阅读量:3
【AI大模型】如何让大模型变得更聪明
前言
在以前,AI和大模型实际上界限较为清晰。但是随着人工智能技术的不断发展,基于大规模预训练模型的应用在基于AI人工智能的技术支持和帮助上,多个领域展现出了前所未有的能力。无论是自然语言处理、计算机视觉,还是语音识别,甚至是自动驾驶,AI模型的性能都取得了显著进步。然而,尽管大模型已经表现出令人惊叹的能力,它们在理解力、泛化能力和适应性等方面仍然面临挑战。有时候依旧还是会出现指鹿为马、画蛇添足、罢工不干的失误性行为。**那么在这个AI大时代,怎么才能让大模型变得更聪明呢?**本文将会给各位进行具体的介绍。
文章目录
一、大模型的现状与挑战
首先,我们需要知道大模型“不够聪明”的原因。
1.1 理解力的局限
大模型在特定任务上表现优异,但它们对于复杂问题和原理性问题的解答仍然有着理解力和想象力的局限。对于复杂的多轮对话,模型往往难以保持上下文一致性,容易出现语义理解偏差;而对于较为深层次的原理性问题,它可能会出现胡言乱语,也就是说大模型生成的内容在表面上看起来是合理的、有逻辑的,甚至可能与真实信息交织在一起, 但实际上却存在错误的内容、引用来源或陈述。这就是所谓“大模型幻觉”。
比如ChatGPT3.5大模型,当我问它“1+1为什么=2”时,它首先会这么说:

而当我继续追问它时:
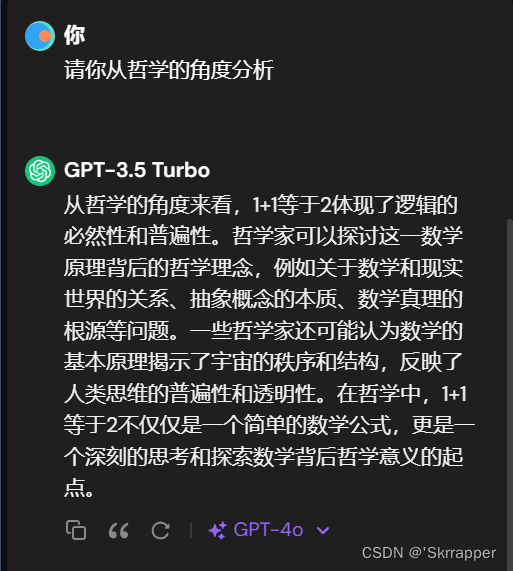
我们仔细分析一下:从哲学角度来看,
一加一等于二这个问题当然体现了逻辑的必然性和普遍性。但是我们发现,一加二等于三也体现了逻辑的必然性和普遍性。这说明——GPT似乎在规避这个问题的本质,它并没有认识到一加一等于二这个问题的特殊性和单一性,它将其归类为普遍性问题去看待,而不是从最原始的角度求分析。并且针对它后续所说:”哲学家可以…“、”在哲学中,1+1等于2不仅仅…“,仔细看这些话术,它实际上并不是在回答我的问题,而是在告诉我别
人是如何回答这个问题的。这里已经脱离了问题的本质。
实际上,自然语言处理大模型只是为了表现得像人,但它并不能跟人一样。
1.2 泛化能力的不足
大模型在训练数据上的表现通常非常出色,但在面对未见过的数据时,其泛化能力仍有待提高。特别是当数据分布发生变化时,模型的性能可能会显著下降。
1.3 适应性的挑战
随着环境和需求的变化,AI模型需要不断适应新的任务和场景。然而,大模型的训练和微调过程通常耗时耗力,这使得模型的适应性成为一大挑战。大型公司在训练他们自己的大模型时,往往动用大量的人力和物力来进行训练,这基于他们庞大的公司运转机制;但是对于小型公司和个人来说,大模型的训练往往是极其吃力的一件事。而当训练效果不佳时,大模型就会变得迟钝和不够聪明——毕竟,时代瞬息万变,大模型也是以时代为背景的。
二、怎么让大模型变聪明呢?
