
阅读量:5
1.jvm组成
什么是jvm,java是跨平台语言,对不同的平台(windos,linux),有不同的jvm版本。jvm屏蔽了平台的不同,提供了统一的运行环境,让java代码无需考虑平台的差异。
jdk包含jre包含jvm
java跨平台原理,通过jvm屏蔽系统差异
为什么要优化jvm?
所谓优化就是配置一些jvm参数,让jvm运行时使用这些参数,让在jvm运行的程序更加良好的运。
行。
默认配置,资源得不到最优分配。
jvm组成
本地方法接口:接入其他语言lib库,native
类加载器:加载类
执行引擎:编译加载过来的类
运行时数据区:程序在运行过程中产生的数据,就在这个地方。
java中所谓的垃圾,就是用来的对象要被回收。
类加载子系统
通过类加载器,把相关类的字节码加载进去。
类加载过程
1.加载:找到字节码文件,读取到内存中,类的加载方式分为隐式加载和显式加载、new,就是隐式加载到jvm。显式加载,通过调用class.forName,加载到内存中去。
2.验证:验证此文件是不是一个真的字节码文件,后缀名是可以改,内在身份标识是不会变的。java验证很严格,通过130多页的验证过程的内容。
3.准备:为类中static修饰的变量分配内存空间并设置初始值,static 123 是初始化才会赋值,准备阶段主要是分配内存。static修饰上还加了final,那么它会在准备赋值。
static 修饰变量分配内存空间,并赋值为0或null
如果static int a =123
final修饰,准备阶段就赋值
4.解析:解析阶段会将java代码中的符号引用替换为直接引用,全限定名(符号引用)找类。
直接引用:
符号引用:
5.初始化:为变量赋初始值,static 初始化
2.类加载机制
类加载器有四种,前三种必然存在
启动类加载器,加载jre_home lib下文件加载,就是jdk中文件夹中lib的文件
扩展类加载器 加载jdk ext下的
应用程序类加载器:加载classpath下的,我们的代码,还有依赖jar都是在classpath
自定义加载器
类加载器,双亲委派机制
先去爷爷那里找,去爸爸那里找,最好自己找。
就是启动类加载器那里找,然后扩展类加载器找,最好应用程序类加载器。
目的是为了让我们不去覆盖java提供的类,三方可以覆盖。2
项目中导入的三方依赖和自己的类都在classpath下,所以我们可以覆盖第三方依赖。之所以让我们的类可以覆盖三方导入的类,是因为可以让我们扩展第三方的类。
比如有的包有bug,自己修一修。
3.运行时数据区
1.7和1.8数据区组成不一样
堆线程共享区:堆
线程隔离区
区别是什么:1.8以后,方法区被元空间替代,没有方法区了,元空间使用本地内存而不是jvm内存。
程序计数器:是线程私有的,指定线程顺序,会记录你当前执行到行数,以及下一句。确定指令的执行顺序
java虚拟机栈:java虚拟机栈也是线程私有的,每个线程分配一个虚拟机栈,每个虚拟机栈有若干的栈帧,每一个栈帧对应一个方法。
一个线程一个栈
每经过一个方法,放一个栈帧
栈帧:一个方法就是一个栈帧。
先进后出,压栈,从上往下。
局部变量表:
操作数栈
本地方法栈:本地方法执行的本地方法,虚拟机栈执行的是java方法,本地是native 方法。
方法区 永久代
1.7把常量池和静态变量放到堆
1.8 类和静态变量到元空间
元空间占本地内存不占jvm内存。
永久代:永远不会被回收
去永久代的原因:
字符串存在永久代,容易出性能问题和内存溢出。
类和方法信息的比较难确定其大小
永久代会为gc带来不必要的复杂度
堆内存
堆和方法区
都是线程共享的
堆分为新生代,老年代,
新生代:
一个eden,两个survivor,from survivor区,to survivor区
eden:刚刚new出来的,一般短命,一次垃圾回收就gg
可能每用完,移到其他区域,历经15次垃圾回收,则放到老年代区
这是常规情况
已经满了的话,直接放入老年代。
堆内存一般存对象和数组,被线程共享。
4.元空间
方法区主要用于存储虚拟机加载的类信息、常量、静态变量,以及编译器编译后的代码等数据,所以方法区溢出的原因就是没有足够的内存来存放这些数据。
常量池在JDK1.6存放在方法区中;
常量池在JDK1.8存放在元空间中
1.8后
不存在永久代方法区,替代它的一块空间为元空间,使用本地内存,可以自己指定元空间大小。
5.jvm内存溢出
堆内存溢出,堆中放对象,数组,不断创建你对象或数组,且让这些对象,数组不会被垃圾回收。那么堆中内存就有可能会溢出。
栈溢出
不停创建线程,让栈的数量溢出 创建多个线程
