
阅读量:3
弹性网络回归算法简介
在机器学习领域中,弹性网络(Elastic Net)是一种结合了L1范数(套索回归)和L2范数(岭回归)的正则化方法。它综合了两者的优点,既可以实现特征选择,又可以处理多重共线性。弹性网络在实际应用中具有广泛的用途,因此,在这篇文章中我们将探讨弹性网络正则化的公式、应用场景、优势以及如何调节超参数等方面。一般线性Elastic Net模型的目标函数:
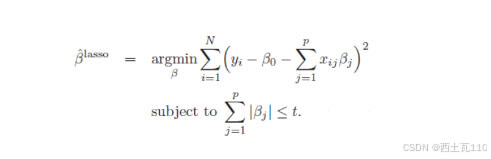
目标函数的第一行与传统线性回归模型完全相同,即我们希望得到相应的自变量系数β,以此最小化实际因变量y与预测应变量βx之间的误差平方和。 而线性Elastic Net与线性回归的不同之处就在于有无第二行的这个约束,线性Elastic Net希望得到的自变量系数是在由t控制的一个范围内。 这一约束也是Elastic Net模型能进行复杂度调整,LASSO回归能进行变量筛选和复杂度调整的原因。 我们可以通过下面的这张图来解释这个道理:
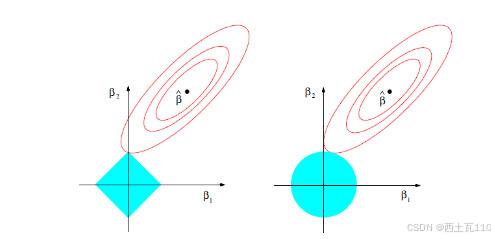
先看左图,假设一个二维模型对应的系数是β1和β2,然后是最小化误差平方和的点,即用传统线性回归得到的自变量系数。 但我们想让这个系数点必须落在蓝色的正方形内,所以就有了一系列围绕的同心椭圆,其中最先与蓝色正方形接触的点,就是符合约束同时最小化误差平方和的点。 这个点就是同一个问题LASSO回归得到的自变量系数。 因为约束是一个正方形,所以除非相切,正方形与同心椭圆的接触点往往在正方形顶点上。而顶点又落在坐标轴上,这就意味着符合约束的自变量系数有一个值是0。 所以这里传统线性回归得到的是β1和β2都起作用的模型,而LASSO回归得到的是只有β2有作用的模型,这就是LASSO回归能筛选变量的原因。
而正方形的大小就决定了复杂度调整的程度。假设这个正方形极小,近似于一个点,那么LASSO回归得到的就是一个只有常量(intercept)而其他自变量系数都为0的模型,这是模型简化的极端情况。 由此我们可以明白,控制复杂度调整程度的λ值与约束大小t是呈反比的,即λ值越大对参数较多的线性模型的惩罚力度就越大,越容易得到一个简单的模型。
