
阅读量:6
配置Prometheus
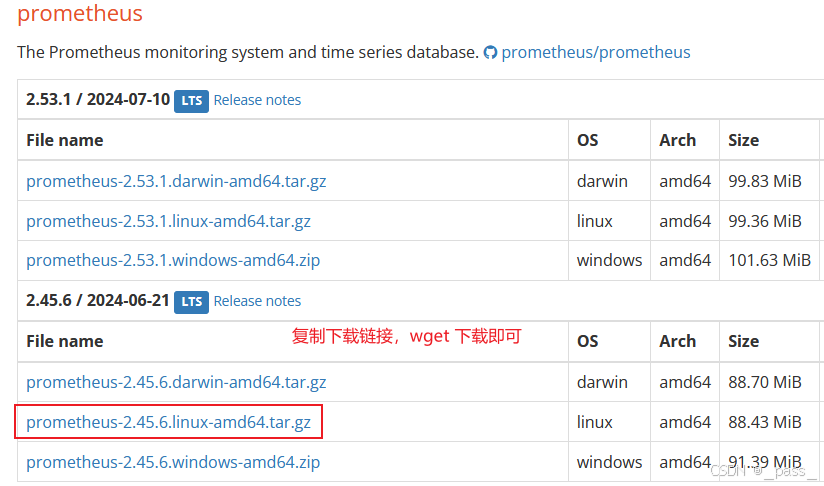
(wegt下载压缩包,解压并重命名prometheus,文件放于/data/prometheus即可)
配置 service方法(文件放于 /etc/systemd/system/prometheus.service):
[Unit] Description=Prometheus Server Documentation=https://prometheus.io/docs/introduction/overview/ After=network-online.target [Service] Type=simple User=prometheus Group=prometheus ExecStart=/data/prometheus/prometheus/prometheus \ --config.file=/data/prometheus/prometheus/prometheus.yml \ --storage.tsdb.path=/data/prometheus/prometheus/data \ --storage.tsdb.retention.time=60d \ --web.enable-lifecycle Restart=on-failure [Install] WantedBy=multi-user.target 授权给用户 prometheus
# 创建用户 -M 不创建源目录 -s 指定 shell useradd -M -s /usr/sbin/nologin prometheus # 赋权 chown prometheus:prometheus -R /data/prometheus启动运行并检查状态
# 启动 systemctl start prometheus.service # 检查 systemctl status prometheus.service # 开启自启动 systemctl enable prometheus.service # 修改单元文件,重新加载systemd配置 sudo systemctl daemon-reload # 检查日志方法 journalctl -u prometheus.service -f重新加载 prometheus
# -X 指定 POST 请求 curl -X POST http://localhost:9090/-/reload 访问web地址9090:
# ip:9090 访问 prometheus http://xxx.xxx.xxx.xxx:9090 监控指标 http://xxx.xxx.xxx.xxx:9090/metrics