让栈里面的空间溢出。 不停调用方法
6.执行引擎
即使编译器:把字节码编译成机械码 和垃圾回收器
javac:把源文件编译为字节码文件
明确一个概念,只认0和1组成的命令集称之为机械码,
垃圾回收
判断是不是垃圾,选择垃圾回收期进行回收,使用垃圾回收机制回收垃圾。
1.垃圾标记算法——识别垃圾
判断对象是否已死有引用计数算法和可达性分析算法。
1.1引用计数算法
引用计数器
每个对象都有计数器,每次引用加一,为零没有人引用,就会被回收。
看起来很简单,但是没用,对象间相互引用,这时他们没有用处了。
可达性分析算法
GC roots,垃圾回收的起点,虚拟机栈中本地变量表中引用的对象,调用链能达到根。达不到根就是死的。
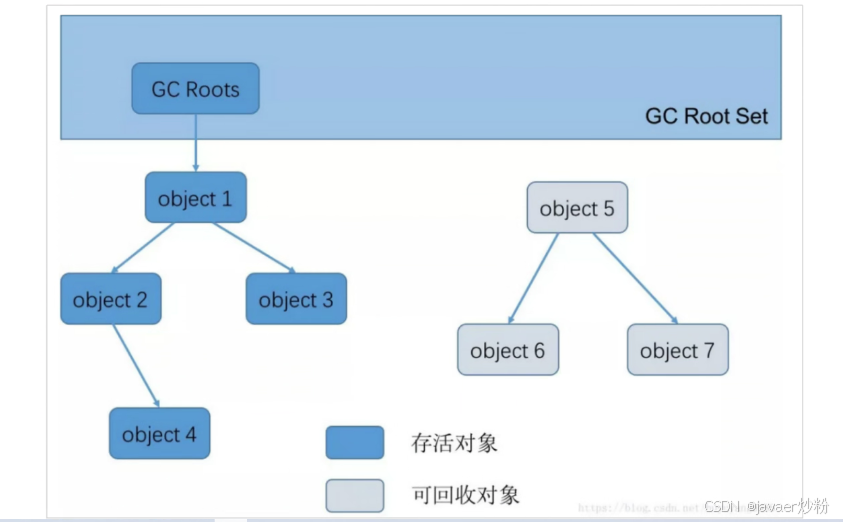
finalize:对象覆盖了finalize,还没有被调用,如果里面方法和根有关联,就可以拯救自己。
JVM 之 虚拟机栈 之 局部变量表(详细)_jvm局部变量表-CSDN博客
常用垃圾回收算法:
7.1标记清除算法,
7.2标记和清除效率不高,会产生大量不连续的内存碎片。
7.3 复制算法,把内存分为大小相等的两块,每次存储只用其中一块,当这一块用完了,就把存活的对象全部复制到另一块上,同时把使用过的这块内存空间全部清理掉,往复循环。
用一半之后,把存活的对象移到另外一半,然后用另外一半,然后清理这一半,相当于分成了两半使用。
缺点:实际可用内存为原来一半。
7.4标记整理算法
对可用对象进行标记,然后所以被标记对象向一端移动,最后清除可用对象边界意外的内存。
7.5分代收集算法
新生代,老年代
新生代一般使用复制算法,存活比较短
老年代标记清除,标记整理。
Minor gc full gc
在说这两种回收的区别之前,我们先来说一个概念,“Stop-The-World”。如字面意思,每次垃圾回收的时候,都会将整个JVM暂停,回收完成后再继续。如果一边增加废弃对象,一边进行垃圾回收,完成工作似乎就变得遥遥无期了。
minor gc 一般暂停时间很短
full gc 一般是老年代的回收,伴随至少一次的minor GC ,新生代和老年代都回收,老年代,暂停时间比较长,因为是标记回收法,通常是minor gc的时间十倍以上。
所以我们尽量minor gc,不要fullgc,经常暂停,给用户很卡的感觉。
GC的流程
大多数情况下,新的对象都分配在Eden区,当Eden区没有空间进行分配时,将进行一次Minor GC,清理Eden区中的无用对象。清理后,Eden和From Survivor中的存活对象如果小于To Survivor的可用空间则进入To Survivor,否则直接进入老年代);Eden和From Survivor中还存活且能够进入To Survivor的对象年龄增加1岁(虚拟机为每个对象定义了一个年龄计数器,每执行一次Minor GC年龄加1),当存活对象的年龄到达一定程度(默认15岁)后进入老年代,可以通过-XX:MaxTenuringThreshold来设置年龄的值。
每经过一次minor gc,年龄加一,达到15次,进入老年代
数据太大青年区去放不了,直接老年代
如果老年代没有连续大空间,则会进行full gc。m gc之前,预测老年代内存不够,full gc
java代码,system。gc,手动进行垃圾回收,不建议,尽量让虚拟机自己的gc策略。
GC 发展阶段:Serial(串行) => Parallel(并行)=> CMS(并发)=> G1 => ZGC
常见垃圾收集器
新生代收集器 Serial、ParNew、Parallel Scavenge
老年代收集器 Serial Old、CMS、Parallel Old
堆内存垃圾收集器
新生代“:
parNew cms 是一对 停顿少 回收多(前面是新生代,后面是老年区)
parallel scavenge parallel old 追求吞吐量,停顿时间长,回收短(前面是新生代,后面是老年区)
jdk1.8和jdk1.7用的就是这个。
jvm优化
系统运行日志
jvm内存优化,通过一些工具或日志
用jps -l,查看进程
jstat 监视虚拟机信息
jmap 查看堆内存情况
分析堆转储快照
有个java可视化工具
jvm优化实战
jvm优化,就是设置堆内存大小和栈内存大小
开发时
通过右上角改
idea开发环境下,进行统一修改
上线的时候,直接写参数
公司里面一般都有一些启动项目的参数模版,拷贝过去先运行。
网上找一个差不多的
为什么要设置这个数,参数是怎么设置,我们有参数模版,每次启动拷贝过来运行即可。没有模版,网上找了个差不多的。
