
阅读量:1
1 简介
最近一直被大语言模型刷屏。本文是周末技术分享会的提纲,总结了一些自然语言模型相关的重要技术,以及各个主流公司的研究方向和进展,和大家共同学习。
2 Transformer
目前的大模型基本都是Transformer及其变种。本部分将介绍Transformer基础模型及其主要变种。
2.1 Transformer模型
Transformer是一种基于自注意力机制的模型,由Encoder和Decoder两部分组成。
下图是精典论文《Attention is all you need》中展示的模型结构图,左边是Encoder,右边是Decoder,
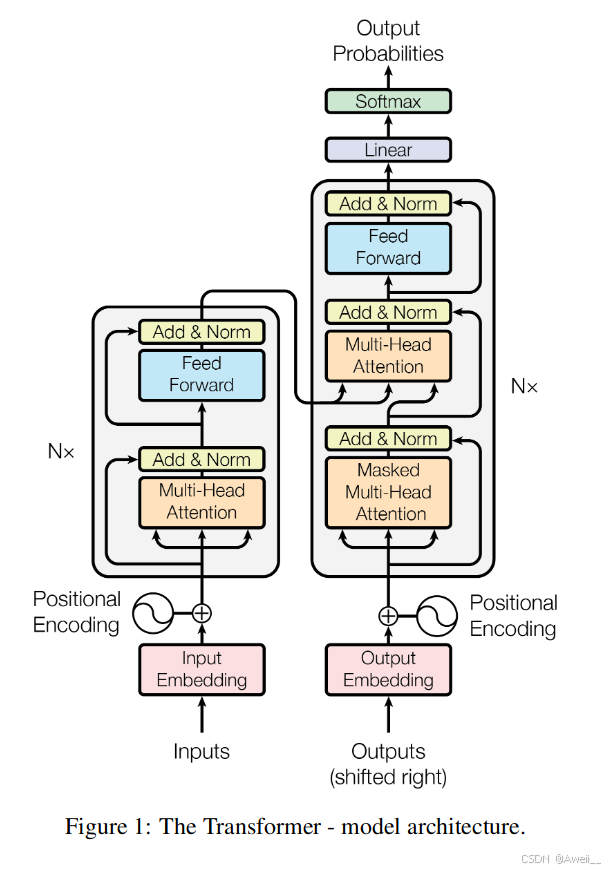
在Transformer中,Encoder将输入序列映射到一个高维空间中,Decoder则将这个高维空间中的向量映射回输出序列。
在Encoder中,所有的词一起输入一起计算;在Decoder中像RNN一样一个一个词输入,将已经出现的词计算得到的Q与Encoder计算得到的K,V进行计算,经过了全部Decoder层再经过FC+Softmax得到结果之后再把结果当做Decoder的输入再走一遍整个流程直到得到END标签。
Transformer既有Encoder又有Decoder,主要因为一开始处理的是翻译任务,需要先理解整句的意思,再逐字生成翻译结果。
Encoder和Decoder的主要区别包括:
- Decoder多包含了一个处理层(编码器-解码器注意力),其接入的是Encoder的输出。
- Decoder下面的是 Masked Attention,它屏蔽了下文,只考虑上文对下文的影响。
简单讲:主要差别就是单向/双向注意力的差别。
论文地址:Attention is All you Need
2.2 自编码
- 常见模型:BERT类模型
- 结构:只有Encoder
- 方法:双向上下文,Mask语言模型
- 场景:编码器产生适合自然语言理解任务的上下文表示,常用于解决阅读理解,完型填空等问题。
- 缺点:不能支持不确定长度文本的生成,而且依赖前后上下文,这样就非常限制下游任务的类型;一般只能在fine-tune后才能在下游任务中使用,这也将涉及大量人工操作和模型调参,模型也不能做得太大。
- 论文地址:BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
2.3 自回归
- 常见模型:GPT-3等模型
- 结构:只有Decoder
- 方法:单向上下文本:从左->右,“一个接一个”生成文本。将解码器自己当前步的输出加入下一步的输入,因此可以生成后续不定长的序列。
- 场景:适用于生成长数据,实现大模型,few-shot任务效果好
- 缺点:单向注意力,使之无法完全捕获 NLU 任务中上下文词之间的依赖关系。可以将其它任务转换成自回归任务,比如:“XXXX电影很好看,这是对/错的”,完型填空题"xxx_yyy,横线上应该填zzz"。这基本就是提示的原理,它让Decoder类模型可以在不fine-tune的情况适应各种类型的下游任务,同时也拥有了BERT的一些优势——虽然不是双向的,但应学习的知识都在前文里。
- 论文地址:Language Models are Few-Shot Learners
2.4 结合Encoder和Decoder
- 常见模型:T5,GLM
- 结构:结合Encoder和Decoder
- 方法:在Encoder中使用双向上下文,Docoder使用单向,在E和D间使用交叉注意力。
- 场景:主要用于有条件的文本生成,比如生成摘要,回答问题
- 缺点:需要更多参数。
2.4.1 T5
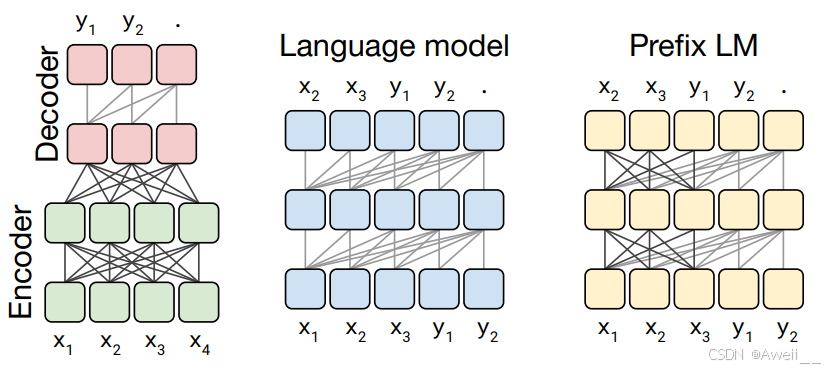
- 第一种方式实现上面提到的翻译功能,只使用其Encoder部分,如BERT。
- 第二种方式是根据上文生成下文,如GPT
- 第三种方式在序列的前缀部分使用完全可见的掩码,如在上面提到的英语到德语的翻译示例中,完全可见的掩码将应用于前缀“translate English to German: That is good.target:”使用因果掩蔽来预测目标“Das ist gut”。(对条件使用双向,对结果使用单向)。
2.4.2 GLM
- 方法 自回归的空白填充
