
阅读量:2
目录
开始
Prometheus 数据类型
简单理解
a)安装好 Prometheus 后会暴露一个 /metrics 的 HTTP 服务(相当于安装了 prometheus_exporter),通过配置(默认会加上 /metrics),Prometheus 就可以采集到这个 /metrics 里面的所有监控样本数据,例如:
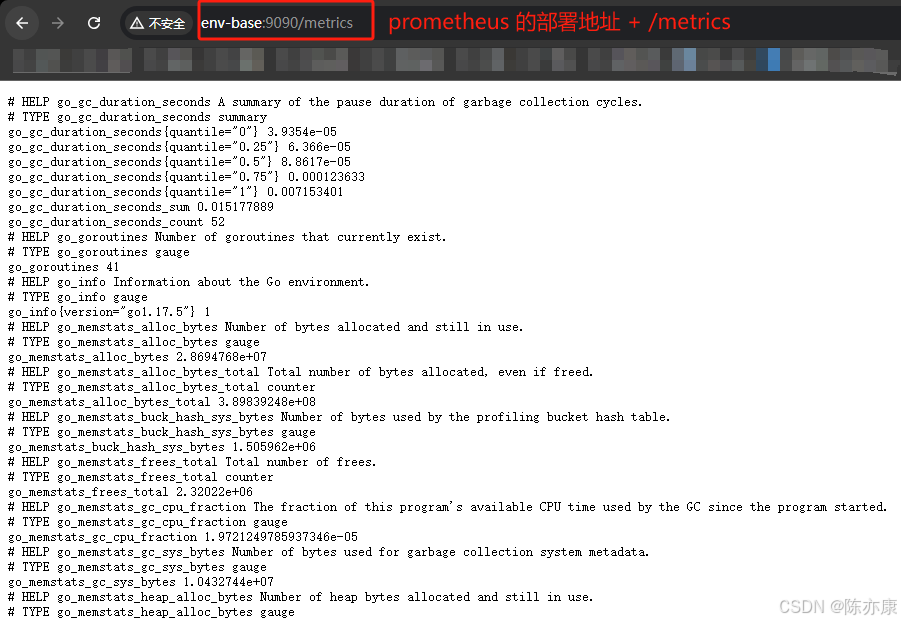
prometheus.yml 文件中:
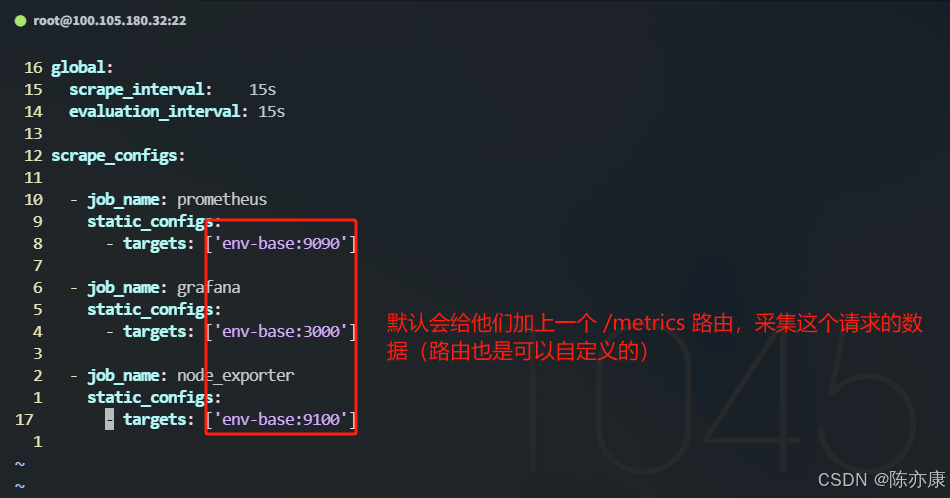
b)Prometheus 存储的是时序数据,也就是按照 时间的维度 存储连续的数据集合(指标名称 和 标签 来做唯一标识),例如如下:
# /metrics 页面中的数据(不显示时间): prometheus_http_requests_total{code="200",handler="/api/v1/label/:name/values"} 3 # 非 /metrics 页面中的数据实际在数据库中存储的(带个毫秒级的 unix 时间戳): prometheus_http_requests_total{code="200",handler="/api/v1/label/:name/values"} @133734964723510 3 # 上述格式: 指标名称 + 标签 + 时间戳 + 值- 指标名称:用于描述系统上要测定的某个特征,例如上述 prometheus_http_requests_total .
- 标签:键值对数据,附加在 指标名称 后面,让指标能够支持多维度特征,例如 {code="200",handler="/api/v1/label/:name/values"}
c)双下划线标签是 Prometheus系统默认标签,是不会显示在 /metrics 页面中的.
