
阅读量:4
作者介绍:10年大厂数据\经营分析经验,现任大厂数据部门负责人。
会一些的技术:数据分析、算法、SQL、大数据相关、python
欢迎加入社区:码上找工作
作者专栏每日更新:
LeetCode解锁1000题: 打怪升级之旅
python数据分析可视化:企业实战案例
备注说明:方便大家阅读 公众号 数据分析螺丝钉 回复关键词 python可视化 领取完整notebook 一起打怪升级
kaggle题目说明
泰坦尼克号的沉没是历史上最臭名昭著的沉船事故之一。
1912 年 4 月 15 日,在她的处女航中,被广泛认为“不沉”的泰坦尼克号与冰山相撞后沉没。不幸的是,船上没有足够的救生艇,导致 2224 名乘客和机组人员中有 1502 人死亡。
虽然生存有一定的运气成分,但似乎某些群体比其他群体更有可能生存。
在本次挑战中,我们要求您建立一个预测模型来回答以下问题:“什么样的人更有可能生存?”使用乘客数据(即姓名、年龄、性别、社会经济阶层等)。
有两个文件,test.csv、train.csv通过这两个文件的数据进行预测输出什么人更有可能生存。包括以下几个字段
- PassengerId: 乘客ID,唯一标识每位乘客的整数。
- Pclass: 船票等级,代表乘客舱位的类别。有三个等级:1 = 一等舱,2 = 二等舱,3 = 三等舱。
- Name: 乘客姓名。
- Sex: 性别,male表示男性,female表示女性。
- Age: 年龄。如果年龄是小数,表示它是估计的。对于年龄小于1岁的婴儿,小数表示真实的年龄。某些年龄未知的乘客则为空。
- SibSp: 同船的兄弟姐妹和配偶数量。兄弟姐妹定义包括继兄弟姐妹和同父异母的兄弟姐妹。配偶定义不包括未婚伴侣。
- Parch: 同船的父母与子女数量。这里的某些儿童只有保姆陪同,因此Parch=0。
- Ticket: 船票号码。
- Fare: 船票价格,表示乘客为旅行票支付的费用。
- Cabin: 客舱号码。某些乘客的客舱号码未知。
- Embarked: 登船港口,表示乘客登船的地点。C = Cherbourg,Q = Queenstown,S = Southampton。
分析步骤
步骤1:看看数据情况
用notebook把下载的文件都放在一起方便查看
train.csv: 包含用于训练机器学习模型的数据。test.csv: 包含用于模型预测的测试数据。gender_submission.csv: 提供一个提交示例,展示了预测结果的正确格式。
import pandas as pd # 加载数据 train_df = pd.read_csv('./train.csv') test_df = pd.read_csv('./test.csv') # 数据概览 print("数据前五行:") print(train_df.head()) print("\n数据集基本信息:") print(train_df.info()) print("\n数值型特征的描述性统计:") print(train_df.describe()) # 缺失值检查 print("\n各列缺失值计数:") print(train_df.isnull().sum()) 检查数据有没缺
# 检查训练集中的缺失值 print(train_df.isnull().sum()) # 检查测试集中的缺失值 print(test_df.isnull().sum()) 可以看到train年龄(Age)有177个缺失值,客舱号码(Cabin)有687个缺失值,还有登船港口(Embarked)有2个缺失值
- 对于
Age,可以使用中位数或平均值来填充。 - 对于
Embarked(仅在训练集中有少量缺失),可以使用众数(最常见的值)来填充。 - 对于
