对所有三种检查点方法都保持正确性。图 8(a)(d) 说明该模型可以适应不同的全局批量大小。在所有这些情况下,实测时间 T 与建模时间 T_model 之间的差异不超过 2.0%。
端到端性能对比
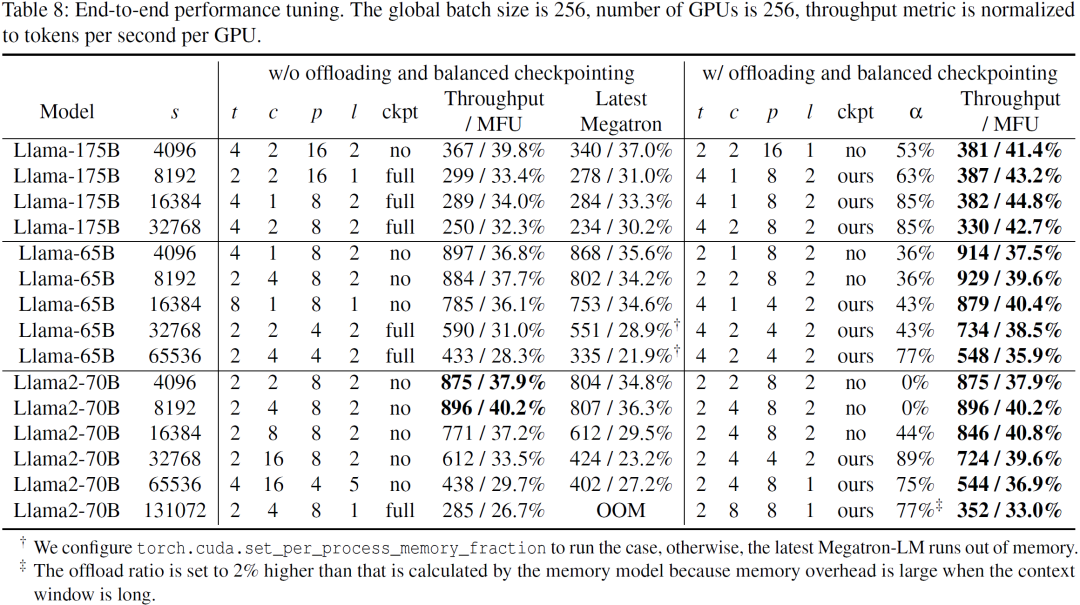
得益于性能建模的准确性,端到端性能对比节省了调优并行配置的时间,且更令人相信 baseline 已调整到最优性能。
实验结果表明,一是 baseline 比最新 Megatron-LM 具有更高的性能和更强的鲁棒性。Baseline 使用了更节省显存和更快速的代码实现,这也是能够鲁棒地进行长序列训练的基础。
二是在卸载和平衡检查点的帮助下,有更大的空间来权衡各种并行配置。与 baseline 相比,性能得到了显著提升。例如,在 256 个 NVIDIA H800 GPU 上,对于上下文窗口大小为 32,768 的 Llama-175B 模型,该方法将 MFU(Model FLOPs Utilization)从 32.3% 提高到 42.7%。
集群规模扩展能力
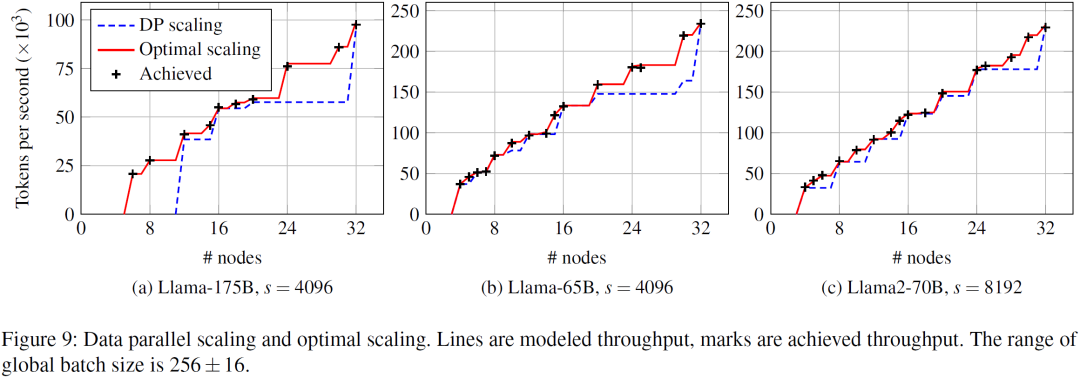
当集群规模的变化时,手工调优的并行配置很难适配这种变化。常见的手工调优方法是针对特定的卡数进行调优,当卡数变化时等比例地增加或减少数据并行数,这种方法简称 DP 扩展法(data parallel scaling)。这可能导致 global batch size 不满足运行要求;即便 global batch size 满足要求,该并行配置也不一定是新集群规模下的最优配置。