在 Prometheus 的 Target 中,鼠标移到 Labels 上,会显示如下:
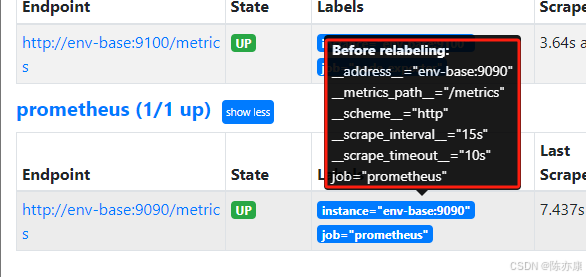
常见标签如下:
- __address:当前 target 实例的 套接字(ip:port) 地址.
- __metrics_path:采集当前 target 使用的 url 路径,默认为 /metrics.
- __scheme:采集当前 target 上指标数据使用的协议(http 或 https).
- __scrape_interval:这个参数指定 Prometheus 以多长的时间间隔抓取一次目标的数据。
- __scrape_timeout:这个参数定义了 Prometheus 抓取目标数据的超时时间。如果抓取操作在指定时间内未完成,Prometheus 将放弃这次抓取。
- __param:传递 url 参数中第一个参数的值.
- __name:此标签是标识指标名称的预留标签,能够使用标签选择器对指标名称进行过滤.
时序样本
按照某个时间维度采集的数据,称为样本,值包含:
一个毫秒级的 unix 时间戳
一个 float64 值
例如如下:
prometheus_http_requests_total{code="200",handler="/api/v1/label/:name/values"} @133734964723510 3 上述格式: 指标名称 + 标签 + 时间戳 + 值.
Ps:样本中的时间戳在 /metrics 页面中是不会显示的,只有在 prometheus 数据库中才能看到.
格式 和 命名要求
Prometheus 时序格式中包含 指标名称 和 标签:
<metric name>{<label name>=<label value>, ...}例如,指标名称为 prometheus_http_requests_total 和 标签为 {code="200",handler="/api/v1/label/:name/values"} 如下
prometheus_http_requests_total{code="200",handler="/api/v1/label/:name/values"}Ps:Prometheus指标名称 和 标签名/标签值 可以包含 ASCII 字母、数字、下划线、冒号. 但是必须匹配正则表达式
[a-zA-Z_:][a-zA-Z0-9_:]*,也就是说开头的第一个字符一定不能是数字!!! 后面自定要 Labels 的时候一定要注意!!!
Metrics 指标类型
Counter 计数器
是一个单调递增的数值. 主要特点就是它的值 只增不减、除非被重置(例如系统重启).
通常用来记录某段时间内 http 请求增长率....
Count 并不会直接作用,而是需要借助 rate、irate 等函数来生成样本数据的变化状况(增长率)如下:
a)获取 1 小内,该指标下各时间序列上的 http 总请求数的增长速率