另外,我们之前提到的参数α就决定了这个约束的形状。刚才提到LASSO回归(α=1)的约束是一个正方形,所以更容易让约束后的系数点落在顶点上,从而起到变量筛选或者说降维的目的。 而Ridge回归(α=0)的约束是一个圆,与同心椭圆的相切点会在圆上的任何位置,所以Ridge回归并没有变量筛选的功能。 相应的,当几个自变量高度相关时,LASSO回归会倾向于选出其中的任意一个加入到筛选后的模型中,而Ridge回归则会把这一组自变量都挑选出来。 至于一般的Elastic Net模型(0<α<1),其约束的形状介于正方形与圆形之间,所以其特点就是在任意选出一个自变量或者一组自变量之间权衡。
弹性网络回归算法模型介绍
弹性网络回归算法的代价函数结合了Lasso回归和岭回归的正则化方法,通过两个参数 λ 和 ρ 来控制惩罚项的大小。
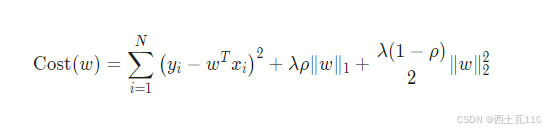
同样是求使得代价函数最小时 w 的大小:
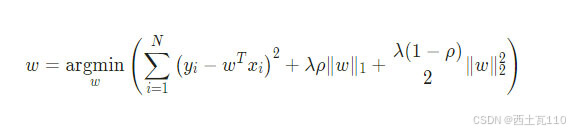
可以看到,当 ρ = 0 时,其代价函数就等同于岭回归的代价函数,当 ρ = 1 时,其代价函数就等同于 Lasso 回归的代价函数。与 Lasso 回归一样代价函数中有绝对值存在,不是处处可导的,所以就没办法通过直接求导的方式来直接得到 w 的解析解,不过还是可以用坐标下降法2(coordinate descent)来求解 w。
弹性网络回归算法步骤
坐标下降法
坐标下降法的求解方法与 Lasso 回归所用到的步骤一样,唯一的区别只是代价函数不一样。
具体步骤:
- 初始化权重系数 w,例如初始化为零向量。
- 遍历所有权重系数,依次将其中一个权重系数当作变量,其他权重系数固定为上一次计算的结果当作常量,求出当前条件下只有一个权重系数变量的情况下的最优解。在第 k 次迭代时,更新权重系数的方法如下:

- 步骤2为一次完整迭代,当所有权重系数的变化不大或者到达最大迭代次数时,结束迭代。
