
阅读量:1
文章目录
前言
大家多多亲自尝试调试,故而这里部分内容讲得很略;
调试真的非常奇妙!
一,什么是bug?
bug即程序漏洞,本意为”昆虫“或”虫子“,现在一般是指在电脑系统或者程序中,隐藏着一些未被发现的缺陷或者问题。
二、什么是调试?
当我们发现一个程序出现问题时就要去找到问题,而找问题的这个过程就是调试;调试的英文为Debug,为消灭bug 的意思;
调试一个程序首先它是存在问题,需要我们去通过各种手段去定位问题的位置,可能是逐过程的调试,也可能是隔离和屏蔽代码的方式,找到问题代码的所在位置,然后确定出现问题的原因,再修复代码消灭bug,重新测试。
三、Debug 与 Release版本的区别

在vs编译器我们发现有Debug 与Release 两种版本;这两种版本分别代表了什么意思呢?
Debug 通常称为调试版本:它包含调试信息,并且不做任何优化,以便于程序员调试程序;
程序员在写代码的时候,需要经常性地调试代码,就在此处设置为Debug版本,这样在编译的过程中产生的是Debug版本的可执行程序,其中包含调试信息,是可以直接进行调试的;
Release 称为发布版本:它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户更好地使用。当程序员写完代码,测试再对代码进行测试(测试测试的是release版本),直到程序的质量交付给用户使用的标准,此时就会用到Release 版本,release版本编译产生的可执行程序是用户使用的,无需包含调试信息等;
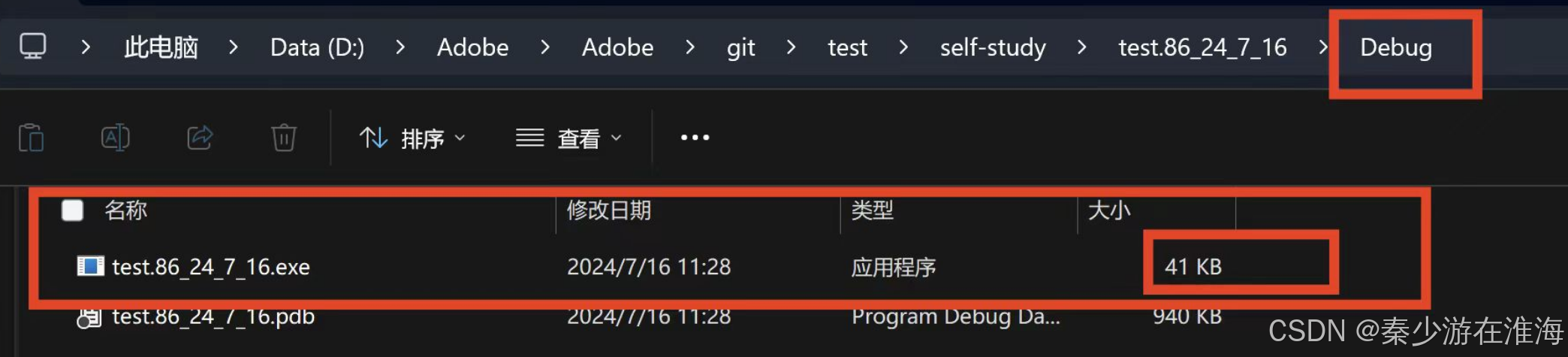
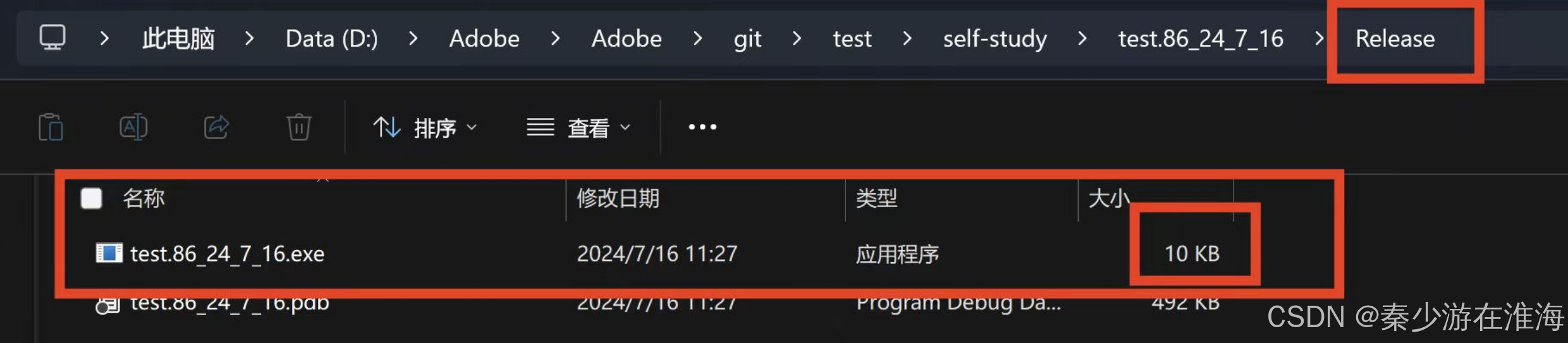
明显地可以看到Release版本下的可执行程序为10 KB,Debug 版本下的可执行程序为41KB;证明了Release版优化了代码所占空间内存的大小;
四、VS调试快捷键
1、环境准备
想要调试就得使用Debug版本;
2、调试快捷键
在了解调试快捷键之前,我们先来laio
F9 :创建断点和取消断点
