
阅读量:1
❃博主首页 : 「码到三十五」 ,同名公众号 :「码到三十五」,wx号 : 「liwu0213」
☠博主专栏 : <mysql高手> <elasticsearch高手> <源码解读> <java核心> <面试攻关>
♝博主的话 :搬的每块砖,皆为峰峦之基;公众号搜索「码到三十五」关注这个爱发技术干货的coder,一起筑基
关注公众号[码到三十五]获取更多技术干货 !
☠博主专栏 : <mysql高手> <elasticsearch高手> <源码解读> <java核心> <面试攻关>
♝博主的话 :搬的每块砖,皆为峰峦之基;公众号搜索「码到三十五」关注这个爱发技术干货的coder,一起筑基
文章目录
引言
Elasticsearch性能调优对于提升系统整体效能至关重要。然而,性能调优并非一蹴而就,需要深入理解ES的内部工作机制,并结合实际业务场景进行精细化调整。本文将深入解释ES性能调优方法的原理,结合具体案例展示如何在实际应用中优化ES性能。
1. 硬件选择和优化
磁盘优化
使用SSD:对于频繁读写操作的Elasticsearch集群,使用SSD(固态硬盘)可以显著提高I/O性能。
RAID配置:可以考虑使用RAID0来提高写入性能,或者使用RAID10(镜像+条带化来兼顾性能和数据安全性。
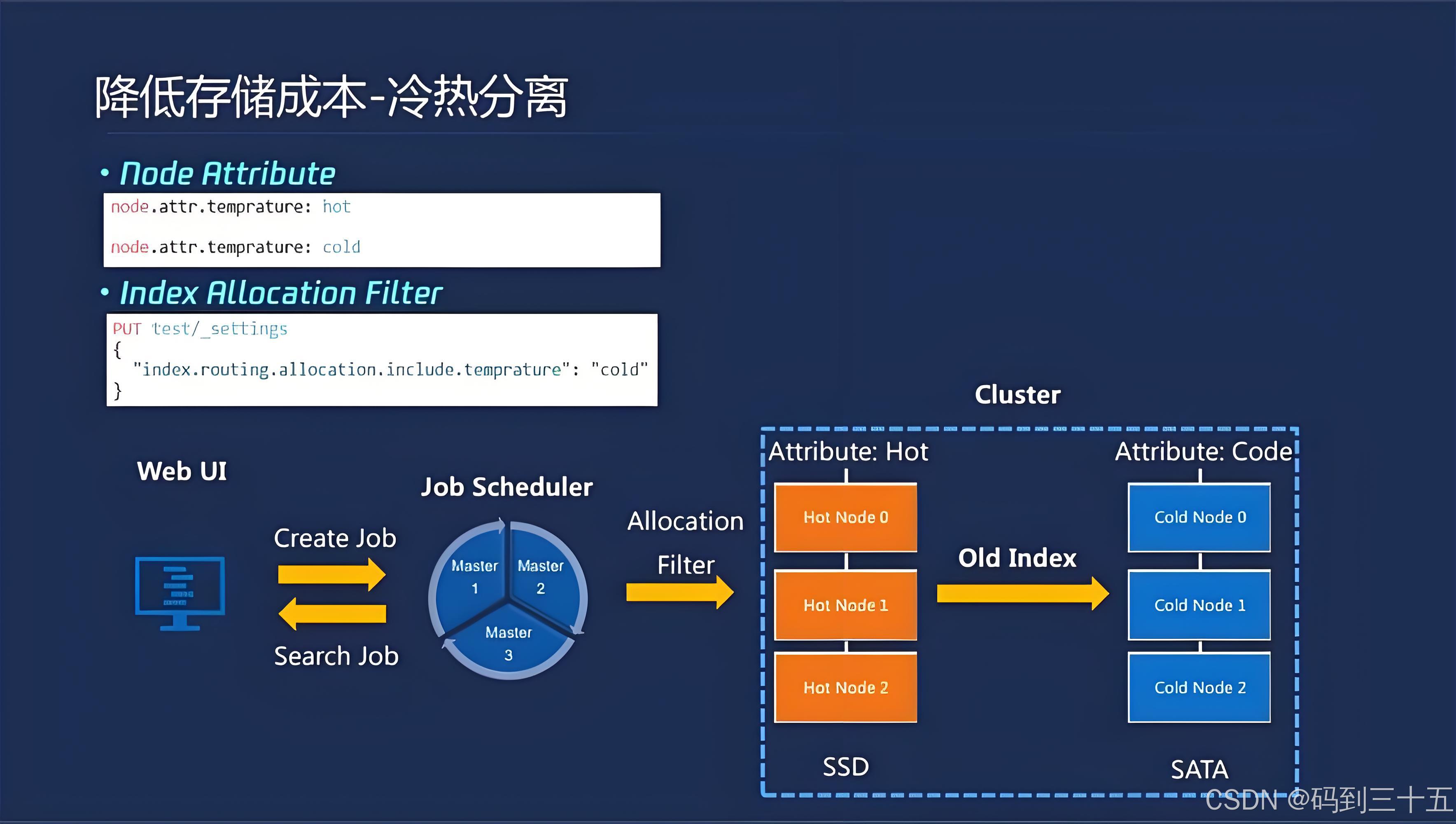
冷热数据分离:对于不经常访问的“冷数据”,可以将其存储在成本更低的机械硬盘上,以节省成本。
CPU优化
多核与多线程:选择CPU时,优先考虑核心数和线程数多的型号,以便更好地处理并发查询和索引操作
避免单核高性能:对于Elasticsearch来说,高单核性能并不是首要考虑的因素,因为Elasticsearch的设计可以很好地利用多核多线程。
网络优化
低延迟网络:确保Elasticsearch集群部署在低延迟的网络环境中,以减少节点间通信的延迟。
跨地域部署的注意事项:尽量避免跨地域部署单个集群,以减少网络故障的风险。
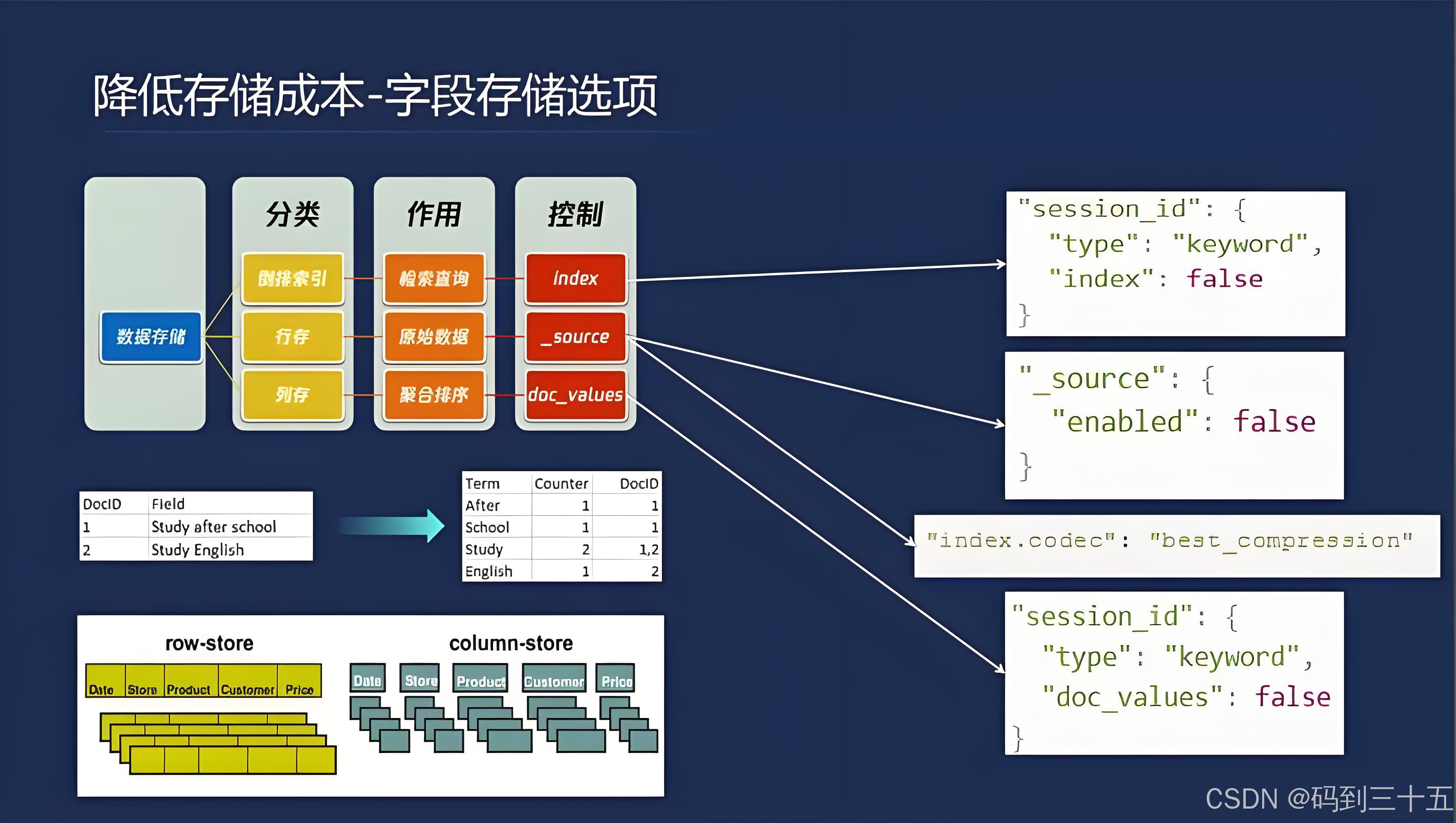
存储与压缩优化
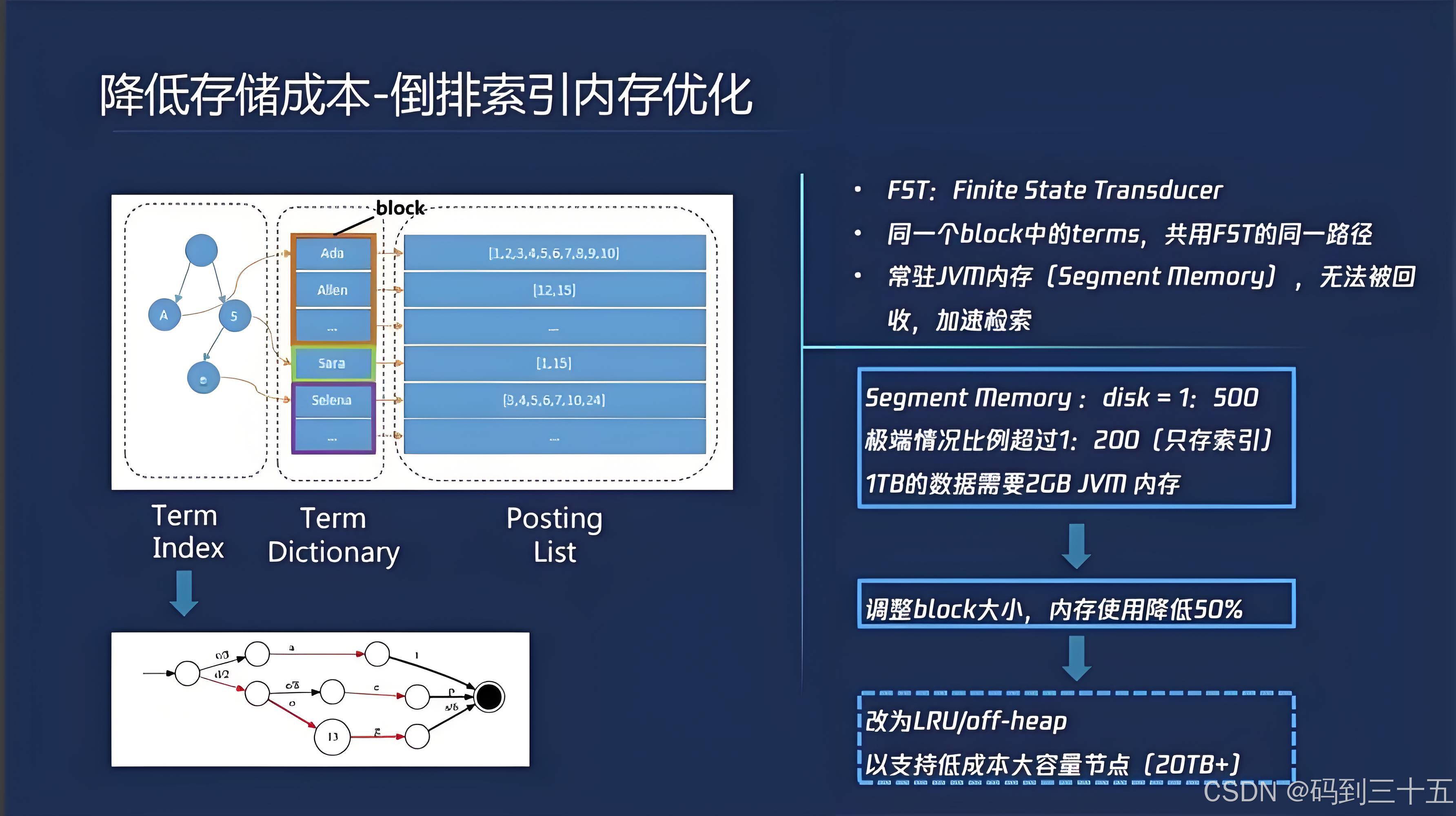
Elasticsearch内部对倒排表的存储进行了深度优化,使用了多种压缩算法来减少存储空间和提高查询效率。在数据建模时,应尽可能采用通用最小化法则,例如使用合适的字段类型(如Keyword代替数值类型进行精确匹配查询)、避免重复存储等。
- FST(Finite State Transducers)模型:Elasticsearch使用FST模型来存储词项字典,可以极大地节省存储空间并提升查询效率。一个TB级的索引,通过FST存储后,其构建的模型大小可缩小至1GB左右。
JVM与内存管理
