
阅读量:3
目录
一、引言
在人工智能的浪潮中,多模态大模型(MLLM)正成为推动技术革新的关键力量。它们融合了视觉和语言等多种模态的信息处理能力,旨在实现更深层次的智能理解。随着深度学习技术的突飞猛进,2023年见证了多模态大模型的显著进展,其中OpenAI的GPT-4v和Google的Gemini模型尤为引人注目。然而,尽管商业模型不断突破,开源领域一直缺少一个能够匹敌的多模态基础模型,直至InternVL 1.5的横空出世。
二、InternVL 1.5概览
InternVL 1.5是由上海人工智能实验室联合多家顶尖学术机构推出的新一代开源多模态大型语言模型。这一模型的发布,标志着开源社区在多模态理解能力上迈出了坚实的一步,为缩小与专有商业模型之间的差距提供了可能。
1、核心组件
InternVL 1.5的核心包括:
- InternViT-6B:一个60亿参数的视觉编码器,基于Transformer架构,专为处理复杂视觉输入设计。
- QLLaMA:一个8亿参数的语言中间件,负责处理和生成语言内容,提供多模态任务的语言支持。
2、技术特点
InternVL 1.5的技术创新体现在:
- 渐进式对齐技术:首次提出对比-生成融合策略,实现视觉与语言模型的精细对齐。
- 多模态性能提升:在OCR、多模态对话等基准测试中取得优异成绩,尤其在高分辨率图像处理和多语言支持方面。
- 动态高分辨率支持:根据输入图像特性动态调整分辨率,最高支持4K,优化了计算效率与细节保留。
- ViT-MLP-LLM架构:结合了预训练视觉编码器与语言模型,通过MLP映射器和Pixel Shuffle技术减少视觉标记数量。
三、性能表现
InternVL 1.5在多模态基准测试中的表现令人瞩目,尤其在OCR、多模态对话和文档理解任务上展现出色。
1、关键性能指标
- OCR任务:在文档图像文字识别中,InternVL 1.5准确高效,即使是复杂布局和低分辨率图像也能准确处理。
- 多模态对话:在连续对话中,模型展现了优秀的上下文理解能力,维持了对话的连贯性。
- 文本与图像结合任务:在TextVQA、ChartQA和DocVQA任务中,准确率分别达到80.6%、83.8%和90.9%,凸显了模型在阅读理解和文档理解方面的优势。
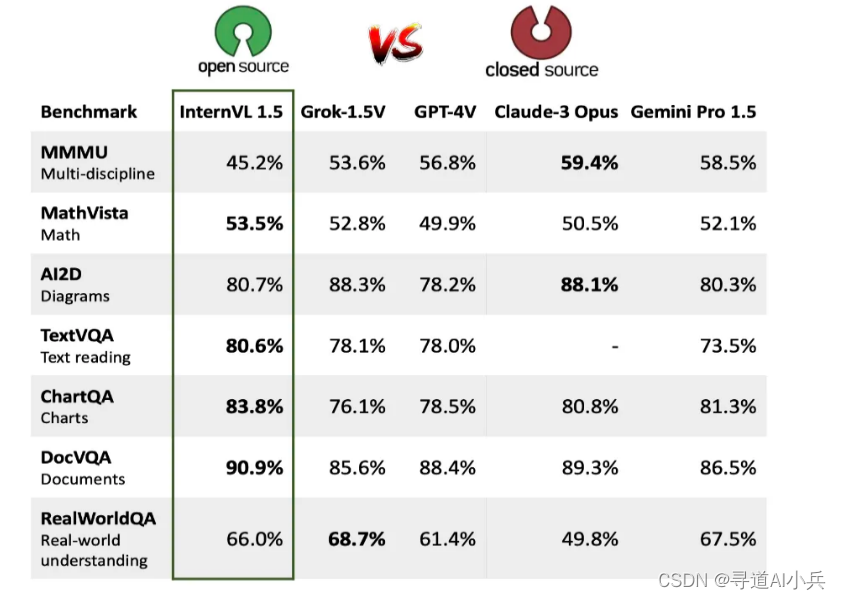
2、高分辨率与多语言支持
- 动态分辨率处理:InternVL 1.5支持高达4K分辨率的图像输入,智能地分割图像以优化细节处理。
- 双语能力:通过双语数据集训练,模型在中英文混合任务中展现出卓越的多语言处理能力。
3、与商业模型的竞争力
在与GPT-4和Gemini Pro等商业模型的比较中,InternVL 1.5显示出不逊色的性能,甚至在特定任务上取得了更佳成绩,证明了开源模型的竞争力。
OpenCompass 多模态模型基准测试作为评估和比较大型语言模型及多模态模型性能的关键平台,在最近的评测中,开源多模态基础模型InternVL v1.5表现卓越,紧跟GPT-4o、GPT-4v、Gemini-1.5-Pro 三大闭源的多模态大模型之后;排在第四名。这个成绩充分展现了 InternVL v1.5 在多模态理解领域的强大实力,无论是在视觉与语言处理任务上的卓越性能,还是在理解和生成多模态内容方面的先进技术,均得到了充分体现。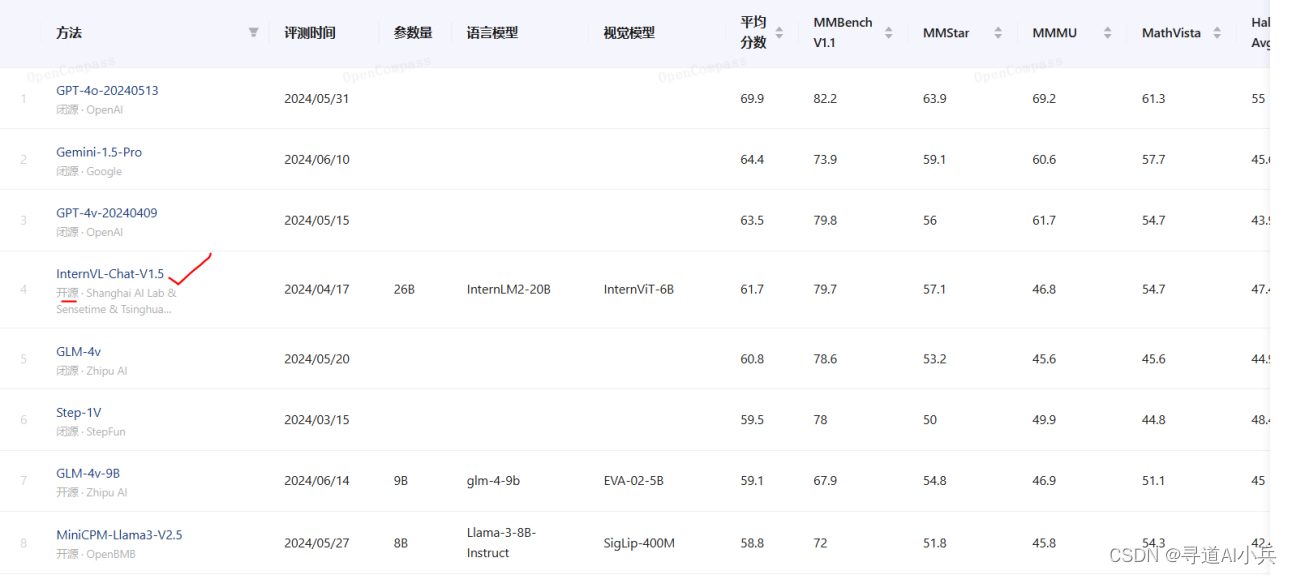
四、技术突破与创新
InternVL 1.5的推出,不仅是开源社区的一次技术突破,更是对现有多模态大模型性能的一次重大提升。通过以下方面的创新,InternVL 1.5成功地缩小了与商业模型之间的差距:
- 强视觉编码器:InternVL-6B的持续学习策略显著提升了视觉理解能力,使其能够在不同环境中迁移和重用。
- 动态高分辨率:模型能够根据输入图像的特性动态调整分辨率,最高支持4K输入,优化了图像细节的处理。
- 双语数据集:高质量的双语数据集的收集和注释,显著提高了模型在OCR和中文相关任务的性能。
五、模型效果体验
地址:https://internvl.opengvlab.com/
1、上传一张狗狗图片,让大模型进行读取分析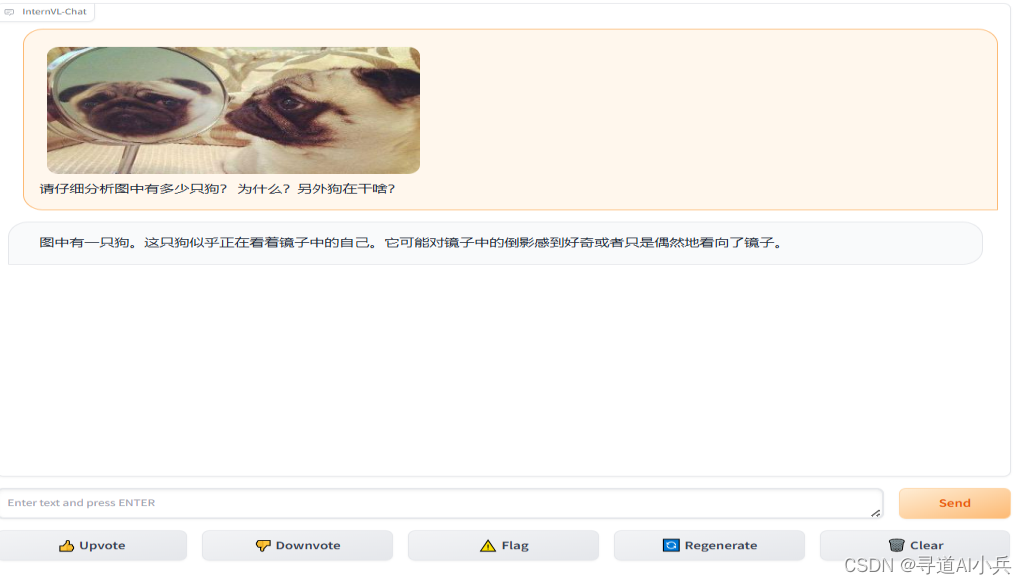
2、我上传了一张AI图片,让他帮忙讲解内容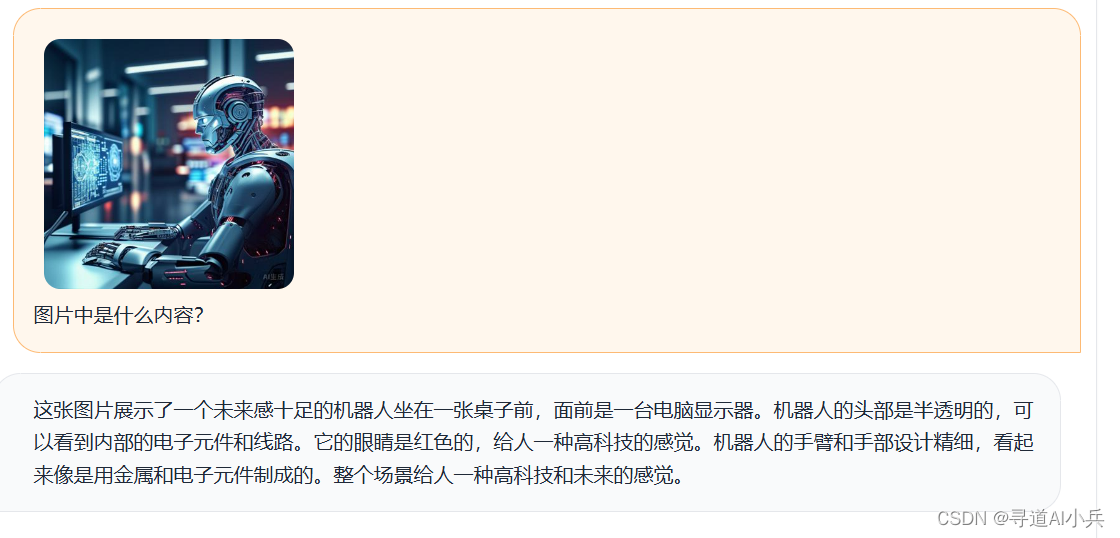
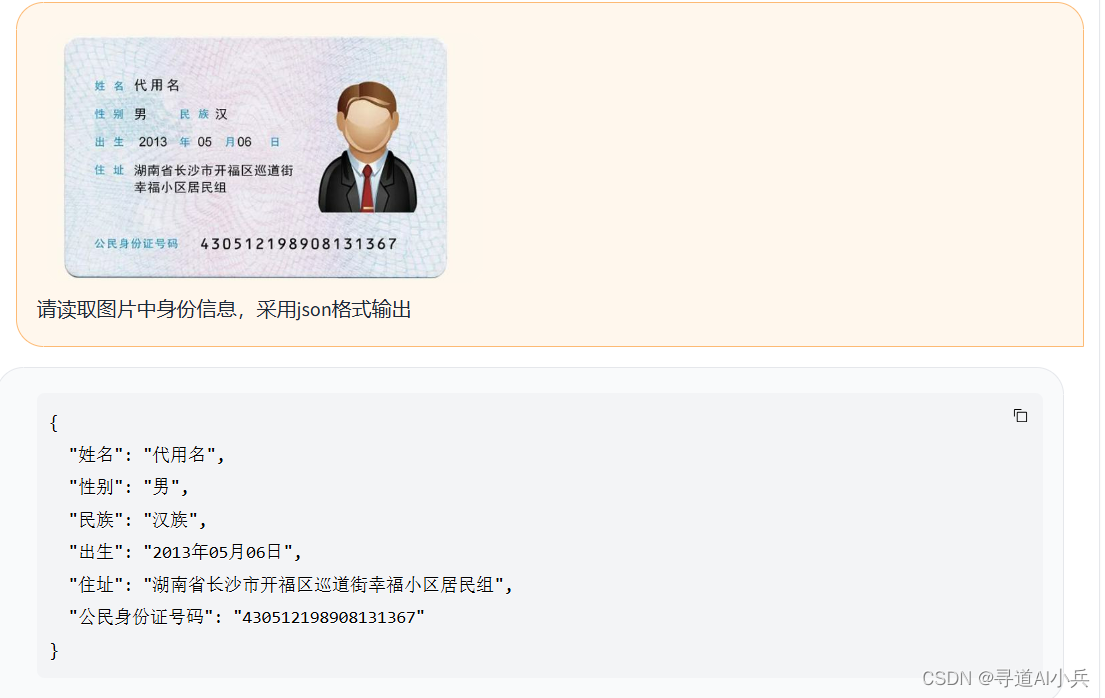
3、上传一张身份证图片,让他解析采用json格式输出
六、 模型部署运行
1、模型下载
git lfs install git clone https://www.modelscope.cn/maple77/Mini-InternVL-Chat-4B-V1-5.git 
修改config.json文件中use_flash_attn为false
2、安装依赖
pip install transformers sentencepiece peft einops bitsandbytes accelerate timm ninja packaging protobuf 3、代码样例
提取准备2张测试图片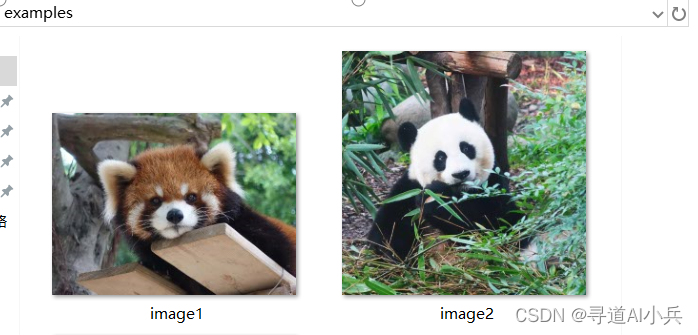
demo.ipynb
以下是官网中提供的代码样例; 修改模型的huggingface地址改为本地地址:
path = “OpenGVLab/Mini-InternVL-Chat-4B-V1-5”
修改改为:
path = ‘autodl-tmp/model/Mini-InternVL-Chat-4B-V1-5’
from transformers import AutoTokenizer, AutoModel import torch import torchvision.transforms as T from PIL import Image from torchvision.transforms.functional import InterpolationMode IMAGENET_MEAN = (0.485, 0.456, 0.406) IMAGENET_STD = (0.229, 0.224, 0.225) def build_transform(input_size): MEAN, STD = IMAGENET_MEAN, IMAGENET_STD transform = T.Compose([ T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img), T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC), T.ToTensor(), T.Normalize(mean=MEAN, std=STD) ]) return transform def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size): best_ratio_diff = float('inf') best_ratio = (1, 1) area = width * height for ratio in target_ratios: target_aspect_ratio = ratio[0] / ratio[1] ratio_diff = abs(aspect_ratio - target_aspect_ratio) if ratio_diff < best_ratio_diff: best_ratio_diff = ratio_diff best_ratio = ratio elif ratio_diff == best_ratio_diff: if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]: best_ratio = ratio return best_ratio def dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=False): orig_width, orig_height = image.size aspect_ratio = orig_width / orig_height # calculate the existing image aspect ratio target_ratios = set( (i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if i * j <= max_num and i * j >= min_num) target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1]) # find the closest aspect ratio to the target target_aspect_ratio = find_closest_aspect_ratio( aspect_ratio, target_ratios, orig_width, orig_height, image_size) # calculate the target width and height target_width = image_size * target_aspect_ratio[0] target_height = image_size * target_aspect_ratio[1] blocks = target_aspect_ratio[0] * target_aspect_ratio[1] # resize the image resized_img = image.resize((target_width, target_height)) processed_images = [] for i in range(blocks): box = ( (i % (target_width // image_size)) * image_size, (i // (target_width // image_size)) * image_size, ((i % (target_width // image_size)) + 1) * image_size, ((i // (target_width // image_size)) + 1) * image_size ) # split the image split_img = resized_img.crop(box) processed_images.append(split_img) assert len(processed_images) == blocks if use_thumbnail and len(processed_images) != 1: thumbnail_img = image.resize((image_size, image_size)) processed_images.append(thumbnail_img) return