配置 alertmanager
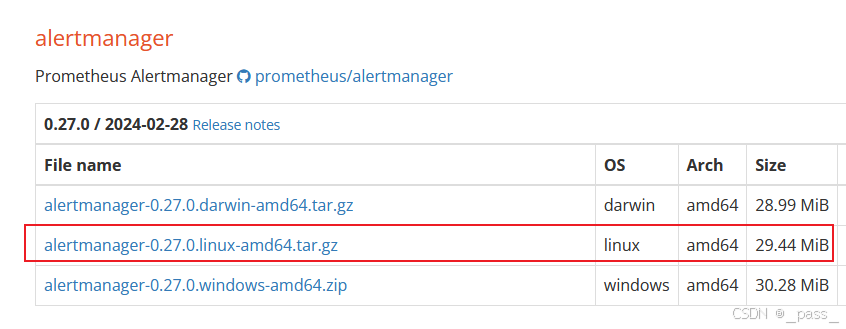
配置文件
[Unit] Description=Alert Manager Wants=network-online.target After=network-online.target [Service] Type=simple User=prometheus Group=prometheus ExecStart=/data/prometheus/alertmanager/alertmanager \ --config.file=/data/prometheus/alertmanager/alertmanager.yml \ --storage.path=/data/prometheus/prometheus/data \ Restart=always [Install] WantedBy=multi-user.target访问:web端口9093
配置alert服务器告警提示:
root@pass:~# cat /data/prometheus/prometheus/alert.yml groups: - name: Prometheus alert rules: - alert: 服务告警 expr: up == 0 for: 30s labels: severity: critical annotations: instance: "{{ $labels.instance }}" description: "{{ $labels.job }} 服务器"访问web检查:
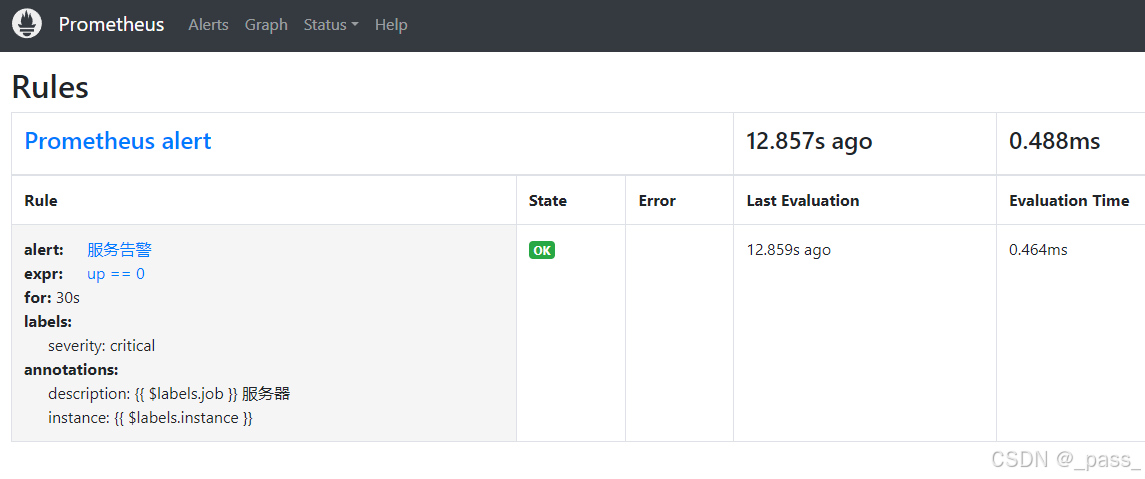
检查yml文件配置方法promtool工具:
root@pass:~# cd /data/prometheus/prometheus/ root@pass:/data/prometheus/prometheus# ./promtool check config prometheus.yml Checking prometheus.yml SUCCESS: 1 rule files found SUCCESS: prometheus.yml is valid prometheus config file syntax Checking alert.yml SUCCESS: 1 rules found配置grafana
下载地址:Download Grafana | Grafana Labs

配置service文件:
[Unit] Description=Grafana server Documentation=http://docs.grafana.org [Service] Type=simple User=prometheus Group=prometheus Restart=on-failure ExecStart= /data/prometheus/grafana/bin/grafana-server \ --config=/data/prometheus/grafana/conf/defaults.ini \ --homepath=/data/prometheus/grafana [Install] WantedBy=multi-user.target 访问web端口3000:(默认账号及密码admin/admin)

配置node_exporter
下载地址同Prometheus

配置service文件:
[Unit] Description=node_exporter Documentation=http://prometheus.io/ After=network.target [Service] User=prometheus Group=prometheus Restart=on-failure ExecStart= /data/prometheus/node_exporter/node_exporter [Install] WantedBy=multi-user.target 访问web端口9100
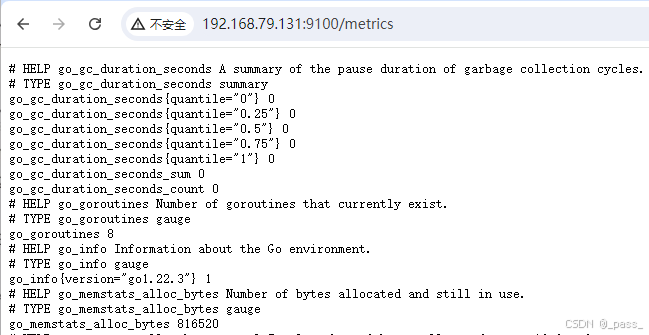
最后注意记得配置时将需要的配置到Prometheus.yml中:
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - localhost:9093 # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "alert.yml" # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] - job_name: "node-exporter" scrape_interval: 15s # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["localhost:9090"] labels: instance: Prometheus服务器web页面展示