弹性网络回归算法代码实现
使用 Python 实现弹性网络回归算法(坐标下降法):
def elasticNet(X, y, lambdas=0.1, rhos=0.5, max_iter=1000, tol=1e-4): """ 弹性网络回归,使用坐标下降法(coordinate descent) args: X - 训练数据集 y - 目标标签值 lambdas - 惩罚项系数 rhos - 混合参数,取值范围[0,1] max_iter - 最大迭代次数 tol - 变化量容忍值 return: w - 权重系数 """ # 初始化 w 为零向量 w = np.zeros(X.shape[1]) for it in range(max_iter): done = True # 遍历所有自变量 for i in range(0, len(w)): # 记录上一轮系数 weight = W[i] # 求出当前条件下的最佳系数 w[i] = down(X, y, w, i, lambdas, rhos) # 当其中一个系数变化量未到达其容忍值,继续循环 if (np.abs(weight - w[i]) > tol): done = False # 所有系数都变化不大时,结束循环 if (done): break return w def down(X, y, w, index, lambdas=0.1, rhos=0.5): """ cost(w) = (x1 * w1 + x2 * w2 + ... - y)^2 / 2n + ... + λ * ρ * (|w1| + |w2| + ...) + [λ * (1 - ρ) / 2] * (w1^2 + w2^2 + ...) 假设 w1 是变量,这时其他的值均为常数,带入上式后,其代价函数是关于 w1 的一元二次函数,可以写成下式: cost(w1) = (a * w1 + b)^2 / 2n + ... + λρ|w1| + [λ(1 - ρ)/2] * w1^2 + c (a,b,c,λ 均为常数) => 展开后 cost(w1) = [aa / 