Cabin,考虑到缺失较多,可以填充为一个常数,如'Unknown',或者从中提取有用信息,如甲板号。 Fare缺失值(在测试集中仅有1个)可以用中位数或平均值填充。
1.1. 年龄缺失处理
由于数据的轻微右偏和存在离群点,使用中位数填充缺失值比使用平均值更为合适。中位数对离群点不敏感,并且可以更好地代表“典型”的乘客年龄,而不会被极端值所扭曲。分析如下
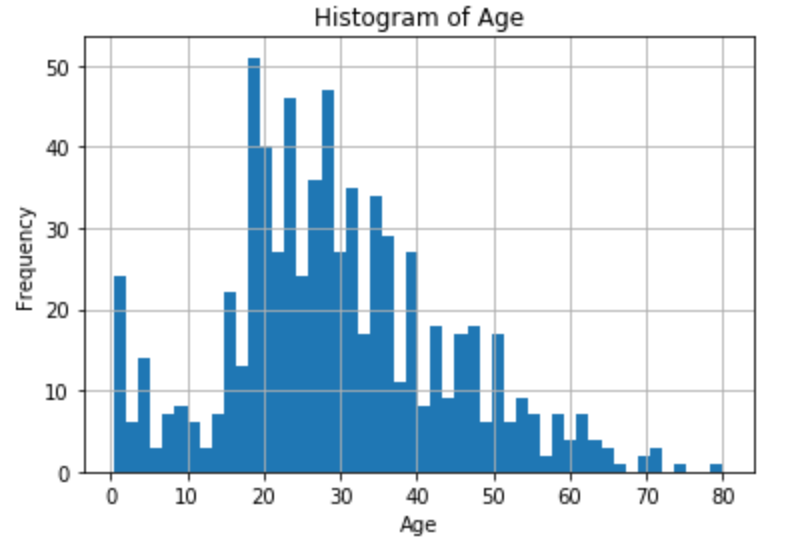
1.1.1 直方图分析
- 年龄的分布似乎接近正态分布,但是略微右偏(偏向老年)。
- 最高频率的年龄组集中在20到30岁之间。
- 这种分布表明年轻人在数据集中占比较高。
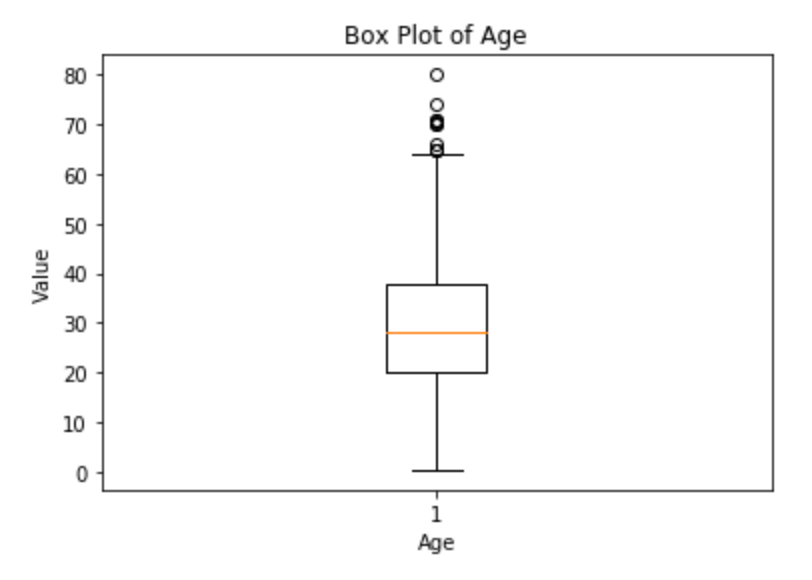
1.1.2 箱线图分析
- 箱线图显示出多个离群点,这些点主要集中在高年龄区域。
- 中位数(箱体中的橙线)低于平均年龄(如果用箱体大小表示的话),这支持我们之前的观察结果,即数据向高年龄方向偏斜。
- 由于这些离群点,平均值会受到较高年龄值的影响,从而偏离大多数乘客的实际年龄。
1.1.3 分析代码
# 绘制年龄的直方图 train_df['Age'].hist(bins=50) plt.title('Histogram of Age') plt.xlabel('Age') plt.ylabel('Frequency') plt.show() # 绘制年龄的箱线图 plt.boxplot(train_df['Age'].dropna()) plt.title('Box Plot of Age') plt.xlabel('Age') plt.ylabel('Value') plt.show()1.1.4 中位数填充缺失
# 填充年龄 train_df['Age'].fillna(train_df['Age'].median(), inplace=True) train_df['Age'].fillna(train_df['Age'].median(), inplace=True)1.2. 填充登船港口
# 填充登船港口 most_common_embarked = train_df['Embarked'].mode()[0] train_df['Embarked'].fillna(most_common_embarked, inplace=True)1.3. 填充甲板号
考虑到 Cabin 字段中有大量的缺失值,通常不会尝试去预测或估计具体的船舱号,也不能删除这个数据,因为其他的字段是有用的,这里我们把它表示为unkowne
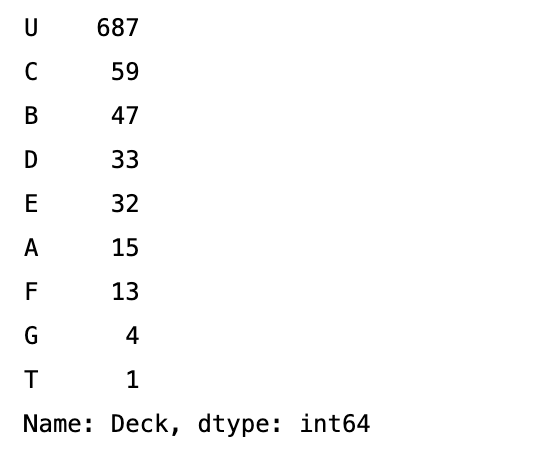
# 填充Cabin的缺失值为 'Unknown' train_df['Cabin'].fillna('Unknown', inplace=True) # 提取Cabin的甲板号,将NaN视为 'U'(代表Unknown) train_df['Deck'] = train_df['Cabin'].apply(lambda x: x[0] if pd.notna(x) else 'U') # 检查提取后的甲板号 print(train_df['Deck'].value_counts())可以看到标识为U的有687个
1.4. 填充船票
# 填充票价 train_df['Fare'].fillna(test_df['Fare'].median(), inplace=True)步骤2:特征选择和工程
2.0 特征分析
- 根据数据的含义和直觉选择有意义的特征。对于泰坦尼克号数据集,
Pclass、Sex、Age、SibSp、Parch、Fare和Embarked可能是有用的特征。这与社会经验相关,理论上经济条件好的票价贵获得的服务更多,生存概率可能更大,其他的也类似,比如性别年龄等等 - 可以创建新特征,如家庭成员总数(