Elasticsearch运行在JVM上,合理的JVM配置对于提升性能至关重要。JVM堆内存大小、垃圾回收策略等都会影响ES的写入和查询性能。
堆内存设置:一般建议JVM堆内存大小不超过物理内存的50%,且最大不超过32GB(对于支持Compressed OOP的JVM)。
禁用Swap:Swap交换会导致JVM堆内存被换出到磁盘,严重影响性能,应尽可能禁用Swap。
2. 索引与分片策略
索引生命周期管理
Rollover Index:定期创建新的索引来存储新数据,避免单个索引过大。
Index Lifecycle Management (ILM):利用Elasticsearch的ILM功能,自动化地管理索引的生命周期,包括创建、滚动、删除等操作。
分片与副本策略
ES通过分片(Shard)和副本(Replica)机制来实现数据的分布式存储和查询,从而提高系统的可用性和性能。
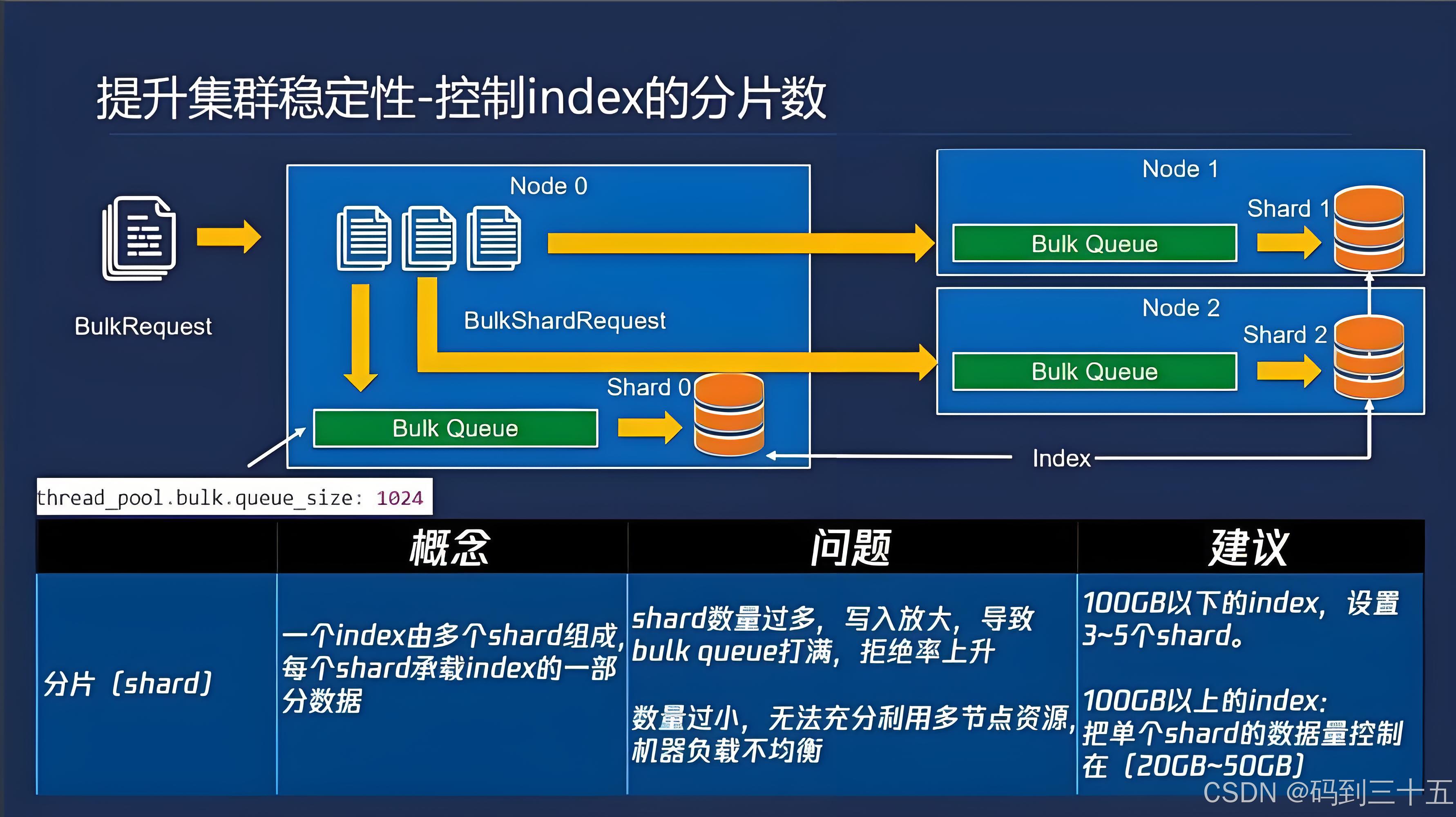
- 分片分配:分片用于数据的水平拆分,可以将数据分片存储在不同的节点上,提高查询的并行处理能力。合理的分片数量和大小对于优化性能至关重要。一般建议单个分片大小控制在10GB到50GB之间。根据数据的增长速度和查询负载来动态调整分片数量和大小。分片过多会增加查询时的JVM开销和协调节点的转发压力,影响查询性能。
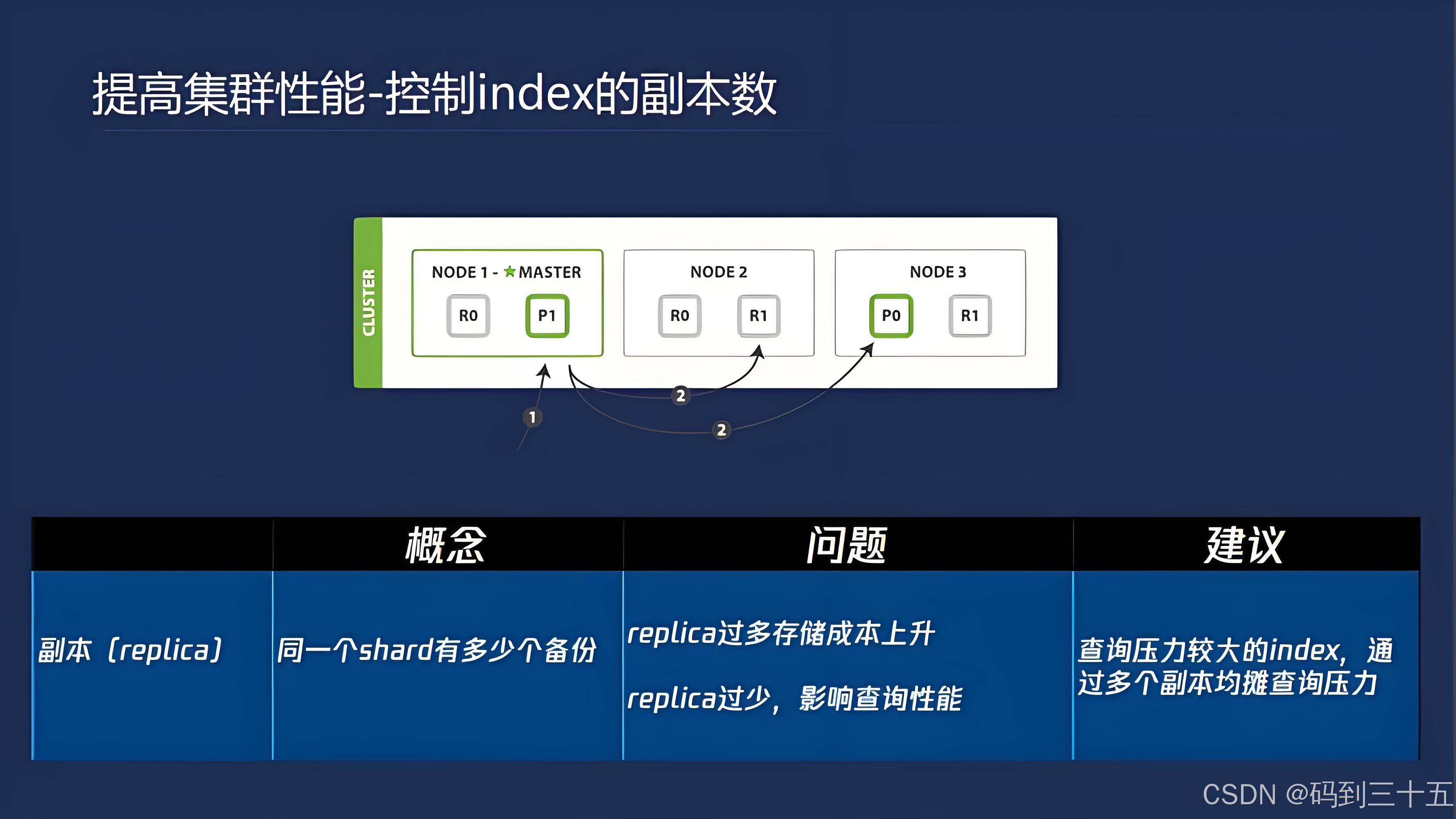
- 副本策略:副本用于数据的冗余存储,提高数据的可用性和容错能力。在写入大量数据时,可以暂时关闭副本以加速索引过程,待数据写入完成后再恢复副本。
3. 查询优化
缓存机制
- 利用查询缓存:Elasticsearch会自动缓存频繁执行的查询结果,以减少查询延迟。可以通过调整
indices.queries.cache.size参数来优化查询缓存的大小。
聚合优化
预索引聚合字段:对于经常需要聚合的字段,可以在索引时预先计算聚合结果,并存储在专门的字段中,以加快查询速度。
避免使用高成本的聚合操作:如global aggregations,这类聚合操作需要访问所有分片的数据,成本较高。
数据建模优化
使用nested和join字段谨慎:nested和join字段会显著增加查询的复杂度,仅在必要时使用,并考虑其性能影响。
合理使用mapping:例如,对于不需要全文检索的字段,可以使用
keyword类型而不是text类型,以提高查询性能。
其他
增加刷新间隔:减少不必要的索引刷新操作,可以提升写入性能。默认情况下,ES每秒刷新一次索引,但在批量写入场景下,可以适当增加刷新间隔。
使用filter代替query:filter查询不计算文档的相关性得分,且通常会被缓存,因此在执行精确匹配查询时,应优先考虑使用filter。
避免深度分页:深度分页会导致大量无用数据的检索,严重影响性能。建议使用scroll API或search_after参数来实现深度分页。
4. 监控与日志
- 实时监控集群状态:使用Elasticsearch自带的监控工具或第三方监控解决方案(如Kibana、Grafana等)来实时监控集群的性能指标(如CPU使用率、内存占用、查询延迟等)。
- 日志分析:定期检查Elasticsearch的日志文件,分析错误信息、警告信息和慢查询日志,及时发现并解决潜在的性能问题。
5. 高级调优技巧
脚本优化
- 避免在查询中使用复杂的脚本:脚本查询通常比DSL查询慢得多,应尽量避免在高频查询中使用脚本。
文档路由
- 合理设置文档路由:通过为文档指定路由值,可以控制文档存储到哪个分片上,有助于优化查询性能和数据分布。
插件与扩展
- 利用插件增强功能:Elasticsearch提供了丰富的插件生态系统,可以通过安装合适的插件来扩展功能或优化性能(如analysis插件、security插件等)。
5. 案例
背景
一家提供SMS短信服务的供应商,其主要客户群体为各大银行系统。随着业务量的增长,短信发送记录的索引变得异常庞大,严重影响了系统的写入和查询性能。
痛点分析
- 索引过于庞大:单个索引包含了大量的短信发送记录,导致查询和写入性能下降。
- 索引过多:虽然通过滚动索引策略解决了单个索引过大的问题,但随着时间推移,索引数量激增,跨索引查询性能成为新的瓶颈。