断点的作用是可以在程序的任意位置设置断点,打上断点按F5就可以使得程序执行到想要的位置并且在那个位置暂停执行,接下来便可以用F10、F11来逐过程、 逐语句来观察代码的执行细节
F5 :启动调试,经常用来直接跳到下一个断点(断点由F9来创建)处,故而一般F5是与F9一起使用
F10 :逐过程,通常用来处理一个过程,这一个过程可以是一次函数调用,也可以是一条语句
F11 :逐语句,就是按一次F11 执行一条语句,但是这个快捷键可以让我们进入函数内部。所以在函数调用的地方想要进入函数观察细节,就必须使用F11,而若用F10便不会进入函数内部;
注:F11与F10:
1、F11与 F10 在处理普通语句时,二者并无区别;
2、F11 与F10 的区别在于函数调用的语句上;F11能进入函数内部;F10不会进入函数内部;
Ctrl + F5 :开始执行不调试
使用举例:
例1:
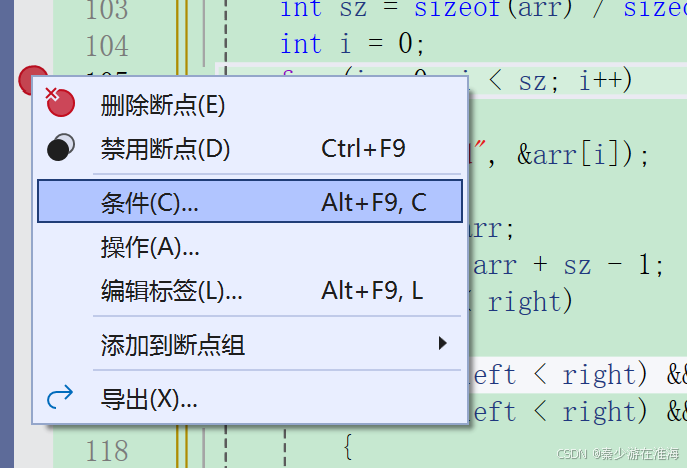
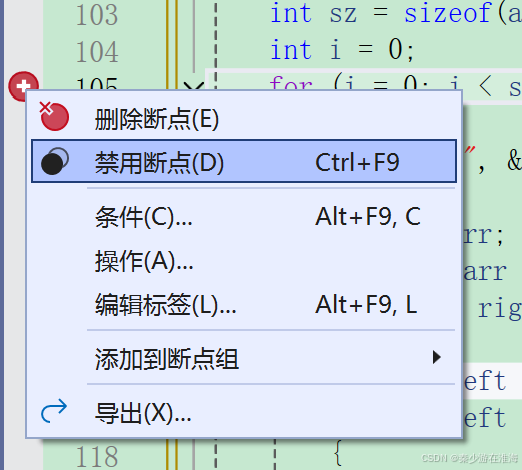
