
阅读量:0
你可能不熟悉 ReAct,这是一个旨在增强语言模型 (LLM) 决策能力的尖端框架。
通过使用新的观察结果更新 LLM 的上下文窗口并提示其重新评估信息,ReAct 促进了类似于人类思维过程的推理水平,超越了诸如思维链提示之类的旧技术。
在本文中,我们对 ReAct 进行了定性评估,并使用 Langchain 的代理模块对其进行了测试,以初始化零样本代理来解决信息检索问题。

ReAct in action
以上是论文《ReAct:语言模型中的协同推理和行动》中的一个例子。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、什么是 ReAct?
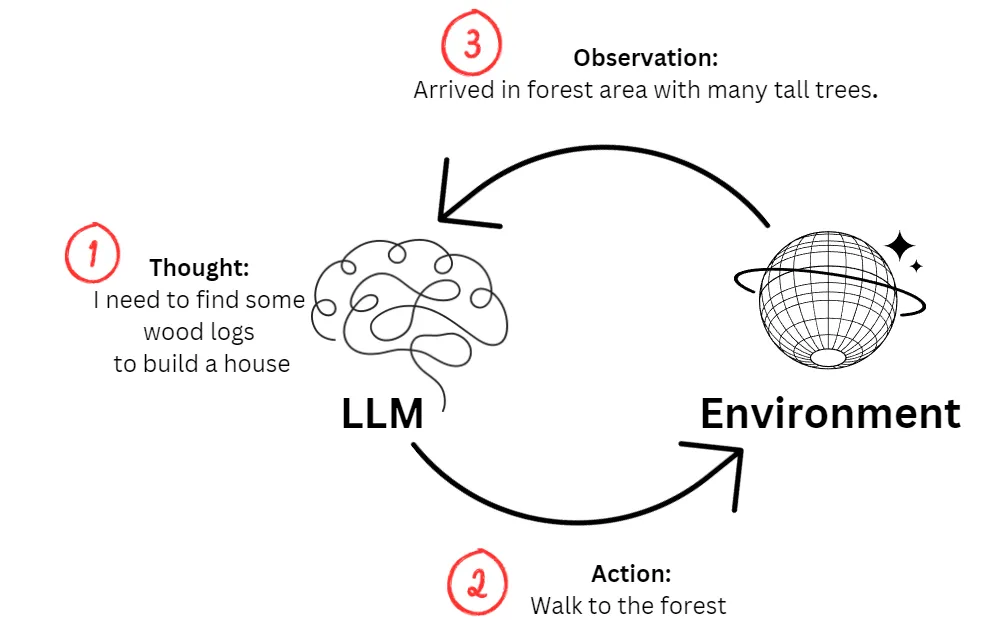
ReAct 模式是Reasoning and Acting(推理和行动)的缩写,是一个将AI模型中的推理过程与行动过程分开的框架。
ReAct 模式的核心是将观察结果提供给 LLM,使其能够更新其上下文窗口。该模型重新评估信息并根据这些见解采取行动以提高其推理能力。这个过程与思维链 (CoT) 提示等技术形成鲜明对比,其中推理步骤嵌入在单个提示中。
ReAct 框架通过提供处理复杂查询的结构化方法来提高 LLM 响应的质量和连贯性。LLM 可以独立分析信息并生成准确反映所提供信息的响应,而不是一次性处理查询。这种方法可以产生更明智和精确的输出。
2、AI 响应链
ReAct 和类似技术的一个关键特性是 AI 响应链(response chaining),而不是依赖于单个 AI 响应。
AI 响应链通过在提示中嵌入顺序步骤来增强 AI 推理,利用神经网络系统来提高组合创造力,从而实现细致入微和创新的响应。
Perplexity AI 是一个值得注意的实现,它根据替代查询聚合搜索结果以最大限度地提高相关性和广度,从而模拟全面的类人搜索过程并有意义地整合各种输入。我们在上一篇关于谷歌 AI 搜索引擎故障的文章中讨论了类似的主题,并将其微不足道的实现与 Perplexity AI 进行了比较。

Where is Google’s AI Search Engine?
开发人员的共同目标是找到一种方法,让 LLM 表现得更智能,减少幻觉,并通过连锁反应,我们可以刺激批判性思维系统。那是什么样子的呢?