SibSp+Parch)。 - 对相关的特征进行分析看与生存的关系用来做预测
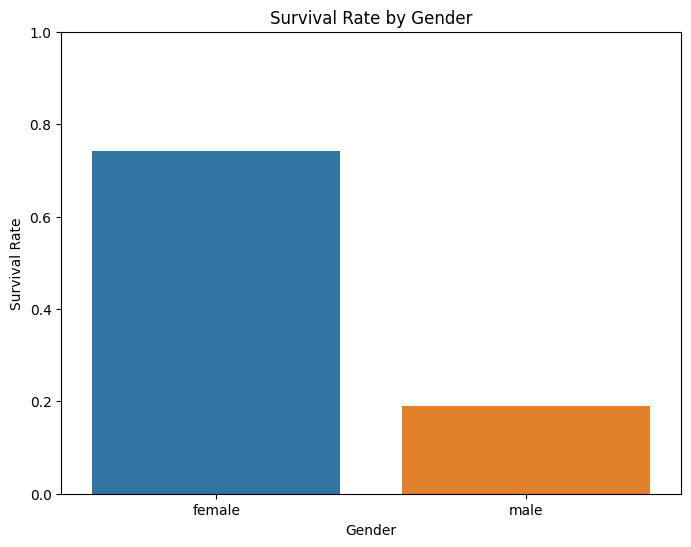
2.0.1 性别与生存的关系
可以看到女的生存率较大,女士优先在各种场合都适用
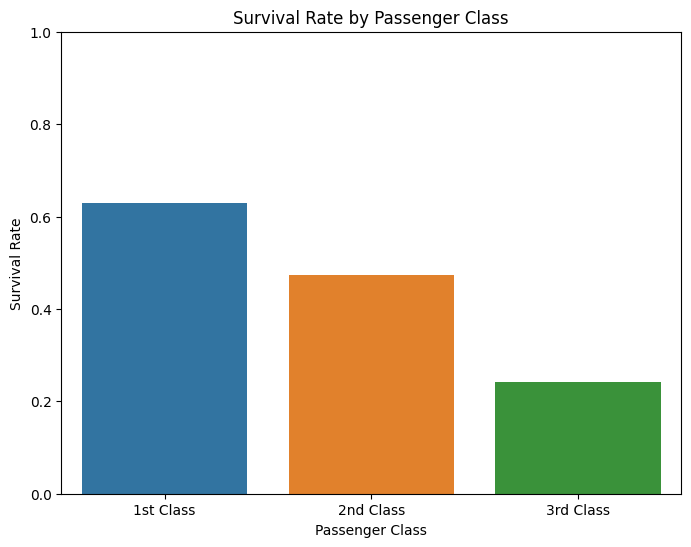
2.0.2 乘客等级与生存率的关系
乘客社会等级越高,幸存率越高,努力挣钱很重要
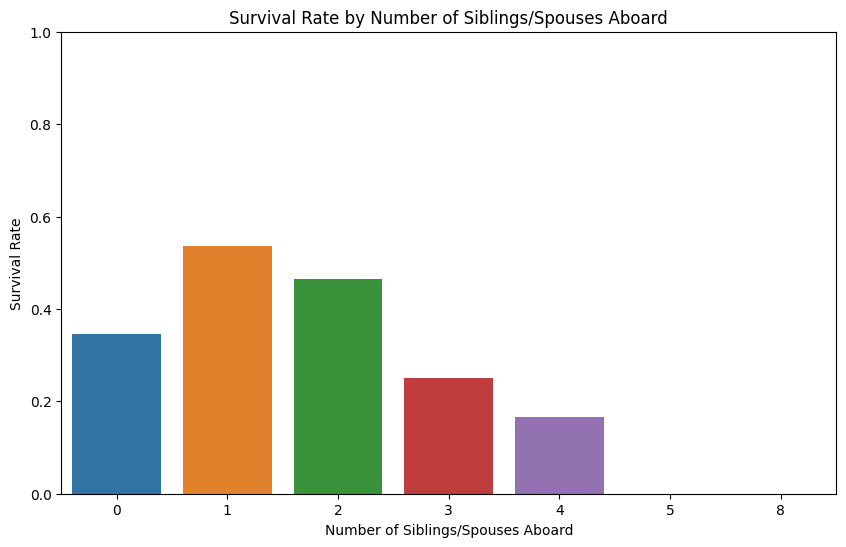
2.0.3 携带配偶及兄弟姐妹与生存率的关系
在紧急情况下,拥有一到两名家庭成员可能有利于生存,而大家庭可能会因为尝试集体行动而处于不利地位
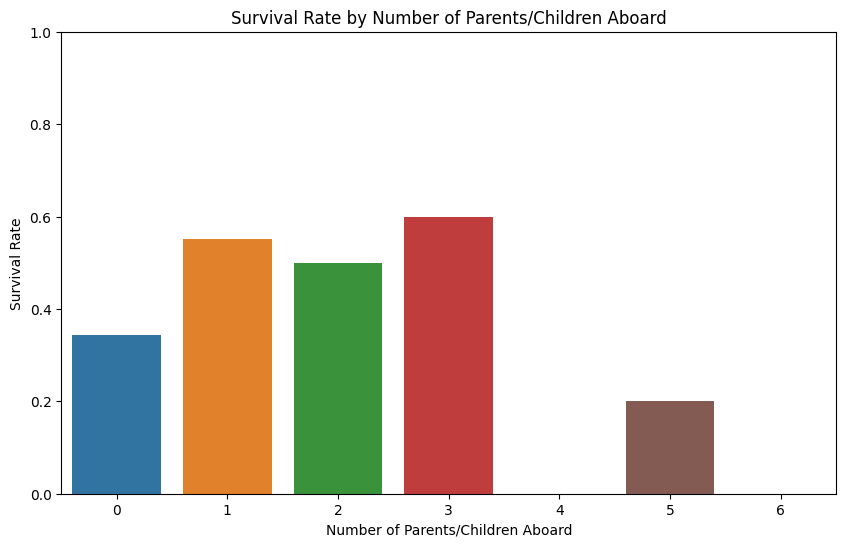
2.0.4 父母与子女与生存率的关系
无父母/子女: 没有携带父母或子女的乘客生存率较低。这可能是因为他们没有亲人的帮助或动力去寻求生存的机会。
一位父母/子女: 与一个父母或子女同行的乘客生存率有所提高。这可能是因为他们可以相互支持,共同寻找逃生的机会。
两位父母/子女: 生存率略有下降,但仍然高于独自旅行的乘客。这可能表明在一些情况下,担负照顾多个家庭成员的责任可能会影响生存机会。
三位父母/子女: 生存率显著增加,这可能意味着拥有一个较大家庭的乘客可能会在疏散时得到优先考虑,或者家庭成员之间的合作对生存至关重要。
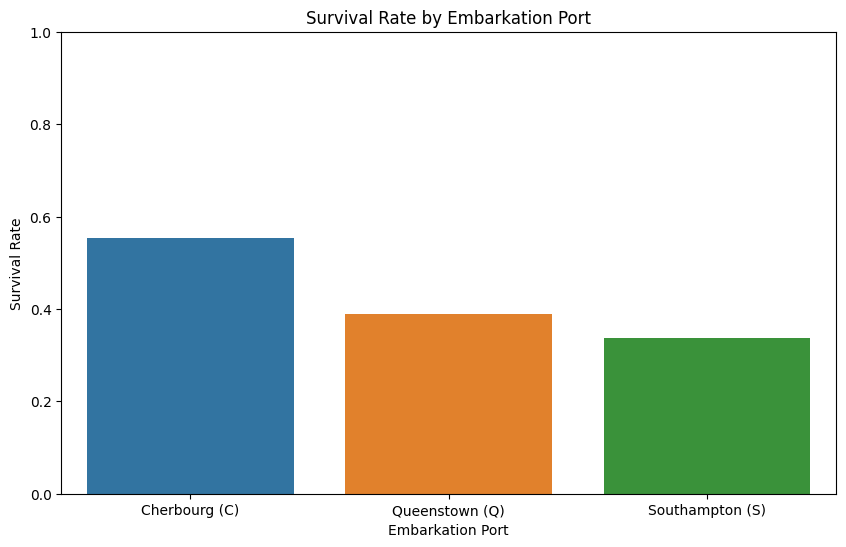
2.0.5 登港港口与幸存率的关系
Cherbourg (C):从Cherbourg登船的乘客有最高的生存率。这可能表明从这个港口登船的乘客在社会经济地位上可能较高,因此可能在船上有更好的住宿条件,或者在疏散过程中获得了更好的机会。
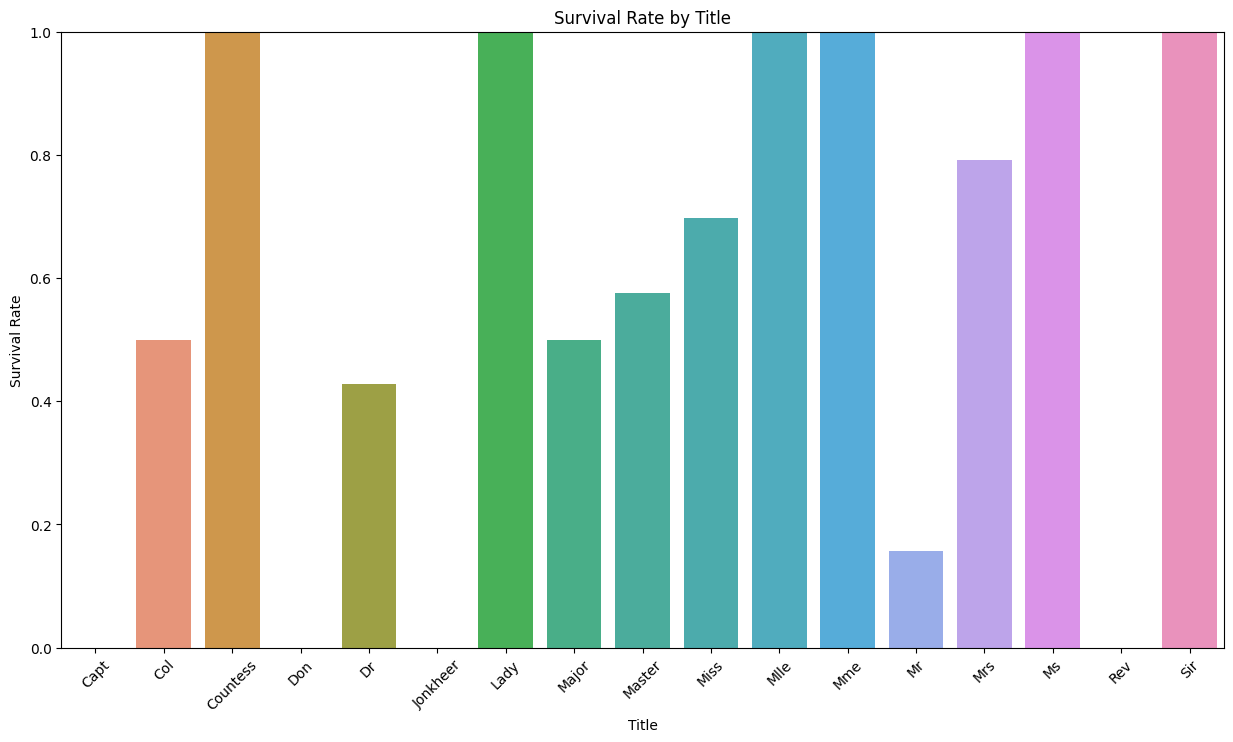
2.0.6 不同称呼与幸存率的关系
一些称呼如
Miss、Mrs、和Master(通常用于未婚女士、已婚女士和年轻男性)显示出较高的生存率,这可能反映了妇女和儿童优先的救生原则。称呼
Mr和Rev(牧师)的生存率相对较低,这可能是因为成年男性在撤离时被赋予了较低的优先级。有几个称呼,如
Sir、Lady、和Countess表现出极高的生存率,这些称呼可能指的是社会地位较高的乘客,他们可能因此获得了更好的救援机会。称呼
Don、Col(上校)和Capt(船长)的生存率较低或为零,这可能表明这些乘客有职责在灾难时帮助他人或保持纪律,从而牺牲了自己的生存机会。注意样本量差异:某些称呼如
Jonkheer(荷兰的贵族)和Mlle(法语中的小姐)样本量可能非常小,因此生存率可能不具有统计意义。
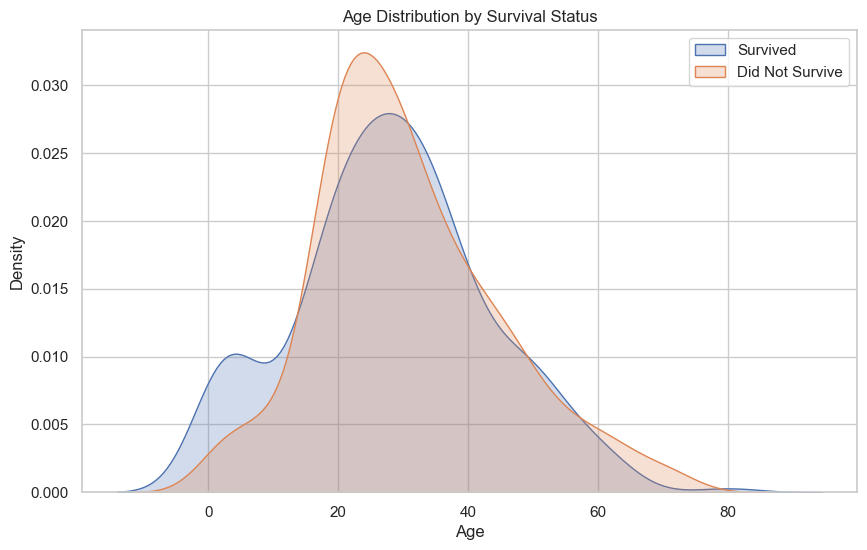
2.07 年龄与生存关系
这个核密度估计图(KDE图)展示了泰坦尼克号上生还者和未生还者的年龄分布。从图中可以看出:
儿童生还率较高:在较低年龄段,特别是10岁以下的儿童,生还曲线(蓝色)高于未生还曲线(橙色),表明儿童的生还率相对较高。
年轻成人生还率:年龄在20到30岁之间的成人生还率似乎低于未生还率,这可能是因为这个年龄段的成年男性较多,而在泰坦尼克号沉船事件中,成年男性的生还率相对较低。
老年生还率:年龄在60岁以上的乘客生还率也较低,这与整体的生还趋势一致,即年龄较大的乘客生还机会减少。
密度的差异:在所有年龄段,未生还者的密度普遍高于生还者,这可能反映了未生还者在整体乘客中占比较大。
峰值分析:生还者的密度峰值似乎在稍微低于30岁的地方,而未生还者的密度峰值略高于30岁,这可能反映了生还者中有更多的较年轻乘客。
2.1. 转换类别变量
