
阅读量:3
Sharding-JDBC系列
2、Sharding-JDBC分库分表之SpringBoot分片策略
3、Sharding-JDBC分库分表之SpringBoot主从配置
4、SpringBoot集成Sharding-JDBC-5.3.0分库分表
前言
Apache ShardingSphere,作为全球知名的基础软件开源项目,最早可追溯到 2015 年。其最初版本是当当网内部项目孵化而成,其目的是为了解决数据库水平拆分而产生的分布式问题。在 2016 年正式开源,逐渐得到了更多公司的关注和贡献,项目规模和影响力逐步扩大。在 2018 年, 该项目进入Apache 基金会孵化器,并于 2020 年成为顶级项目成功孵化。
ShardingSphere 4.x版本是在2019年发布,5.x版本是在2021年发布。在2020年成为Apache基金会顶级项目之后,特别是到5.3.0,在规范化、性能优化、分片策略等做了很多改动。
《Sharding-JDBC系列》的前3篇博文都是基于Sharding-JDBC-4.1.1,5.x 之后有许多改动,以下以ShardingSphere 5.3.0版本,分享ShardingSphere在SpringBoot中的使用。
准备工作
以下以订单分表为例,介绍Sharding-JDBC 5.3.0的基本使用。
1)订单表:订单表的字段有订单id、会员id、总价格、状态、下单时间;
2)创建两个订单表,分表为tb_order_1和tb_order_2;
3)分表规则:以订单id分表,id被2整除的放tb_order_1,不能被2整除的放tb_order_2;
本篇的示例和Sharding-JDBC分库分表的基本使用-CSDN博客是一样,只是使用的Sharding-JDBC的版本不一样,可以对比着查看。
导入依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.7.1</version> <relativePath/> <!-- lookup parent from repository --> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>Sharding-JDBC-demo2</artifactId> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.1</version> </dependency> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-jdbc-core</artifactId> <version>5.3.0</version> </dependency> <dependency> <groupId>org.yaml</groupId> <artifactId>snakeyaml</artifactId> <version>1.33</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.28</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.22</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <optional>true</optional> <scope>runtime</scope> </dependency> </dependencies> </project>Sharding-JDBC 5.3.0的依赖是shardingsphere-jdbc-core;
在5.x之前,依赖是sharding-jdbc-spring-boot-starter。5.0到5.2,依赖是shardingsphere-jdbc-core-spring-boot-starter;
如果springboot的版本为2.x,会提示org.yaml.snakeyaml.LoaderOptions找不到setCodePointLimit()方法。该类在snakeyaml.jar包,且1.33之后才有这个方法。springboot依赖的snakeyaml为1.30。解决方式如下:
1)方法1:使用springboot 3.x的版本,jdk需要升级到17。idea也要升级为2022之后的版本;
2)方法2:手动引入snakeyaml.jar的1.33版本;
yml配置
从 5.1.2 版本开始,Sharding-JDBC提供了原生JDBC驱动ShardingSphereDriver。在5.3.x之后,配置也做了规范化处理。
4.1 application.yml的配置
server: port: 8080 spring: main: # 处理连接池冲突 allow-bean-definition-overriding: true datasource: driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver url: jdbc:shardingsphere:classpath:sharding.yml在spring.datasource.url中,配置shardingsphere的配置文件路径为sharding.yml
4.2 sharding.yml的配置
dataSources: order_ds: dataSourceClassName: com.zaxxer.hikari.HikariDataSource driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/shardingjdbctest?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false username: root password: 123456 rules: - !SHARDING tables: tb_order: #逻辑表 actualDataNodes: order_ds.tb_order_$->{1..2} #order1:数据源名称;两个tb_order表,分别为tb_order_1和tb_order_2 keyGenerateStrategy: # 指定主键生成策略 column: order_id keyGeneratorName: snowflake tableStrategy: standard: #没有inline策略 shardingColumn: order_id #分片键。对id进行分表 shardingAlgorithmName: order_inline shardingAlgorithms: #分片算法 order_inline: #算法名称 type: inline #算法类型 props: algorithm-expression: tb_order_$->{order_id % 2 + 1} #分片算法 keyGenerators: # 主键生成器 snowflake: type: SNOWFLAKE props: sql-show: true # 是否打印sql1)独立分片规则的文件,与Spring分离;
