
阅读量:0
以下结合案例:统计消息中单词出现次数,来测试并说明kafka消息流式处理的执行流程
Maven依赖
<dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams</artifactId> <exclusions> <exclusion> <artifactId>connect-json</artifactId> <groupId>org.apache.kafka</groupId> </exclusion> <exclusion> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> </dependency> </dependencies> 准备工作
首先编写创建三个类,分别作为消息生产者、消息消费者、流式处理者KafkaStreamProducer:消息生产者
public class KafkaStreamProducer { public static void main(String[] args) throws ExecutionException, InterruptedException { Properties properties = new Properties(); //kafka的连接地址 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.246.128:9092"); //发送失败,失败的重试次数 properties.put(ProducerConfig.RETRIES_CONFIG, 5); //消息key的序列化器 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); //消息value的序列化器 properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> producer = new KafkaProducer<>(properties); for (int i = 0; i < 5; i++) { ProducerRecord<String, String> producerRecord = new ProducerRecord<>("kafka-stream-topic-input", "hello kafka"); producer.send(producerRecord); } producer.close(); } } 该消息生产者向主题kafka-stream-topic-input发送五次hello kafkaKafkaStreamConsumer:消息消费者
public class KafkaStreamConsumer { public static void main(String[] args) { Properties properties = new Properties(); //kafka的连接地址 properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.246.128:9092"); //消费者组 properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group1"); //消息的反序列化器 properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); //手动提交偏移量 properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties); //订阅主题 consumer.subscribe(Collections.singletonList("kafka-stream-topic-output")); try { while (true) { ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { System.out.println("consumerRecord.key() = " + consumerRecord.key()); System.out.println("consumerRecord.value() = " + consumerRecord.value()); } // 异步提交偏移量 consumer.commitAsync(); } } catch (Exception e) { e.printStackTrace(); } finally { // 同步提交偏移量 consumer.commitSync(); } } } KafkaStreamQuickStart:流式处理类
public class KafkaStreamQuickStart { public static void main(String[] args) { Properties properties = new Properties(); properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.246.128:9092"); properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); properties.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-quickstart"); StreamsBuilder streamsBuilder = new StreamsBuilder(); //流式计算 streamProcessor(streamsBuilder); KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(), properties); kafkaStreams.start(); } /** * 消息格式:hello world hello world * 配置并处理流数据。 * 使用StreamsBuilder创建并配置KStream,对输入的主题中的数据进行处理,然后将处理结果发送到输出主题。 * 具体处理包括:分割每个消息的值,按值分组,对每个分组在10秒的时间窗口内进行计数,然后将结果转换为KeyValue对并发送到输出主题。 * * @param streamsBuilder 用于构建KStream对象的StreamsBuilder。 */ private static void streamProcessor(StreamsBuilder streamsBuilder) { // 从"kafka-stream-topic-input"主题中读取数据流 KStream<String, String> stream = streamsBuilder.stream("kafka-stream-topic-input"); System.out.println("stream = " + stream); // 将每个值按空格分割成数组,并将数组转换为列表,以扩展单个消息的值 stream.flatMapValues((ValueMapper<String, Iterable<String>>) value -> { String[] valAry = value.split(" "); return Arrays.asList(valAry); }) // 按消息的值进行分组,为后续的窗口化计数操作做准备 .groupBy((key, value) -> value) // 定义10秒的时间窗口,在每个窗口内对每个分组进行计数 .windowedBy(TimeWindows.of(Duration.ofSeconds(10))) .count() // 将计数结果转换为流,以便进行进一步的处理和转换 .toStream() // 显示键值对的内容,并将键和值转换为字符串格式 .map((key, value) -> { System.out.println("key = " + key); System.out.println("value = " + value); return new KeyValue<>(key.key().toString(), value.toString()); }) // 将处理后的流数据发送到"kafka-stream-topic-output"主题 .to("kafka-stream-topic-output"); } } 该处理类首先从主题kafka-stream-topic-input中获取消息数据,经处理后发送到主题kafka-stream-topic-output中,再由消息消费者KafkaStreamConsumer进行消费
执行结果
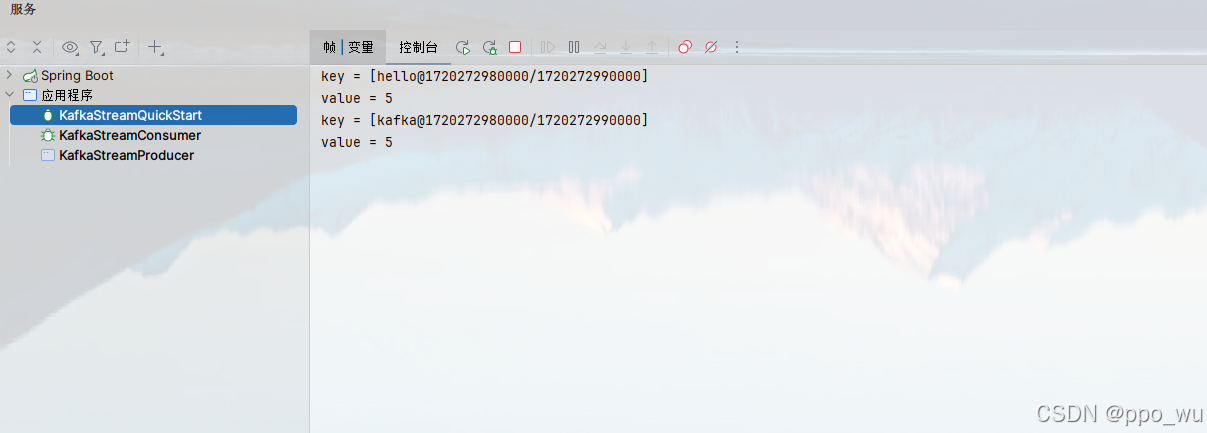
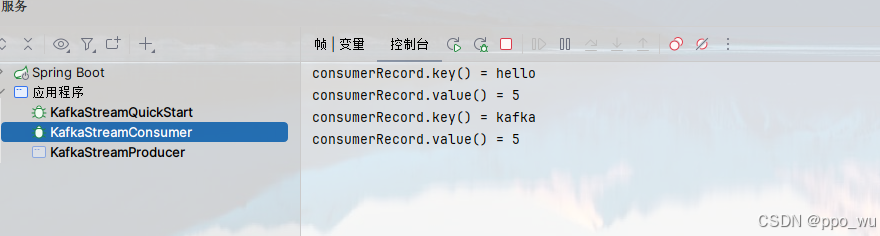
流式处理流程及原理说明
初始阶段
当从输入主题kafka-stream-topic-input读取数据流时,每个消息都是一个键值对。假设输入消息的键是null或一个特定的字符串,这取决于消息是如何被发送到输入主题的。
KStream<String, String> stream = streamsBuilder.stream("kafka-stream-topic-input"); 分割消息值
使用flatMapValues方法分割消息的值,但这个操作不会改变消息的键。如果输入消息的键是null,那么在这个阶段消息的键仍然是null。
stream.flatMapValues((ValueMapper<String, Iterable<String>>) value -> { String[] valAry = value.split(" "); return Arrays.asList(valAry); }) 按消息的值进行分组
在 Kafka Streams 中,当使用groupBy方法对流进行分组时,实际上是在指定一个新的键,这个键将用于后续的窗口化操作和聚合操作。在这个案例中groupBy方法被用来按消息的值进行分组:
.groupBy((key, value) -> value) 这意味着在分组操作之后,流中的每个消息的键被设置为消息的值。因此,当你在后续的map方法中看到key参数时,这个key实际上是消息的原始值,因为在groupBy之后,消息的值已经变成了键。
定义时间窗口并计数
在这个阶段,消息被窗口化并计数,但是键保持不变。
.windowedBy(TimeWindows.of(Duration.ofSeconds(10))) .count() 将计数结果转换为流
当将计数结果转换为流时,键仍然是之前分组时的键
.toStream() 处理和转换结果
在map方法中,你看到的key参数实际上是分组后的键,也就是消息的原始值:
.map((key, value) -> { System.out.println("key = " + key); System.out.println("value = " + value); return new KeyValue<>(key.key().toString(), value.toString()); }) map方法中的key.key().toString()是为了获取键的字符串表示,而value.toString()是为了将计数值转换为字符串。
将处理后的数据发送到输出主题
.to("kafka-stream-topic-output"); 