解决方案
优化索引结构:
- 采用滚动索引策略,每天创建一个新的索引来存储当天的短信发送记录。
- 根据业务属性(如手机号归属地、所属运营商)对索引进行拆分,减少跨索引查询的范围。
调整JVM与内存设置:
- 增加JVM堆内存大小,确保系统有足够的内存来处理大量数据。
- 禁用Swap,避免JVM堆内存被换出到磁盘。
优化查询性能:
- 对于精确匹配查询,使用filter代替query。
- 避免深度分页,使用scroll API来实现大数据量的分页查询。
动态调整分片与副本:
- 根据数据量和业务需求动态调整分片数量和大小。
- 在批量写入时,暂时关闭副本以加速索引过程。
具体设置及代码
JVM设置
在elasticsearch.yml中配置JVM堆内存大小:
-Xms32g -Xmx32g 禁用Swap:
# 编辑/etc/sysctl.conf文件 vm.swappiness=0 # 执行sysctl -p使设置生效 sysctl -p 索引设置
调整索引刷新间隔和Buffer大小:
PUT /sms_index/_settings { "index" : { "refresh_interval" : "30s", "indices.memory.index_buffer_size": "20%" } } 关闭副本进行批量写入:
PUT /sms_index/_settings { "number_of_replicas": 0 } 批量写入完成后,恢复副本数量:
PUT /sms_index/_settings { "number_of_replicas": 1 } 查询优化
使用filter代替query进行精确匹配查询:
GET /sms_index/_search { "query": { "bool": { "filter": [ { "term": { "phone_number": "138xxxxxx88" }} ] } } } 使用scroll API进行深度分页查询:
POST /sms_index/_search?scroll=1m { "size": 100, "query": { "match_all": {} } } # 使用scroll id进行后续查询 GET /_search/scroll { "scroll": "1m", "scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==" } 结语
Elasticsearch性能调优是一个持续的过程,需要根据业务需求、数据量和集群规模不断调整和优化。希望本文提供的详细分析和建议能够帮助读者更好地理解和应用Elasticsearch性能调优方法,提升系统的整体效能。同时,也鼓励读者不断探索和实践新的调优策略,以适应不断变化的业务需求和技术环境。