在介绍了现如今大模型陷入的挑战之后,我们该如何让大模型变得聪明呢?以下是具体方案和python的代码实现。
2.1 增强数据多样性和质量
2.1.1 数据增强技术
数据增强是一种通过对训练数据进行各种变换来生成新的数据样本的方法,可以有效提高模型的泛化能力。例如,在图像处理中,可以通过旋转、平移、缩放等操作来增强数据。在自然语言处理中,可以使用同义词替换、随机插入、删除等方法来扩展语料库。
下面示例展示了如何使用同义词替换进行数据增强,从而提高自然语言处理模型的泛化能力。
import random from nltk.corpus import wordnet def synonym_replacement(sentence, n): """ 使用同义词替换句子中的单词来进行数据增强。 参数: sentence (str): 输入的句子。 n (int): 要替换的单词数量。 返回: str: 经过同义词替换后的句子。 """ words = sentence.split() # 将句子拆分成单词列表 new_words = words.copy() # 复制一份新词列表 # 选择句子中有同义词的单词,并随机打乱顺序 random_word_list = list(set([word for word in words if wordnet.synsets(word)])) random.shuffle(random_word_list) num_replaced = 0 # 初始化替换计数 for random_word in random_word_list: synonyms = wordnet.synsets(random_word) # 获取该单词的所有同义词 if len(synonyms) > 0: synonym = random.choice(synonyms).lemmas()[0].name() # 随机选择一个同义词 # 用选择的同义词替换句子中的该单词 new_words = [synonym if word == random_word else word for word in new_words] num_replaced += 1 # 更新替换计数 if num_replaced >= n: # 如果达到替换数量,停止替换 break return ' '.join(new_words) # 返回替换后的句子 sentence = "The quick brown fox jumps over the lazy dog" augmented_sentence = synonym_replacement(sentence, 2) # 进行同义词替换 print(augmented_sentence) # 输出替换后的句子 2.1.2 高质量数据集的构建
除了数据增强**,构建高质量的数据集**同样至关重要。高质量的数据不仅包含丰富的信息,还需要准确标注。为了构建这样的数据集,可以采用专家标注、众包标注和自动标注相结合的方法。
2.2 模型结构优化
2.2.1 多任务学习
多任务学习(Multi-Task Learning, MTL)通过同时学习多个相关任务的知识,可以提高模型的泛化能力和理解力。例如,在自然语言处理领域,可以同时训练语言模型、问答系统和文本分类器,从而共享知识,提高整体性能。
这个示例展示了如何使用预训练的BERT模型进行多任务学习,包括掩码语言模型任务和下一句预测任务。
from transformers import BertTokenizer, BertModel import torch # 加载BERT的分词器和模型 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased') # 对输入句子进行编码 input_ids = tokenizer("The quick brown fox jumps over the lazy dog", return_tensors="pt")["input_ids"] # 创建掩码标签 labels = tokenizer("The quick brown fox [MASK] over the lazy dog", return_tensors="pt")["input_ids"] # 前向传播,计算损失和logits outputs = model(input_ids, labels=labels) loss = outputs.loss logits = outputs.logits print(f"Loss: {loss.item()}") # 输出损失值 2.2.2 模型架构创新
近年来,Transformer架构取得了巨大成功,但仍有优化空间。例如,增强注意力机制、设计更深层次的网络、引入图神经网络(Graph Neural Networks, GNN)等,都可以进一步提升模型性能。
这个示例展示了如何使用图卷积网络(GCN)来进行图结构数据的分类任务。
import torch import torch.nn.functional as F from torch_geometric.nn import GCNConv from torch_geometric.data import Data # 定义图卷积网络模型 class GCN(torch.nn.Module): def __init__(self, num_node_features, num_classes): super(GCN, self).