3 模型变迁
- BERT(Devlin et al.,2018)
- GPT-2(Radford et al.,2019)
- MegatronLM(Shoeybi et al.,2019)
- T5(Raffel et al,2019)。
- GPT-3(Brown et al.,2020 年)取得了重大突破
- 开始大模型
- Jurassic-1(Lieber et al.,2021)
- Megatron-Turing NLG 2022)
- Gopher (Rae et al., 2021)
- Chinchilla (Hoffmann et al., 2022)
- PaLM (Chowdhery et al., 2022)
- OPT (Zhang et al., 2022)
- GLM (Zeng et al., 2022)

4 主流大模型
- 思想 & 结构 & 应用(道 术 技)
- 一般称参数大于100B的语言模型为大语言模型。
- 大模型主要用于解决few shot, zero shot问题。
4.1 Google
Google 的几篇文章从模型架构,算法优化,模型规模,应用场景,以及大语言模型指导机器人同步推理;对话场景中的其它应用(搜索、翻译、计算器)结合等方面进行了广泛探索,且基本都是开源的。
4.1.1 T5模型
- 发布时间:2019-06-11
- 解决问题:T5是Transfer Text-to-Text Transformer的简写,它是一种NLP Text-to-Text预训练模型。它的输入是文本,输出也是文本,模型使用迁移学习的技术,使用Transformer架构。其目标是给整个 NLP 预训练模型领域提供了一个通用框架,把所有任务都转化成一种形式。
- 方法:提出了Encoder加Decoder的新结构,结合了BERT和GPT结构的优势。将任务转换成合适的文本输入输出。
- 模型结构:Encoder+Decoder
- 模型和数据规模:包含 3B(Billion)和11B版本,处理后最终生成了750GB的数据集C4,并且在TensorFlow Datasets开放了数据。
- 亮点:模型结构,整体框架
- 论文地址:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
4.1.2 LaMDA
- 发布时间:2022-02-10
- 解决问题:调优对话机器人。提升模型的安全性和事实性,同时可利用外部知识来源,如:信息检索系统、语言翻译器和计算器——结合了自然语言模型与其它工具。
- 方法:利用众包方式,选择人类偏好的回答,利用标注数据finetune模型。
- 模型结构:Decoder结构。
- 数据和模型规模:1.56T 词进行预训练,137B 参数。
- 亮点:结合了自然语言模型和其它工具,功能有点像newbing
- 论文地址:LaMDA: Language Models for Dialog Applications
4.1.3 引导调优
- 发布时间:2022-02-08
- 解决问题:在通过指令描述的一组数据集上微调语言模型,它显著提高了未见任务的 zero-shot 性能。FLAN 的性能相对于LaMDA每个任务平均值提升了10左右。
- 方法:将此类模型称为FLAN(Finetuned Language Net),用 Tensorflow Datasets 上公开可用的 62 个文本数据集,划分为十二种任务,针对每种任务编写模板,用于调优模型。指令调优管道混合了所有数据集并从每个数据集中随机抽样。为了平衡不同大小的数据集,将每个数据集的训练示例数量限制为 30k,并遵循示例比例混合方案。
- 数据结构:同 LaMDA
- 数据和模型规模:预训练同LaMDA,精调使用62个数据集数据。
- 亮点:指令调优,见原理图
- 论文地址:Finetuned Language Models Are Zero-Shot Learners
4.1.4 GLaM
- 发布时间:2022-08-01
- 解决问题:针对节约计算资源的研究,推进了针对细分专家领域的发展。
- 方法:一种混合专家(MoE)模型,可以将其视为具有不同子模型(或专家)的模型,每个子模型都专门针对不同的输入。每层中的专家由门控网络控制,该网络根据输入数据激活专家。每次只激活8%的子网络。