当你选择想要断点的行时,按下F9 ,便会出现一个红点;再右击此红点,就会出现上图的选项;
下图中便是点击了 ”选择“,设置为 i == 4; 代表着当按下 F5 时,这个程序会在当i == 4;时停下来。
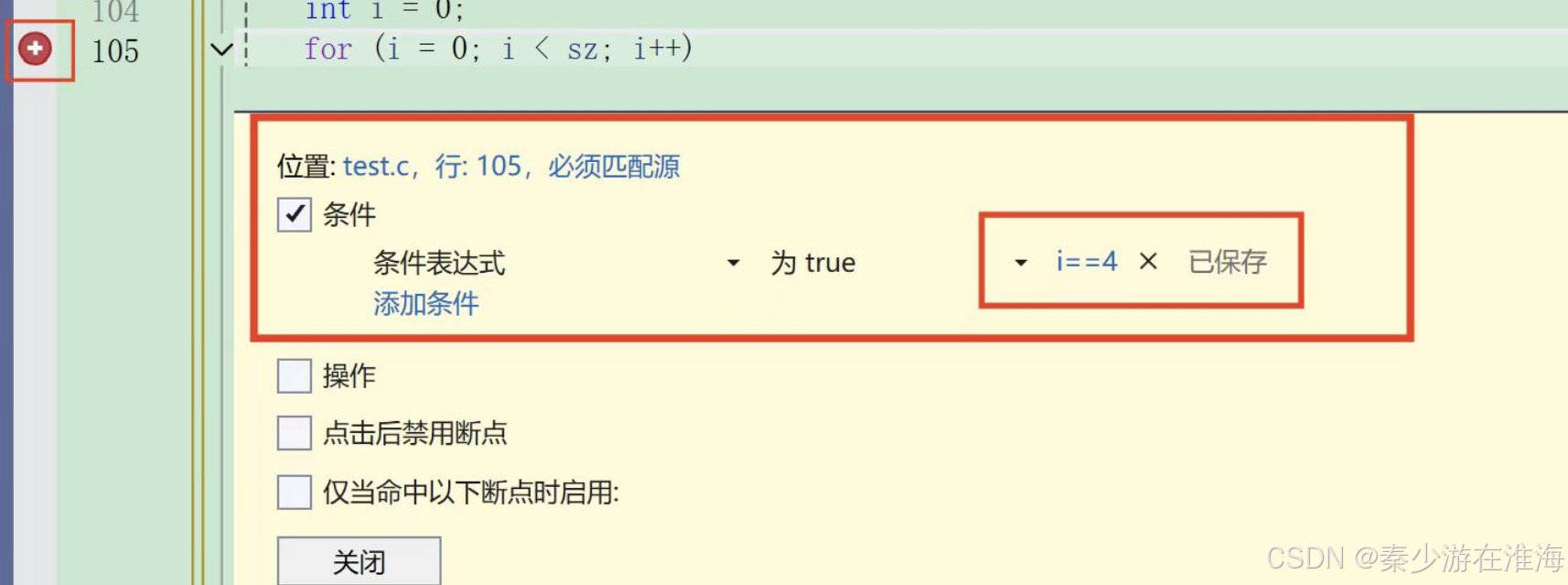
当你不想用这个断点时可以右击该断点--> ”禁用断点 “
五、监视和内存观察
前提:在调试后再观察
1、监视
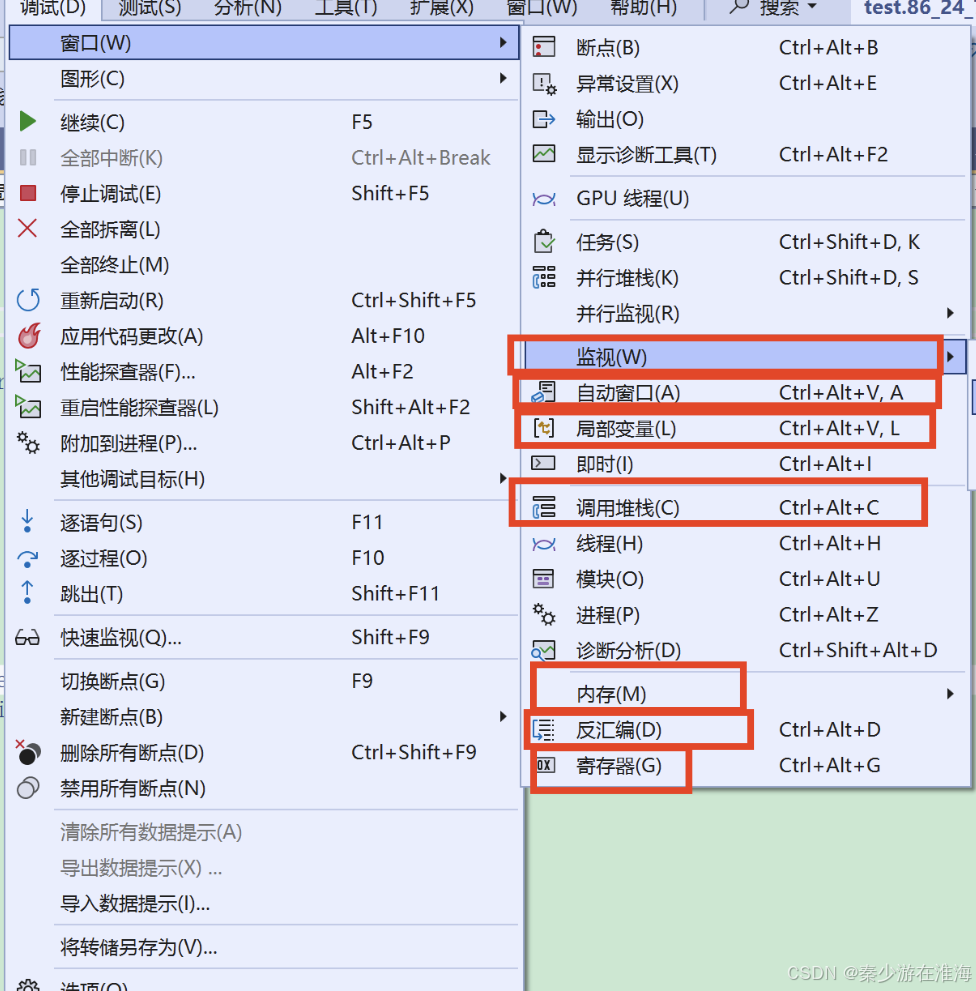
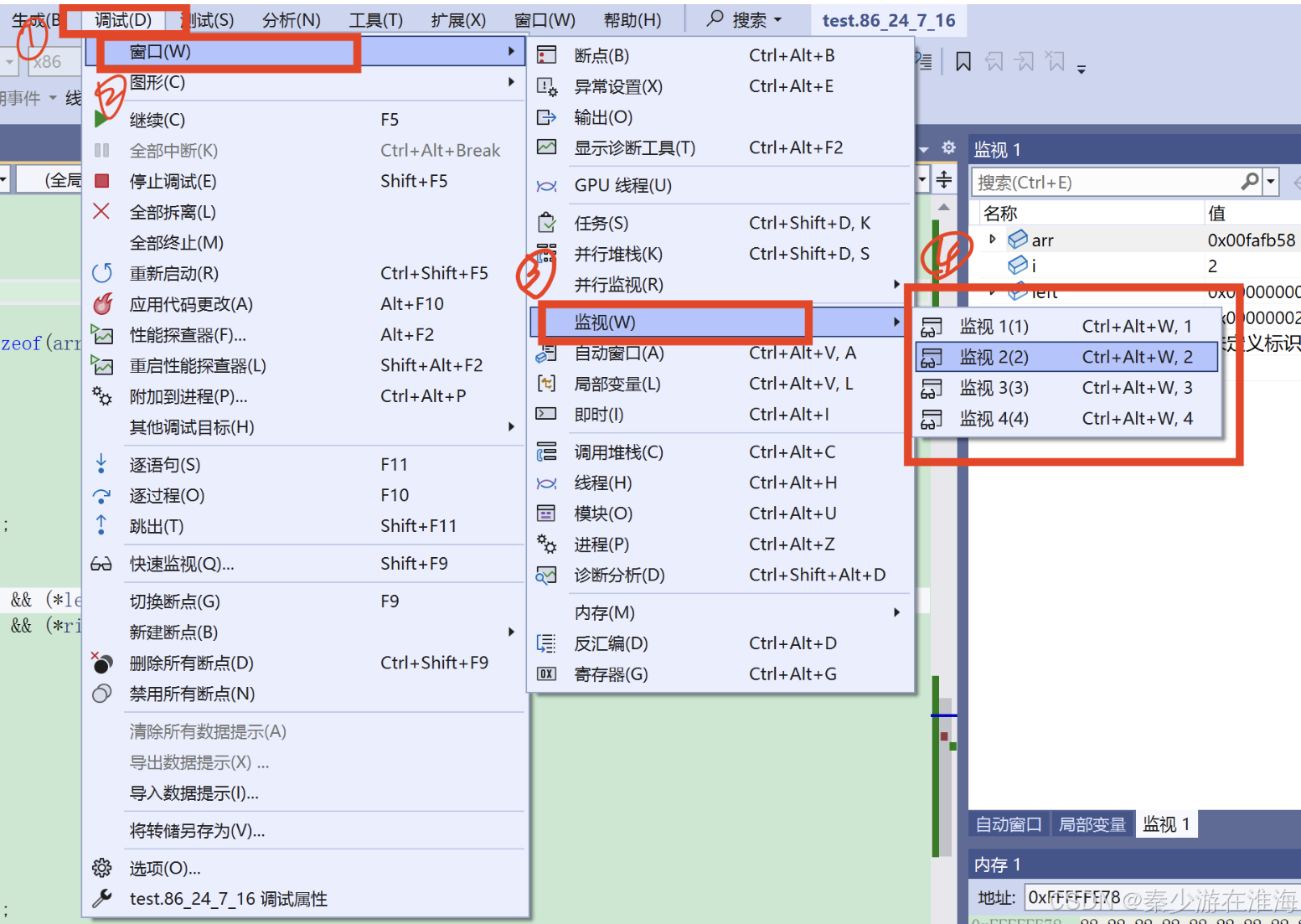
开始调试之后: 调试--> 窗口--> 监视,;此时会有4个监视器可以进行选择,随便点一个就行,当然这四个监视窗口可以同时展开,只要去调整它们之间的位置即可;
2、内存
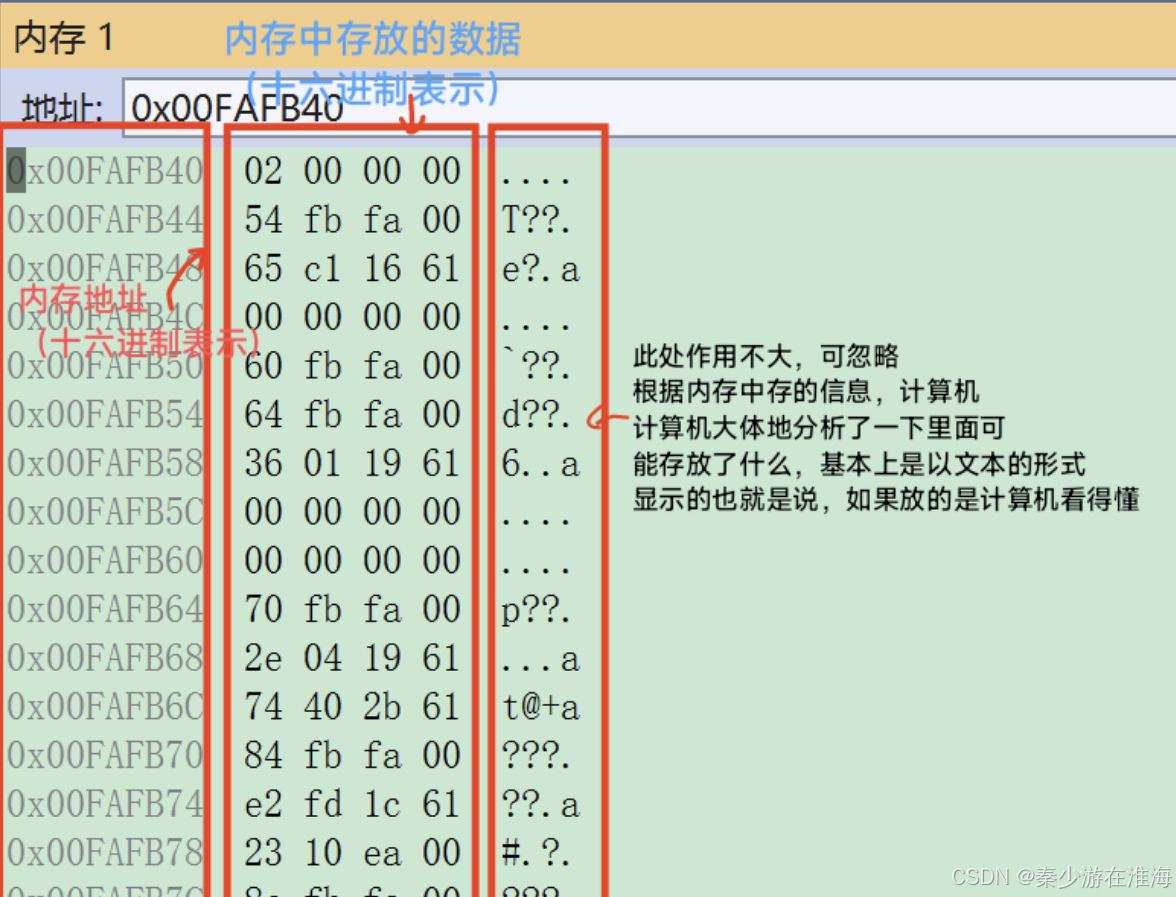
调试之后,调试--> 窗口--> 内存
六、查看调用堆栈
调试之后,调试--> 窗口--> 调用堆栈
