
阅读量:4
目录
3.1.1 corePoolSize | maximumPoolSize:
一、线程池的概念及优势
1.1 线程池的概念:
线程池是一种并发编程的技术,它维护着一组预先创建的线程,以便在需要时重用它们来执行多个任务。这可以提高程序的性能和效率,因为线程的创建和销毁通常是昂贵的操作,通过重用线程,可以减少这种开销。
在我们前面已经介绍了线程比进程更加轻量,在频繁创建销毁的时候,线程更有优势。但是随着时代的发展,对于 “频繁” 有了新的定义(比如之前 1 万就认为是频繁,但是现在可能 1000 万才认为是频繁)。即使是线程,在如此频繁的创建和销毁的情况下,开销也变得难以接受。
那么要怎么优化呢?
答:我们可以通过线程池和协程进行优化。
协程这里我们暂且不进行描述,Go 语言主打的卖点就是使用协程处理并发编程。线程池的优化我们马上讲到。
1.2 线程池的优势:
• 降低资源消耗:
减少线程的创建和销毁带来的性能开销。
• 提高响应速度:
当任务来时可以直接使用,不用等待线程创建
• 可管理性:
进行统一的分配,监控,避免大量的线程间因互相抢占系统资源导致的阻塞现象。
二、工厂模式
在下面即将介绍的线程池参数中,其中有一个参数是工厂类。所以在这里提前给大家解释一下什么是工厂模式。
工厂模式:也是一种设计模式,主要解决的问题是构造方法创建对象太坑了的问题。为什么说构造方法创建对象有坑呢?举个栗子:

因为在 Java 的语法中要求构造方法的命名必须是类名且参数类型和个数,排列顺序不能一样。这就导致遇到上面这种案例解决不了。就需要工厂模式,核心思路,不使用构造方法创建对象,给构造方法包装一层。例如下面这段代码:这只是个伪代码,看看思路就行,makePointByXY 这样的方法就叫 “工厂方法”,这样写代码的套路就叫做 “工厂模式”,没有什么特别的。
public class Point { public static Point makePointByXY(double x,double y){ Point p = new Point(); p.setX(x);//和 setR 是有区别的,比如传给的函数不一样 p.setY(y); return p; } public static Point makePointByRA(double r,double a){ Point p = new Point(); p.setR(r); p.setA(a); return p; } } 工厂类的写法如下图: 工厂方法用单独的类来进行提供。
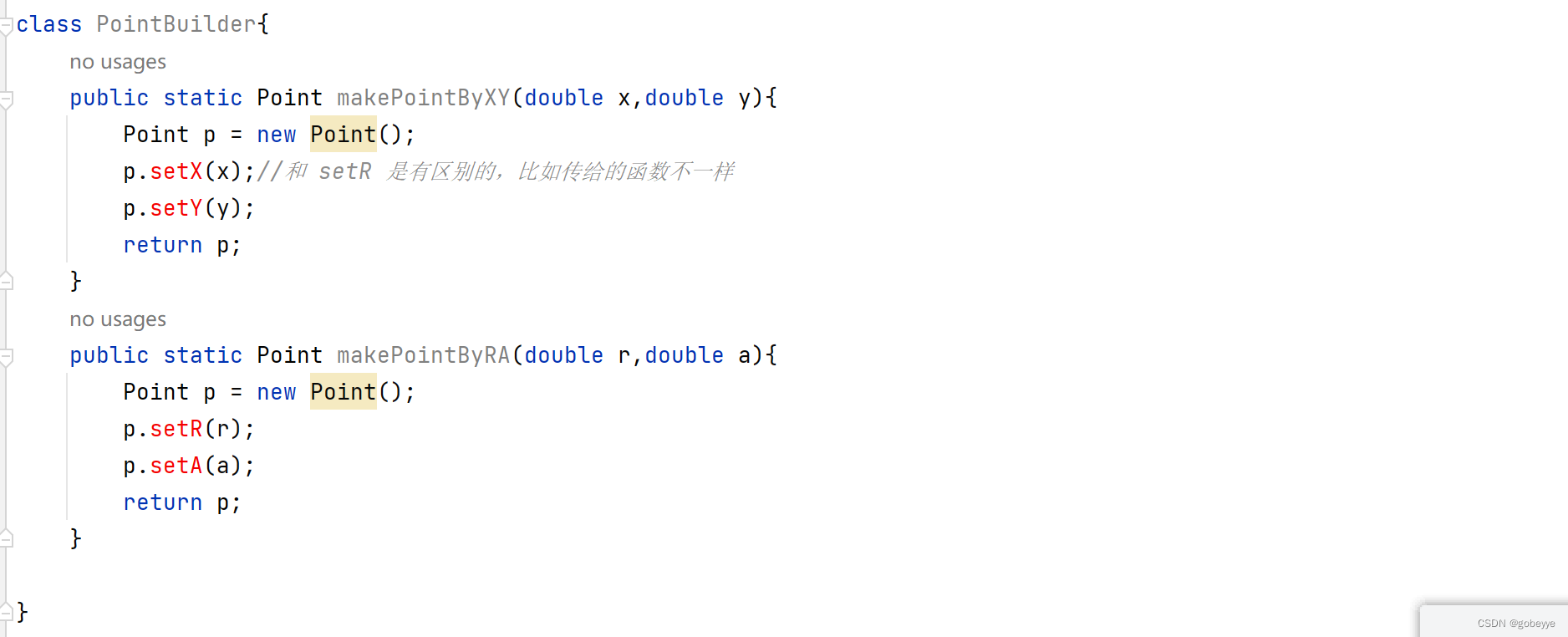