- 模型结构:MoE,Decoder结构。
- 数据和模型规模:最大的 GLaM 有 1200B 参数,大约是 GPT-3 的 7 倍,却仅消耗用于训练 GPT-3 的 1/3 的能量,并且需要一半的计算触发器来进行推理;质量筛选数据对模型训练的影响。过滤后的网页包含 143B 个token,而未过滤的网页包含大约 7T 个token,实验说明有些任务需要高质量数据训练。
- 亮点:模型结构,见模型结构图
- 论文地址:GLaM:Efficient Scaling of Language Models with Mixture-of-Experts
4.1.5 PaLM
- 发布时间:2022-10-05
- 解决问题:作者认为当模型大到一定程度后,其性能也能飞跃,而PathWay技术是其大规模训练的基础。PaLM更关注逻辑推理相关的任务,这也为后面的PaLM-E机器人行为规划奠定了基础。
- 方法:推理链提示和大模型都明显提升了模型的推理能力。
- 模型结构:Decoder结构。
- 数据和模型规模:使用6144 个芯片训练,模型8B/62B/540B参数,780 B高质量token,密集激活。数据基于训练 LaMDA和GLaM的数据,除了自然语言,还包含多种编程语言的源代码。根据文件之间的 Levenshtein 距离删除重复项。
- 亮点:大模型&推理部分&模型解释(6.3 推理,9. 探索解释)
- 论文地址:PaLM: Scaling Language Modeling with Pathways
4.1.6 PaLM-E
- 发布时间:2023-03-06
- 解决问题:通过多模态接入了视频,传感器,将大模型学到的知识应用于机器人领域,进一步解决世界中的交互问题。PaLM-E直接产生动作的计划,从而让机器人自己规划过程。
- 方法:将图像和状态等输入嵌入到与语言标记相同的隐空间中,并由基于Transformer的LLM的自注意力层以与文本相同的方式进行处理,输出可以是问题的答案,或者文本形式生成的、由机器人执行的决策序列。
- 模型结构:Decoder解码器;提出神经网络结构,支持多模态token。模型包含三部分:观测数据编码器,映射器和自然语言模型。
- 数据和模型规模:训练的最大模型有 562B 参数,包含540B语言参数和22B视觉参数。
- 亮点:论文实验部分
- 论文地址:PaLM-E: An Embodied Multimodal Language Model
4.2 Meta(Facebook)
Meta 更偏重于模型的应用场景,在模型规模,减少标注开销,提升质量等方面进行了研究,尤其是其发布的 LLaMA 目前已经成为各个经济适用模型的基础模型,可能很快成为DIY的主流框架。本部分除了 Meta公司的研究,还介绍了两个 LLaMA 的衍生产品。
4.2.1 OPT-175B
- 发布时间:2022-05-03
- 解决问题:超大规模语言模型,该模型是当时第一个模型参数超过千亿级别的开放模型,该模型与GPT-3相比,更加开放及便于访问。
- 方法:训练 125M - 175B 各种大小的模型,经过一系列优化,只使用了GPT-3的1/7的训练资源。这是通过结合Meta的开源完全分片数据并行(FSDP) API和NVIDIA的张量并行抽象在Megetron-LM中实现的。
- 模型结构:Decoder结构。
- 数据和模型规模:175B参数
- 论文地址:OPT: Open Pre-trained Transformer Language Models
4.2.2 Self instruct
- 发布时间:2022-12-20
- 解决问题:对引导精调的优化,之前引导精调主要使用人工处理的数据,数据量和范围都有限,本文通过示范少量引导示例,让模型自己生成引导数据对模型进行优化。经过自引导可使基础模型的GPT-3提升33%,与InstructGPT001差不多的效果。
- 方法:自引导过程是一个迭代自举算法。在第一阶段,模型被提示为新任务生成指令。此步骤利用现有的指令集合来创建更广泛的指令定义任务;然后,在将低质量和重复的指令添加到任务池之前,使用各种措施对其进行修剪;针对许多交互重复此过程,直到生成大量任务。
- 模型结构:Decoder结构。
- 数据和模型规模:以GPT-3作为基础,产生大约 52k 条指令,与大约 82k 实例输入和目标输出配对。