注:什么叫做调用堆栈?在一个项目中会写很多代码,而这些代码之间会互相调用;当这些代码互相调用时,其中的调用逻辑就会非常复杂,此时如果想观察当前程序中代码之间是如何调用的,就会用到调用堆栈;
七、查看汇编信息
方法一:右击代码的页面--> 转到反汇编
方法二:调试之后,调试--> 窗口--> 反汇编
八、查看寄存器信息
调试之后,调试--> 窗口--> 寄存器
九、案列分析
bug代码分析:
代码如下:
#include<stdio.h> int main() { int i = 0; int arr[10] = { 1,2,3,4,5,6,7,8,9,10 }; for (i = 0; i <= 12; i++) { arr[i] = 0; printf("haha\n"); } return 0; }代码在Degug x86 环境下的运行结果如下,陷入了死循环:
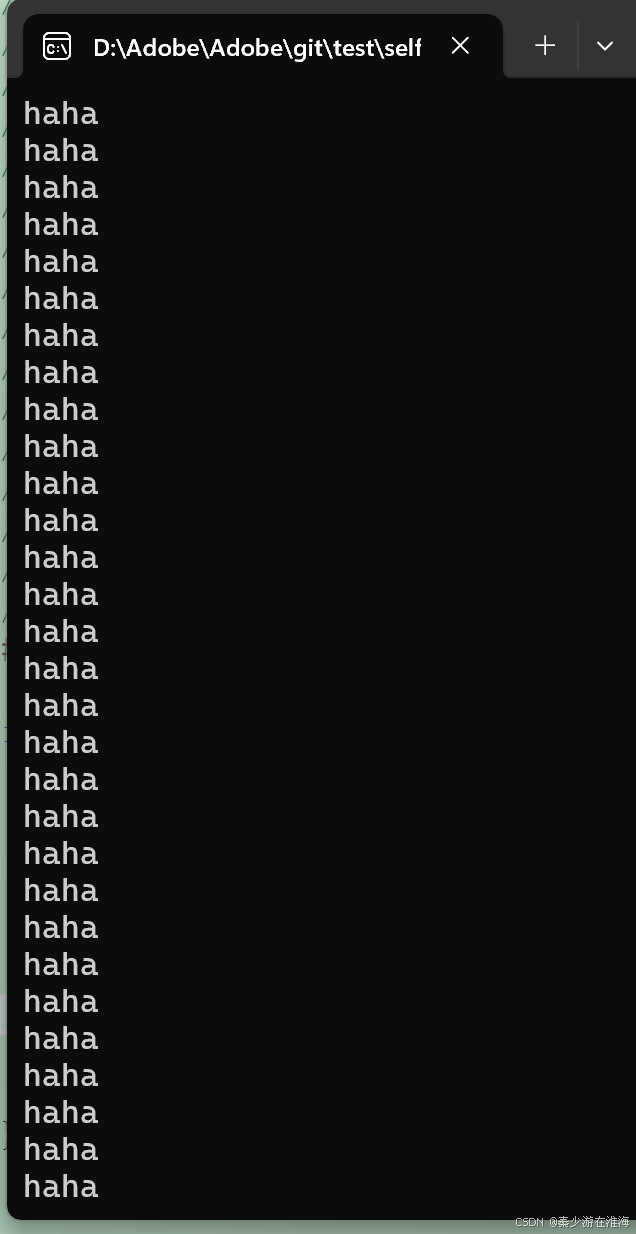
上述代码明明无非就是数组越界访问,但是为什么会陷入死循环呢?