机器学习模型通常需要输入是数值型数据,因此需要将类别变量转换为数值型。这通常通过编码技术如独热编码或标签编码来实现。
类别变量编码:
Sex: 将性别转换为数值(0和1)。Embarked: 使用独热编码,因为它是非序列的类别型数据。
# 将性别转换为数值 train_df['Sex'] = train_df['Sex'].map({'male': 0, 'female': 1}) test_df['Sex'] = test_df['Sex'].map({'male': 0, 'female': 1}) # 使用独热编码处理登船港口 train_df = pd.get_dummies(train_df, columns=['Embarked']) test_df = pd.get_dummies(test_df, columns=['Embarked'])2.2.创建新的特征
通过创建新的特征以揭示数据中的更深层次信息,这些信息可能跟生存概率有关系,这个需要有一些社会经验。
Title提取自乘客的全名,表示他们的社会称谓,这可能与生存概率相关。FamilySize是从SibSp和Parch计算得出的,表示乘客的家庭成员总数。IsAlone是基于FamilySize创建的,表明乘客是否独自一人在船上。Deck是从Cabin的第一个字母提取的,代表乘客的船舱甲板位置,这可能会影响他们在紧急情况下的逃生机会。TicketPrefix提取自Ticket,可能包含了与票价或船舱位置相关的信息。
# 从Name中提取称谓作为新特征Title train_df['Title'] = train_df['Name'].apply(lambda name: name.split(',')[1].split('.')[0].strip()) test_df['Title'] = test_df['Name'].apply(lambda name: name.split(',')[1].split('.')[0].strip()) # 创建FamilySize特征 train_df['FamilySize'] = train_df['SibSp'] + train_df['Parch'] + 1 test_df['FamilySize'] = test_df['SibSp'] + test_df['Parch'] + 1 # 创建IsAlone特征 train_df['IsAlone'] = 1 # initialize to yes/1 is alone train_df['IsAlone'].loc[train_df['FamilySize'] > 1] = 0 # now update to no/0 if family size is greater than 1 test_df['IsAlone'] = 1 # initialize to yes/1 is alone test_df['IsAlone'].loc[test_df['FamilySize'] > 1] = 0 # now update to no/0 if family size is greater than 1 # 从Cabin特征提取甲板信息作为新特征Deck # 如果Cabin值缺失,则使用 'U' 表示Unknown train_df['Deck'] = train_df['Cabin'].apply(lambda x: x[0] if pd.notna(x) else 'U') test_df['Deck'] = test_df['Cabin'].apply(lambda x: x[0] if pd.notna(x) else 'U') # 从Ticket特征提取票据前缀 train_df['TicketPrefix'] = train_df['Ticket'].apply(lambda x: x.split()[0] if not x.isdigit() else 'None') test_df['TicketPrefix'] = test_df['Ticket'].apply(lambda x: x.split()[0] if not x.isdigit() else 'None') # 查看数据集中新构造的特征 print(train_df[['Title', 'FamilySize', 'IsAlone', 'Deck', 'TicketPrefix']].head())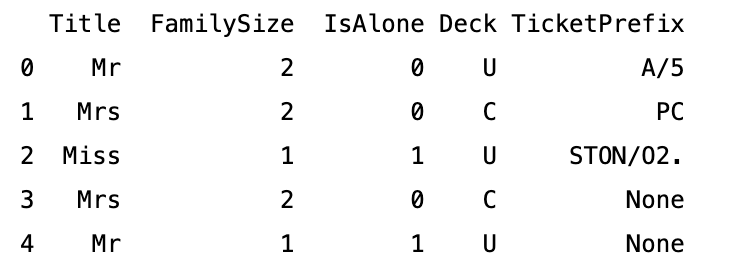
2.3. 特征选择
特征选择的目的是从原始数据中选择最相关的特征子集以用于模型训练。这样做有几个好处:
- 减少过拟合:减少冗余或无关的特征可以降低模型在训练数据上过分拟合的风险。
- 提高准确率:正确的特征子集可以提高模型的预测准确率。
- 减少训练时间:较少的特征意味着模型训练时间减少。
- 增强模型解释性:更少的特征使模型更易于理解和解释。
# 特征选择 y_train = train_df['Survived'] X_train = train_df.drop('Survived', axis=1) forest = RandomForestClassifier(n_estimators=100, random_state=42) forest.fit(X_train, y_train) selector = SelectFromModel(forest, threshold='mean', prefit=True) X_important_train = selector.transform(X_train) important_feature_names = X_train.columns[selector.get_support()] print("Selected features after feature selection:", important_feature_names)RandomForestClassifier被训练在完整的训练数据上,然后SelectFromModel根据随机森林估计出的特征重要性来选择特征。选择标准threshold='mean'意味着将选择重要性大于平均重要性的特征。selector.transform(X_train)创建了一个新的特征矩阵,只包含这些选定的重要特征。selector.get_support()提供了一个布尔数组,用于标识哪些特征被选中。- 最后,打印出的
important_feature_names就是那些被选择的特征的名字。
输出结果如下

详细对每个特征做一些分析,发现passengerId与存活率应该关系不大需要剔除

# 删除不再需要的原始列 drop_columns = ['PassengerId','Name', 'Ticket', 'Cabin', 'Sex', 'Embarked', 'Title'] train_df.drop(columns=drop_columns, inplace=True) test_df.drop(columns=drop_columns, inplace=True)步骤3:建立模型
使用分割后的训练数据(X_train 和 y_train)来训练选定的机器学习模型。这可能包括:
- 设置模型参数:根据模型类型(如逻辑回归、随机森林、支持向量机等),设置初始参数。
- 拟合模型:在训练数据上训练模型,使模型学习数据特征和目标之间的关系。
# 分割数据进行本地验证 X_train, X_valid, y_train, y_valid = train_test_split(X_important_train, y_train, test_size=0.2, random_state=42)使用分割出的验证数据集(X_valid 和 y_valid)来评估模型的性能。常用的评估指标包括:
- 准确率(Accuracy)