- 亮点:需要更少的人工标注数据
- 论文地址:Self-Instruct: Aligning Language Model with Self Generated Instructions
4.2.3 LLaMA
- 发布时间:2023-02-27(论文发布时间)
- 解决问题:开源项目,以小取胜。使用更多token训练,更少的模型参数。其小模型可以运行在单GPU环境下,65B大模型可与PaLM模型效果竞争。
- 方法:大模型在Few Shot上表现好,主要归功于大模型的参数量。本文至力于找到合适的数据量和参数量,以实现快速推理。调整模型结构,提升训练和预测速度。
- 模型结构:Decoder结构。
- 数据和模型规模:模型从7B-65B参数,使用T级别token训练。在训练 65B 参数模型时,代码在具有 80GB RAM 的 2048 A100 GPU。对包含 1.4T 令牌的数据集进行训练大约需要 21 天。
- 论文地址:LLaMA: Open and Efficient Foundation Language Models
4.2.4 ColossalChat
- 发布时间:2023-02-15
- 解决问题:开源完整 RLHF 训练代码,已开源含7B、13B两种模型。体验最小 demo 训练流程最低仅需 1.62GB 显存,任意单张消费级 GPU 即可满足。
- 方法:以Meta最新开源的LLaMA为基础预训练模型。用于通过完整的RLHF管道克隆ChatGPT。该管道包括监督数据收集、监督微调、奖励模型训练和强化学习微调,基于LLaMA预训练模型。它只需要不到10B个参数,就可以通过RLHF微调在中英文双语能力方面达到与ChatGPT和GPT-3.5相似的效果。
- 模型结构:同 LLaMA
- 数据和模型规模:英双语数据集,训练的英文一共 24M tokens,中文大约 30M tokens,总共约 54M tokens。4bit量化推理70亿参数模型仅需4GB显存。
- 详见:源码地址 24.3K star
4.2.5 Dolly
- 发布时间:2023-03-24(韩国公司)
- 解决问题:Dolly是一个低成本的LLM,它采用LLaMA为基础,是具有60亿参数的开源模型。通过指令精调,使其具有了类似于ChatGPT的交互性。可以自己下载训练,开发成本仅需30美元,且开源。
- 方法:对模型进行细微的修改,以激发服从指令的能力。斯坦福大学基于LLaMA构建了Alpaca,但不同之处在于,它利用一个包含50,000个问题和答案的小数据集进行了微调。即便对一个开源大型语言模型 GPT-J,也能通过30分钟的训练,赋予它神奇的类似ChatGPT的指令跟随能力。
- 模型结构:同 LLaMA
- 数据和模型规模:使用包含50,000个问题和答案的小数据集进行了微调。
- 详见:Dolly 低成本生成式 AI
4.3 OpenAI
OpenAI 的 GPT-4 无疑是目前最好的大语言模型,从GPT到GPT-4一路走来,ChatGPT爆发,可能是我们这个时代最重要的事件之一。可能是为了保持领先,OpenAI 逐渐转换策略,不再公开具体技术,常被讽 CloseAI。
最初坚持使用单向Transformer构造大模型,现在看的确很有眼光,ChatGPT比GPT-3便宜10倍的价值,抢先占领市场,这个策略可能也是合理的。
而AI、语言模型发展到今天,也是互联网数据,软硬件,深度学习,强化学习各个领域近年高速发展和开源的结果。个人认为:无论谁都不太可能一家独大。
4.3.1 GPT-GPT3.5
4.3.2 GPT-4
- 发布时间:2023-03-14
- 解决问题:评测了GPT-4:一个大规模的多模态模型,可以接受图像和文本输入并产生文本输出。提升了利用知识去解决具体问题的能力。对于非常复杂的指令,GPT-4的理解能力和创造力远超3.5。
- 方法:模型训练具体使用了互联网数据和一些三方版权数据。然后使用人类反馈强化学习 (RLHF) 对模型进行微调。
- 模型结构:延续了GPT-3的结构
- 数据和模型规模:报告不包含关于架构(包括模型尺寸)、硬件、训练计算、数据集构建、训练方法或类似的更多细节。
- 亮点:实验结果
- 论文地址:GPT-4 Technical Report
4.4 清华