如果语法层面上,不强制要求构造方法名字必须和类名一致,就没有上述模式的必要了。
三、标准库中的线程池
3.1 标准库线程池参数解释:
ThreadPoolExecutor:
使用起来比较复杂,在其构造方法中,包含很多的参数。(面试考点)例如下面这个就是包含全部参数的构造方法,了解这个了,其他的就都会了,下面会围绕这个构造方法参数进行解释。

3.1.1 corePoolSize | maximumPoolSize:

在 Java 的标准库中线程池把线程分成两类:1. 核心线程。2. 非核心线程。
顾名思义 corePoolSize 就是核心线程数,maximumPoolSize 就是最大线程数(核心线程数 + 非核心线程数)。
这里就涉及到动态扩展的概念,在线程池刚开始就会创建出核心线程数的线程(最小线程数),随着项目的进行,如果添加的任务比较多的话,核心线程数处理不过来了(有很多任务在队列中,排队等待执行),这个时候线程池就会自动的创建出新的线程,来支撑更多的任务。但是,创建出来的线程总数不能超过最大线程数(maximumPoolSize),过了一段时间,任务没有那么多了,线程 “清闲下来” 这时部分非核心线程就会被释放掉,线程池中会保证线程数目不少于核心线程数。
这样就既可以保证任务多的时候的效率,也能保证任务少的时候,系统的开销。到这里就又有了一个问题:
在实际开发中,线程数应该设置成多少合适呢?
答:只要是具体的数字,答案一定是错误的。我们要根据实验的方式,对程序进行性能测试,测试过程中,设定不同的线程池的数值。最终根据实际程序的响应速度和系统开销,综合权衡,找到一个合适值。
这不仅仅和电脑的配置有关(有多个 CPU 核心),更重要的是,和我们的程序的实际特点有关系。极端情况下可以分为两大类:
• CPU 密集型程序:代码完成的逻辑,都是要通过 CPU 来完成的.(此时的性能瓶颈是 CPU)。此时线程的数量是不应该超过 CPU 逻辑核心数的。
• IO 密集型程序:代码大部分时间在等待 IO(等待 IO 是不消耗 CPU,不参与调度)。此时瓶颈就不在 CPU 上,我们更多考虑其他方面(比如网络程序,要考虑网卡宽带的瓶颈)。
3.1.2 keepAliveTime | unit:

• keepAliveTime:
表示非核心线程,允许空闲的最大时间。也就是说非核心线程在线程池 ”不忙“ 的时候不是马上回收掉。
• unit:
TimeUnit:这是一个枚举类型。其中的枚举常量有:

3.1.3 workQueue:

阻塞队列我们上一篇文章已经自己实现过了,这里利用阻塞队列要存储 Runnable 对象也就是要执行的任务。线程池会提供 submit 方法,让其他线程把任务提交给线程池。其他线程会 submit 任务到这个队列中,这个队列存的元素就是 Runnable 对象,要执行的逻辑就是 run 方法里面的内容。
3.1.4 ThreadFactory:

ThreadFactory:是标准库中提供的,用来创建线程的工厂类。这个线程工厂,主要是为了批量的给创建的线程设置一些属性, 线程工厂在它的工厂方法中,把线程的属性提前初始化好了。至于什么是工厂类,在上面的工厂模式那里已经解释过了,这里就不再赘述。
3.1.5 handler:

面试官问线程池的参数都是什么意思?其实就是在考我们对于这个参数的理解,前面 6 个都是添头。注意:此处 Handler 不是句柄的意思(句柄的术语也是 Handler)。
这里可以理解为拒绝策略,如果当前任务队列满了,仍要继续添加任务,咋办呢?直接阻塞其实不太合适。所以这里多了一个拒绝策略的参数。
幸运的是,我们 Java 的大佬已经给我们实现了四种常用的拒绝策略,在 ThreadPoolExecutor 类的里面,有四种静态内部类,列举如下:
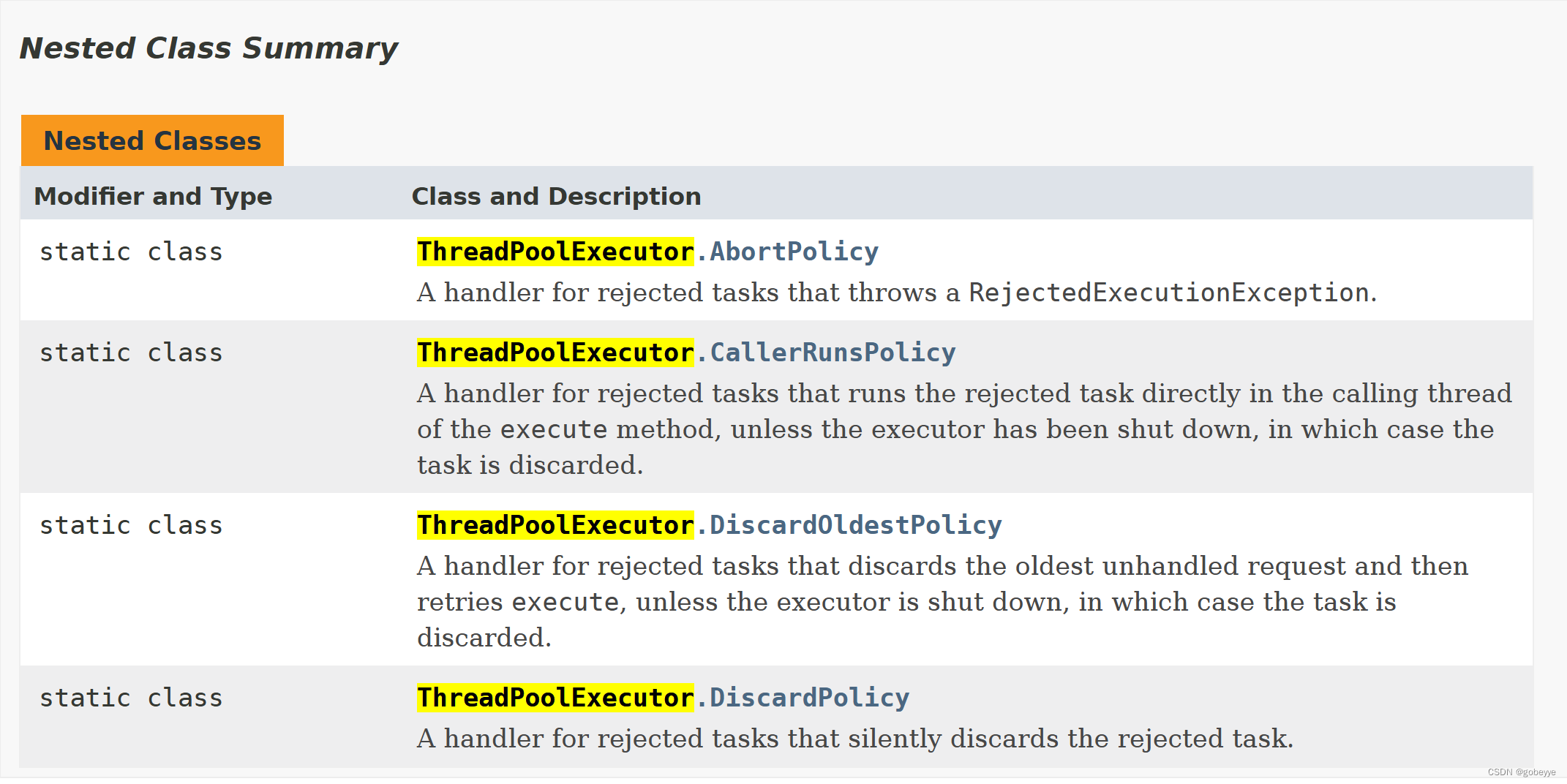
对上面四种拒接策略的简单翻译如下:
• AbortPolicy():超过负荷,直接抛出异常。
• CallerRunsPolicy():调用者负责处理多出来的任务。
• DiscardOldestPolicy():丢弃队列中最老的任务。
• DiscardPolicy():丢弃新来的任务。
3.2 创建线程池演示:
这里唯一有些难度的就是拒绝策略的创建,在 ThreadPoolExecutor 类中有四个内部类实现了 RejectedExecutionHandler 接口。具体代码如下:
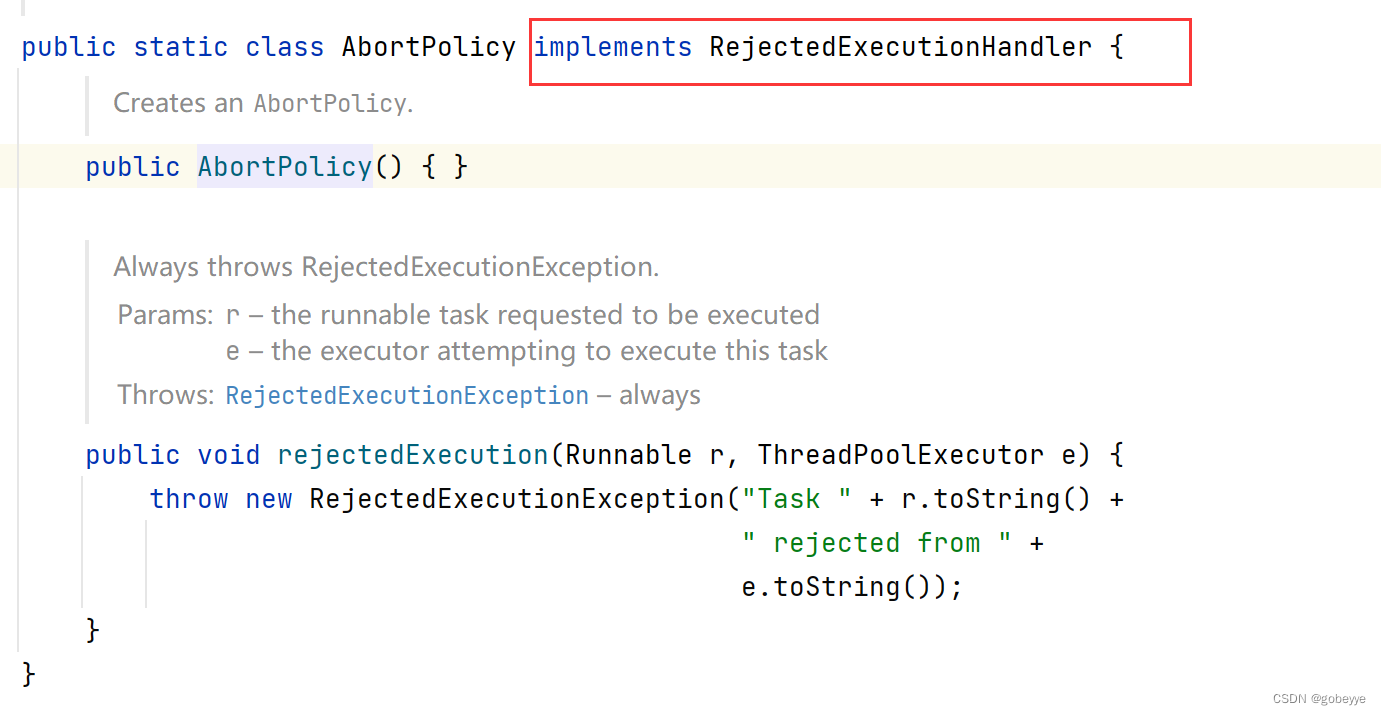
简单的编写如下:
import java.util.concurrent.*; public class demo3 { public static void main(String[] args) { BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(5);//阻塞队列 ThreadFactory factory = new ThreadFactory() {//工厂模式 @Override public Thread newThread(Runnable r) { return new Thread(r);//这里就可以对 Thread 设置一些参数 } }; RejectedExecutionHandler handler = new ThreadPoolExecutor.AbortPolicy();//拒绝策略,注意这里是调用 ThreadPoolExecutor 的静态内部类 ThreadPoolExecutor pool = new ThreadPoolExecutor(3,6,100,TimeUnit.DAYS, queue,factory,handler); } } 3.3 利用线程池的工厂类来创建线程池:
使用线程池的工厂类来创建线程池的方法一共有 6 种,其中我们重点理解下面给出的四种即可。
工厂类为:Executors ,这里产生的线程池为 ExecutorService 类。具体如下图:
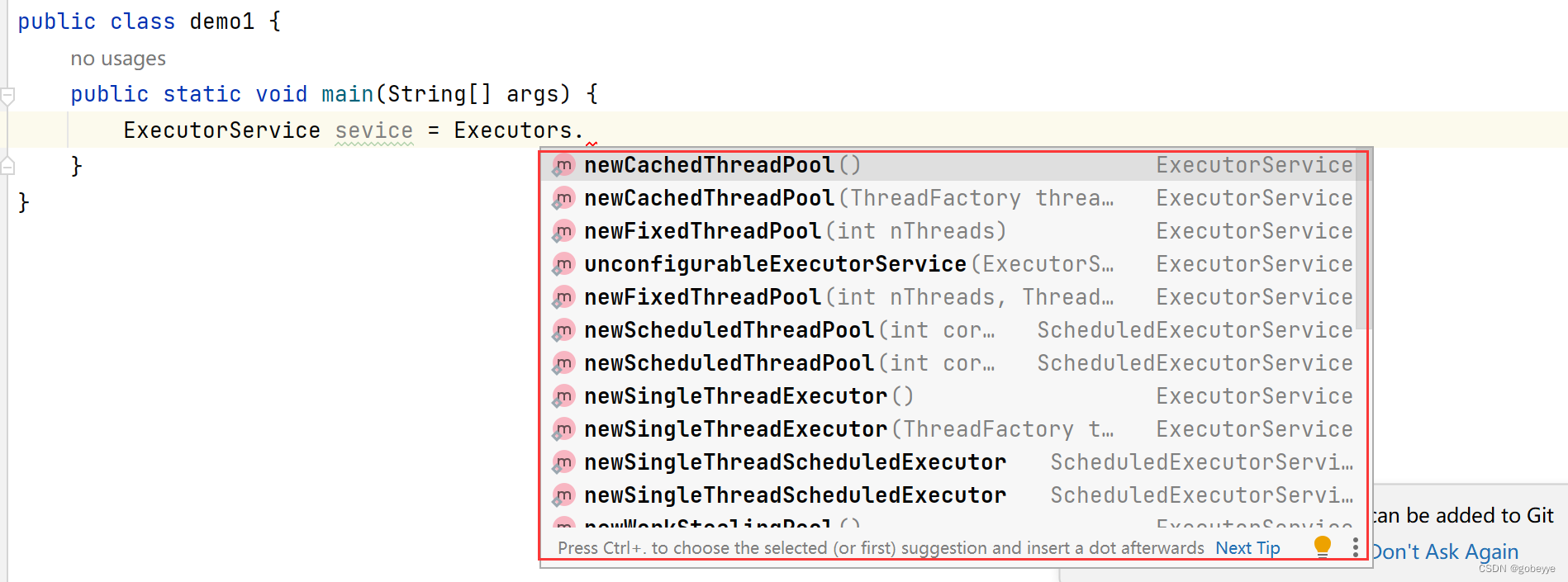
可以看到官方提供的创建线程池的工厂方法还是很多的。我们主要理解下面这四个即可。
import java.util.concurrent.Executors; import java.util.concurrent.ExecutorService; public class demo1 { public static void main(String[] args) { //能够根据任务数量,自动进行线程扩容的线程池 ExecutorService sevice1 = Executors.newCachedThreadPool(); //创建固定线程数目的线程池 ExecutorService service2 = Executors.newFixedThreadPool(4); //创建只包含单个线程的线程池 ExecutorService service3 = Executors.newSingleThreadExecutor(); //创建固定数目的线程个数,但是任务延时执行的线程池 ExecutorService service4 = Executors.newScheduledThreadPool(4); } } Executors 创建线程池的几种方式:
• newFixedThreadPool:创建固定线程数的线程池。
• newCachedThreadPool:创建线程数目动态增长的线程池。
• newSingleThreadExecutor:创建只包含单个线程的线程池。
• newScheduledThreadPool:设定延迟时间后执行命令,或者定期执行命令。
Executors 本质上是 ThreadPoolExecutor 类的封装。
3.4 线程池的使用演示:
我们可以利用 submit 来进行添加任务(每个都必须实现 Runnable 接口)。
import java.util.concurrent.*; public class demo1 { public static void main(String[] args) { ExecutorService service1 = Executors.newCachedThreadPool(); for(int i = 1;i <= 1000;i++){ int id = i;//这里必须要使用 id 来接受 i service1.submit(new Runnable() {//匿名内部类 @Override public void run() { System.out.println(id +" , " + Thread.currentThread().getName());//必须只能打印 id,打印 i 会报错 //报错的原因为:变量捕捉 } }); } } } 案例演示的结果如下:
至于剩下三个线程池都是一样的,这里就不过多赘述了。 如果只是简单的使用一下,就直接用工厂类即可,如果希望更加精细的控制,就使用原生的 ThreadPoolExecutor。所以 Java 标准库线程池的创建方式一共有 7 种。
四、线程池的实现
为了更加深入的理解线程池的使用,这里我们就来简单的实现一个简易的线程池。我们要实现的东西有1. 若干线程。2. 任务队列。3. 提供 submit 方法。
我们可以利用 ArrayList 来存储线程,利用阻塞队列来辅助完成线程池,创建一个能自动扩容的线程池,每个线程的任务就是不停的去阻塞队列中取元素然后执行。剩下的一些在代码中都有注释。
代码实现如下:
import java.util.concurrent.*; import java.util.*; //自己实现一个线程池 class MyThreadPool{ //1. 线程 private int corePoolSize;//核心线程数 private int maximumPoolSize;//最大线程数 private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(1000); private List<Thread> threads = new ArrayList<>();//存储线程 public MyThreadPool(int coreThreadSize,int maximumPoolSize) throws InterruptedException { this.corePoolSize = coreThreadSize; this.maximumPoolSize = maximumPoolSize; for(int i = 0;i < coreThreadSize;i++){ Thread t = newThread(); t.start(); threads.add(t); } } private Thread newThread(){ //每个线程的任务就是不停的执行队列中的元素 Thread t = new Thread(() -> { while(true){ try { Runnable task = queue.take(); task.run(); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); return t; } //2. 阻塞队列 //3. submit 方法 public void submit(Runnable task) throws InterruptedException { queue.put(task); //如果队列中的元素大于一个阈值,且线程数小于最大线程数时,就可以创建新的线程来帮助,处理队列中的元素 if(queue.size() >= 50 && threads.size() < maximumPoolSize){ //创建 线程 Thread t = newThread(); t.start(); threads.add(t); } } } public class demo3 { public static void main(String[] args) throws InterruptedException { MyThreadPool threadPool = new MyThreadPool(4,50); for(int i = 0;i < 10000;i++) { int id = i; threadPool.submit(new Runnable(){ @Override public void run(){ System.out.println("hello " + id + " ," + Thread.currentThread().getName()); } }); } } }具体效果如下:
如果要实现拒绝策略的话,也是在 submit 这里实现。
结语:
其实写博客不仅仅是为了教大家,同时这也有利于我巩固知识点,和做一个学习的总结,由于作者水平有限,对文章有任何问题还请指出,非常感谢。如果大家有所收获的话还请不要吝啬你们的点赞收藏和关注,这可以激励我写出更加优秀的文章。

