
阅读量:0
目录
窗口分类
1.按照驱动类型分类
1. 时间窗口(Time window)
时间窗口以时间点定义窗口的开始和结束,因此截取出就是某一段时间的数据。当到达结束时间时窗口不在接受数据,触发计算输出结果,并关闭销毁窗口。
flink有一个专门的类用来表示时间窗口TimeWindow,这个类只有两个私有属性;窗口的方法获取最大时间戳为end-1,因此窗口[start,end) 左开右闭;
@PublicEvolving public class TimeWindow extends Window { private final long start; private final long end; public TimeWindow(long start, long end) { this.start = start; this.end = end; } @Override public long maxTimestamp() { return end - 1; }2.计数窗口(Count window)
计数窗口是基于元素个数截取,在到达固定个数是就触发计算并关闭窗口。
stream.keyBy(data -> true) .window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(2))) // .max() .aggregate(new AvgPv()) .print(); 查看源代码,windou函数后见windowStrream时获取默认的触发器 @PublicEvolving public WindowedStream(KeyedStream<T, K> input, WindowAssigner<? super T, W> windowAssigner) { this.input = input; this.builder = new WindowOperatorBuilder<>( windowAssigner, windowAssigner.getDefaultTrigger(input.getExecutionEnvironment()), //湖区触发器 input.getExecutionConfig(), input.getType(), input.getKeySelector(), input.getKeyType()); } // 计数窗口底层采用全局窗口加计数器来实现 public WindowedStream<T, KEY, GlobalWindow> countWindow(long size) { return window(GlobalWindows.create()).trigger(PurgingTrigger.of(CountTrigger.of(size))); } public WindowedStream<T, KEY, GlobalWindow> countWindow(long size, long slide) { return window(GlobalWindows.create()) .evictor(CountEvictor.of(size)) .trigger(CountTrigger.of(slide)); }2.按照窗口分配数据的规则分类
滚动窗口(Tumbling Window)
窗口大小固定,窗口没有重叠;
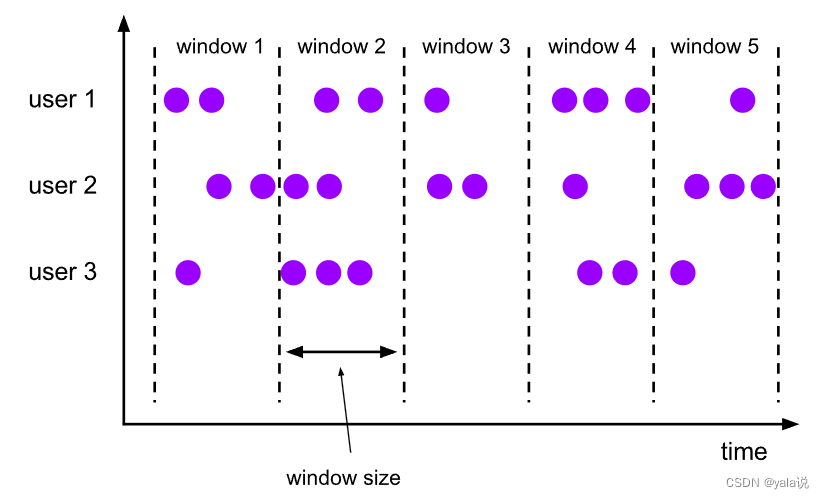
滑动窗口 (Sliding Window)
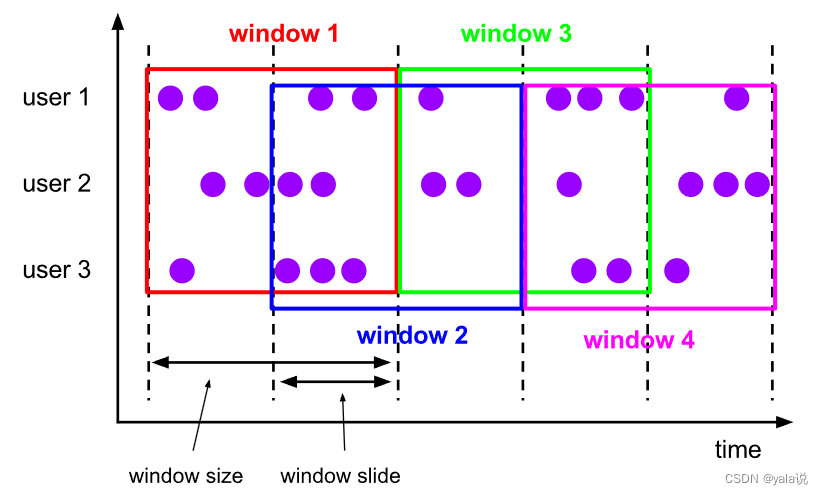
滑动窗口有重叠,也可以没有重叠,如果窗口size和滑动size相等,等于滚动窗口;
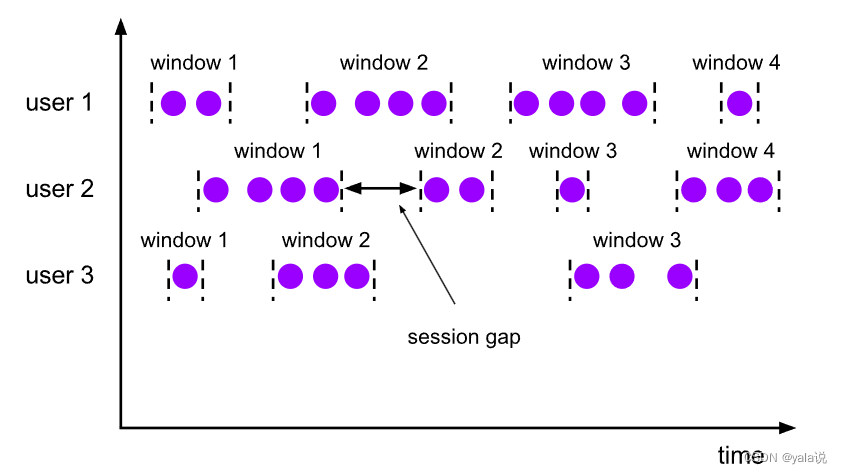
会话窗口 (Session Window)
基于会话对窗口进行分组,与其他两个不同的是,会话窗口是借用会话窗口的超时失效机触发窗口计算,当数据到来后会开启一个窗口,如果在超时时间内有数据陆续到来,窗口不会关闭,反之会关闭;极端情况,如果数据总能在窗口超时时间到达前远远不断的到来,该窗口会一直开启不会关闭;
全局窗口 (Global Window)
比较通用的窗口,该窗口会把数据分配到一个窗口中,窗口为全局有效,会把相同key的数据分配到同一个窗口中,默认不会触发计算,跟没有窗口一样,需要自定义触发器才能使用;
注意:实际使用中windowAll的窗口分配器内部有封装好的定时器,可以直接使用,实现滑动、
滚动窗口和session窗口功能。