- 召回率(Recall)
- 精确率(Precision)
- F1 分数(F1 Score)
- ROC-AUC(Receiver Operating Characteristic - Area Under Curve)
步骤4:模型训练和验证
- 使用训练数据训练模型,并使用验证数据评估模型性能。
- 调整模型参数或尝试不同的模型以提高预测性能。
4.1 训练代码
from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, classification_report # 模型初始化 model = RandomForestClassifier(n_estimators=100, random_state=42) # 模型训练 model.fit(X_train, y_train) # 模型预测 y_pred = model.predict(X_valid) # 模型评估 print("Accuracy:", accuracy_score(y_valid, y_pred)) print("Classification Report:\n", classification_report(y_valid, y_pred)) 4.2 报告解读
准确率 (Accuracy): 81.56%
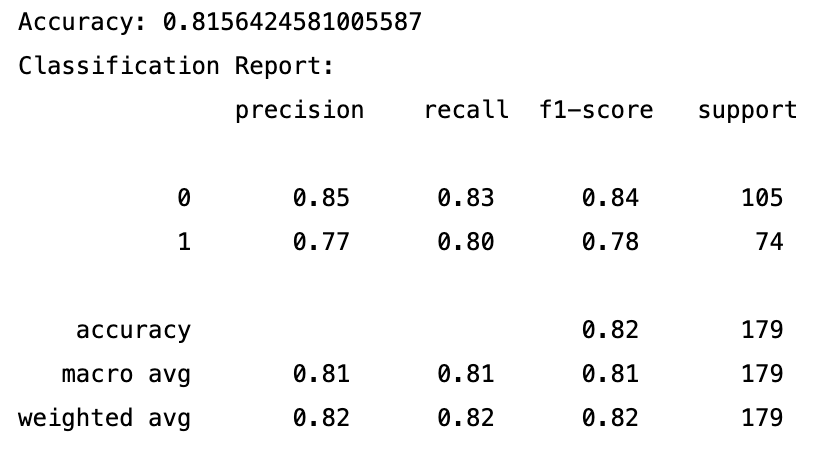
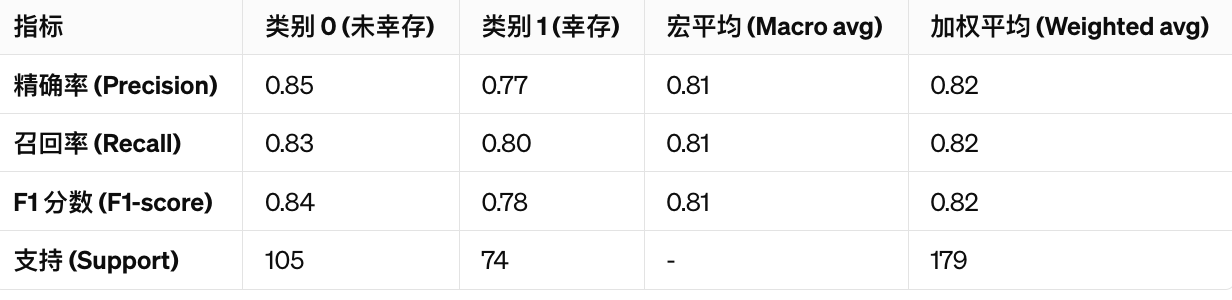
这个模型具有相对较高的准确率,但还有提升的空间。特别是对于分类为幸存(1)的实例,我们可以看到召回率和精确率略低于未幸存(0)的实例。这可能意味着模型在区分幸存者时不如在区分未幸存者那么准确。根据这个报告,我们可能会考虑进一步优化模型,比如通过调整阈值、尝试不同的特征组合、使用不同的算法或调整模型超参数来改进模型性能。
4.3 调参优化
寻找随机森林模型最佳超参数组合的标准流程,并使用找到的最佳模型在验证数据上评估性能
# 超参数调优和模型训练 rfc = RandomForestClassifier(random_state=42) param_grid = { 'n_estimators': [100, 200, 300], 'max_depth': [5, 10, 15], 'min_samples_leaf': [1, 2, 4] } grid_search = GridSearchCV(estimator=rfc, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2) grid_search.fit(X_train, y_train) # 最佳参数模型 best_clf = grid_search.best_estimator_ # 模型评估 y_pred = best_clf.predict(X_valid) print("Accuracy:", accuracy_score(y_valid, y_pred)) print(classification_report(y_valid, y_pred))RandomForestClassifier(random_state=42)初始化了随机森林分类器,并设定了随机种子以确保结果的可重复性。param_grid定义了三个参数:n_estimators、max_depth和min_samples_leaf的搜索范围,GridSearchCV将会尝试这些参数的所有组合。GridSearchCV(...)对象配置了用于搜索的估计器(estimator),参数网格(param_grid),交叉验证折数(cv=5),并行作业数(n_jobs=-1使用所有可用核心),和详细程度(verbose=2显示详细输出)。grid_search.fit(X_train, y_train)在训练数据上运行网格搜索来找出最佳参数。
输出

