
阅读量:2
目录
引言
在人工智能技术的不断演进中,文本到语音(TTS)技术已经成为连接人类语言与机器表达的重要桥梁。近期,一个名为ChatTTS的项目以其卓越的性能和创新性迅速走红,成为技术圈的热议话题。本文将深入探讨ChatTTS的技术特性、应用潜力以及未来发展前景。
一、ChatTTS技术特性解析
1、创新的语音合成模型
ChatTTS是由2Noise团队开发的一款文本转语音项目,它在短时间内在GitHub上获得了超过9000个Star,显示出其受欢迎程度。与传统TTS技术相比,ChatTTS在语音合成的自然度和可玩性上实现了重大突破。
2、多语言与细粒度控制
ChatTTS不仅支持中文和英文,还能够进行细粒度的语音控制,如加入笑声、说话间的停顿以及语气词等,极大地丰富了语音合成的表达力。
3、大规模数据训练的成果
ChatTTS的最大模型使用了超过10万小时的中英文数据进行训练,这为其高质量的语音合成效果提供了坚实的数据基础。
4、韵律特征的精准控制
ChatTTS能够预测和控制细粒度的韵律特征,如语调、节奏等,使其在韵律方面超越了大部分开源TTS模型。
二、ChatTTS的实现原理
1、深度学习与神经网络
ChatTTS的核心技术基于深度学习,特别是神经网络的应用。通过大量的数据训练,模型学习到了语言的韵律和语调,能够更加自然地模拟人类语音。
2、端到端的语音合成
ChatTTS采用了端到端的语音合成方法,这意味着从文本到语音的转换过程中不需要传统的中间步骤,如音素识别或规则基的韵律生成。
3、个性化与定制化
ChatTTS支持个性化和定制化的语音输出,用户可以根据自己的需求调整语音的各种参数,包括语速、音量、语调等。
三、ChatTTS的多元化用途
1、对话式交互的完美伴侣
ChatTTS特别适用于对话场景,能够为大型语言模型(LM)助手提供高质量的语音输出,极大地提升了对话式交互的自然度和用户体验。
2、多媒体内容创作
无论是有声读物的制作还是视频配音,ChatTTS都能够提供流畅自然的语音合成效果,为内容创作者带来便利。
3、虚拟助手的语音表达
ChatTTS可以作为虚拟助手的语音输出模块,使其能够以更加自然和人性化的方式与用户进行交流。
4、 教育与辅助工具
ChatTTS也可以应用于教育领域,作为辅助工具帮助有阅读障碍的学生学习,或者作为语言学习工具帮助用户练习发音和语调。
四、ChatTTS的实践操作
1、便捷的在线试用
用户可以通过https://chattts.com/zh的在线体验平台直接试用ChatTTS的功能,感受其语音合成的魅力。
2、音色调节与克隆
ChatTTS允许用户调节数字指定说话人的音色,或通过随机生成的方式获得不同的音色效果,为音色定制提供了可能。
3、长文本处理的挑战与展望
尽管ChatTTS在短文本处理上表现出色,但在长文本处理上仍面临挑战。未来,随着技术的不断优化,我们期待ChatTTS能够在长文本处理上取得更大的突破。
五、ChatTTS部署实践
1、下载模型
从modelscope下载模型
git clone https://www.modelscope.cn/pzc163/chatTTS.git 
2、下在源代码
从github上下载源代码
git clone https://github.com/2noise/ChatTTS 
3、创建虚拟环境
- 创建 myChatTTS虚拟环境:conda create -n myChatTTS
- 查看已安装环境:conda env list
- 激活环境:conda activate myChatTTS
- 退出环境:conda deactivate
4、安装相关依赖
cd ChatTTS pip install -r requirements.txt torch依赖冲突
报错后修改torch中的版本指定,重新安装依赖
安装依赖还是报错