为了找到这个原因,我们就去调试一下;
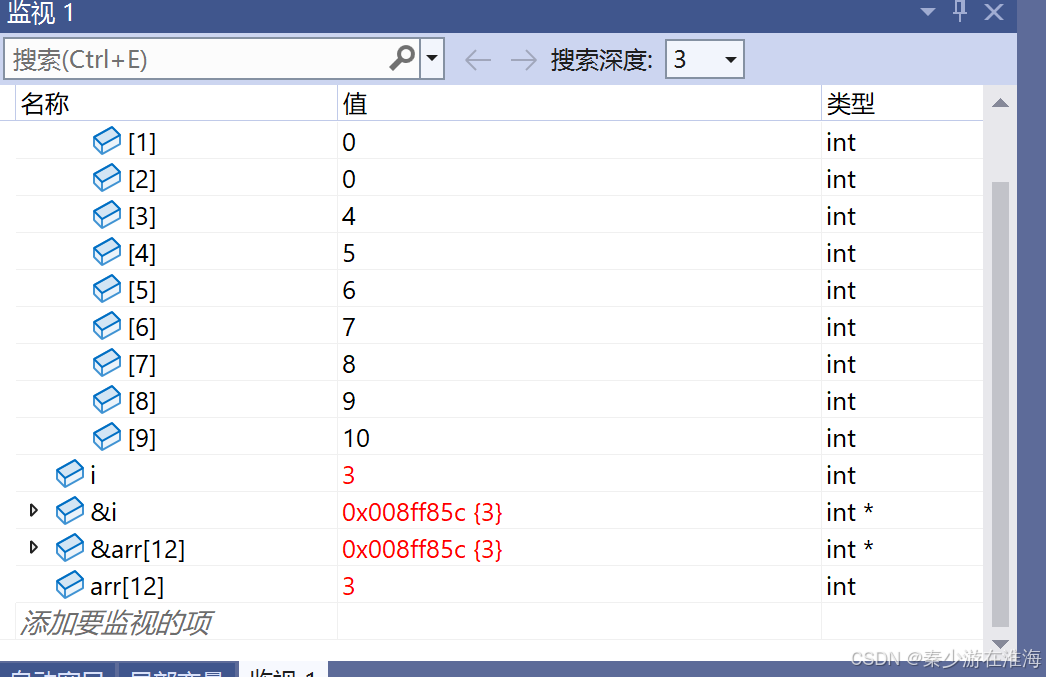
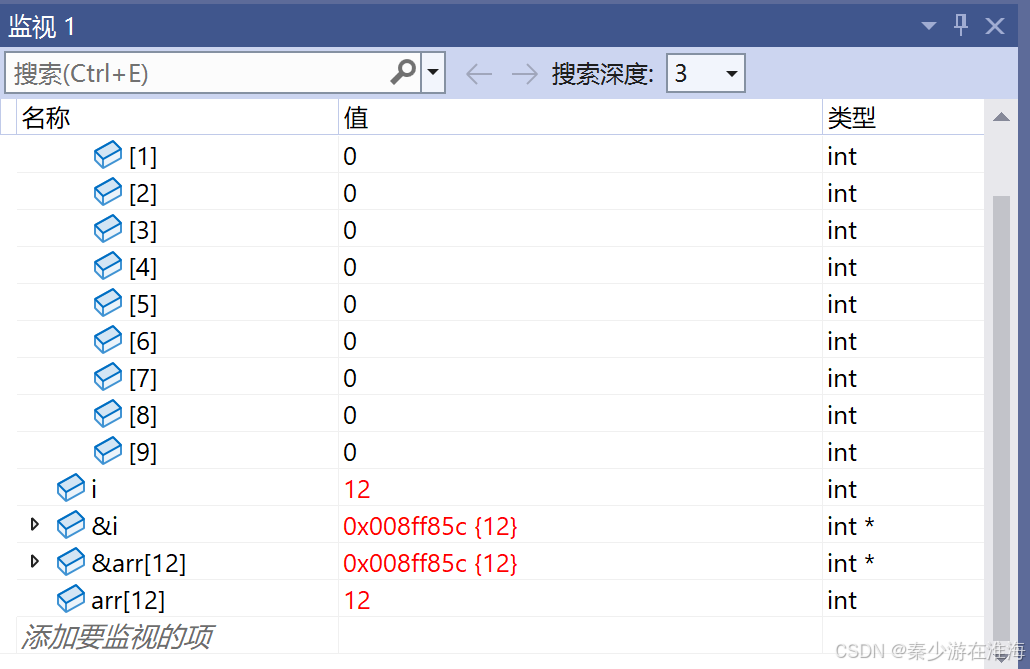
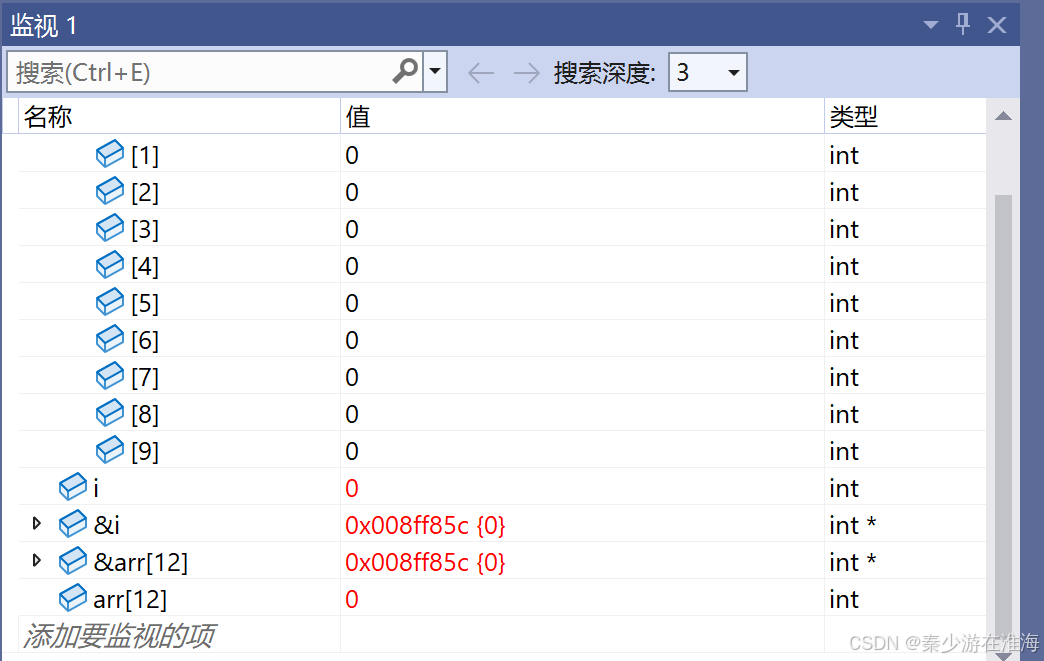
我们发现 变量i 的地址与越界访问arr[12] 的地址空间相同,i 变化会牵动 arr[12]变化,也即是说arr[12]的变化会牵动 i 的变化,当将 arr[ 12 ] = 0;时,i也会变成 0,故而在 for 循环中陷入了死循环;
那么为什么 i 的地址也是arr[12] 的地址呢?
在此之前我们先来了解一下内存;内存分为栈区、堆区、静态区;局部变量存放在栈区;栈区内存使用的规则:在Debug x86 环境下,先使用高地址的内存而后再使用低地址的内存;而在Release版本或者在 x64环境下,则就是先使用低地址内存而后使用高地址内存;随着数组下标的增长,其元素的地址由低变高;图解如下:
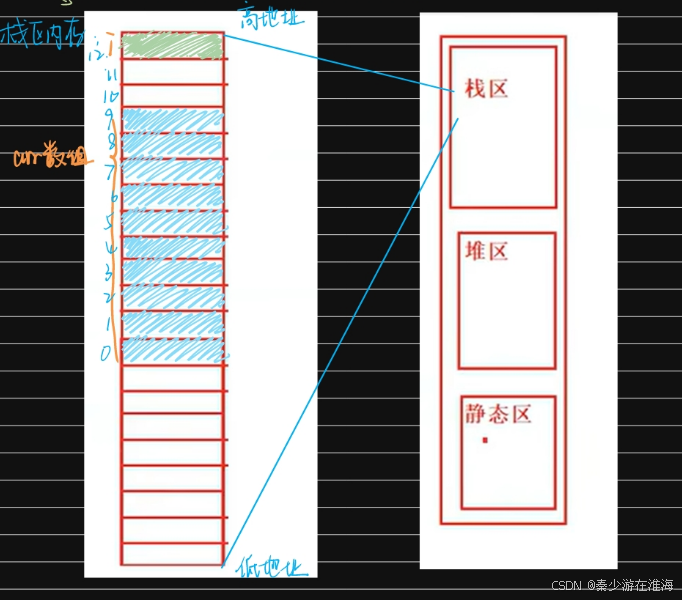
假设每个格子为 1byte 。
由于在Debug x86环境下,栈区的空间使用规则规则是,先使用高地址后使用;所以在创建局部变量 i 的时候,会向内存申请栈区中的高地址空间;数组arr也是局部变量,故而存放在栈区;但是数组的存放规则是,随着数组下标的增加其元素的地址由低到高即数组从低地址开始存放;那么当这个数组越界的时候,越界之后的空间可能会与存放变量a 的空间是同一个;
注:在此处vs的编译器下,变量i与数组arr之间只隔了两个字节的空间是巧合。变量i与数组arr之间隔了多少个字节取决于编译器,在不同编译器中空出的空间也是不一样的;代码中的这些变量内存和地址的分配是由编译器指定的,所以不同编译器之间就有差异;故而此代码陷入死循环与环境有关;
十、优秀的代码
1、优秀代码的体现
a. 代码运行正常
b.bug少
c.代码效率高
d.代码的可读性高
e.代码的可维护性高
f.注释清晰
g.文档齐全
2、写出好代码的技巧
a.使用assert
注:assert();中为假时便会报警;
b.尽量使用const
注:const 修饰指针时:(以 int* p = &a;为例)
1、const 在* 左边,有两中写法;即 const int* p ;或者 int const * p ; 这两种写法都代表着*p 是const修饰的常变量即不可被修改的属性;也就是说,指针p 所指向的对象为常变量;