rate(prometheus_http_requests_total[1h]) 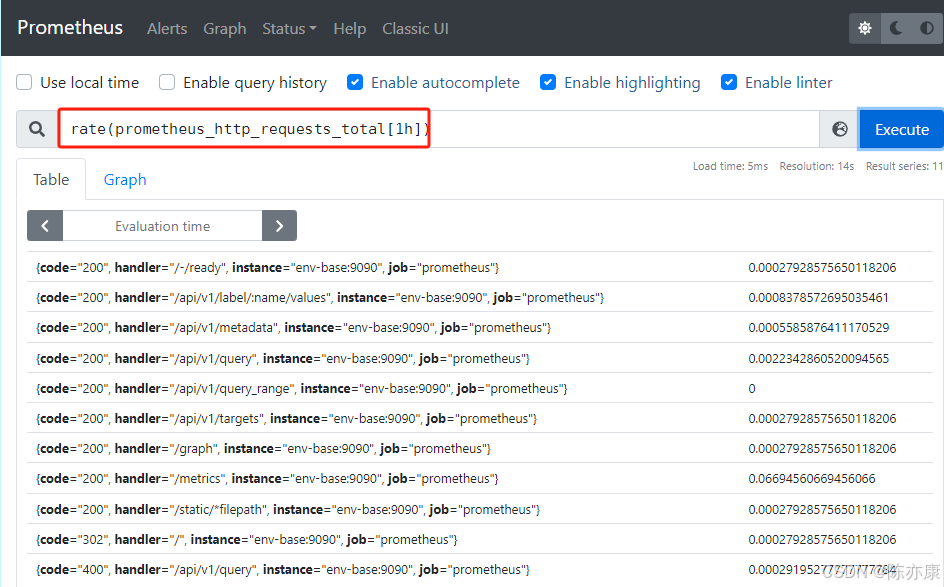
b)irate 为高灵敏度函数,用于计算指标的瞬时速率,基于样本范围内的最后两个样本进行计算
irate(prometheus_http_requests_total[1h])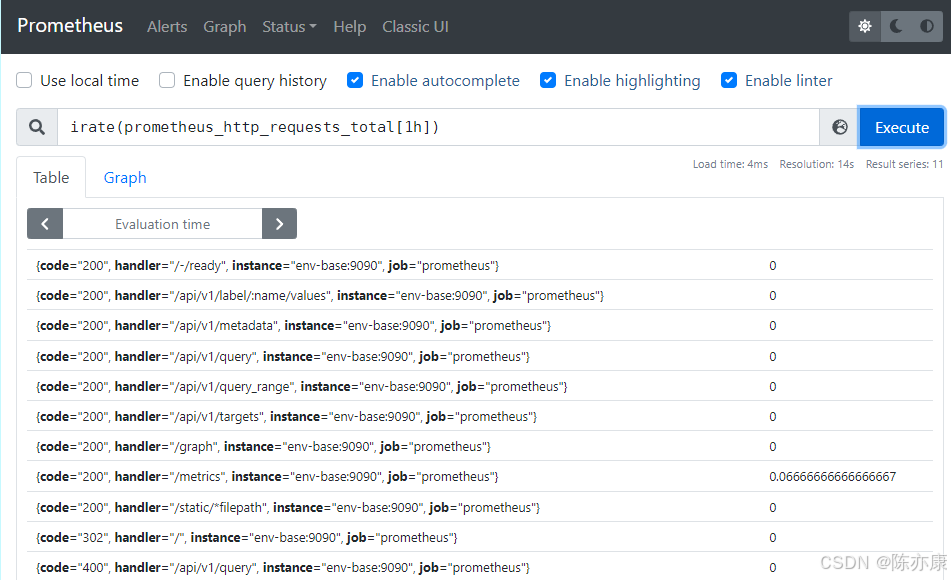
Gauge
Gauge 是一种用于记录可以任意上下变化的数值指标类型. 与 Counter 单调递增不同,Gauge 可增可减,使得 Gauge 适合用来监控瞬时值或频繁变化的值.
Gauge 常用于进行 求和、平均值、最大值、最小值 等聚合计算,经常会搭配 PromQL 的 delta 使用.
a)返回该服务器上的CPU温度与1小时之前的差异
delta(cpu_temp_celsius{host="node_exporter"}[1h])
Histogram
用于记录数据分布的指标类型. 通过将数据划分成多个桶(buckets),统计每个桶中的样本数量,从而提供数据的分布情况,对于监控请求的延迟、响应时间非常有用.
例如统计在 0~15 ms 之间的请求数有多少,在 10~20ms 之间的请求数有多少. 这样可以快速分析系统慢的原因.
从 /metrics 页面中可以看出这些指标,以及值
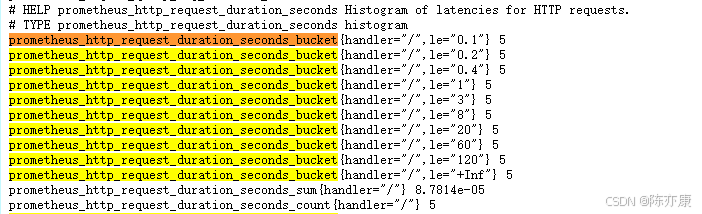
a)在 handler 为 /metrics 的情况下,响应时间小于等于 0.1 秒的请求数是 612
prometheus_http_request_duration_seconds_bucket{handler="/metrics",le="0.1"} 612b)在 handler 为 /metrics 的情况下,响应时间小于等于 0.2 秒的请求数是 612
prometheus_http_request_duration_seconds_bucket{handler="/metrics",le="0.2"} 612结合上一个数据,这意味着响应时间在 0.1 秒到 0.2 秒之间的请求数是 0,因为前一个桶(le="0.1")的请求数也是 612
c)在 handler 为 /metrics 的情况下,响应时间小于等于 0.4 秒的请求数是 612。
prometheus_http_request_duration_seconds_bucket{handler="/metrics",le="0.4"} 612这意味着响应时间在 0.2 秒到 0.4 秒之间的请求数是 0,因为前一个桶(le="0.2")的请求数也是 612。
Summary
用于观察和聚合时间持续时间或大小的指标类型. 和 Histogram 类似,用于记录一系列数据的分布情况,但是 Summary 更关注分位数. Summary 会自动计算请求延迟、响应时间等的分位数,同时还会维护时间的总数和.