手动创建仪表板:官方地址 Grafana dashboards | Grafana Labs
复制需要的ID ,然后导入到granafa图表中即可
第一步:
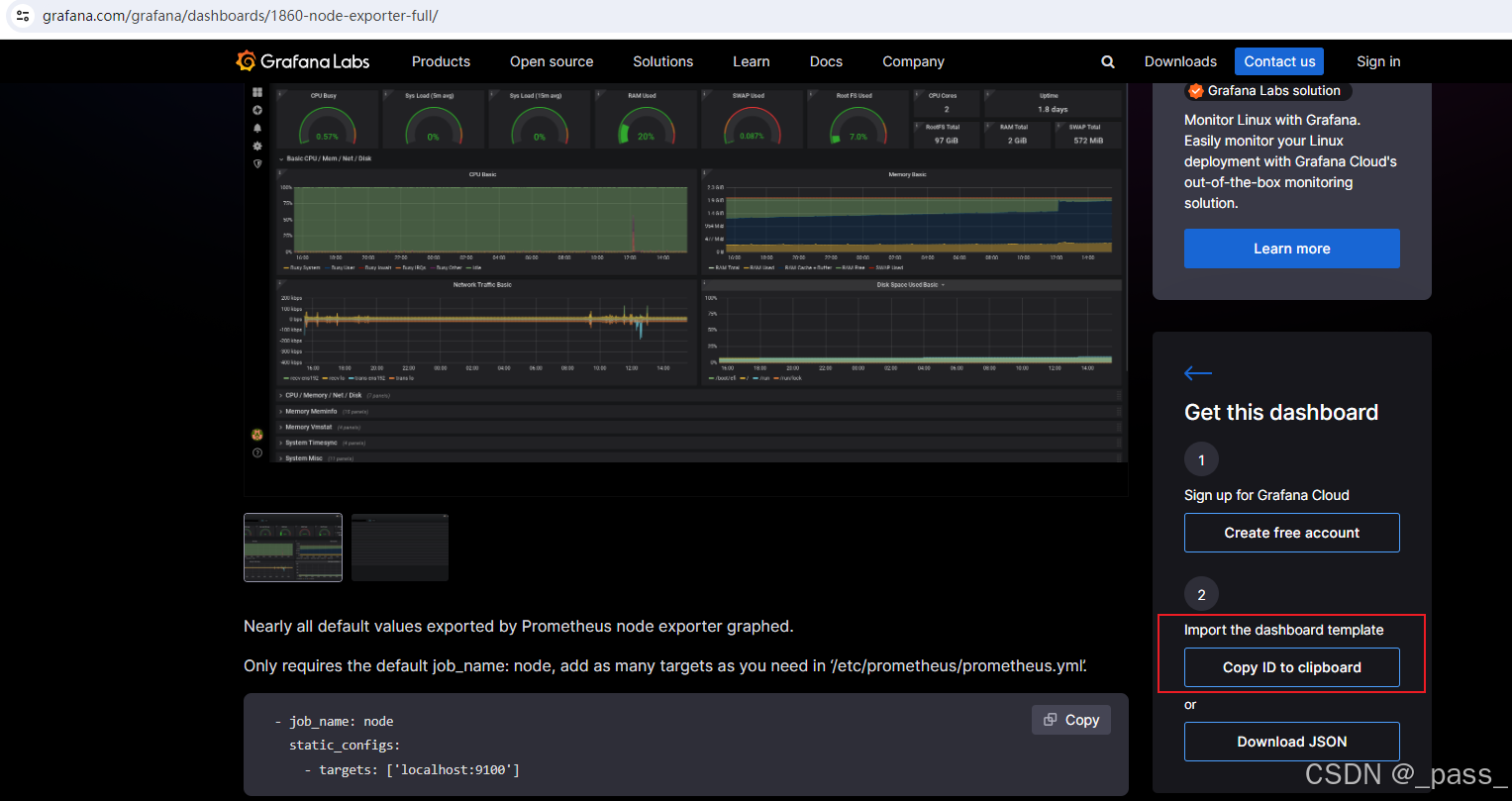
第二步:
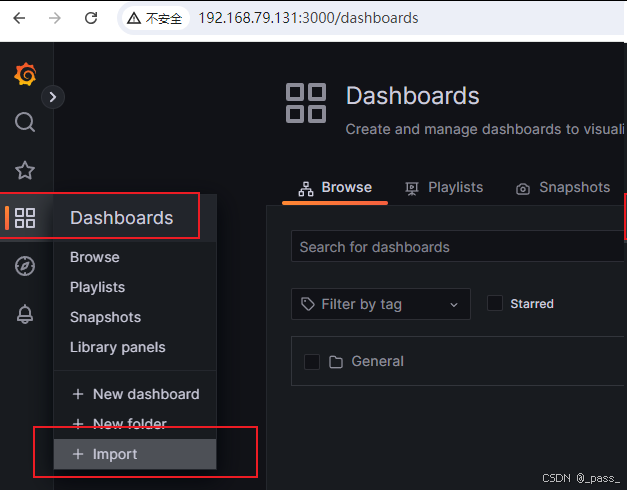
第三步:

展示结果:

