
阅读量:4
目录
1.打开google浏览器,点击>扩展程序,点击>访问chrome应用商店
1.CSV (Comma-Separated Values)
背景介绍:
在当今数字化时代,我们被海量信息所包围。数据已成为企业和个人决策过程中不可或缺的资源。无论是市场研究、产品分析、客户洞察还是趋势预测,获取准确和及时的数据是至关重要的。然而,许多有价值的数据散布在互联网的各个角落,以非结构化的形式存在,不易直接使用。这就是Web Scraper发挥作用的地方。
Web Scraper是一个强大的工具,它允许用户自动化地从网页中提取信息。与传统的手动数据收集相比,Web Scraper可以大幅提高数据获取的效率和准确性。它通过模拟人类的浏览行为,访问网页并从中抓取所需的数据,然后将其转换为结构化格式,方便进一步分析和使用。
第一部分:Web Scraper简介
1.什么是Web Scraper:
Web Scraper🛒
是一款专为浏览器设计的插件,它允许用户通过一个直观的图形用户界面(GUI)来创建数据抓取规则,无需编写任何代码。用户可以通过选择网页上的元素来定义抓取点,然后让插件自动地从这些元素中提取数据。Web Scraper支持多种浏览器,包括但不限于Chrome和Firefox,使其可以轻松集成到用户的日常工作流程中。
主要用途:
市场研究:收集竞争对手的价格、产品信息等。
客户洞察:从社交媒体和论坛中提取用户反馈和评论。
内容聚合:自动收集新闻、博客文章或其他在线内容。
数据监控:定期抓取特定网页上的数据变化,用于趋势分析。
个性化数据收集:根据用户需求定制抓取特定数据。
2.为什么选择Web Scraper:
用户友好:Web Scraper提供了一个简单易用的界面,即使是没有编程经验的用户也能快速上手。
无需编码:与需要编写代码的抓取工具相比,Web Scraper允许用户通过选择器直观地定义抓取规则。
实时预览:在定义选择器时,用户可以实时预览抓取结果,确保准确性。
自动化处理:一旦设置完成,Web Scraper可以自动执行抓取任务,减少人工干预。
多页面支持:Web Scraper能够处理分页数据,自动抓取多个页面上的信息。📈
第二部分:安装Web Scraper
1.打开google浏览器,点击>扩展程序,点击>访问chrome应用商店
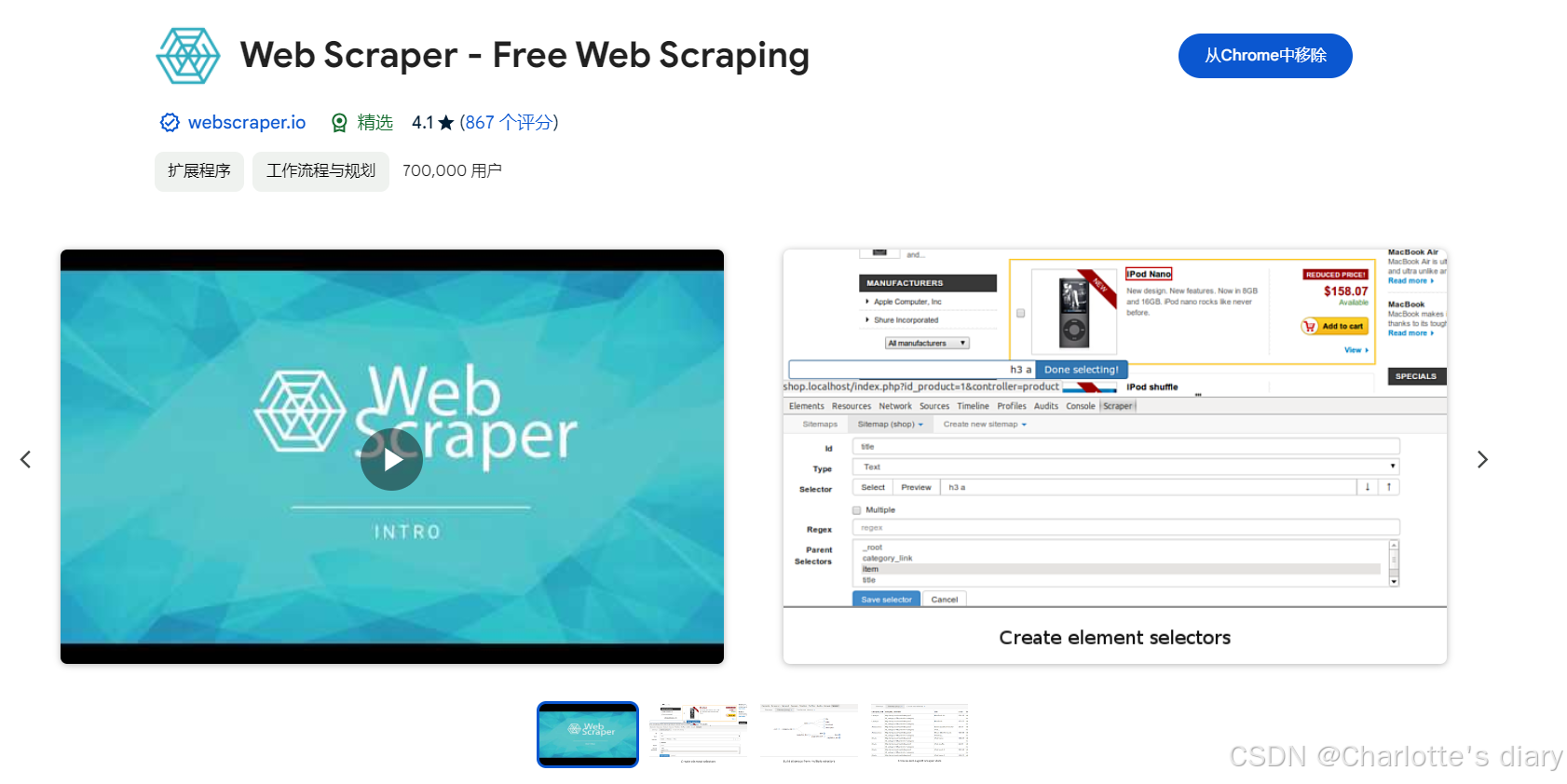
2.搜索web scraper,并下载如下:

第三部分:详细爬取步骤
1.选择目标网站:
我选择的ChinaDaily,可以自己爬取出来当作外刊阅读~~:China Daily Website - Connecting China Connecting the World
进入之后,点击>F12,会显示出 开发者工具(Developer Tools),如下:

然后观察功能,找到最后一个Web Scraper,点击进入:

2.定义选择器:
1.新建一个sitemap:

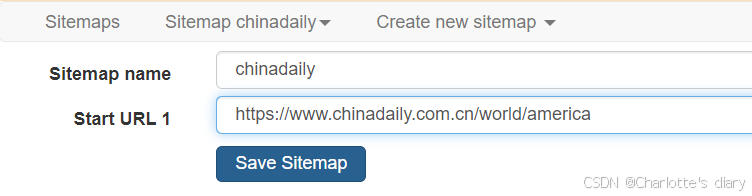
2.命名,输入网址,点击>create sitemap:
我想爬取一点最近的实时,所以选择了美洲,不是在首页哦😊
3.确定并创建一些爬取的内容:
浏览首页,选择一个新闻标题作为数据点,使用Web Scraper的元素选择器工具,点击标题,自动生成选择器。
1.点击chinadaily进入
2.创建选择器,点击selector
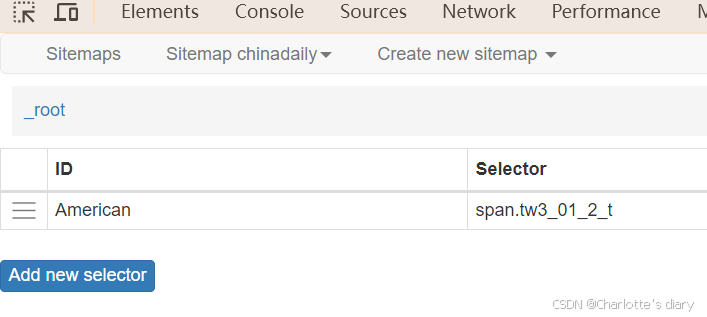
3.选择器创建具体操作:
选择:element,记住要选:mutiple
select的时候,先选第一个,再选相似的第二个,这样就能自动选上所有相似的

4.创建自己想要爬取的东西:
按照自己需求创,一般都是text类型,链接用link,图片用image,别的,,(我也是初学,还不会用 ~ ~ )

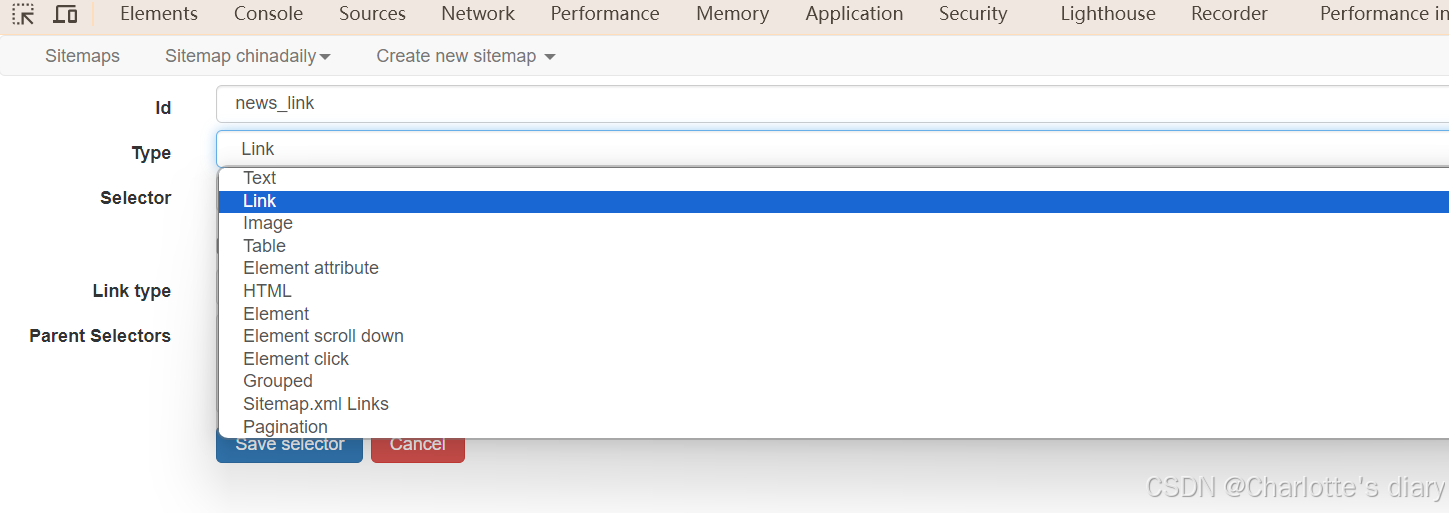
5.爬取具体信息
点击链接进入之后,可以接着创建想要的信息。记得选择link对应的选择器名字

我的是这样子的:

6.开始爬取
点击scrape
 继续点击
继续点击

爬取的时候会有个弹窗,不要管,爬取完了自己就关掉了
点击refresh,就会有下面的数据了

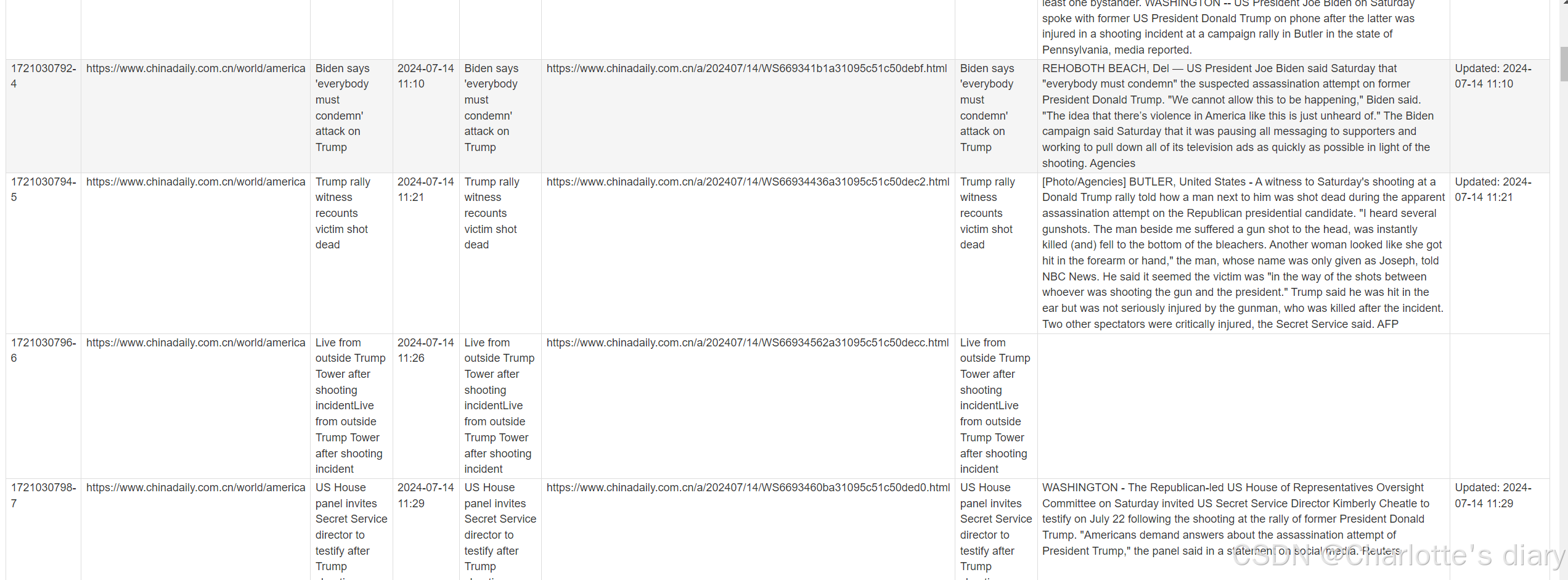
第四部分:数据导出与后续处理
数据导出:
1.CSV (Comma-Separated Values)
用途:CSV是一种广泛使用的数据格式,它以纯文本形式存储表格数据,字段之间用逗号分隔。CSV文件易于使用,可以被大多数电子表格软件(如Microsoft Excel、Google Sheets)和数据库应用程序直接打开和处理。
2.Excel
用途:Excel文件(通常是
.xls或.xlsx格式)是微软的电子表格格式,广泛用于数据的存储、计算和可视化。Excel提供了丰富的数据处理功能,包括公式、图表、数据透视表等。
具体操作:


到这一步,已经成功爬取了新闻,可以当外刊读了~~
