阅读量:0
文章目录
1语言模型的概念
语言模型使用概率来评估一个单词序列发生的可能性,即在多大程度上是自然的单词序列
- 例如在语音识别中,系统会根据人的发言生成多个句子作为候选;此时,使用语言模型,可以按照“作为句子是否自然”这一基准对候选句子进行排序;即按照每个句子是自然的句子的概率来排序;
用后验概率来表示一个句子(语言模型):
考虑由 m m m个单词 w 1 , ⋅ ⋅ ⋅ , w m w_1, · · · ,w_m w1,⋅⋅⋅,wm构成的句子,将单词按 w 1 , ⋅ ⋅ ⋅ , w m w_1, · · · ,w_m w1,⋅⋅⋅,wm的顺序出现的概率记为 P ( w 1 , ⋅ ⋅ ⋅ , w m ) P(w_1, · · · ,w_m) P(w1,⋅⋅⋅,wm);因为这个概率是多个事件一起发生的概率,所以称为联合概率;
根据概率的知识,两个事件同时发生的概率可以用条件概率来表示,如下式所示;至于谁是谁的条件都可以,这里并没有明确的先后顺序;
P ( A , B ) = P ( A ∣ B ) P ( B ) (1) P(A,B)=P(A|B)P(B) \tag{1} P(A,B)=P(A∣B)P(B)(1)
即 A A A和 B B B两个事件共同发生的概率 P ( A , B ) P(A,B) P(A,B)是 B B B发生的概率 P ( B ) P(B) P(B)和 B B B发生后 A A A发生的概率 P ( A ∣ B ) P(A|B) P(A∣B)的乘积。基于这个概率公式,我们可以对上面的联合概率 P ( w 1 , ⋅ ⋅ ⋅ , w m ) P(w_1, · · · ,w_m) P(w1,⋅⋅⋅,wm)进行分解,分解过程如下:
首先,令 A = w 1 , ⋅ ⋅ ⋅ w m − 1 A=w_1, · · · w_{m-1} A=w1,⋅⋅⋅wm−1,则有:
P ( w 1 , ⋅ ⋅ ⋅ , w m ) = P ( A , w m ) = P ( w m ∣ A ) P ( A ) (2) P(w_1, · · · ,w_m)=P(A,w_m)=P(w_m|A)P(A) \tag{2} P(w1,⋅⋅⋅,wm)=P(A,wm)=P(wm∣A)P(A)(2)类似地,令 A ′ = w 1 , ⋅ ⋅ ⋅ w m − 2 A^{'}=w_1, · · · w_{m-2} A′=w1,⋅⋅⋅wm−2,则有:
P ( A ) = P ( A ′ , w m − 1 ) = P ( w m − 1 ∣ A ′ ) P ( A ′ ) (3) P(A)=P(A^{'},w_{m-1})=P(w_{m-1}|A^{'})P(A^{'}) \tag{3} P(A)=P(A′,wm−1)=P(wm−1∣A′)P(A′)(3)以此类推,我们最终可以将联合概率分解为:
P ( w 1 , ⋅ ⋅ ⋅ , w m ) = P ( w m ∣ w 1 , ⋯ , w m − 1 ) P ( w m − 1 ∣ w 1 , ⋯ , w m − 2 ) . . . P ( w 3 ∣ w 1 , w 2 ) P ( w 2 ∣ w 1 ) P ( w 1 ) = ∏ t = 1 m P ( w t ∣ w 1 , ⋯ , w t − 1 ) (4) \begin{aligned} P(w_1, · · · ,w_m)&=P(w_m|w_1,\cdots,w_{m-1})P(w_{m-1}|w_1,\cdots,w_{m-2})...P(w_3 | w_1,w_2)P(w_2 | w_1)P(w_1)\\ &=\prod_{t=1}^mP(w_t|w_1,\cdots,w_{t-1}) \end{aligned} \tag{4} P(w1,⋅⋅⋅,wm)=P(wm∣w1,⋯,wm−1)P(wm−1∣w1,⋯,wm−2)...P(w3∣w1,w2)P(w2∣w1)P(w1)=t=1∏mP(wt∣w1,⋯,wt−1)(4)
即联合概率可以表示为后验概率的乘积。放到句子中就是:以目标词左侧的全部单词为上下文(条件)的后验概率表示到目标词为止的句子的概率。也就是说,要求语言模型的联合概率 P ( w 1 , ⋅ ⋅ ⋅ , w m ) P(w_1, · · · ,w_m) P(w1,⋅⋅⋅,wm),只需要求式(4)中的 P ( w t ∣ w 1 , ⋯ , w t − 1 ) P(w_t|w_1,\cdots,w_{t-1}) P(wt∣w1,⋯,wt−1)。
2概率视角下的word2vec
以CBOW模型为例。
- CBOW模型是用目标词左右的上下文单词来预测中间的词;在