processed_images def load_image(image_file, input_size=448, max_num=6): image = Image.open(image_file).convert('RGB') transform = build_transform(input_size=input_size) images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num) pixel_values = [transform(image) for image in images] pixel_values = torch.stack(pixel_values) return pixel_values #path = "OpenGVLab/Mini-InternVL-Chat-4B-V1-5" path = 'autodl-tmp/model/Mini-InternVL-Chat-4B-V1-5' model = AutoModel.from_pretrained( path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True).eval().cuda() tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True) # set the max number of tiles in `max_num` pixel_values = load_image('./examples/image1.jpg', max_num=6).to(torch.bfloat16).cuda() generation_config = dict( num_beams=1, max_new_tokens=512, do_sample=False, ) # single-round single-image conversation question = "请详细描述图片" # Please describe the picture in detail response = model.chat(tokenizer, pixel_values, question, generation_config) print(question, response) # multi-round single-image conversation question = "请详细描述图片" # Please describe the picture in detail response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True) print(question, response) question = "请根据图片写一首诗" # Please write a poem according to the picture response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True) print(question, response) # multi-round multi-image conversation pixel_values1 = load_image('./examples/image1.jpg', max_num=6).to(torch.bfloat16).cuda() pixel_values2 = load_image('./examples/image2.jpg', max_num=6).to(torch.bfloat16).cuda() pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0) question = "详细描述这两张图片" # Describe the two pictures in detail response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True) print(question, response) question = "这两张图片的相同点和区别分别是什么" # What are the similarities and differences between these two pictures response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True) print(question, response) # batch inference (single image per sample) pixel_values1 = load_image('./examples/image1.jpg', max_num=6).to(torch.bfloat16).cuda() pixel_values2 = load_image('./examples/image2.jpg', max_num=6).to(torch.bfloat16).cuda() image_counts = [pixel_values1.size(0), pixel_values2.size(0)] pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0) questions = ["Describe the image in detail."] * len(image_counts) responses = model.batch_chat(tokenizer, pixel_values, image_counts=image_counts, questions=questions, generation_config=generation_config) for question, response in zip(questions, responses): print(question) print(response) 4、运行效果

请详细描述图片 这张图片展示了一只红熊猫,它是一种以其独特的红色和白色毛发而闻名的熊科动物。红熊猫的眼睛又大又圆,表情似乎很好奇或者专注。它的耳朵尖尖的,耳朵上有一些白色的毛发。红熊猫的鼻子是黑色的,它正伸出头来,似乎在凝视着某个东西。它的毛发主要是红色的,背部和腹部有一些黑色的毛发。 红熊猫正在一个木制的结构上,这个结构看起来像是一个树架或者树枝。红熊猫的前爪放在这个结构上,而它的后腿则悬挂在空中。背景中可以看到一些绿色的植物,这表明红熊猫可能在一个围栏或者动物园的环境中。整体上,这张图片给人一种温馨和迷人的感觉。 dynamic ViT batch size: 7 请详细描述图片 这张图片展示了一只红熊猫,它是一种以其独特的红色和白色毛发而闻名的熊科动物。红熊猫的眼睛又大又圆,表情似乎很好奇或者专注。它的耳朵尖尖的,耳朵上有一些白色的毛发。红熊猫的鼻子是黑色的,它正伸出头来,似乎在凝视着某个东西。它的毛发主要是红色的,背部和腹部有一些黑色的毛发。 红熊猫正在一个木制的结构上,这个结构看起来像是一个树架或者树枝。红熊猫的前爪放在这个结构上,而它的后腿则悬挂在空中。背景中可以看到一些绿色的植物,这表明红熊猫可能在一个围栏或者动物园的环境中。整体上,这张图片给人一种温馨和迷人的感觉。 