对于每个指标,Summary 以指标名称为前缀,生成如下几个指标序列:
- _sum :统计所有样本值之和
- _count :统计所有样本总数
- {quantile=“x”} :统计样本值的分位数分布情况,分位数范围:0 ≤ x ≤ 1
在 /metrics 页面中如下:

a)prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} NaN
表示在给定时间段内,99 分位数的 WAL 持久化操作耗时无法计算。
b)prometheus_tsdb_wal_fsync_duration_seconds_sum 0.010883303
表示在给定时间段内,所有 WAL 持久化操作的总耗时为约 0.010883303 秒。
c)prometheus_tsdb_wal_fsync_duration_seconds_count 2
表示在给定时间段内,共有 2 个 WAL 持久化操作被记录。
Exporter 相关
概述
所有可以向 Prometheus 提供监控样本数据的程序都可以被称为一个 Exporter,而 Exporter 的一个实例被称为 Target.
Exporter 可以用户自定义,也可以使用社区提供的,例如 MySQL_Exporter、Redis_Exporter、RabbitMQ_Exporter......
Prometheus 通过轮询的方式,定期的从这些 target 中获取样本数据.
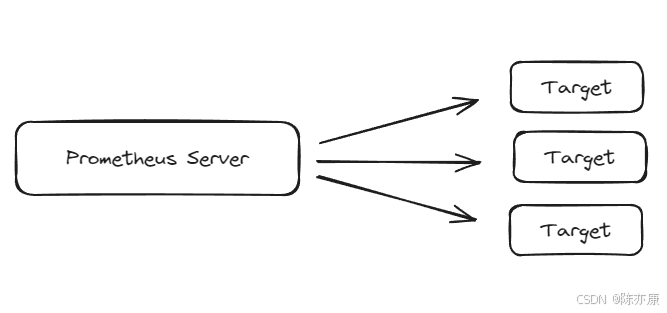
Ps:安装好 Exporter 后会暴露一个 http://ip:port/metrics 的 HTTP 服务,通过 prometheus.yml 进行配置,就可以采集到 http://ip:port/metrics 里面所有监控样本数据.
Exporter 类型
通常来说可以将 Exporter 分为两类:
a)直接采集型
这类 Exporter 直接内置了对应的应用程序,用于向 Prometheus 直接提供 Target 数据支持. 这样设计的好处是,可以更好的监控各自系统的内部运行状态,同时也适合更多自定义监控的项目实施,例如 k8s 等,他们都内置了向 Prometheus 提供监控数据的端点.
这类例如:MySQL Exporter、RabbitMQ Exporter、Mongo Exporter、Nginx Exporter
b)简洁采集型
原始监控目标并不直接支持 Prometheus,需要我们使用 Prometheus 提供的 Client Library 编写该监控目标的监控采集程序,用户可以将程序独立运行,取获取指定的各类监控数据值.
例如 Linux 操作系统自身并不能直接支持 Prometheus,因此需要单独安装 Node_Exporter 来进行监控 Linux 系统的各项监控指标.
这类例如:Node Exporter
Exporter 规范
a)所有的 Exporter 程序都需要按照 Prometheus 的规范,返回监控样本数据.
以 node_exporter 为例,访问:http://env-base:9100/metrics 就会返回如下内容:
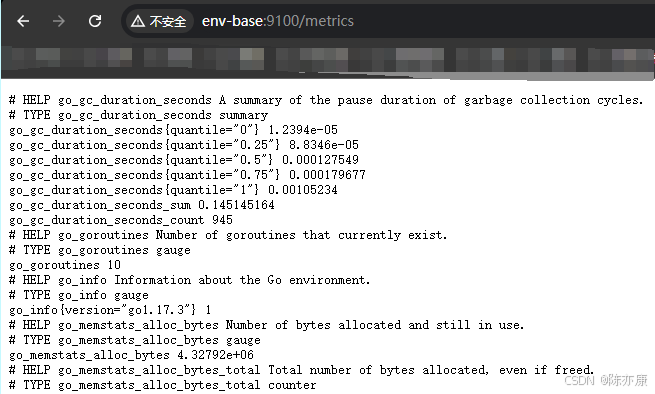
# 开头表示注释内容,这类样本数据说明如下:
- # HELP 开头的行,表示 metrics 的帮助与说明注释,可以包含当前 监控指标名称 和 对应的说明信息.
- # Type 开始的行,表示定义 metrics 类型,可以包含当前 监控指标名称 和 类型. 类型有 Counter、Gauge、Histogram、Summary.
- 非 # 开头的,就是监控的样本数据.
b)监控的样本数据规范
metric_name 和 label_name 必须遵循 PromQL 的格式规范要求. value 是一个 float 格式的数据,timestamp 类型为 int64(从 1970-01-01 00:00:00 以来的毫秒数). 具有相同 metric_name 的样本必须要按照一个组的形式排列,并且每一行必须是唯一的 指标名称 和 指标键值对组合.