2n + λ(1 - ρ)/2] * w1^2 + (ab / n) * w1 + λρ|w1| + c (aa,ab,c,λ 均为常数) """ # 展开后的二次项的系数之和 aa = 0 # 展开后的一次项的系数之和 ab = 0 for i in range(X.shape[0]): # 括号内一次项的系数 a = X[i][index] # 括号内常数项的系数 b = X[i][:].dot(w) - a * w[index] - y[i] # 可以很容易的得到展开后的二次项的系数为括号内一次项的系数平方的和 aa = aa + a * a # 可以很容易的得到展开后的一次项的系数为括号内一次项的系数乘以括号内常数项的和 ab = ab + a * b # 由于是一元二次函数,当导数为零是,函数值最小值,只需要关注二次项系数、一次项系数和 λ return det(aa, ab, X.shape[0], lambdas, rhos) def det(aa, ab, n, lambdas=0.1, rhos=0.5): """ 通过代价函数的导数求 w,当 w = 0 时,不可导 det(w) = [aa / n + λ(1 - ρ)] * w + ab / n + λρ = 0 (w > 0) => w = - (ab / n + λρ) / [aa / n + λ(1 - ρ)] det(w) = [aa / n + λ(1 - ρ)] * w + ab / n - λρ = 0 (w < 0) => w = - (ab / n - λρ) / [aa / n + λ(1 - ρ)] det(w) = NaN (w = 0) => w = 0 """ w = -(ab / n + lambdas * rhos) / (aa / n + lambdas * (1 - rhos)) if w < 0: w = -(ab / n - lambdas * rhos) / (aa / n + lambdas * (1 - rhos)) if w > 0: w = 0 return w弹性网络回归算法动画演示