dynamic ViT batch size: 7 请根据图片写一首诗 红熊猫儿凝望着, 树枝上栖息着。 它的眼睛圆圆的, 好奇心在它的眼中。 它的毛发红亮亮, 背部和腹部有黑色的毛。 它的耳朵尖尖的, 耳朵上有一些白色的毛。 它的鼻子是黑色的, 它伸出头来,似乎在凝视着某个东西。 它的前爪放在木制结构上, 后腿悬挂在空中。 背景中有绿色的植物, 这表明红熊猫可能在一个围栏或者动物园的环境中。 整个场景给人一种温馨和迷人的感觉, 红熊猫儿的姿态和表情都很有趣。 dynamic ViT batch size: 12 详细描述这两张图片 这两张图片都展示了动物园内的熊猫。 第一张图片中,一只熊猫正坐在一个木制的长凳上,它的头部稍微低垂,似乎在休息或者观察周围的环境。熊猫的皮毛主要是黑白相间,耳朵和眼睛周围有一些棕色的毛发。它的眼睛很大,表情看起来很温和。熊猫周围有一些绿色的植物,可能是竹子或者其他植物。 第二张图片中,另一只熊猫也坐在一个木制的长凳上,它的头部稍微低垂,似乎在休息或者观察周围的环境。这只熊猫的皮毛也是黑白相间,耳朵和眼睛周围有一些棕色的毛发。它的眼睛很大,表情看起来很温和。熊猫周围有一些绿色的植物,可能是竹子或者其他植物。 两张图片中的熊猫都显得很平静,周围环境看起来很自然,给人一种宁静的感觉。 dynamic ViT batch size: 12 这两张图片的相同点和区别分别是什么 相同点: 1. 两张图片中都有熊猫。 2. 熊猫的皮毛主要是黑白相间,耳朵和眼睛周围有一些棕色的毛发。 3. 熊猫的眼睛很大,表情看起来很温和。 4. 熊猫周围都有绿色的植物,可能是竹子或者其他植物。 5. 熊猫都坐在木制的长凳上。 区别: 1. 第一张图片中的熊猫头部稍微低垂,似乎在休息或者观察周围的环境。而第二张图片中的熊猫头部也稍微低垂,但表情看起来更加放松。 2. 第一张图片中的熊猫周围有一些竹子,而第二张图片中的熊猫周围有一些其他的绿色植物。 3. 第一张图片中的熊猫坐在一个木制的长凳上,而第二张图片中的熊猫坐在一个木制的长凳上,但长凳的设计和材料可能有所不同。 七、挑战与不足
尽管InternVL 1.5在多模态领域取得了显著进展,并在多个场景中展现了优异性能,但它仍面临一些挑战和局限性,这些正是未来模型改进的方向。
1、数据训练不足的场景理解 InternVL可能在特定数据场景中遇到理解和处理不足的问题,特别是在新颖或高度专业化的领域。由于训练样本的不足或数据分布与实际应用场景不匹配,模型可能无法充分捕捉领域特定的特征和模式。
2、图片中的复杂元素识别 对于图像中的复杂元素,如表格、二维码和签章等,InternVL的识别能力有待提升。这些元素的结构化信息提取和解读对算法的精度和理解深度提出了更高要求。
3、处理重复问题 在实际应用中,用户可能会重复提出相似或相同的问题。InternVL需要更好地理解和处理这种重复性,避免提供冗余答案,同时提供更精准和个性化的响应。
八、总结
InternVL 1.5的开源发布,为全球AI社区提供了一个强大的多模态大模型工具。它在技术上实现了视觉编码器参数的突破,并通过创新的对齐技术提升了多模态任务的处理能力。随着技术的不断发展,InternVL 1.5有望在未来版本中提供更加完善和智能的多模态解决方案,推动人工智能技术向更深层次发展。
参考资源

🎯🔖更多专栏系列文章:AIGC-AI大模型开源精选实践
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:建立有技术交流群,可以扫码👇 加入社群,500本各类编程书籍、AI教程、AI工具等你领取!
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
