
阅读量:0

父子进程
一个进程可以创建另一个进程吗?

干想代码可能很犹豫,因为我们从来都没有见过创建新进程的代码。但是:
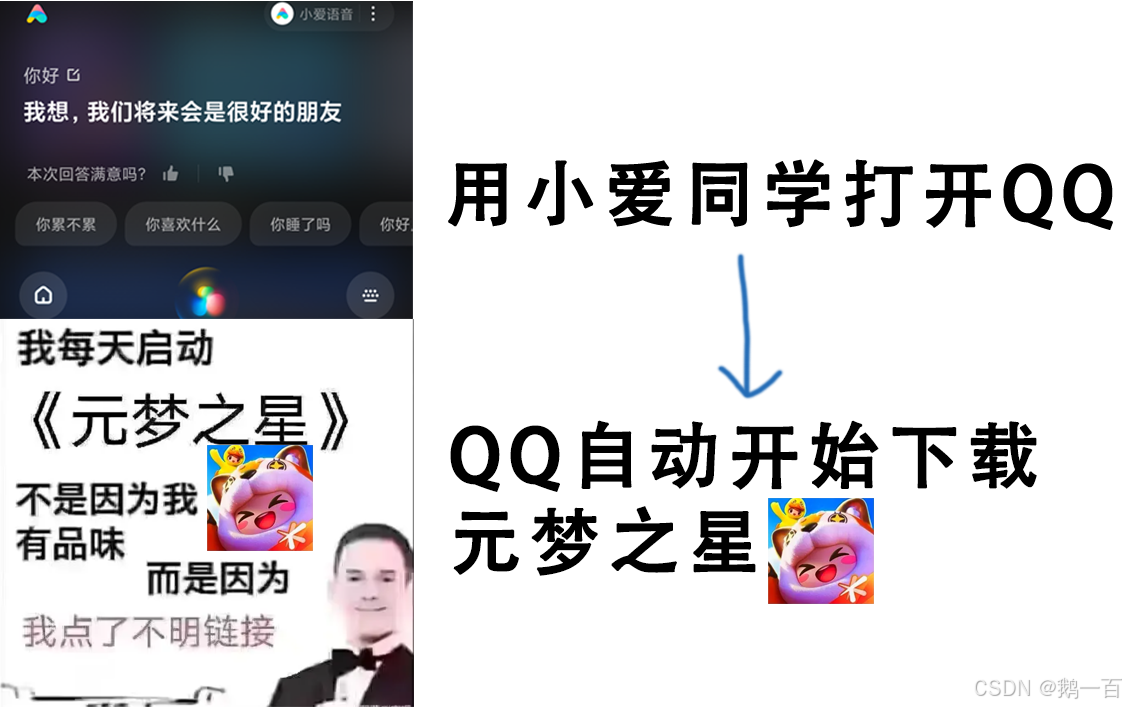
短短几秒钟,就创建了两个进程。这些进程是系统创建的吗?不是。一个是小爱同学创建的,另一个则是QQ创建的。所以,一个进程是完全拥有创建另一个进程的能力的。
就像你和你的室友们一样,被创建的进程就叫做子进程,另一个就叫做父进程。
创建父子进程
但是,小爱同学和QQ也是代码写出来的,那怎么用代码去创建一个进程呢?很简单的一个函数
fork()
不过,使用fork的代码就很反人类了:
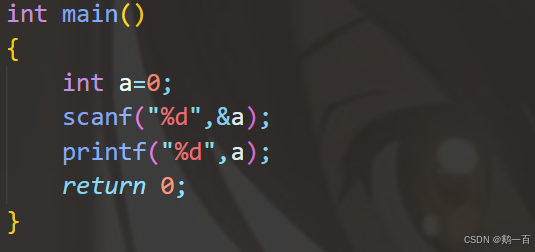
int main() { int pid = fork(); if(pid==0) { printf("this process:%d\n",pid); } else { printf("And this process:%d\n",pid); } return 0; }很简单啊,判断pid的值,不管是不是0,最后都输出自己的pid,无非就是输出pid前的语句不同罢了。
可是结果:
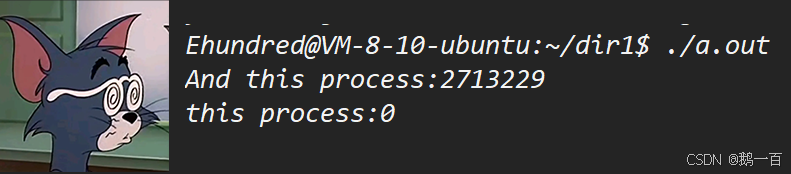
嗯?怎么会输出两条语句?
而且两个输出的pid还不一样?
中途没有任何语句去改变pid的值,而且就算改变了,一个程序运行时,可能同时进入if和else两条路吗?不可能,除非这个入开桂了。
此时,我们再来想想这个函数的功能:创建一个子进程。那么,只剩下一种可能: 
那我们就以这个假设来看这段代码。
因为整段代码,只有在fork处改变了pid的值,所以肯定是fork对pid发生了不同的改变。对两个不同的进程,会分别给他们返回不同的值0或非0,然后把两个值分别赋值给不同进程中的pid,继续向后运行。此时,进入if和else的判断,因为pid的值是0或非0,所以输出了不同的结果。完美!
但是,又会产生很多问题:
- fork返回值的具体含义是什么?为什么要返回0或非0?
- 我们怎么判断谁是父进程?谁是子进程?重要吗?
- 子进程凭什么可以进入到if/else的判断里?
别急,我们来一个一个分析:
fork
fork返回值的含义是什么?
一句话总结:fork返回值的具体含义,就是某个进程的pid。
pid的全程,process id,就和你元神的uid一样,只是为了可以找到你。这个在进程中有讲过,不理解的可以去看看:Linux进程与运行-CSDN博客
更具体的说,fork返回的是子进程的pid。父进程创建子进程,就把创建出的子进程pid给他。但是子进程刚被创建出来,还没有创建进程,他没有子进程,怎么办?因为进程的计数是从1开始的,1是第一个被创建出来的进程,也就是操作系统。那我就返回一个0,就如同返回一个null一样,代表没有子进程。于是,fork函数的返回值就明了了:
- 给父进程返回刚被创建的子进程的pid
- 给子进程返回0
但是,你怎么证明给父进程返回的,就是子进程的pid?
很简单一个指令:ps