@Deprecated public AllWindowedStream<T, TimeWindow> timeWindowAll(Time size, Time slide) { if (environment.getStreamTimeCharacteristic() == TimeCharacteristic.ProcessingTime) { return windowAll(SlidingProcessingTimeWindows.of(size, slide)); } else { return windowAll(SlidingEventTimeWindows.of(size, slide)); } } // 够着函数中有默认构造器 public AllWindowedStream(DataStream<T> input, WindowAssigner<? super T, W> windowAssigner) { this.input = input.keyBy(new NullByteKeySelector<T>()); this.windowAssigner = windowAssigner; this.trigger = windowAssigner.getDefaultTrigger(input.getExecutionEnvironment()); } 窗口API分类
窗口大的分类可以分为按键分区和非按键分区两种:按键分需要经过keyby操作,会把数据进行分发,实现负载均分,可以并行处理更大的数据量。而非按键分区窗口,相当于并行度为1,使用上直接调用windowall(),因此一般并不推荐使用;
stream .keyby(...) //流按键分区 .window(...) //定义窗口分配器 [.trigger()] //设置出发器 [.evictor()] //设置移除器 [.allowedLateness()] // 设置延迟时间 [.sideOutputLateData()] //设置侧输出流 .reduce/aggregate/fold/apply() //处理函数 [.getSideOutput()] //获取侧输出流 stream .windowAll(...) //定义窗口分配器 [.trigger()] //设置出发器 [.evictor()] //设置移除器 [.allowedLateness()] // 设置延迟时间 [.sideOutputLateData()] //设置侧输出流 .reduce/aggregate/fold/apply() //处理函数 [.getSideOutput()] //获取侧输出流API调用
窗口操作包含两个重要的概念:窗口分配器(window Assigners)和窗口函数(window function)两部分;
窗口分配器用于构建窗口,确定窗口类型,确定数据划分哪一个窗口,窗口函数制定数据的计算规则;
窗口分配器器:
作用:窗口分配器用来划分窗口属于哪一个窗口;
窗口按照时间可以划分为:滚动、滑动和session,三种类型窗口;
窗口计数划分:滚动和滑动两种类型;
eventStream.keyBy(data -> data.url) .window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))) .aggregate();窗口函数
窗口函数按照计算特点可以分为增量计算和全量计算; reduce()、aggregate()、apply() 和process(),
增量聚合函数:数据到达后立即计算,窗口只保存中间结果。效率高,性能好,但不够灵活。 reduce()、aggregate();
全量聚合函数:缓存窗口的所有元素,触发后统一计算,效率低,但计算灵活。apply() 和process();
查看原代码发现process()方法地城会调用apply方法
public <R> WindowOperator<K, T, ?, R, W> apply(WindowFunction<T, R, K, W> function) { Preconditions.checkNotNull(function, "WindowFunction cannot be null"); return apply(new InternalIterableWindowFunction<>(function)); } public <R> WindowOperator<K, T, ?, R, W> process(ProcessWindowFunction<T, R, K, W> function) { Preconditions.checkNotNull(function, "ProcessWindowFunction cannot be null"); return apply(new InternalIterableProcessWindowFunction<>(function)); } private <R> WindowOperator<K, T, ?, R, W> apply( InternalWindowFunction<Iterable<T>, R, K, W> function) { if (evictor != null) { return buildEvictingWindowOperator(function); } else { ListStateDescriptor<T> stateDesc = new ListStateDescriptor<>( WINDOW_STATE_NAME, inputType.createSerializer(config)); return buildWindowOperator(stateDesc, function); } }增量聚合函数:
数据进入窗口会参与计算,窗口结束前只需要保留一个聚合后的状态值,内存压力小。
1.规约函数(ReduceFunction):数据保存留一个状态,输入类型和输出类型必须一致,来一条数据会处理将数据合并到状态中;
stream.keyBy(r -> r.f0) // 设置滚动事件时间窗口 .window(TumblingEventTimeWindows.of(Time.seconds(5))) .reduce(new ReduceFunction<Tuple2<String, Long>>() { @Override public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception { // 定义累加规则,窗口闭合时,向下游发送累加结果 return Tuple2.of(value1.f0, value1.f1 + value2.f1); } }) .print();sum、max、min等底层都是通过同名AggregateFunction实现(非下面的聚合函数),本质还是实现ReduceFunction结构重写了reduce方法;
2.聚合函数(AggregateFunction):在规约函数基础上进行完善。解决输出和输入类型必须一致的限制问题。实现应用更灵活;
// 所有数据设置相同的key,发送到同一个分区统计PV和UV,再相除 stream.keyBy(data -> true) .window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(2))) .aggregate(new AvgPv()) .print(); public static class AvgPv implements AggregateFunction<Event, Tuple2<HashSet<String>, Long>, Double> { @Override public Tuple2<HashSet<String>, Long> createAccumulator() { // 创建累加器 return Tuple2.of(new HashSet<String>(), 0L); } @Override public Tuple2<HashSet<String>, Long> add(Event value, Tuple2<HashSet<String>, Long> accumulator) { // 属于本窗口的数据来一条累加一次,并返回累加器 accumulator.f0.add(value.user); return Tuple2.of(accumulator.f0, accumulator.f1 + 1L); } @Override public Double getResult(Tuple2<HashSet<String>, Long> accumulator) { // 窗口闭合时,增量聚合结束,将计算结果发送到下游 return (double) accumulator.f1 / accumulator.f0.size(); } @Override public Tuple2<HashSet<String>, Long> merge(Tuple2<HashSet<String>, Long> a, Tuple2<HashSet<String>, Long> b) { return null; } }全量窗口函数
全窗口函数会将进入窗口的数据先进行缓存,然后在窗口关闭时一起计算,缓存数据会占用内存资源,如果一个窗口数据量太大时,可能出现内存溢出的问题;
全窗口函数可以划分窗口函数(windowFunction)和处理窗口函数(processWindowFunction)两种;
窗口函数(windowFunction):老版本通用窗口接口,window()后调用apply(),传入实现windowFunction接口; 缺点是不能获取上下文信息,也没有更高级的功能。因为在功能上可以被processWindowFunction全覆盖,因此慢慢会被弃用;
区别
windowFunction是接口继承Function函数,功能比较原始单一,无法获取上线文信息。
processWindowFunction是抽象类,继承抽象富函数,功能比较丰富,可以获取上下文等信息。
public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window> extends AbstractRichFunction
public interface WindowFunction<IN, OUT, KEY, W extends Window> extends Function, Serializable
DataStream<Tuple2<String, Long>> input = ...; input .keyBy(<key selector>) .window(<window assigner>) .apply(new MyWindowFunction()); @Public public interface WindowFunction<IN, OUT, KEY, W extends Window> extends Function, Serializable { /** * Evaluates the window and outputs none or several elements. * * @param key The key for which this window is evaluated. * @param window The window that is being evaluated. * @param input The elements in the window being evaluated. * @param out A collector for emitting elements. * @throws Exception The function may throw exceptions to fail the program and trigger recovery. */ void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out) throws Exception; }处理窗口函数(processWindowFunction):是窗口API中最底层通用的窗口函数接口,可以获取到上问对象(context),实现为调用process方法传入自定义继承ProcessWindowFunction类;
input .keyBy(t -> t.f0) .window(TumblingEventTimeWindows.of(Time.minutes(5))) .process(new MyProcessWindowFunction()); /* ... */ public class MyProcessWindowFunction extends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> { @Override public void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) { long count = 0; for (Tuple2<String, Long> in: input) { count++; } out.collect("Window: " + context.window() + "count: " + count); } }注意:一般增量窗口函数和全量窗口函数可以一起使用,window().aggregate()方法可以传入两个函数,第一个采用增量聚合函数,第二个传入全量函数,这样数据在进入窗口会触发增量计算,窗口不会缓存数据。当窗口关闭触发计算时,结果数据穿度到全量计算,参数Iterable中一般只有一个数据;
aggregate(acct1,acct2)
flink sql 窗口函数
flink sql 窗口也包含常见的滚动窗口、滑动窗口、session窗口,但还有一种累计窗口。
在flink1.13版本后flinksql支持累计窗口CUMULATE,可以实现没5分钟触发一次计算,输出当天的累计数据,使用样例
SELECT cast(PROCTIME() as timestamp_ltz) as window_end_time, manufacturer_name, event_id, case when state is null then -1 else state end , cast(sum(agg)as string ) as agg FROM TABLE(CUMULATE( TABLE dm_cumulate , DESCRIPTOR(ts1) , INTERVAL '5' MINUTES , INTERVAL '1' DAY(9))) GROUP BY window_end ,window_start ,manufacturer_name ,event_id ,case when state is null then -1 else state end 