报告摘要:
- 宏平均精确率、召回率和 F1 分数 (Macro avg): 均为 0.82。
- 加权平均精确率、召回率和 F1 分数 (Weighted avg): 均为 0.83。
- 样本数 (Support): 179。
最佳模型参数:
- 最大树深度 (
max_depth): 5。 - 叶节点最小样本数 (
min_samples_leaf): 1。 - 估计器数量 (
n_estimators): 300。
步骤5:对测试集进行预测并准备提交
5.1 首次提交
- 对测试数据集应用相同的预处理和特征工程步骤。
- 使用训练好的模型对测试集进行预测。
- 创建符合提交要求的CSV文件,通常包括乘客ID和预测的生还状态。
用相同的方式处理训练集,生成预测数据csv
# 训练模型 X_train = train_df.drop(['Survived','PassengerId'], axis=1) y_train = train_df['Survived'] model = RandomForestClassifier(n_estimators=300, max_depth=5, random_state=42) model.fit(X_train, y_train) # 预测测试集 X_test = test_df.drop('PassengerId', axis=1) predictions = model.predict(X_test) # 生成提交文件 submission = pd.DataFrame({'PassengerId': test_df['PassengerId'], 'Survived': predictions}) submission.to_csv('submission.csv', index=False)第一次提交后发现只有 77%的准确率,在kaggle排400名,看来这个赛道还是卷的不行

5.2 增加不同模型
# Define the models to train classifiers = { 'LogisticRegression': LogisticRegression(max_iter=1000, random_state=42), 'SVC': SVC(random_state=42), 'GradientBoosting': GradientBoostingClassifier(random_state=42) }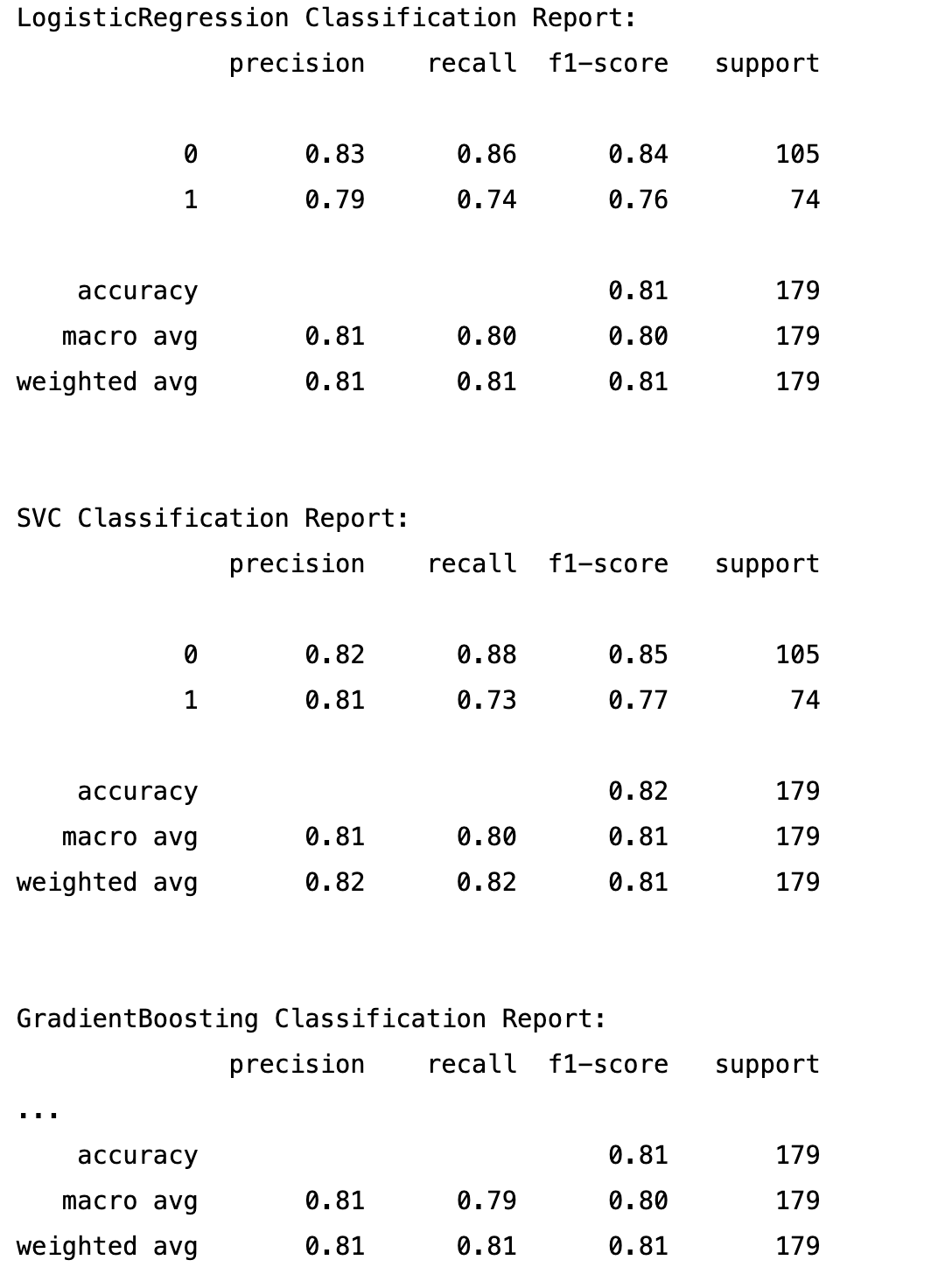
生成不同的上传文件
 完整代码
完整代码
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.ensemble import GradientBoostingClassifier from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from sklearn.impute import SimpleImputer # Load datasets train_df = pd.read_csv('train.csv') test_df = pd.read_csv('test.csv') # Separate features and target y = train_df['Survived'] X = train_df.drop(['Survived', 'PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1) # Define categorical and numerical features categorical_features = ['Sex', 'Embarked'] numerical_features = X.select_dtypes(include=['int64', 'float64']).columns.tolist() # Create preprocessors categorical_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='constant', fill_value='missing')), ('onehot', OneHotEncoder(handle_unknown='ignore')) ]) numerical_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='median')), ('scaler', StandardScaler()) ]) # Combine preprocessors preprocessor = ColumnTransformer( transformers=[ ('num', numerical_transformer, numerical_features), ('cat', categorical_transformer, categorical_features) ] ) # Define the models to train classifiers = { 'LogisticRegression': LogisticRegression(max_iter=1000, random_state=42), 'SVC': SVC(random_state=42), 'GradientBoosting': GradientBoostingClassifier(random_state=42) } # Process of training models and creating submission files for classifier_name, classifier in classifiers.items(): # Create pipeline pipeline = Pipeline(steps=[('preprocessor', preprocessor), ('classifier', classifier)]) # Train the model pipeline.fit(X, y) # Using all available data for training # Make predictions on the test data X_test = test_df.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1) predictions = pipeline.predict(X_test) # Create submission file submission = pd.DataFrame({'PassengerId': test_df['PassengerId'], 'Survived': predictions}) submission_file = f'submission_{classifier_name}.csv' submission.to_csv(submission_file, index=False) print(f"Created submission file: {submission_file}") 