2)以驼峰命名取代了下划线命名;
3)在tables规则中,只配置策略及对应算法名称;
4)分片策略中,取消了inline类型的分片策略,只作为标准分片中的inline算法类型;
5)独立分片算法、主键生成器等,当不同的table需要相同的算法时,可以复用;
详细配置查看:YAML 配置 :: ShardingSphere
实体类
package com.jingai.sharing.jdbc.entity; import com.baomidou.mybatisplus.annotation.TableName; import lombok.Data; import lombok.ToString; import java.util.Date; @Data @ToString @TableName("tb_order") public class OrderEntity { private long orderId; private long memberId; private float totalPrice; private String status; private Date orderTime; }在实体类中,@TableName指定配置中的逻辑表。
Mapper类
package com.jingai.sharing.jdbc.dao; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.jingai.sharing.jdbc.entity.OrderEntity; import org.apache.ibatis.annotations.Insert; import org.apache.ibatis.annotations.Options; public interface OrderMapper extends BaseMapper<OrderEntity> { @Insert("insert into tb_order(member_id, total_price, status, order_time) values " + "(#{memberId}, #{totalPrice}, #{status}, #{orderTime})") @Options(useGeneratedKeys = true, keyProperty = "orderId") int insert2(OrderEntity order); } 在5.2的配置中,通过key-generator设置了逻辑表的主键生成策略为雪花算法。当进行数据插入时,需要编写新的插入接口,不能直接使用Mybatis-plus中的insert()接口。因为在默认的insert()接口中,实体对象的orderId为0,不会走配置的雪花算法。
Service类
package com.jingai.sharing.jdbc.service; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import com.jingai.sharing.jdbc.dao.OrderMapper; import com.jingai.sharing.jdbc.entity.OrderEntity; import org.springframework.stereotype.Service; import javax.annotation.Resource; @Service public class OrderService extends ServiceImpl<OrderMapper, OrderEntity> { @Resource private OrderMapper orderMapper; public long insert2(OrderEntity order) { int rs = orderMapper.insert2(order); return rs > 0 ? order.getOrderId() : 0; } } 为了便于测试,此处省略了Service的接口类。
Controller类
@RestController public class OrderController { @Resource private OrderService orderService; @RequestMapping("order") public String order(OrderEntity order) { order.setOrderTime(new Date()); long insert = orderService.insert2(order); return insert > 0 ? "success" : "fail"; } @RequestMapping("list") public List<OrderEntity> list() { return orderService.list(); } }8.1 访问order接口
访问order接口,添加记录,打印的日志如下:
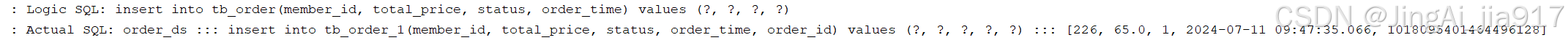
id为1018095401464496128,分片到tb_order_1。
8.2 访问list接口
访问list接口,查询全部数据,打印的日志如下:

由于list是查询全部,所以会进行全局扫描查询,需要查询tb_order_1和tb_order_2两个表。此处通过union all,一次性查询了两张表。
对比Sharding-JDBC-4.1.1,对于全局查询,打印的日志如下:

同样是查询tb_order_1和tb_order_2两个表,但是分开两次查询。
小结
以下对比 5.3.0 版本与 4.1.1 的差别:
1)引入的依赖不同,5.3.0 为 shardingsphere-jdbc-core,4.1.1 是sharding-jdbc-spring-boot-starter;
2)配置不同。4.1.1 中的分片策略在application.yml中进行配置,5.3.0 在application.yml中只配置了分片策略的文件路径,分片策略在专门的分片策略文件中配置;
3)5.3.0 相比 4.1.1,提供了许多分片算法。如基于取模的分片算法、基于可变时间范围的分片算法等;
4)5.3.0 相比 4.1.1,某些功能的性能得到了优化;
关于本篇内容你有什么自己的想法或独到见解,欢迎在评论区一起交流探讨下吧。