下面动图展示了不同的 ρ 对弹性网络回归的影响,当 ρ 逐渐增大时,L1正则项占据主导地位,代价函数越接近Lasso回归,当 ρ 逐渐减小时,L2正则项占据主导地位,代价函数越接近岭回归。
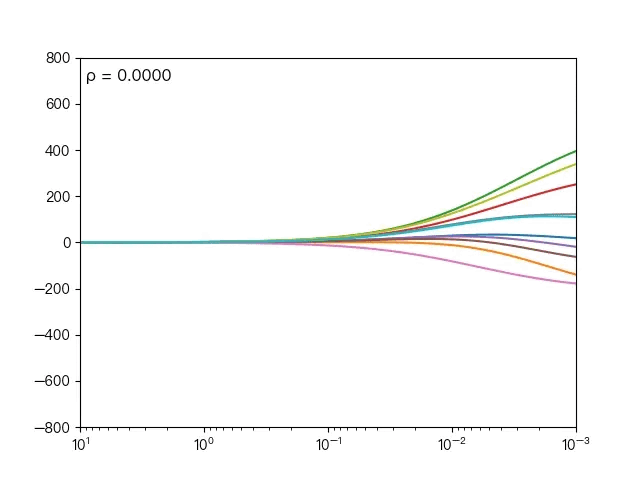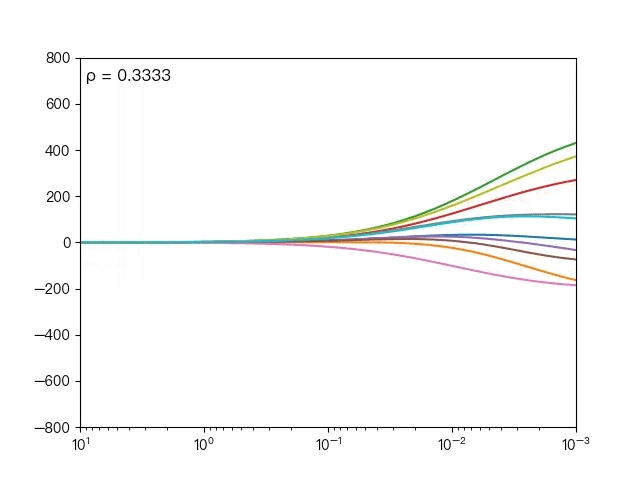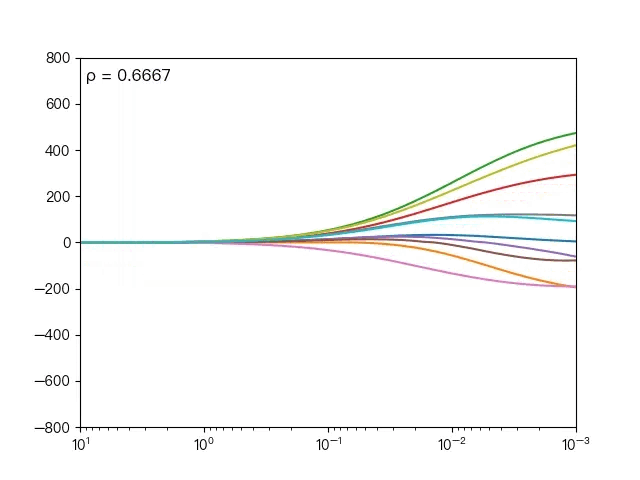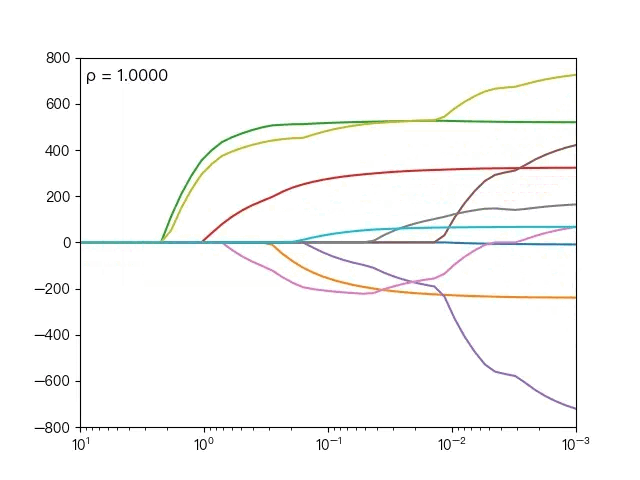
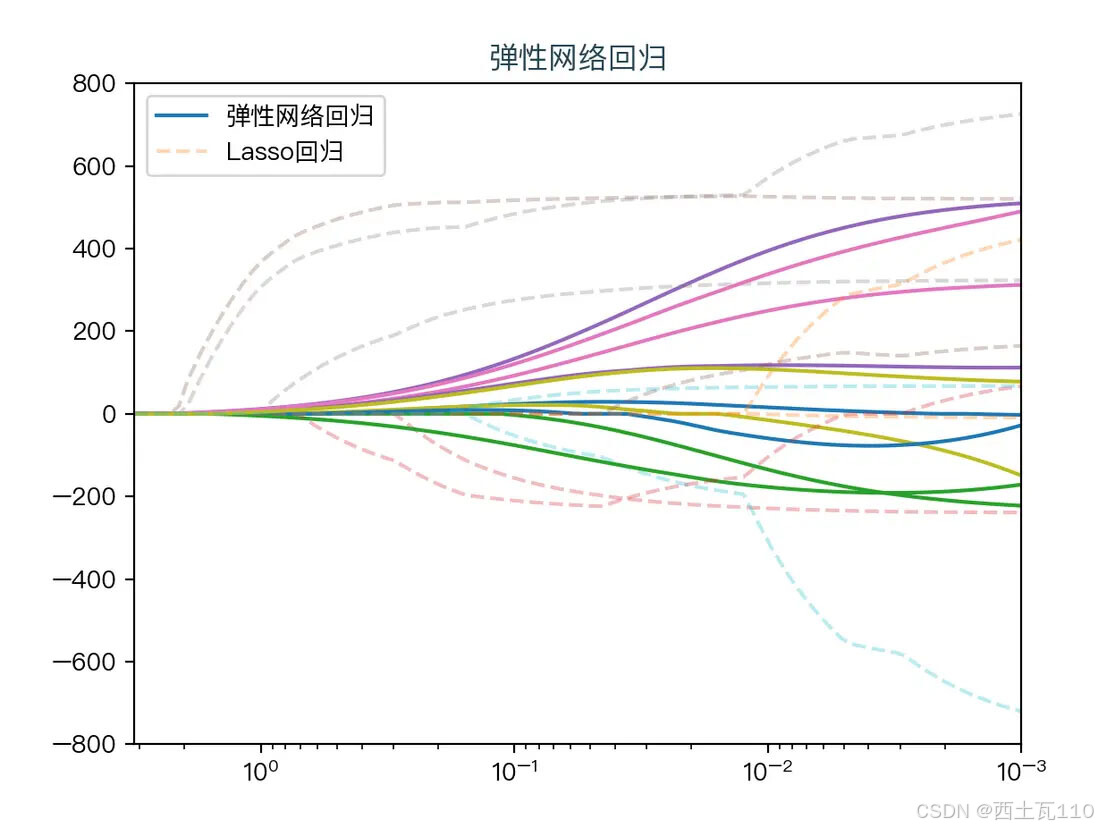
下面动图展示了Lasso回归与弹性网络回归对比,虚线表示Lasso回归的十个特征,实线表示弹性网络回归的十个特征,每一个颜色表示一个自变量的权重系数(训练数据来源于sklearn diabetes datasets)
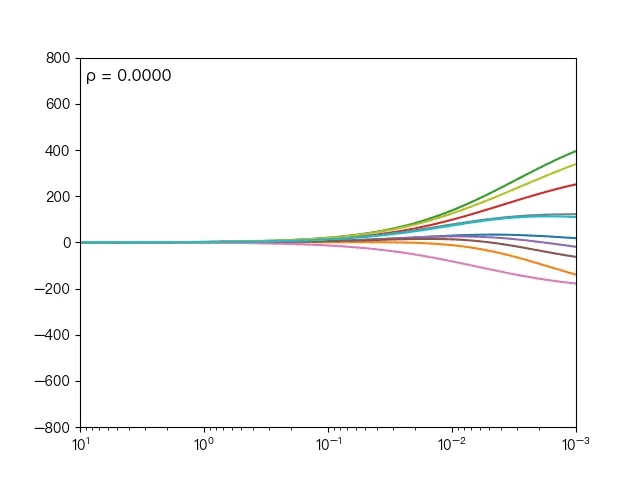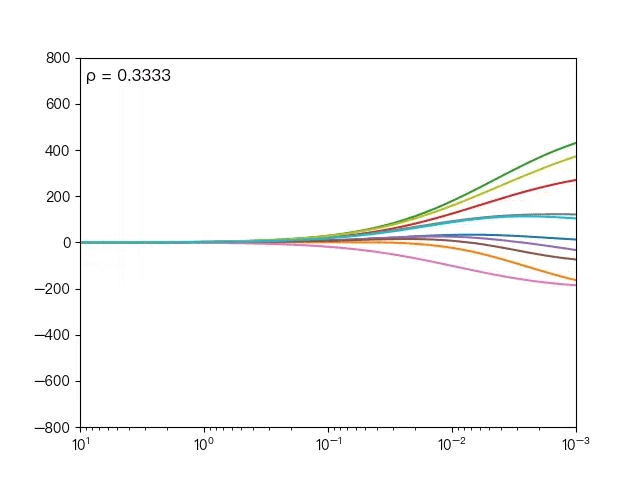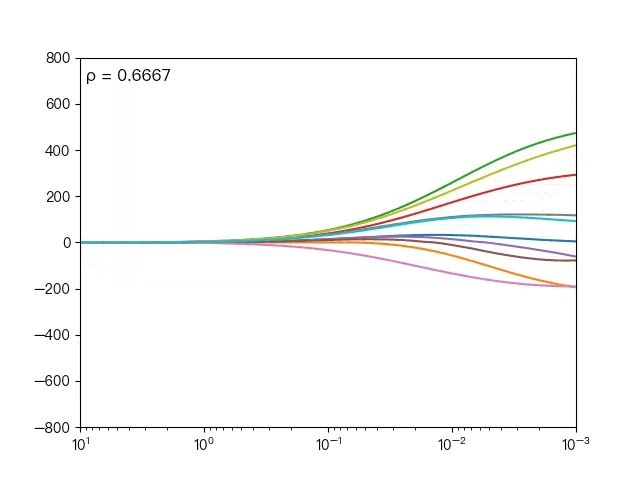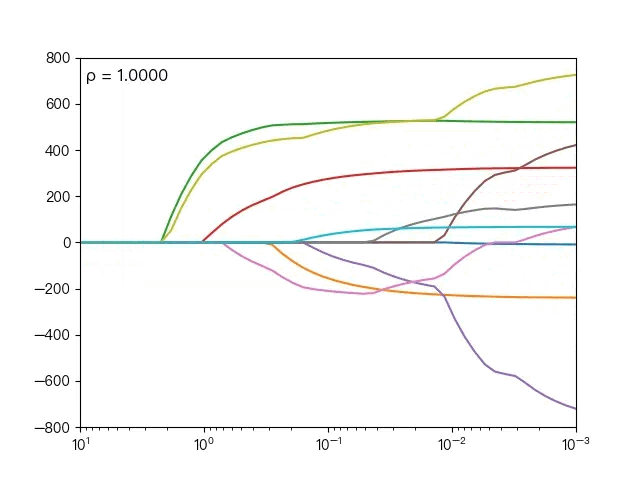
Lasso回归与弹性网络回归对比
弹性网络回归算法优势和劣势
- 优势:弹性网络综合了套索回归和岭回归的优点,既能实现特征选择,又能处理多重共线性;对噪声具有一定的鲁棒性;适用于高维数据和具有相关特征的情况。
- 劣势:需要调节两个超参数,增加了模型的复杂度;在特征高度相关的情况下,可能无法有效区分特征的重要性。
弹性网络回归算法的应用场景
- 处理高维数据:当数据集具有大量特征时,弹性网络可以帮助筛选出最重要的特征,避免过拟合问题和提高模型泛化能力。
- 处理共线性:弹性网络能够处理特征之间存在较强相关性的情况,通过综合考虑L1和L2正则化的效果,可以更好地稳定模型参数估计。
- 噪声较多的情况:弹性网络对噪声具有一定的鲁棒性,可以减小噪声对模型的影响,提高模型的预测准确性。