ps,简单说就是任务管理器,可以查看所有进程和其pid
同时,在代码内,也有相应的函数:getpid()和getppid()
- getpid(),就是获取当前进程的pid
- getppid(),就是获取当前进程的父进程pid,ppid(parent pid)
所以,我们再把刚刚的代码稍微改一下:
int main() { int pid = fork(); if(pid==0) { printf("I'm child,my id:%d\n",getpid()); printf("my child id:%d\n",pid); printf("my parent id:%d\n\n",getppid()); } else { sleep(1);//为了防止输出串行,让父进程后运行 printf("I'm parent,my id:%d\n",getpid()); printf("my child id:%d\n",pid); printf("my parent id:%d\n\n",getppid()); } return 0; } 很容易发现父子关系。
很容易发现父子关系。
而且,因为子进程没有孩子,所以孩子pid为0;父进程是另外一个进程创建的,所以给的是创建父进程的进程pid。
OK,那么第一个问题便解决了:
怎么判断父子进程?
其实在上一个问题中,就已经解决了怎么判断父子进程:getpid和getppid。那么,这里重点讲一下第二个问题:
判断谁是父子进程,重要吗?
废话,当然重要。我们先不管具体怎么实现,我们只先来思考一下这些概念:
首先,我们为什么要去创建一个子进程?因为是为了让他完成某些任务。那我们怎么知道这个任务完成地怎么样?子进程去告诉父进程。所以,子进程一定要可以找到父进程,父进程也一定要能找到子进程。
其次,如果子进程在完成之前,父进程意外终止了,那子进程的结果和状态,应该给谁呢?只能给其他相关的进程,让能处理这些东西给父进程擦屁股的进程,去处理这些事情。所以,其他进程也必须要找到子进程,而且知道,这个子进程是失去父亲的进程。
这种父子关系是非常重要的。
不过,这也说明了一个问题:
父进程一直在偷窥自己的子进程,等到子进程运行完了,直接冲过去拿结果。但是,父进程难道是去看子进程运行到哪一行了吗?不现实,因为父进程也要有自己的事,要是一直去盯着子进程,那父进程就不叫父亲而叫监工了。为了方便和高效,所以直接用一个状态来表示,子进程在运行的时候,就把状态设置成为running,而在进程结束的同时,把状态的running调整为finish。
父进程偷窥的时候,只用看一眼子进程的状态,如果是running,哦,我的孩子正在运行,那我就不管了;但是,一旦发现是finish,那我就直接冲过去拿结果,极大提高了父进程的效率。
而这些,会涉及到两个问题:进程等待和进程状态。在讲完第三个问题“子进程的运行”时,我们再回来解决这两个问题。
子进程是怎么运行的
子进程凭什么可以进入到if/else的判断里?
或者换句话说,子进程被创建之后,他运行的是什么代码?
首先,父子进程是不可能同时运行同一段代码的,因为会涉及到一个概念——
进程的独立性:不同的进程是无法看到其他进程里的数据的。
进程的独立性
对每一个进程,都有一个进程PCB,PCB里存储着两个重要的东西:
struct PCB { Data* data;//数据段地址,比如上下文等 Code* code;//代码段地址,运行时的代码 //还有其他数据 };在程序被新创建的时候,PCB被放入内存中,操作系统再根据PCB,找到对应的代码和数据,将代码和数据放入内存。而在这个过程中,是没有任何其他进程插手的。换句话说,任何进程就算是父进程,对一个其他的进程,也只有获得其PCB的能力,而无法查看其中的代码和数据。
进程就像紧锁的房间,你只能从门卡上获取房间的基本信息,但是里面居住的人,里面的设施,只有房间的主人才知道,其他人没有任何办法看到。
那父进程获取子进程的消息,既然只能看到PCB,那怎么可能获得到消息呢?
答案很简单:中间渠道。