这个问题是由于torch和torchvision、torchaudio的版本不兼容导致的。根据错误信息,torchvision 0.18.0+cu121需要torch== 2.3.0,但是torchaudio 2.3.1需要torch==2.3.1,因此出现了依赖冲突。
为了解决这个问题,你可以尝试安装满足所有依赖的torch版本。在命令行终端中输入以下命令:
pip install torch==2.3.1
如果你使用的是conda环境,可以使用以下命令:
conda install -c pytorch torch == 2.3.1
这将会从pytorch通道安装指定版本的torch。安装完成后,你可以再次运行
pip install -r requirements.txt
5、简单测试
import torch import ChatTTS from IPython.display import Audio # 初始化ChatTTS chat = ChatTTS.Chat() #加载远程huggingface上的模型 #chat.load_models() #加载本地box chat.load_models(compile=True, source='local', local_path="/root/autodl-tmp/model/chatTTS") # 定义要转换为语音的文本 texts = ["你好,欢迎使用ChatTTS"] # 生成语音 wavs = chat.infer(texts, use_decoder=True,do_text_normalization=False) # 播放生成的音频 Audio(wavs[0], rate=24_000, autoplay=True) 6、保存本地
将输出的音频文件,保存到本地磁盘
# Import necessary libraries and configure settings import torch import torchaudio import soundfile torch._dynamo.config.cache_size_limit = 64 torch._dynamo.config.suppress_errors = True torch.set_float32_matmul_precision('high') import ChatTTS from IPython.display import Audio # Initialize and load the model: chat = ChatTTS.Chat() #chat.load_models(compile=False) # Set to True for better performance chat.load_models(compile=True, source='local', local_path="/root/autodl-tmp/model/chatTTS") # Define the text input for inference (Support Batching) texts = [ "So we found being competitive and collaborative was a huge way of staying motivated towards our goals, so one person to call when you fall off, one person who gets you back on then one person to actually do the activity with.", ] # Perform inference and play the generated audio wavs = chat.infer(texts,do_text_normalization=False) Audio(wavs[0], rate=24_000, autoplay=True) # Save the generated audio #torchaudio.save("output.wav", torch.from_numpy(wavs[0]), 24000) soundfile.write("output1.wav", wavs[0][0], 24000) 7、笑声和停顿的控制
在chat.infer()函数中,确保use_decoder=True。