__init__() self.conv1 = GCNConv(num_node_features, 16) # 第一层图卷积 self.conv2 = GCNConv(16, num_classes) # 第二层图卷积 def forward(self, data): x, edge_index = data.x, data.edge_index x = self.conv1(x, edge_index) # 进行第一次卷积 x = F.relu(x) # 应用ReLU激活函数 x = self.conv2(x, edge_index) # 进行第二次卷积 return F.log_softmax(x, dim=1) # 输出分类结果 # 生成示例数据 num_nodes = 100 num_node_features = 3 num_classes = 2 x = torch.randn((num_nodes, num_node_features)) # 随机生成节点特征 edge_index = torch.randint(0, num_nodes, (2, num_nodes*2)) # 随机生成边索引 y = torch.randint(0, num_classes, (num_nodes,)) # 随机生成节点标签 data = Data(x=x, edge_index=edge_index, y=y) # 构建图数据对象 model = GCN(num_node_features, num_classes) # 初始化GCN模型 output = model(data) # 前向传播,获得输出 print(output) # 打印输出结果 2.3 强化学习与自适应学习
2.3.1 强化学习(Reinforcement Learning, RL)
强化学习通过奖励机制引导模型逐步改进,可以有效提升模型的适应性。将强化学习应用于自然语言处理、机器人控制等领域,能够显著提升模型在复杂环境中的表现。
这个示例展示了如何使用OpenAI Gym环境进行强化学习训练。以经典的 CartPole 环境为例。
import gym # 创建CartPole环境 env = gym.make('CartPole-v1') observation = env.reset() for _ in range(1000): env.render() # 渲染环境 action = env.action_space.sample() # 随机选择一个动作 observation, reward, done, info = env.step(action) # 执行动作 if done: observation = env.reset() # 重置环境 env.close() 2.3.2 自适应学习(Adaptive Learning)
自适应学习通过实时调整模型参数,使其更好地适应新环境和任务。(同时自适应学习(Adaptive Learning)也是指一种利用实时数据和反馈来动态调整教学内容和学习路径的教育技术方法,以满足每个学习者的个性化需求。)通过分析大模型的学习行为、针对方向和应用点,自动调整训练策略,从而达到自适应学习的结果,AI可以自己朝着具体的方向进行深入学习,从而形成更大的数据库。

2.4 融合外部知识和常识推理
2.4.1 知识图谱(Knowledge Graphs)
知识图谱通过结构化的知识表示,可以为大模型提供丰富的背景信息,增强其理解力和推理能力。在自然语言处理任务中,结合知识图谱可以显著提高模型的表现。
from py2neo import Graph # 连接到Neo4j数据库 # "bolt://localhost:7687" 是Neo4j数据库的Bolt协议URL # auth=("neo4j", "password") 是Neo4j数据库的认证信息,用户名是 "neo4j",密码是 "password" graph = Graph("bolt://localhost:7687", auth=("neo4j", "password")) # 定义一个Cypher查询 # 这个查询匹配具有Person标签的节点之间的KNOWS关系 # 并返回这些Person节点的名称 query = """ MATCH (n:Person)-[r:KNOWS]->(m:Person) RETURN n.name AS name1, m.name AS name2 """ # 执行查询并获得结果 results = graph.run(query) # 遍历查询结果,逐行打印每对名字 # record["name1"] 和 record["name2"] 分别表示KNOWS关系的两端节点的名称 for record in results: print(record["name1"], "knows", record["name2"]) 2.5 模型压缩与高效推理
2.5.1 模型蒸馏(Model Distillation)
模型蒸馏通过将大模型的知识迁移到小模型中,能够在保持性能的同时,显著减少计算资源的消耗。
2.5.2 量化(Quantization)
量化技术通过降低模型参数的精度,可以显著减少存储和计算成本,同时对模型性能影响较小。
import torch from torch.quantization import quantize_dynamic model = torch.nn.Linear(5, 10) quantized_model = quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8) 三、展望未来的大模型学习
看待如今的大模型,我们彷佛是在看着自己的孩子,从初出茅庐,牙牙学语,到学会思考,学会说话,这个过程有趣并且具有意义。
“在大模型技术高速发展的时代,一个重要的趋势是:我们每一个人,除非你有独特的见解、独特的认知、独特的问题解决能力,否则你能做的,大模型都可以做到。”在实际的大模型当中,想要使其做得更加“像人”,就必须不能停止它的学习。基于不断变化的时代背景下,大模型要学习的东西是源源不断的,永不停息的。所以,当我们看待如何让大模型变得更聪明这个课题的同时,也要认识到时代的延展性,而人的行为也是如此,只有不断学习,跟进时代,才能不被淘汰,增进知识——从另一个角度来看,这不也正是大模型为了“像人”而努力的一个点吗?