当子进程完成的时候,我不让父进程进到我房间里去,我放一张纸条在门口,父进程发现门口有张纸条,就只将纸条拿回到父进程的房间,这样父子进程在没有进出相互房间的情况下,进行了信息的交流,而这张纸条,就是实现的中间渠道。
同时,为了保证这张纸条不被其他进程拿走,或者不被操作系统打扫走,这张纸条的位置肯定要被单独保管起来,也就是操作系统给他分配一块空间,专门用于两个进程之间的交流。
进程的独立性,总结便是,每一个进程都是绝对封闭的,任何进程都无法查看其他进程的代码和数据,而进程间需要交换数据,则必须通过中间媒介来间接交换。
所以,子进程是看不到父进程的代码的,自然就无法和父进程运行同一块代码。不过,虽然我看不见,那我就不能把代码复制过来,变成自己的代码吗? 
当子进程被创建的时候,PCB还在形成。这个时候,PCB中的数据段地址和代码段地址都是空的,但是我们想让子进程接着父进程运行,于是我们把父进程数据段和代码段的地址全部赋值给子进程,因为只是两个地址的复制,所以要的时间几乎为0。
复制之后,子进程和父进程分裂开来,两个进程保持着独立性,但是因为子进程已经把父进程的代码段和数据段地址复制来了,可以直接访问到代码段和数据段。此时就算我看不到父进程的数据,我也有着自己复制来的数据,可以自己独立运行,这就是子进程创建的过程。
所以,子进程是怎么运行的?在fork处分裂开来,子进程复制父进程所有的代码和数据,两个进程根据自己独立的数据运行下去,互补干扰。
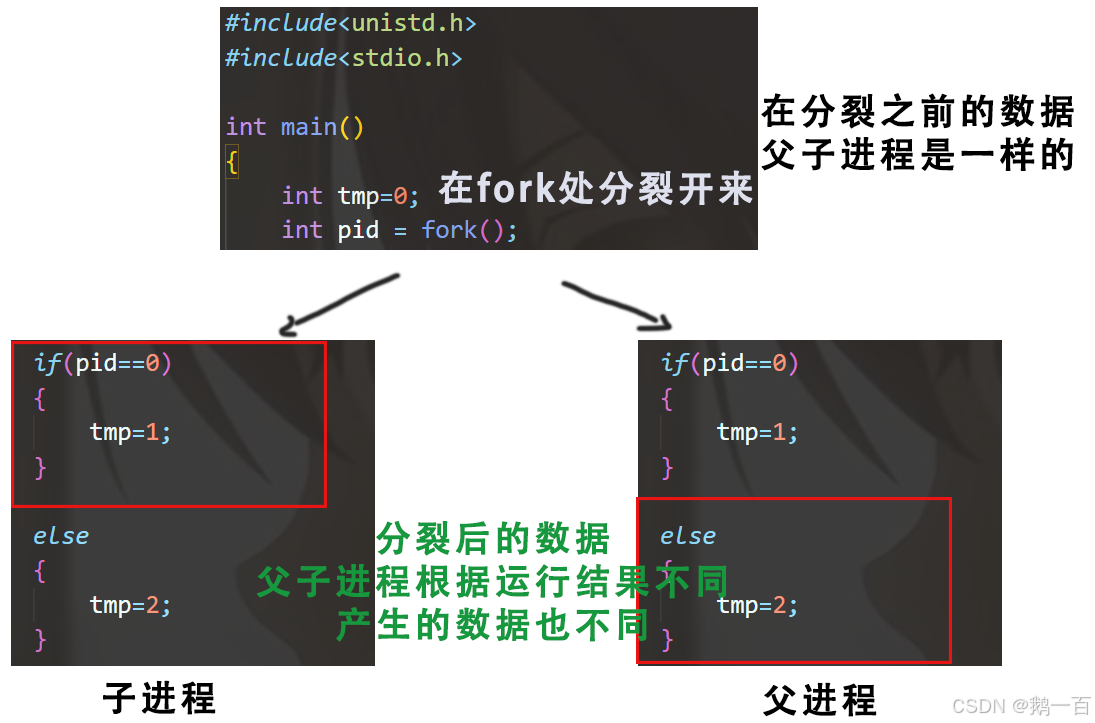