1.6自然语言的分布式表示-word2vec补充说明.md中我们说过,CBOW可以用概率建模为 P ( w t ∣ w t − 1 , w t + 1 ) P(w_t|w_{t-1},w_{t+1}) P(wt∣wt−1,wt+1);并结合交叉熵损失函数进一步转换为 L = − log P ( w t ∣ w t − 1 , w t + 1 ) L=-\log P(w_t|w_{t-1},w_{t+1}) L=−logP(wt∣wt−1,wt+1); - 如果只考虑目标词左侧的窗口,窗口大小设置为2;即考虑目标词左侧的2个单词;则CBOW可以用概率建模为 P ( w t ∣ w t − 2 , w t − 1 ) P(w_t|w_{t-2},w_{t-1}) P(wt∣wt−2,wt−1);
3能否将word2vec用作语言模型
- 概括
- word2vec 是以获取单词的分布式表示为目的的方法,因此一般不会用于语言模型
- 基于 RNN 的语言模型虽然也能获得单词的分布式表示,但是为了应对词汇量的增加、提高分布式表示的质量,word2vec 被提了出来。
语言模型的联合概率 P ( w 1 , ⋅ ⋅ ⋅ , w m ) P(w_1, · · · ,w_m) P(w1,⋅⋅⋅,wm)是需要求句子中每个单词的 P ( w t ∣ w 1 , ⋯ , w t − 1 ) P(w_t|w_1,\cdots,w_{t-1}) P(wt∣w1,⋯,wt−1),然后相乘;我们如果在CBOW模型中限定只考虑目标词左侧的窗口,窗口大小设置为2,那么语言模型的联合概率 P ( w 1 , ⋅ ⋅ ⋅ , w m ) P(w_1, · · · ,w_m) P(w1,⋅⋅⋅,wm)可以近似表示为下式:
P ( w 1 , ⋅ ⋅ ⋅ , w m ) = ∏ t = 1 m P ( w t ∣ w 1 , ⋯ , w t − 1 ) ≈ ∏ t = 1 m P ( w t ∣ w t − 2 , w t − 1 ) (5) P(w_1, · · · ,w_m)=\prod_{t=1}^mP(w_t|w_1,\cdots,w_{t-1})\approx\prod_{t=1}^mP(w_t|w_{t-2},w_{t-1}) \tag{5} P(w1,⋅⋅⋅,wm)=t=1∏mP(wt∣w1,⋯,wt−1)≈t=1∏mP(wt∣wt−2,wt−1)(5)由于这个上下文窗口大小是可以设置的,因此我们可以将其扩大,这样可以考虑足够长的上文单词;
但是需要注意的是,虽然上下文窗口大小是可以设置的,但是必须是固定的,因为CBOW模型的结构中,我们需要根据上下文窗口大小去生成相应数量的输入层;
那么,既然是固定的,就可能存在一个很长的句子,我们的上下文窗口没法完全覆盖,那就存在信息的丢失;下图是书上的一个例子:

另外,对于word2vec模型,没有去考虑单词的顺序;例如在CBOW模型中,我们是直接将多个输入层的输出结果相加再求平均的,是没有顺序的;当然,针对这个问题也有相关的改进,比如在中间层拼接上下文的单词向量,这虽然能够将顺序的信息加入,但是当上下文单词很多时,权重参数的数量将与上下文大小成比例地增加,如下图所示:
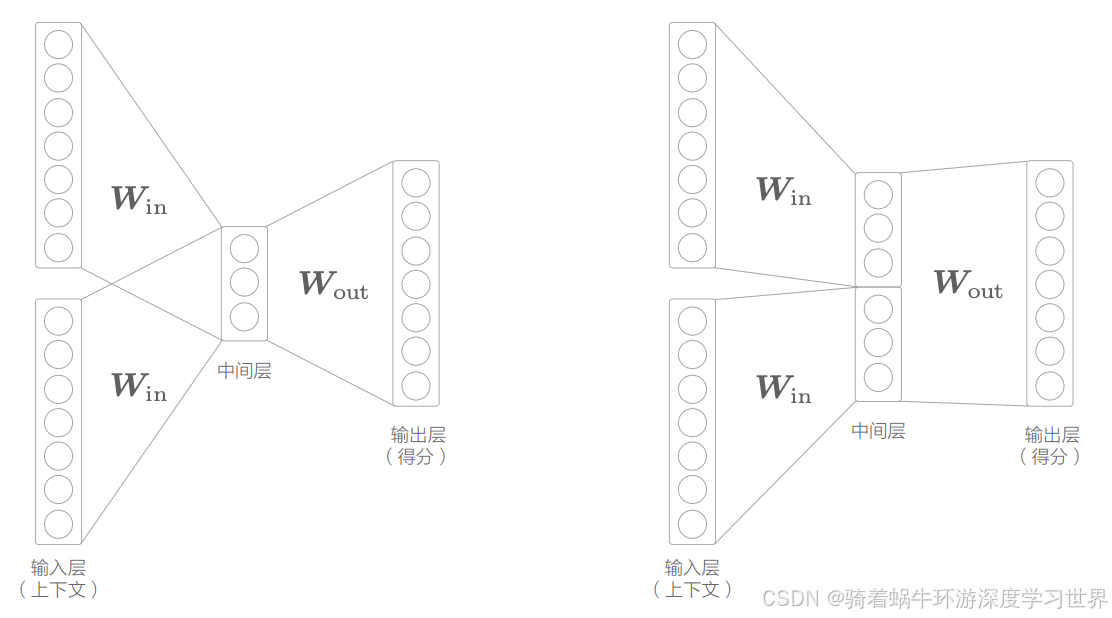
因此,word2vec模型不适合来表示语言模型;
4 RNN
Recurrent Neural Network 通常译为“循环神经网络”。另外, 还有一种被称为 Recursive Neural Network(递归神经网络)的网络。这个网络主要用于处理树结构的数据,和循环神经网络不是一个东西。
4.1 RNN层的简单结构
循环神经网络得有循环吧;那这个循环直观体现在RNN层的结构上;
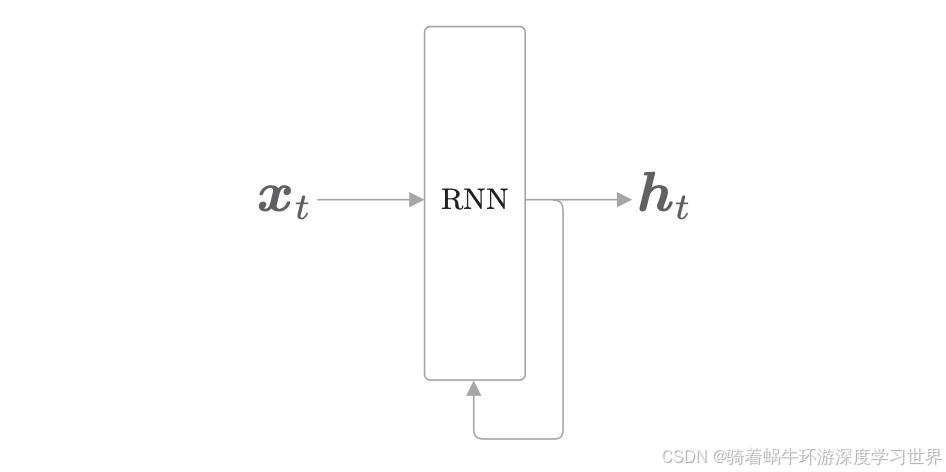
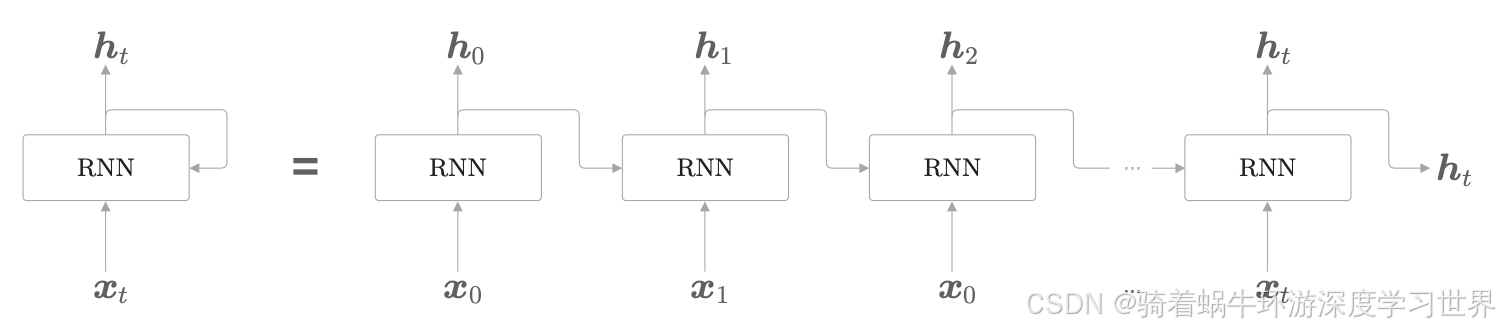
RNN层的结构如下图所示:
- 时序数据 ( x 0 , x 1 , ⋯ , x t , ⋯ ) (\boldsymbol{x}_0,\boldsymbol{x}_1,\cdots,\boldsymbol{x}_t,\cdots) (x0,x1,⋯,xt,⋯)会被输入到RNN层中;时刻 t t t的输入是 x t \boldsymbol{x}_t xt,得到输出 h t \boldsymbol{h}_t ht;整个时序数据的输出就是 ( h 0 , h 1 , ⋯ , h t , ⋯ ) (\boldsymbol{h}_0,\boldsymbol{h}_1,\cdots,\boldsymbol{h}_t,\cdots) (h0,h1,⋯,ht,⋯);
- 在各个时刻输入的 x t \boldsymbol{x}_t xt都是向量;对应到句子里面,每个时刻输入的就是某个单词的向量表示;
- 下图中输出侧有分支,说明RNN层的输出被**复制**了,一个进入到后面的层, 一个又指向了自己;
- 通过这个指向自己的分支,形成循环;通过数据的循环,RNN 一边记住过去的数据,一边更新到最新的数据
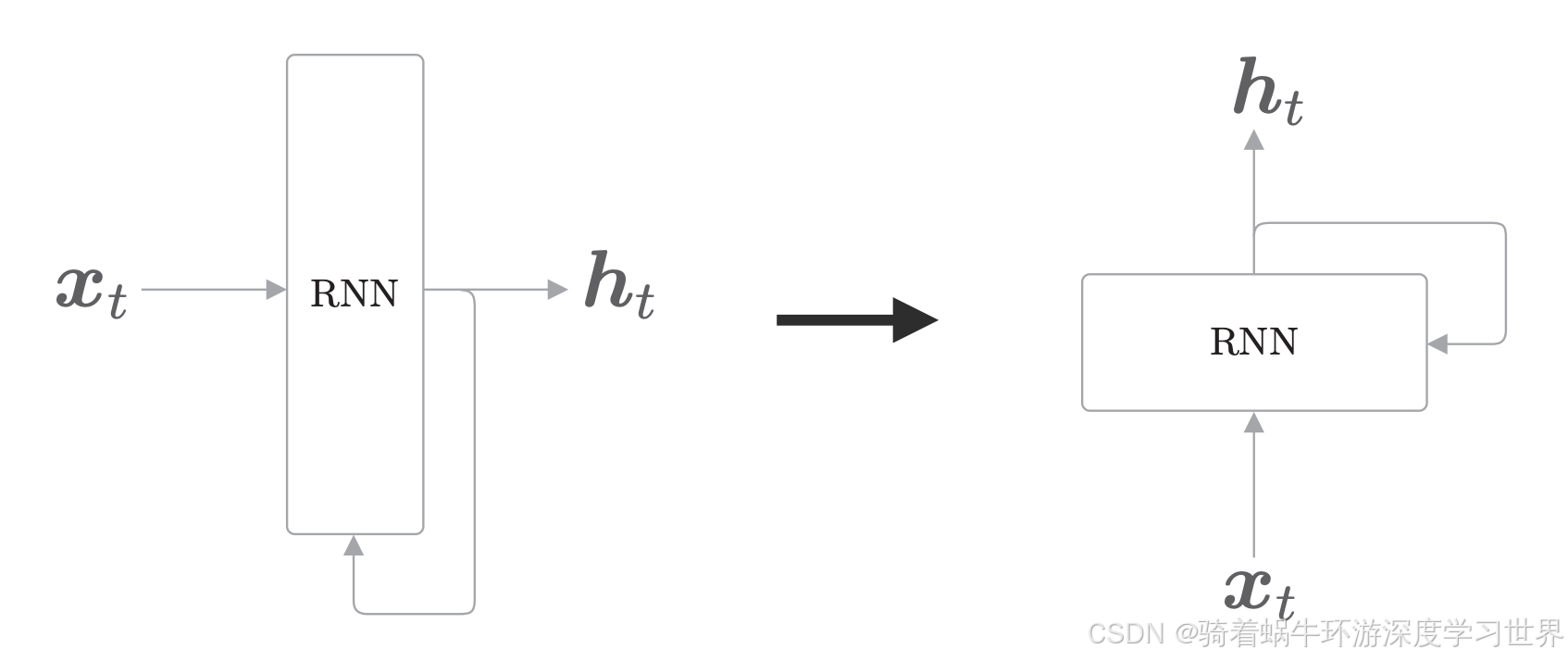
为了能够展示RNN层记住过去信息的特点,需要将上图旋转为下图的样子:
4.2 RNN层的循环结构
RNN的循环结构如下图所示:
- 在循环结构中我们可以引入时刻的概念:时刻 t t t的输入数据为 x t \boldsymbol{x}_t xt;在自然语言处理的情况下, x t \boldsymbol{x}_t xt就是第 t t t个单词或者第 t t t个RNN层,也可以说时刻 t t t的单词或时刻 t t t的RNN层;
- 各个时刻的 RNN 层接收传给该层的输入 x t \boldsymbol{x}_t xt和前一个 RNN 层的输出 h t − 1 \boldsymbol{h}_{t-1} ht−1;
- 这样的从左向右延伸的长神经网络,和我们之前看到的前馈神经网络的结构相同;但是需要注意的是,这里虽然展开成多个RNN层,但实际上都是一个层,换句话说,梯度反向传播时,更新的参数只有一组,而不是每个层都有自己的一组参数;
单独看一下其中一个RNN层:根据输入和上一个时刻的输出,通过式(6)计算当前时刻的输出:
- 式中的 W h \boldsymbol{W}_h Wh和 W x \boldsymbol{W}_x Wx是两个权重矩阵, b \boldsymbol{b} b是偏置;
- 对于自然语言处理而言,当前时刻的 x t \boldsymbol{x}_t xt是一个单词的单词向量,即一个行向量; W x \boldsymbol{W}_x Wx作用于当前时刻输入, W h \boldsymbol{W}_h Wh作用于上一时刻的隐藏状态 h t − 1 \boldsymbol{h}_{t-1} ht−1,加上偏置后计算双曲正切,得到当前RNN层的输出 h t \boldsymbol{h}_{t} ht;
- 这个 h t \boldsymbol{h}_{t} ht一方面向上输出到另一个层,另一方面向右输出到下一个 RNN 层(自身)。
- 设输入的单词向量的维数是 D D D,隐藏状态向量的维数是 H H H; W x \boldsymbol{W}_x Wx将输入变换到隐藏状态空间的维度,因此 W x ∈ R D × H \boldsymbol{W}_x\in R^{D\times H} Wx∈RD×H;通过公式可以知道 h t \boldsymbol{h}_{t} ht与 x t W x \boldsymbol{x}_t\boldsymbol{W}_x xtWx的维度应该是一样的,即 h t ∈ R 1 × H \boldsymbol{h}_t\in R^{1\times H} ht∈R1×H;如此一来,可以推出其他各个量的形状;
- 整个公式的形状变化如式(7)所示;
h t = tanh ( h t − 1 W h + x t W x + b ) (6) \boldsymbol{h}_t=\tanh(\boldsymbol{h}_{t-1}\boldsymbol{W}_h+\boldsymbol{x}_t\boldsymbol{W}_x+\boldsymbol{b}) \tag{6} ht=tanh(ht−1Wh+xtWx+b)(6)
( 1 , H ) = t a n h ( ( 1 , H ) ⋅ ( H , H ) + ( 1 , D ) ⋅ ( D , H ) + ( 1 , H ) ) (7) (1,H)=tanh((1,H)\cdot(H,H)+(1,D)\cdot(D,H)+(1,H)) \tag{7} (1,H)=tanh((1,H)⋅(H,H)+(1,D)⋅(D,H)+(1,H))(7)
经过上面的介绍可以看出,现在的输出 h t \boldsymbol{h}_{t} ht是由前一个输出 h t − 1 \boldsymbol{h}_{t-1} ht−1计算出来的;也就是说,RNN具有“状态” h \boldsymbol{h} h,并通过式(6)不断被更新,那么之后的 h t \boldsymbol{h}_{t} ht就具有了之前所有隐藏状态 h \boldsymbol{h} h的信息;这就是说RNN层是“具有状态的层”或“具有存储(记忆)的层”的原因。
4.3 RNN的反向传播
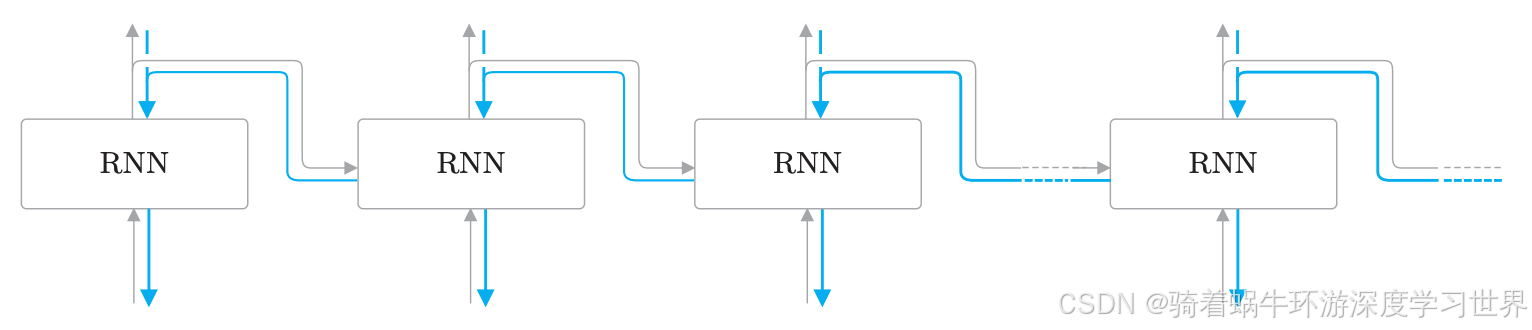
从RNN的结构来看,RNN除了像普通神经网络那样具有纵向的前向计算外,还在水平方向上有一个正向传播计算;但是都是可以遵循计算图的;
由于水平方向上是按时间顺序展开计算的,即**按时间顺序展开的神经网络的误差反向传播法,因此称为基于时间的反向传播,Backpropagation Through Time,简称BPTT**。
如下图所示是RNN在水平方向上反向传播的示意图:
4.4 Truncated BPTT
意思为被截断的BPTT。
当水平方向上的循环过长时,在反向传播时,需要保留的正向计算时的中间数据就越多,消耗的资源就越多,因此不能对整个时间序列来求梯度,需要进行截断;而且长度过长,梯度反向传播时可能也存在梯度消失等问题;
Truncated BPTT是什么:
- 将时间轴方向上过长的网络在合适的位置进行截断,从而创建多个小型网络,然后对截出来的小型网络执行误差反向传播法;
- 如下图所示,我们每10个单词进行一次截断;
- 像这样,只要将反向传播的连接截断,就不需要再考虑块范围以外的数据了,因此可以以各个块为单位(和其他块没有关联)完成误差反向传播法。

反向传播被分成好多个部分,但是**正向传播是没有被截断的**;即上图中 h 9 \boldsymbol{h}_{9} h9依然会进入到下一个RNN层与 x 10 \boldsymbol{x}_{10} x10一起得到 h 10 \boldsymbol{h}_{10} h10;
4.5 Truncated BPTT的mini-batch学习
4.5.1不考虑mini-batch
- 目前来说,我们可以先总结如下:
- RNN中,一个batch里面每条数据都是一个句子;每个batch输入每个句子的某个块的数据;下一个batch再输入这些句子下一个块的数据。
- 每个batch中,都使用每条句子的当前块的数据进行正向传播,然后反向传播计算梯度;
- 一般的神经网络是:一个batch就是把多个句子的全部数据输入进去;下一个batch就是另外一些句子了;
在之前的word2vec的网络结构中,一个句子可以形成多个
<上下文单词,目标词>对,我们将其输入到神经网络层中,计算中间结果;例如CBOW模型,我们可以用一个mini-batch将多个<上下文单词,目标词>对送入网络,但我们不需要去考虑每个<上下文单词,目标词>对谁在前,谁在后;但是RNN网络中,使用Truncated BPTT来进行模型学习时,根据截断的大小,一个句子会被相应的分成几块;那么这个句子的几个块需要按顺序输入到网络中,比如:
先输入第一个块的数据 ( x 0 , x 1 , . . . , x 9 ) (\boldsymbol{x}_0,\boldsymbol{x}_1,...,\boldsymbol{x}_9) (x0,x1,...,x9),进行正向传播和反向传播,如下图所示:
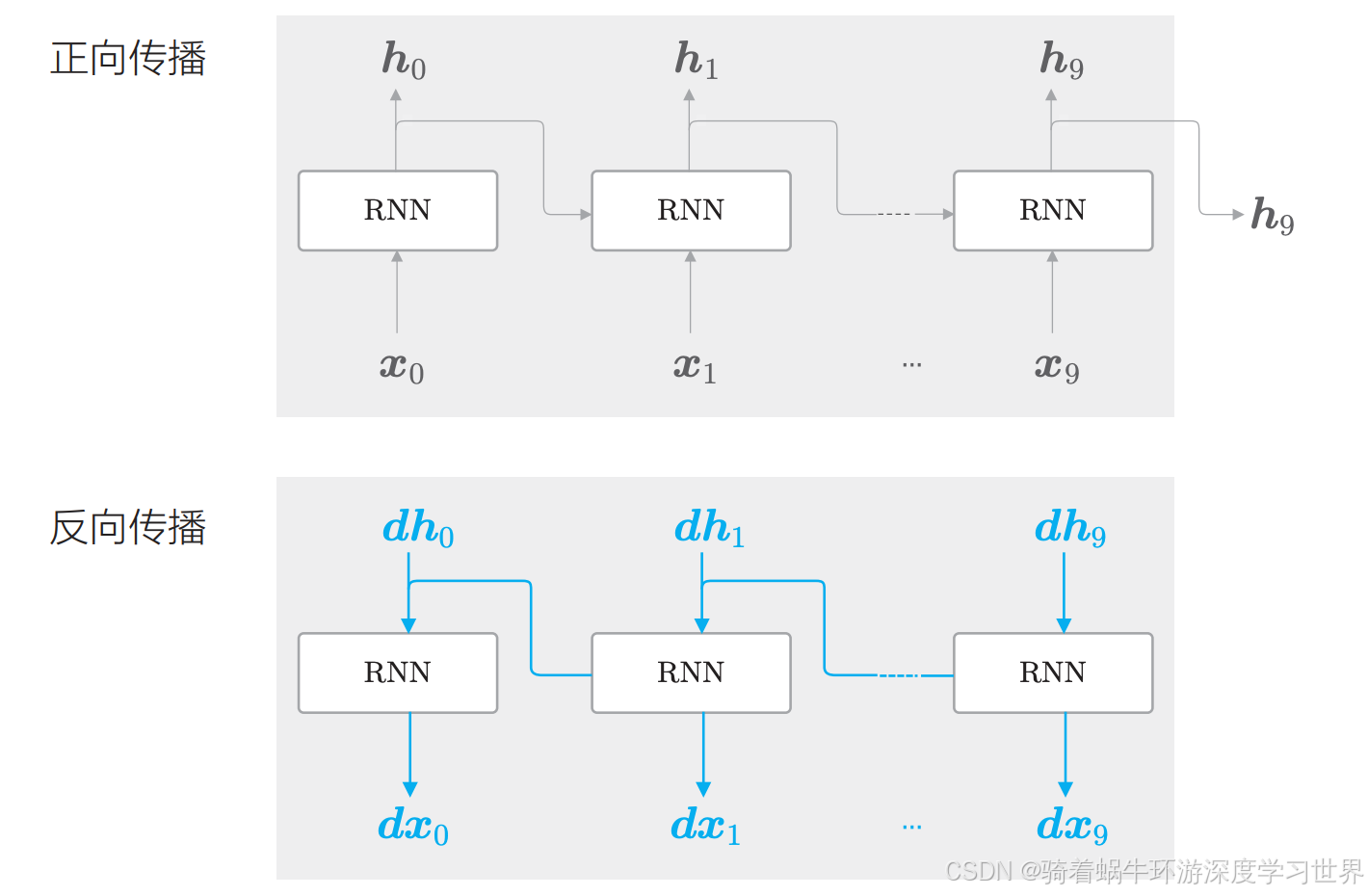
然后输入下一个块的数据 ( x 10 , x 11 , . . . , x 19 ) (\boldsymbol{x}_{10},\boldsymbol{x}_{11},...,\boldsymbol{x}_{19}) (x10,x11,...,x19),此时正向传播的计算需要前一个块最后的隐藏状态 h 9 \boldsymbol{h}_{9} h9;即正向传播是连续没有截断的;然后反向传播的时候依然是在这个块内进行,不接收前面的块的梯度,也不将梯度传递到下一个块;如下图所示:
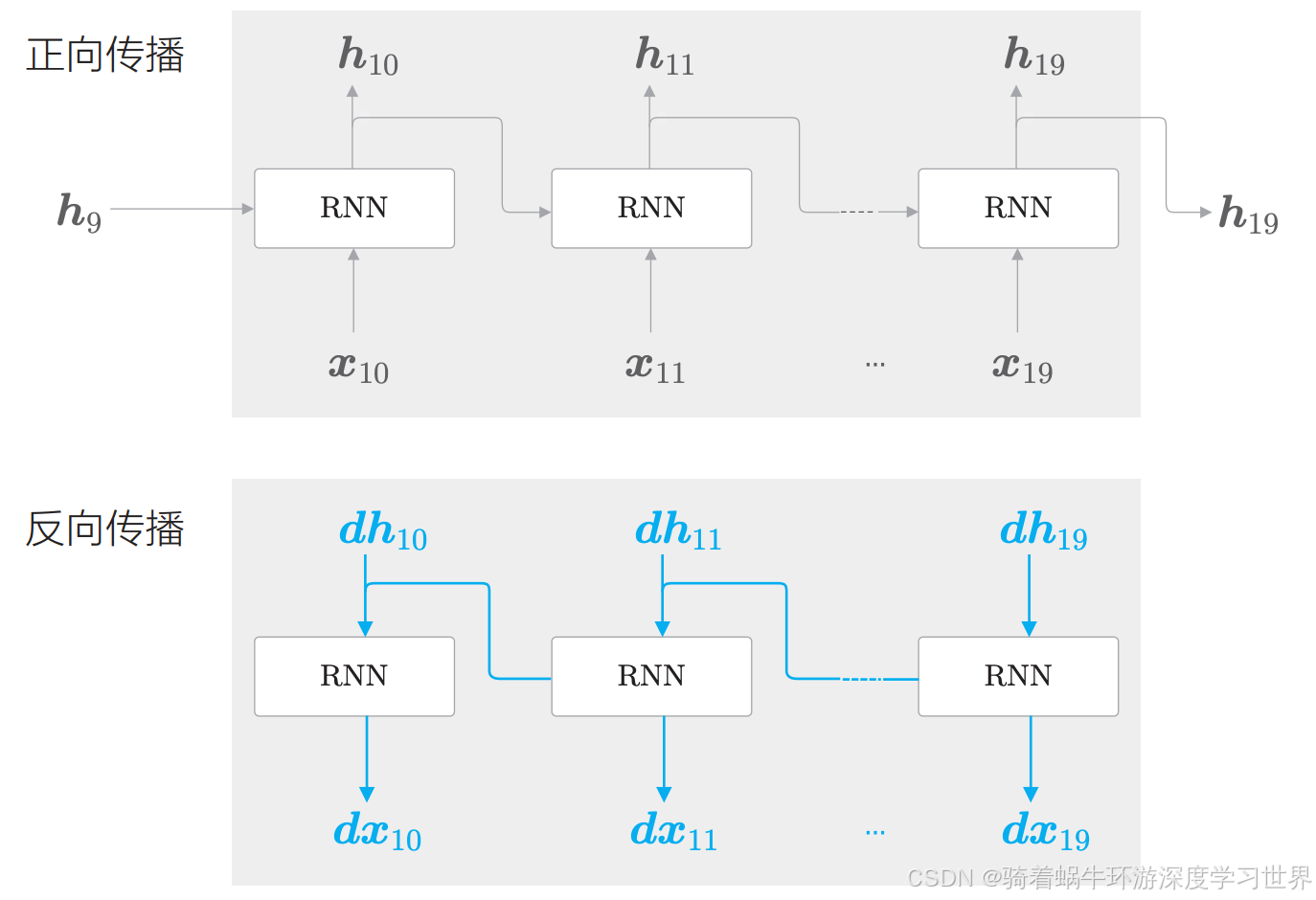
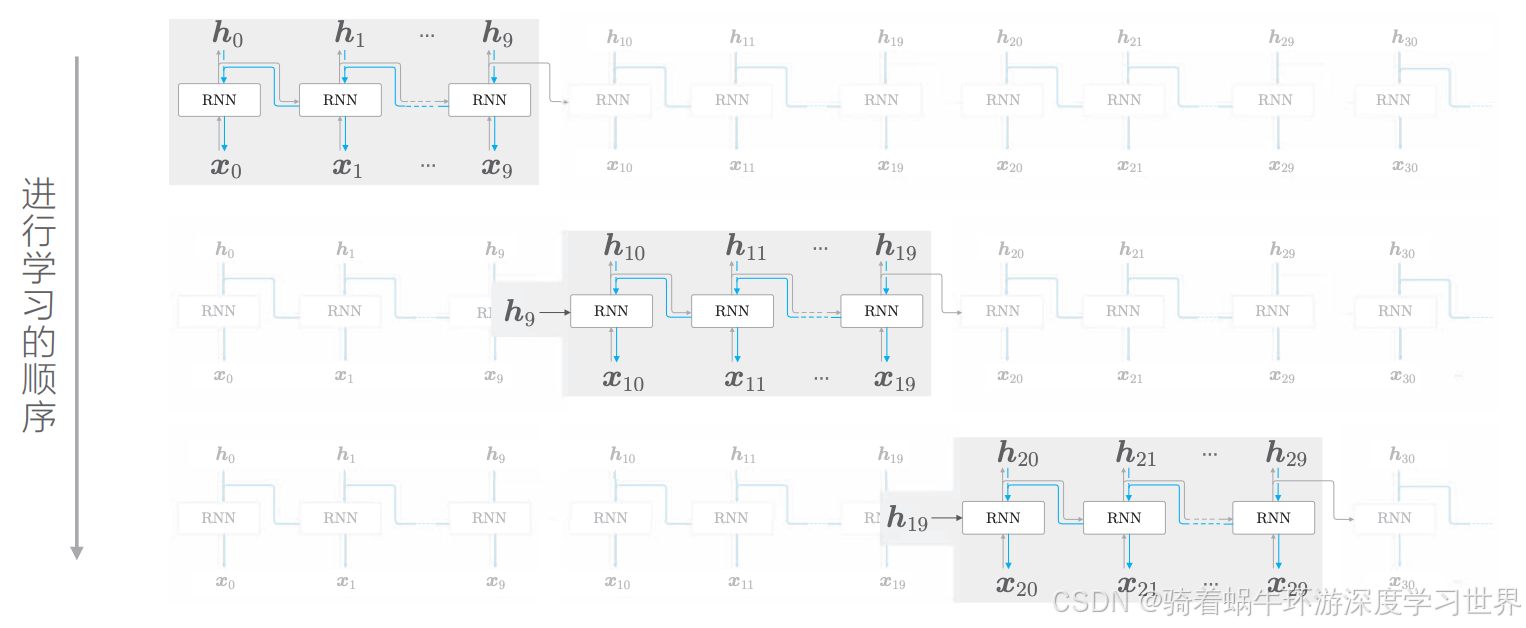
依此类推,这个过程的学习顺序就是下图的样子:
- 每次都是一个块的数据进行前向计算,以及反向传播;
- 然后再来一个块的数据;
- 重复上述过程;
- 由此可知,RNN中的块是复用的,即每一组数据都按顺序输入到同一个块中;
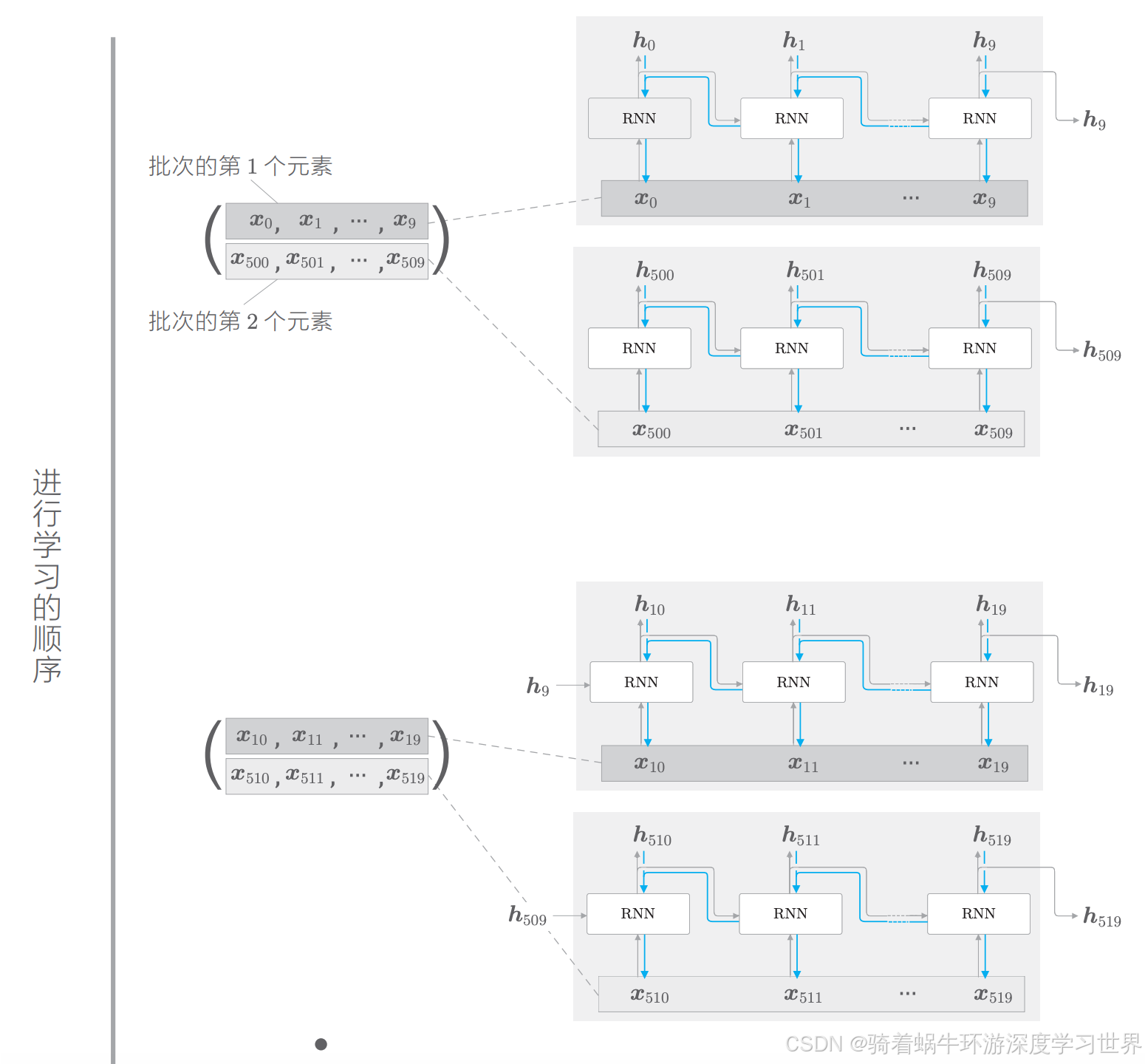
4.5.2考虑mini-batch
示例为:对长度为1000的时序数据,以时间长度10为单位进行截断。此时, 如何将批大小设为 2 进行学习呢
由于批处理大小为2,因此相当于一个批次可以同时处理两个句子对应的一个块的数据;因此我们可以把长度为1000的时序数据分成两个“句子”,每个“句子”的长度为500
时间长度为10,因此第一个batch我们只能处理 ( x 0 , x 1 , . . . , x 9 ) (\boldsymbol{x}_0,\boldsymbol{x}_1,...,\boldsymbol{x}_9) (x0,x1,...,x9)和 ( x 500 , x 501 , . . . , x 509 ) (\boldsymbol{x}_{500},\boldsymbol{x}_{501},...,\boldsymbol{x}_{509}) (x500,x501,...,x509),然后第二个batch处理处理 ( x 10 , x 11 , . . . , x 19 ) (\boldsymbol{x}_{10},\boldsymbol{x}_{11},...,\boldsymbol{x}_{19}) (x10,x11,...,x19)和 ( x 510 , x 511 , . . . , x 519 ) (\boldsymbol{x}_{510},\boldsymbol{x}_{511},...,\boldsymbol{x}_{519}) (x510,x511,...,x519);如下图所示;以此类推;