然后在文本中,[uv_break]和[lbreak]表示停顿;[laugh]表示笑声。
# Import necessary libraries and configure settings import torch import torchaudio import soundfile torch._dynamo.config.cache_size_limit = 64 torch._dynamo.config.suppress_errors = True torch.set_float32_matmul_precision('high') import ChatTTS from IPython.display import Audio # Initialize and load the model: chat = ChatTTS.Chat() #chat.load_models(compile=False) # Set to True for better performance chat.load_models(compile=True, source='local', local_path="/root/autodl-tmp/model/chatTTS") rand_spk = chat.sample_random_speaker() params_infer_code = { 'spk_emb': rand_spk, # add sampled speaker 'temperature': .3, # using custom temperature 'top_P': 0.7, # top P decode 'top_K': 20, # top K decode } ################################### # For sentence level manual control. # use oral_(0-9), laugh_(0-2), break_(0-7) # to generate special token in text to synthesize. params_refine_text = { 'prompt': '[oral_2][laugh_0][break_6]' } #wav = chat.infer(texts, params_refine_text=params_refine_text, params_infer_code=params_infer_code) ################################### # For word level manual control. text = 'What is [uv_break]your favorite english food?[laugh][lbreak]' wavs2 = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code) ##torchaudio.save("output2.wav", torch.from_numpy(wavs[0]), 24000) soundfile.write("output2.wav", wavs2[0][0], 24000) 8、批量推理
texts = ["So we found being competitive and collaborative was a huge way of staying motivated towards our goals, so one person to call when you fall off, one person who gets you back on then one person to actually do the activity with.",]*3 \ + ["我觉得像我们这些写程序的人,他,我觉得多多少少可能会对开源有一种情怀在吧我觉得开源是一个很好的形式。现在其实最先进的技术掌握在一些公司的手里的话,就他们并不会轻易的开放给所有的人用。"]*3 wavs = chat.infer(texts) #播放第一个 Audio(wavs[0], rate=24_000, autoplay=True) #播放第四个 Audio(wavs[3], rate=24_000, autoplay=True) 9、其他错误处理
1)错误1:模型文件下载不完整
运行代码样例报错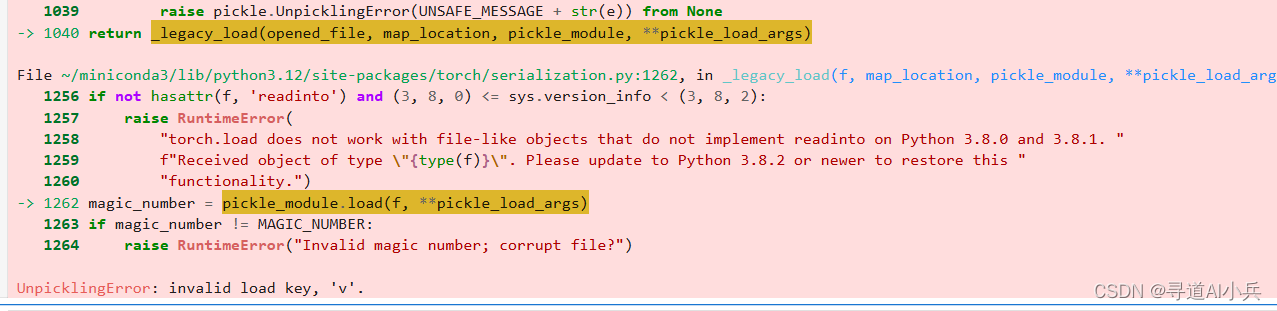
经常查找资料发现说是模型文件下载不完整导致的,对比发现asset目录下的文件的确没有下载完整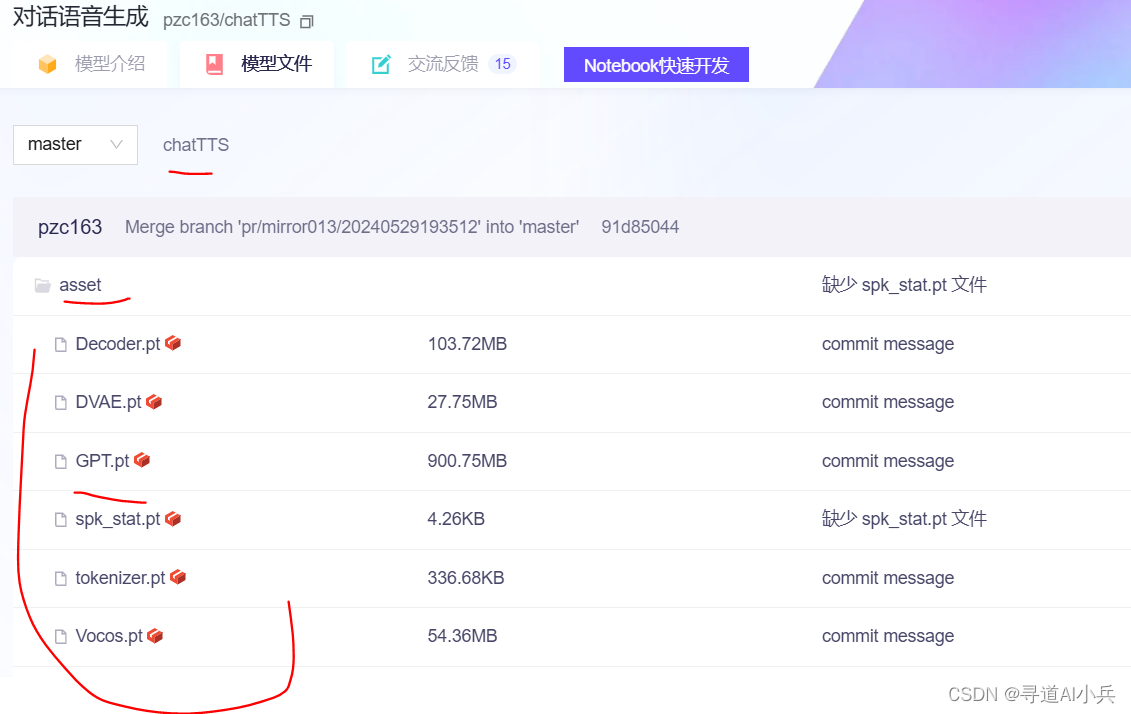
本地文件
在Ubuntu环境下使用Git LFS进行大文件版本控制的具体操作命令和步骤如下:
安装Git LFS:
sudo apt-get update sudo apt-get install git-lfs 启用Git LFS:
git lfs install 重新下载模型成功,这一次文件没有缺失
git clone https://www.modelscope.cn/pzc163/chatTTS.git 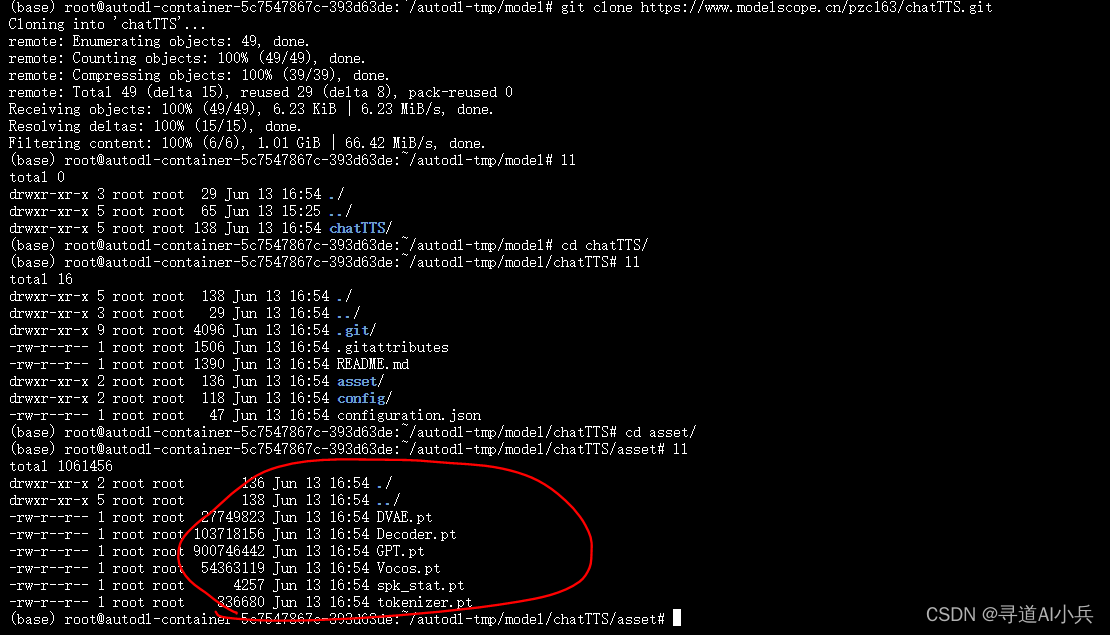
2)错误2:python版本不兼容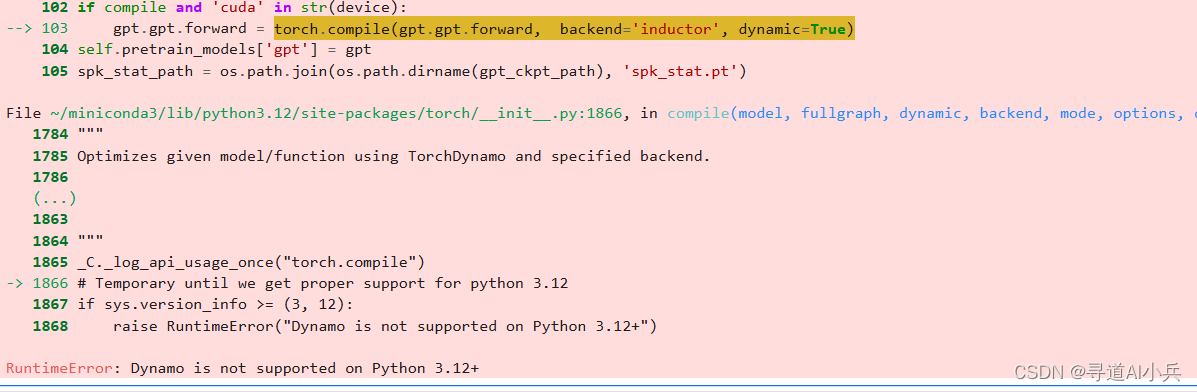
当前版本:
检查可用的Python版本
在激活环境后,检查哪些Python版本可供安装。通过执行以下命令,Conda会列出所有可用的Python版本供您选择:
conda search python 更新Python版本
选择一个版本,并运行以下命令来更新Python版本:
conda install python=3.11.9 3)错误3:cannot access local variable ‘Normalizer’
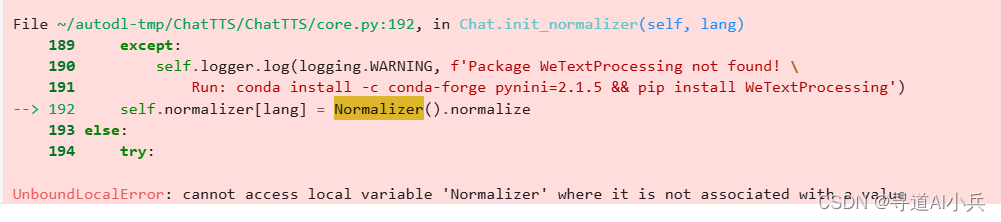
解决方案
1)参考错误信息中运行:cannot access local variable ‘Normalizer’
conda install -c conda-forge pynini=2.1.5 && pip install WeTextProcessing 2)推理时设置do_text_normalization=False
wavs = chat.infer(texts, use_decoder=True,do_text_normalization=False) 结语
ChatTTS作为一项新兴的文本转语音技术,其创新性和实用性已经得到了业界的广泛认可。随着技术的不断进步和优化,我们有理由相信ChatTTS将在语音合成领域扮演越来越重要的角色。对于技术爱好者和开发者而言,深入了解并掌握ChatTTS的使用,无疑将为他们的项目开发和创新带来更多的可能性。

🎯🔖更多专栏系列文章:AIGC-AI大模型开源精选实践
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:建立有技术交流群,可以扫码👇 加入社群,500本各类编程书籍、AI教程、AI工具等你领取!
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