以下面一段代码为例:
#include<unistd.h> #include<stdio.h> int main() { int tmp=0; int pid = fork(); if(pid==0) { tmp=1; } else { tmp=2; } return 0; }
进程状态
在一般的教材里,进程一般都会有一个状态转换图:
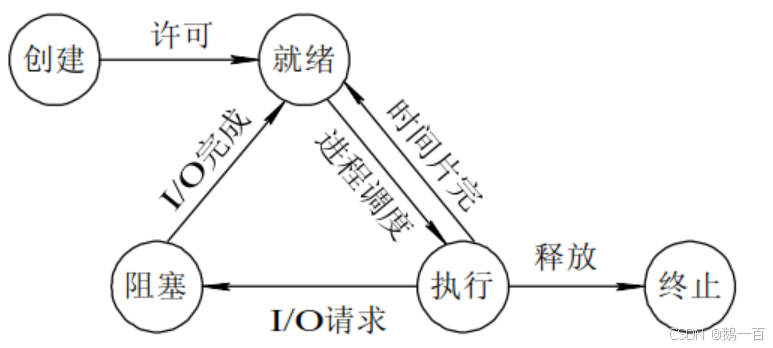
对硬件层的理解,这个图是完美的时间片逻辑:
在一个cpu上,进程是不可能占着cpu不走的,所以每隔一段时间,cpu就要从进程之间切换,由一个进程切换到另一个进程。但是,被切换走的进程并不是不能继续运行了,而是被强迫剥离走,它还想被继续运行下去,它就要在运行队列里继续排队,等到下一次被调度。在运行的时候,就是执行状态,而在运行队列里排队的时候,就是就绪状态。
但是,并非每个进程都是一直在等待着被调度的。有些进程缺少了运行的必要条件,比如:
在没有输入的时候,进程会一直卡在scanf那里,这便是进程缺少了继续运行的必要条件。这个时候,就算调度了它把它放在了cpu上,它也只能像人机一样发呆,纯纯浪费资源。为了避免这种事情发生,我们单独用一种状态表示他,当cpu看到这个状态时,明白他不能继续运行,所以直接跳过他,而这种状态,就叫做阻塞。
很完美是不是?但是这只是硬件层的理解,说人话便是给cpu看的状态。而给进程和操作系统看的状态,与之大不一样,就像:

在Linux中,有以下几个进程状态:
static const char* task_state_array[]= { "R",//running 运行 "S",//sleeping 睡眠 "D",//disk sleep 深度睡眠 "T",//stop 暂停 "t",//tracing stop 挂起暂停 "x",//dead 死亡 "z"//zombie 僵尸 };还是一个一个来看。
运行
并非在cpu上跑的进程状态才叫运行,只要在运行队列中,都叫做运行状态。
睡眠
int main() { sleep(100); }在sleep的100秒中,就叫做进程正处于睡眠状态。
深度睡眠
如果只是单单用代码sleep一段时间,叫做浅度睡眠。那么深度睡眠是什么?
在一个进程涉及到文件操作的时候,数据量一大起来,读取文件肯定是很慢的。但是,如果在读取文件的时候,读取到一半,你把这个进程关了,那就会造成一个结果:

如果直接把这些数据直接丢掉不管了,一些小游戏存档还好,要是是银行更新数据更新一半,操作系统直接给更新进程杀了,那:

所以,深度睡眠状态是什么?就是因为在进行较慢的IO操作,此时进程停在了代码的某一行。但是为了保护IO操作,进程会处于深度睡眠状态,任何操作包括操作系统强制都无法杀掉深度睡眠的进程,一直到IO操作结束退出深度睡眠状态。
除非你关机。
暂停
在Linux当中,我们可以通过发送SIGSTOP信号使进程进入暂停状态(stopped),发送SIGCONT信号可以让处于暂停状态的进程继续运行。
对于信号的部分,我们放在单独一个章节来讲,但是可以通过kill -l指令,来查看所有的信号: 
挂起暂停
挂起
什么是挂起?
我们知道,再nb的cpu,他的内存也是有上限的。当内存被塞满了,怎么办?
- 删掉一部分进程?不可能,当你删一个进程的时候,那个进程肯定不服气:凭什么要删我不删他?
- 把进程压缩?也不可能,压缩和解压也是需要时间和空间的,得不偿失。
此时,我们把头一瞥,突然发现了一件事:

所以,cpu有可能把内存中的数据放在磁盘上吗?
之前在冯诺依曼体系中说过,内存和磁盘的空间,最大的区别便是读写速度。内存中的数据是处理最快的,所以必须要将磁盘中的数据加载到内存里,再进行操作;磁盘的空间是最大的,所以只需要保存数据的时候,就把数据放回到磁盘上。
那,是所有的数据都要被处理吗?当一个进程被暂停或者睡眠的时候,或者就算是在运行队列中没有被调度的时候,这些数据都不会被处理,而是在等待调度。既然不会被处理,那是不是就可以被暂时放回到磁盘中呢?当然可以。我们只把PCB留在内存里,把数据和代码都放回到磁盘中,等到被调度的时候,把数据和代码从磁盘里重新导入到内存里;时间片结束了,再把数据和代码放回磁盘。这样,同一时间,只有被调度的进程数据和代码在内存中,便极大节省了空间,再也不怕太多进程导致内存爆炸了。
不过,内存和磁盘的交互还是太慢了。为了提速,磁盘中单独弄出一个分区,叫做swap区(不是swag!)。swap分区大概只有2G左右,专门用于与内存的资源交互,因为swap分区很小而且地址固定,所以相比于在1T的磁盘中查找资源,在2G的固定空间中查找显然快得多。
这个时候再想想,一个大游戏,动不动就50个G,但是一般的电脑都是16G的RAM,难道游戏运行的时候,就是将所有的50G全部加载到内存里吗?当然不是,只在需要的时候,加载一个场景里的东西,当切换场景的时候,就将前一场景的内存全部除去,将新场景的内存加载,因为场景之间的切换涉及到了内存和磁盘的资源交换,现在知道为什么会这么卡了吧
那么,挂起是什么?PCB在内存中,但是数据和代码在磁盘中的进程,就叫做挂起状态。
挂起和挂起暂停其实是一回事,只不过是存储的方式不同而已。
死亡
一个进程结束,返回信息交给父进程,从内存中消失,就叫做死亡状态。死亡是一瞬间的,并不像可碧一样世人会牢牢记住他伟大,一个进程甚至没有一个名字,一旦死亡,便无法被发现。