2、const 在* 右边,写法为:int * const p; 即指针 p 是const 修饰的常变量即p 中存放的地址是不可被修改的;
c.养成良好的编程风格
d,添加必要的注释
e. 避免代码陷阱
3、模拟实现strcpy
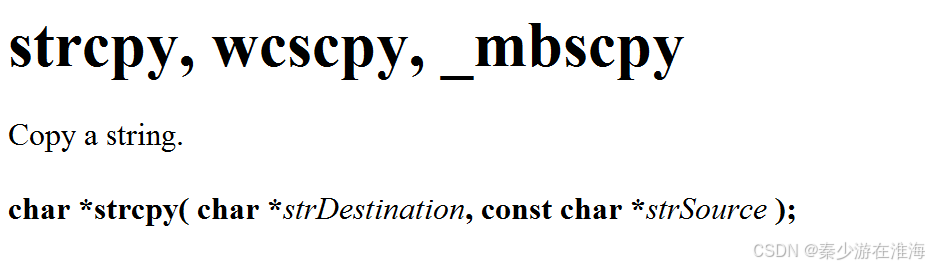
首先我们看一下 strcpy 函数的结构;strcpy() 是用来拷贝一个字符串的函数,其的返回值的类型为char* ; 其中的const char* strSource 中的const 修饰* strSource,以表示strSource指向的变量是常变量即不可被修改;此函数是将strSource指向的内容拷贝到Destination 指向的对象之中;
模拟strcpy函数的代码如下:
#include<stdio.h> #include<assert.h> char* my_strcpy(char* dest, const char* src) { assert(dest && src); char* ret = dest; //strcpy() 会拷贝'\0',需要一个 循环将让*dest= *src;之后二者分别自增,当拷贝到'\0'时就停止循环 while ( *dest++= *src++)//后置++,先使用再++ { ; } return ret;//返回首元素地址 } int main() { char ch1[20] = { "xxxx"}; char ch2[12] = { "holle word" }; printf("%s\n", my_strcpy(ch1, ch2)); return 0; }4、模拟实现 strlen
同样的,我们先看一下strlen( )
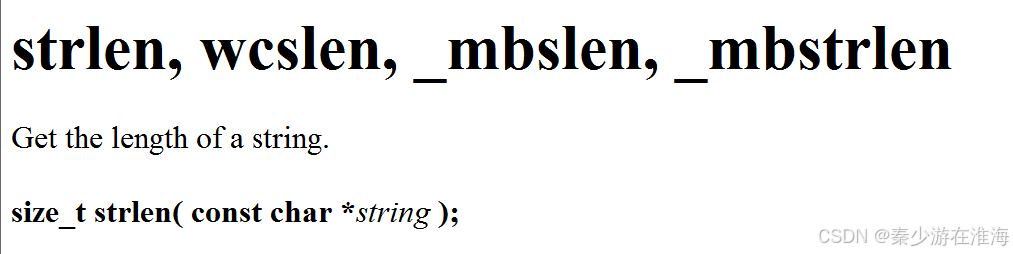
strlen 是用来求字符串长度的函数;size_t 是unsigned int 类型;const char* string ;中的const 中修饰的是 *string ,表示string 指向的对象是个常变量即不可更改属性;
模拟实现strlen 函数的代码如下:
//模拟实现strlen 函数 #include<stdio.h> #include<assert.h> int my_strlen(const char* str) { //strlen() 的计算原理,识别到'\0' 便停止 int count = 0; assert(str); while (*str) { count++; str++; } return count; } int main() { char ch[20] = { "i love chongqing" }; printf("%d\n", my_strlen(ch)); return 0; }十一、编程常见错误
在了解编程的常见错误之前,先让我们了解一下在VS中,一个可执行程序是怎样产生的;
源文件( .c文件) ---> 编译 ---> .obj文件 ---> 链接 --> 可执行程序(.exe 文件);即在源文件形成可执行程序期间,会经历编译与链接这两过程;那么便可以理解了,编程常见的错误分为编译型错误、链接型错误、运行时错误;
1、编译型错误
编译型错误一般是语法错误,一般看错误信息便可以解决,双击错误信息,便可以跳转到代码错误的地方或者附近;
2、链接型错误
出现在链接期间的错误就是链接型错误;看错误的提示信息,主要在代码中找到错误信息中的标识符;一般是因为:1、标识符名不存在;2、拼写错误;3、头文件没包含;4、引用的库不存在
3、运行时错误
运行时的错误需用调试的方式来解决;
总结
1、F9 :创建断点和取消断点
断点的作用是可以在程序的任意位置设置断点,打上断点按F5就可以使得程序执行到想要的位置并且在那个位置暂停执行,接下来便可以用F10、F11来逐过程、 逐语句来观察代码的执行细节
2、F5 :启动调试,经常用来直接跳到下一个断点(断点由F9来创建)处,故而一般F5是与F9一起使用
3、F10 :逐过程,通常用来处理一个过程,这一个过程可以是一次函数调用,也可以是一条语句
4、F11 :逐语句,就是按一次F11 执行一条语句,但是这个快捷键可以让我们进入函数内部。所以在函数调用的地方想要进入函数观察细节,就必须使用F11,而若用F10便不会进入函数内部;
5、Debug 通常称为调试版本:它包含调试信息,并且不做任何优化,以便于程序员调试程序;
6、Release 称为发布版本:它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户更好地使用。当程序员写完代码,测试再对代码进行测试(测试测试的是release版本),直到程序的质量交付给用户使用的标准,此时就会用到Release 版本,release版本编译产生的可执行程序是用户使用的,无需包含调试信息等;