2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。 它准确性和恶意性指标上与 GPT-3 175B (davinci) 接近或持平。
ChatGLM是GLM公开的单机版本,基本是开包即用,又是中英文双语训练的模型,对中文用户比较友好。
4.4.1 GLM
- 发布时间:2022-01-01
- 解决问题:通过在结构上的调整,结合了GPT和BERT类模型的优点,且模型规模和复杂度没有提升。将NLU任务转换成生成任务训练模型,使上下游任务训练方式保持一致。
- 方法:没有一个预训练框架对自然语言理解 (NLU)、无条件生成和条件生成这三个主要类别的所有任务表现都好。GLM 基于自回归空白填充来解决这一挑战。使用了二维的位置编码,相对于T5模型有更少的参数,差不多的效果。一个模型同时支持NLU和文本生成,所以是多任务的训练。
- 模型结构:GLM基于自回归的空白填充。从输入文本中随机删除连续的token(自编码),并训练模型以顺序重建删除的token(自回归)。
- 数据和模型规模:使用BERT/RoBERT 几种模型大小相同的数据训练模型,以保证对比的公平性。
- 论文地址:GLM: General Language Model Pretraining with Autoregressive Blank Infilling
4.4.2 ChatGLM
- 发布时间:2023-01-01
- 解决问题:开源,并针对中文进行了优化,尤其是可以在自己的机器上搭建其简版的int4服务,实测回答一般性问题效果还不错。
- 方法:ChatGLM是使用中英双语预训练的大语言模型,在稳定性和性能方面进行了调优。在模型结构上结合了GPT和BERT。在英文方面,效果优于GPT-3;在中文方面,优于260B参数的ERNIE TITAN 3.0。可在4×RTX 3090 (24G) 或 8×RTX 2080 Ti (11G) GPUs 环境下运行。
不仅包括自监督的GLM自回归空白填充,还包括对小部分token的多任务学习,以提升其下游zero-shot任务的性能。 - 模型结构:同GLM。
- 数据和模型规模:具有130B参数(1300亿),包括1.2 T英语、1.0 T的中文悟道语料库,以及从网络爬取的250G中文语料库(包括在线论坛、百科全书和QA),形成了平衡的英汉内容构成。
- 亮点:搭建方法
- 论文地址:GLM-130B: AN OPEN BILINGUAL PRE-TRAINED
4.5 DeepMind
DeepMind 围绕提升模型性能展开研究,其研究为后继的模型精减和优化,和更广阔的使用场景奠定了基础。
4.5.1 Gopher
- 发布时间:2021-12-08
- 解决问题:经过实验得出结论:任何学术科目,连同一般知识,通过模型改进模型规模都能提升其效果,但规模对逻辑推理、常识和数学任务的好处较少。
- 方法:DeepMind 训练了 6 个不同大小的模型,从 44M 参数到 280B 参数的 Gopher 模型,进行比较,他们在一组 152 个任务上评估了模型,Gopher 打破了 100 项记录。
- 模型结构:Decoder结构。
- 数据和模型规模:10.5TB语料库上进行训练,280 B参数。
- 论文地址:Scaling Language Models: Methods, Analysis & Insights from Training Gopher
4.5.2 Chinchillla
- 发布时间:2022-03-29
- 解决问题:针对训练数据量,模型参数量,以及数据训练量,得出结论:更长的训练时间,更多token,能提升模型效果;大模型的参数量和性能之间存在幂律分布。
- 方法:在 5 到 5000 亿个标记上训练 400 多个语言模型,范围从 7000 万到超过 160 亿个参数,把参数量和数据规模加入Loss的惩罚。在运算量固定的情况下,如何选择参数和token量的配比,使损失函数最小;它对Gopher的进行调整,将模型大小变为其1/4,token变为其4倍,与Gopher计算量基本一致。
- 模型结构:同Gopher
- 数据和模型规模:10.5TB语料库上进行训练,70B模型参数。
- 论文地址:Training Compute-Optimal Large Language Models
4.6 MicroSoft
本月微软发布的两篇文章(2023年03月),相对偏具体的应用场景,以及语言模型和其它(如图片)数据相结合实现的应用效果,尽管把文本和图本映射到同一嵌入空间;通过调整提示调用ChatGPT和图像修改工具,并不是首次提出,但是实现的效果还是很炫酷有趣的。
4.6.1 Visual ChatGPT
- 发布时间:2023-03-08
- 解决问题:在ChatGPT和图像构建方法间做了桥接,和其它模型相比,除了利用大语言模型中的知识,还利用了ChatGPT强化学习带来的能力,
- 方法:主要对聊天的场景进行优化,在提示上作文章。即:在ChatGPT外边包了一层,这也是当前最常见的用法,文章偏工程化的具体实现。将CoT的潜力扩展到大规模任务,包括但不限于文本生成高清图像、图像到图像的翻译、图像到文本的生成等。
- 模型结构:主要组合调用现有模型,设计了一个Prompt Manager,其中涉及22个不同的虚拟功能矩阵,并定义了它们之间的内部关联,以便更好地交互和组合。
- 数据和模型规模:(OpenAI “text-davinci-003” version)
- 论文地址:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
4.6.2 Kosmos-1
- 发布时间:2023-03-01
- 解决问题:主要研究视觉和文本领域的对齐,具体应用是看图回答问题。KOSMOS - 1是一种多模态语言模型,能够感知通用模态、遵循指令、在语境中学习并产生输出。
- 方法:也没太说具体是怎么做的,主要是提出概念,展示能力。
- 模型结构:包含单模态数据和多模态数据。使用单模态数据进行表示学习。例如,利用文本数据进行语言建模预训练指令跟随、语境学习、各种语言任务等。此外,用跨模态对和交错数据学习将一般模态的感知与语言模型对齐。
- 数据和模型规模:1.3 B的参数。
- 亮点:应用场景:回答图片智力题,直接OCR 备2_论文阅读_Kosmos-1
- 论文地址:Language Is Not All You Need: Aligning Perception with Language Models
4.7 其它大模型
还有一些大语言模型也有着里程碑的意义,比如:MT-NLG 530B,当时首次把模型扩展到 500+B的量级,示范了训练单体超大模型的方法;又如 BLOOM 是一个开放的模型,任何人都可以从Hugging Face网站免费下载它进行研究。它们也常常在其它文章中用作模型对比的基线。
4.7.1 Megatron–Turing NLG(威震天-图灵,MT-NLG 530B)
- 发布时间:2021年10月
- 解决问题:英伟达和微软合作训练模型,示范了训练单体超大模型的方法,
- 方法:4480块A100训练,DeepSpeed & Megatron 三维并行训练技术。DeepSpeed 是一个深度学习优化库,让分布式训练变得简单、高效且有效,Megatron-LM 是由 NVIDIA 的应用深度学习研究团队开发的大型、强大的 transformer 模型框架。
- 模型结构:Decoder结构。
- 数据和模型规模:530 B 参数
- 论文地址:Using DeepSpeed and Megatron to Train Megatron-Turing NLG
530B, A Large-Scale Generative Language Model
4.7.2 BLOOM
- 发布时间:模型的训练于 2022 年 3 月至 7 月期间,耗时约 3.5 个月完成,在2022年11月上传arxiv。
- 解决问题:Hugging Face 联合创始人发起,多方联合,BigScience 的研究人员发布的开源模型。BLOOM最大的特点在于可访问性,任何人都可以从Hugging Face网站免费下载它进行研究。
- 方法:Megatron & DeepSpeed 训练。
- 模型结构:Decoder结构。
- 数据和模型规模: 176 B参数,1.5TB 经过大量去重和清洗的文本,包含 46 种语言,最终转换为 350B token。
- 论文地址:BLOOM: A 176B-Parameter Open-Access Multilingual
Language Model