3、一个例子
导入库和 API 密钥设置:
!pip install --upgrade openai !pip install --upgrade langchain !pip install --upgrade python-dotenv !pip install google-search-results # import libraries import openai import os from langchain.llms import OpenAI from langchain.agents import load_tools from langchain.agents import initialize_agent from dotenv import load_dotenv load_dotenv() # load API keys; you will need to obtain these if you haven't yet os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY") os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")配置 AI 和 LLM
此示例在实施 ReAct 框架时使用零样本提示(无示例)。这意味着观察和想法仅基于指令,几乎没有或根本没有推理或相关示例来指导 AI。
你可以配置自己的模型,该模型采用少量样本和一些示例来鼓励 AI 以稍微更适合你的任务的方式思考。
llm = OpenAI(model_name="text-davinci-003" ,temperature=0) tools = load_tools(["google-serper", "llm-math"], llm=llm) agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)运行链
执行后,你会注意到代理如何动态搜索和收集信息以提供连贯而详细的响应。
agent.run("What is Asycd and what do they do in the space of AI?")输出:
Entering new AgentExecutor chain... Thought: I need to find out what Asycd is and what they do in the space of AI. Action: Search Action Input: "What is Asycd and what do they do in AI?" Observation: Asycd is a company focused on using AI to revolutionize art creation and user interaction. They leverage AI technologies to provide innovative tools that enhance the creative process and offer personalized user experiences. Thought: I need more details about Asycd's specific activities and platforms related to AI. Action: Search Action Input: "Asycd AI innovations and platforms" Observation: Asycd offers several AI-driven solutions including: An AI-based platform for generating unique art pieces. Tools for artists to collaborate with AI to expand their creative boundaries. User-centric AI applications that personalize and enhance user interactions with art and other creative content. Thought: I now have a comprehensive understanding of Asycd's role in the AI space." Final Answer: Asycd is a company dedicated to transforming art creation through artificial intelligence. They offer a variety of AI-driven solutions such as an AI-based platform for generating unique artwork, collaborative tools for artists to push creative limits with AI, and user-centric applications that tailor and enrich user interactions with creative content. > Finished chain.你可以逐步看到 AI 采取的流程操作:首先在 Google 上搜索用户提出的查询,看看是否可以通过直接搜索 Google 找到答案。
代理评估搜索结果,并有另一个想法,可能类似于“这些结果没有回答用户的查询,但它是一个有用的起点”。它可能会从搜索结果中挑选关键字,并在下一次搜索中使用这些关键字,这将是它的下一步操作。
最终,AI 找到有关 Asycd 的 AI 活动的正确信息,并利用这些信息制定对初始查询的最终响应。
4、替代方案
有几种替代提示框架旨在协调人类和人工智能的决策,类似于 ReAct:
- 思维链 (CoT) 提示:此框架鼓励 LLM 生成逐步推理轨迹或“思维链”以得出最终答案。它有助于使模型的推理过程更加透明和可解释,使其与类似人类的推理保持一致。
- 自一致性提示:这种方法提示 LLM 生成多个可能的解决方案,然后交叉检查它们的一致性,模仿人类如何复查其工作。它可以提高 LLM 输出的可靠性和连贯性。
- 递归奖励建模 (RRM):RRM 训练 LLM 以递归方式建模任务的奖励函数,使模型能够以更符合人类的方式推理任务的目标和约束。
- 辩论:该框架促使 LLM 就给定主题产生多种观点或论点,类似于人类辩论。它可以帮助提出不同的观点和考虑,促进更全面的决策。
- 迭代放大 (IA):IA 涉及通过让 LLM 批评和改进自己的响应来迭代地完善其输出,类似于人类通过自我反思和迭代来完善思维的方式。
- 合作 AI:这种方法涉及促使多个 LLM 协作和共享知识,模仿人类经常合作解决复杂问题的方式。
所有这些技术本质上都是代理性的,仅在提示配置以及 AI 响应的结构上有所不同。
5、结束语
研究 ReAct 非常有价值,它使我们能够探索各种创新方法来提高聊天机器人和人工智能工具的有效性。我们希望你发现这里分享的见解既有信息量又有启发性!
原文链接:ReAct提示框架 - BimAnt