僵尸
但是,我说但是,牢大复活赛打赢了呢?
僵尸进程,就是当子进程的任务完成了,要返回了,写了张纸条给父进程,突然发现,父进程似了。

也不一定必须是父进程死亡。有可能父进程处于暂停状态,睡眠状态,或者单纯是父进程忘了写接收子进程消息的代码,反正最后会产生一个结果:子进程虽然结束,但是无法有效告知子进程现在的状态。子进程必须要等父进程拿到消息才可以安稳趋势,但是在父进程没有接收到消息之前,子进程会处于一种状态:

而在子进程运行完毕,到父进程拿到子进程结果的中间状态,就叫做僵尸状态。
僵尸进程是一种无法选中的状态。任何操作都无法杀掉一个僵尸进程,只有子进程把消息给父进程,僵尸进程才会自动转换为死亡进程,否则僵尸进程会一直停留在内存里,一直占用内存,某种意义上造成内存泄漏。
孤儿进程

父进程死亡了的进程,就叫做孤儿进程。
对僵尸进程来说,如果父进程只是睡着了,或者暂停了,那其实还好说。因为总有一个时候,父进程会醒过来,拿到子进程的状态,然后子进程安稳趋势。但是,如果父进程忘了写接收子进程消息的代码,那问题就大了:
父进程完全忘了自己还有个子进程,父进程运行完了,直接倒头趋势;这个时候子进程一看,父进程没了!子进程变成了孤儿进程,再也没有办法把消息交给父进程,子进程便一直处于孤儿状态,没有任何办法处理掉这个进程,这块内存就无法释放了。
所以,操作系统有专门处理孤儿进程的方法——转递抚养权。当父进程似了,子进程的抚养权就会交给父进程的父进程。但是,如果父进程的父进程也无法处理这个子进程的消息,就会再往上递,一直层层上递给能处理消息的父进程。并且,所有的进程,其最终的祖宗进程是操作系统,操作系统一定有处理僵尸进程的办法,也就保证了,任何孤儿进程的僵尸状态一定能保证被处理。
进程等待
那么,子进程的消息,父进程应该怎么处理呢?
两种方法:wait和waitpid

- wait便是简单粗暴,只要有子进程返回信息,就接收信息;
- 而waitpid,则是wait功能的扩展,所以我们重点来讲waitpid
status
参数中的status是进程退出状态。我们知道int的大小是4子节32byte,而传入指针是因为函数中要修改传图的status参数,像C++中传引用一样。其中32byte,并非都会用到,而只使用了低16byte
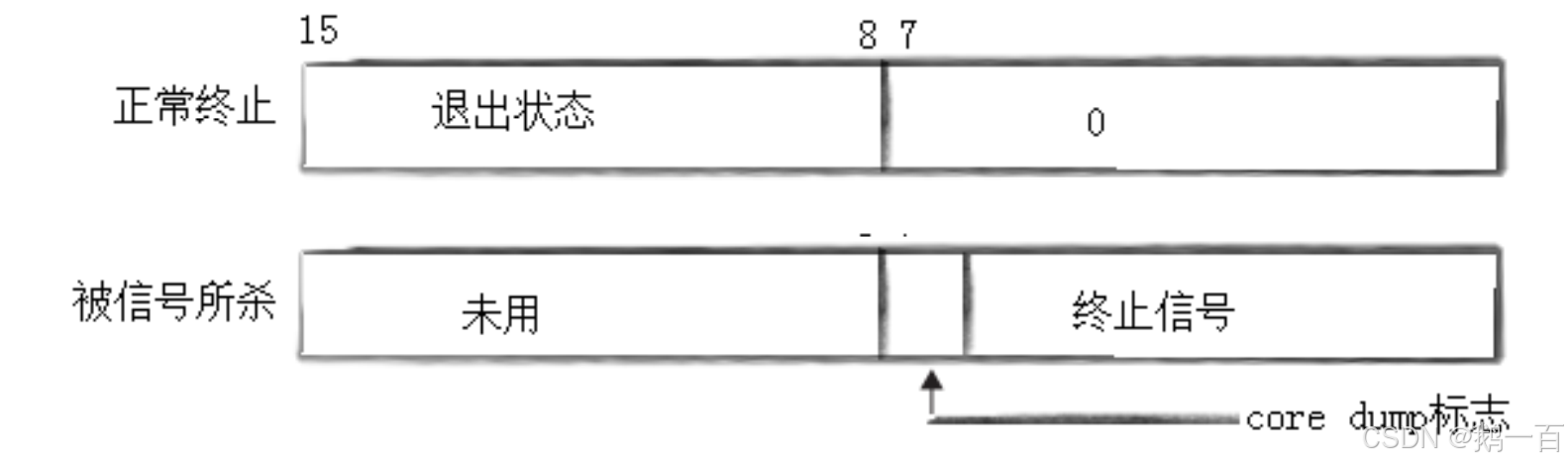
当进程正常终止的时候,就会用8-15byte,来表示退出的状态;当进程异常终止的时候,就会用0-7byte来表示终止的错误码。而我们获取status的含义,并不需要采用位操作手动分析,只需要调用两个系统函数:
bool WIFEXITED(int status); //若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出) int WEXITSTATUS(int status); //若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)这些函数会自己进行位操作的分析,然后提取出有用的信息,以基本的类型表示出来。
options
options,是进程等待的状态。进程等待有两种状态——阻塞等待和非阻塞等待。
- 阻塞等待,就是在受到子进程的返回值之前,会一直停在代码的那一行,一直到接收到子进程的返回值再继续往后运行。
- 而非阻塞等待,便是在waitpid处看一眼,如果子进程返回了,就拿到结果;如果子进程没有返回,也不等他,接着往后运行。所以,非阻塞等待一般会搭配一个循环运行:
int pid=0,cnt=0; while(pid==0) { pid = waitpid(-1,nullptr,WNOHANG); //非阻塞等待,如果等到了子进程,就返回子进程的pid,否则返回0 cnt++; }就像你突然肚子疼,要跑去WC,发现所有坑位都满了。
如果这个时候你很急,你要一直等在原地,当哪个坑位出来了人,你直接冲进去,就叫做阻塞等待;
如果这个时候你没有那么急,WC太臭了,你决定先出去透透气,隔段时间回来看一次坑位,就叫作非阻塞等待。
进程退出
子进程一定是正常退出的吗?当然不是,进程可能在中间出现了某些问题,无法继续运行下去,提前退出了。但是,对于主函数退出很简单,只需要return 1便可以;对非主函数的退出,return可起不到效果:
void func(int i) { if(i==-1) return 1;//这里的return是返回值,并不会使程序终止 } int main() { func(-1); return 0;//无论i是否为-1,最终都会return 0; }那么,有没有办法,让程序可以在任意地方退出呢?当然有:
exit和_exit
在C语言,肯定看到过exit这个函数,来进行程序的退出,最终的返回值为exit中的参数。但是,Linux中,存在exit和_exit,都表示程序的退出,他们的区别是什么?
exit是C语言中的函数,而_exit是系统调用函数。只有在Linux中,_exit才会生效,而且是一种强制的退出。比如:
int main() { printf("hello world"); exit(0);//分别使用_exit()和exit() }我们会发现,使用exit()会输出结果,而使用_exit()并不会有任何输出。这是因为,exit()是对_exit()的封装,_exit()只是完成进程退出这一功能,而exit()除了要完成进程退出,还需要刷新缓冲区,执行析构函数等等操作,所以在使用exit()的时候,刷新了缓冲区,hello world才被输出了出来,而如果只使用_exit(),他只不过完成了退出这一操作,并没有刷新缓冲区,所以缓冲区的数据永远丢失了。换句话说:
void exit(int status) { _flash();//刷新缓冲区 _destroy();//析构 //... _exit(status);//最后调用_exit() }exit封装了许多系统调用。
而许多Linux系统调用与C语言的函数大多都是这样。对不同的系统,其系统调用都不同,用户不可能换一个系统便去学习该系统的调用。所以C语言,将所有类似的系统调用封装成一个函数,用户只需要去学习C语言,便可以用于所有的系统之中,减少了用户的学习成本,这也是C语言存在的意义——统一所有系统的操作。

