
阅读量:2
目录
4) 将master配置好的spark 拷贝到slave1,slave2
一、集群规划
主机名 | 操作系统 | 地址 | 角色 | 硬件配置 |
master | Centos | 10.1.0.248 | namenode | 2g 1核 |
slaver1 | Centos | 10.1.0.94 | datanode | 1g 1核 |
slaver2 | Centos | 10.1.0.31 | datanode | 1g 1核 |
二、更改主机名
分别修改主机名文件(重启永久生效)
sudovi /etc/sysconfig/network
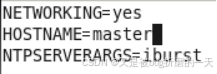


三、建立主机名和ip的映射
sudovi /etc/hosts

拷贝到slave1和slave2中
![]()
![]()
四、关闭防火墙(master,slave1,slave2)
关闭防火墙:sudoservice iptables stop
关闭防火墙自启:sudochkconfig iptables off
五、配置ssh免密码登录
ssh-keygen -t rsa
ssh-copy-idmast