性能模型能够完全适应集群规模变化。例如训练 Llama-65B 模型,上下文长度 4096,global batch size 范围限制在 256 ± 16:给定 24 个节点时,按照性能模型求解出来的最优配置运行,训练吞吐达到了 1.80e5 TPS(Tokens Per Second),而 DP 扩展法只能利用上 20 个节点,吞吐预期只有 1.48e5 TPS。即便限制在 20 个节点,也应该用性能模型求解的最优配置,它达到了 1.59e5 TPS,优于 DP 扩展法。
正确性
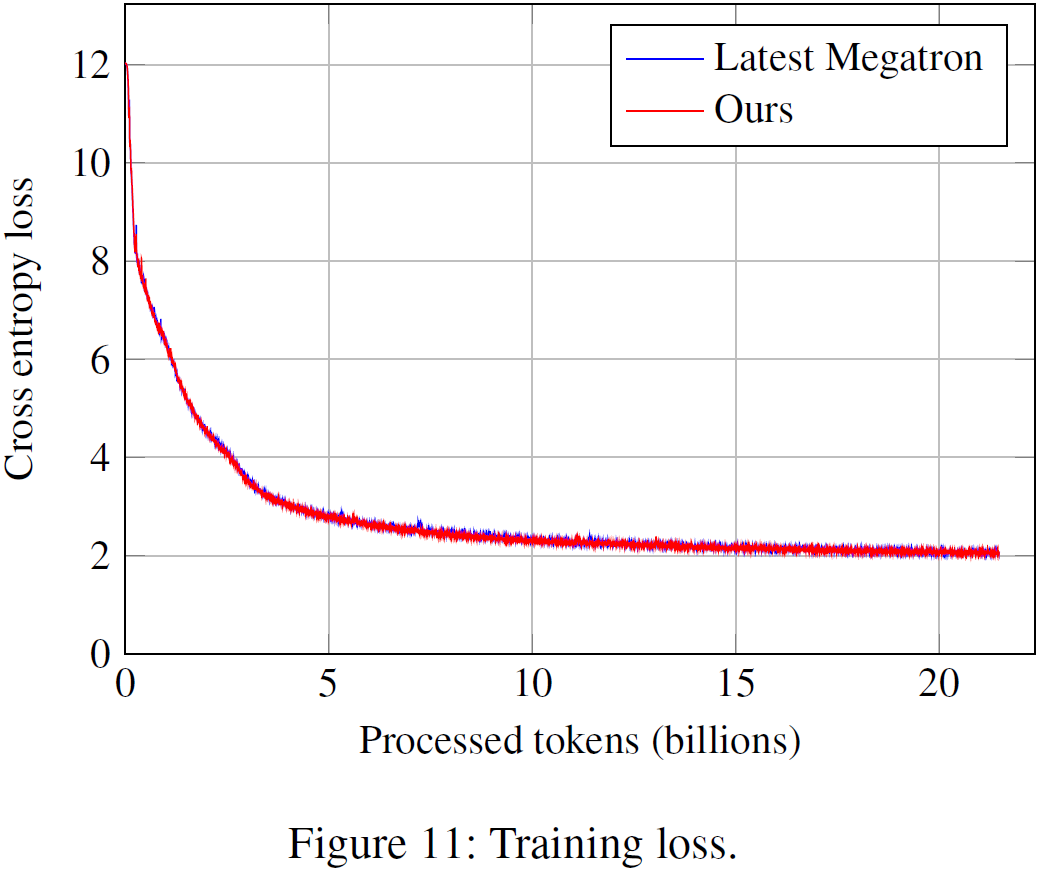
从头训练 Llama2-70B 模型,使用 Pile 数据集,上下文长度 4096,开启所有 4D 混合并行技术(TP、CP、PP、DP),以及 offloading 和 checkpointing。实验结果表明,论文提出的训练系统与最新 Megatron-LM 的 loss 曲线一致,说明训练系统与 GQA 和所有 4D 混合并行技术兼容,且没有损害模型的性能。
五、总结
本文提出了两种激活值重建方法,包括感知流水并行的激活值卸载(Pipeline-Parallel-Aware Offloadin),该方法最大程度利用了主存来存储激活值,以及计算-内存均衡的检查点策略(Compute-Memory Balanced Checkpointing),该策略寻求激活值大小和计算效率之间的实际平衡。针对庞大的并行参数搜索空间,提出了一种最优并行配置求解方法,通过测量少量基本性能数据来构建性能模型,从而全面搜索最优的参数组合。
论文代码附带有运行脚本和 Docker 镜像,以确保实验结果的可复现性。
代码在 GitHub 上公开可访问,以促进进一步的研究。
