
阅读量:17
文章目录
Tortoise ORM 简介
Tortoise ORM 是一个为异步Python应用设计的ORM(对象关系映射)库;
它允许开发者以面向对象的方式与关系型数据库进行交互,同时充分利用异步编程的优势来提高应用的性能和响应速度;
Tortoise ORM 支持多种数据库后端,如PostgreSQL、MySQL和SQLite等。
核心概念
- 模型(Models):Tortoise ORM 使用Python类来定义数据库中的表结构。每个类代表一个数据库表,类的属性对应表中的列。
- 字段(Fields):在模型中定义字段,这些字段映射到数据库表的列。Tortoise ORM 提供了多种字段类型,如整型、字符串型、日期型等。
- 关系(Relations):Tortoise ORM 支持定义模型之间的关系,如一对一、一对多、多对多等。
- 异步操作:所有数据库操作都是异步的,使用
async和await关键字来执行。应用场景
- 构建高性能的异步Web应用,如使用FastAPI、Sanic或Starlette的应用;
- 需要面向对象方式操作数据库的项目。
- 需要异步数据库访问以提高应用性能的场景。
核心功能
- 模型定义:通过Python类定义数据库表结构。
- 数据查询:支持复杂的查询构建和执行。
- 数据操作:支持创建、更新、删除数据库记录。
- 关系管理:支持定义和查询模型之间的关系。
- 迁移和同步:提供数据库迁移工具,用于管理数据库模式的变更。
Tortoise ORM 特性
- 异步特性:Tortoise ORM 的所有数据库操作都是异步的,这意味着它们可以在单线程中同时处理多个数据库请求,而不会阻塞彼此。这大大提高了应用的并发性和性能。
- 模型定义:在Tortoise ORM 中,开发者使用Python类来定义数据库表结构。这些类中的属性对应于数据库表中的列,这使得数据库操作更加直观和易于理解。
- 查询构建:Tortoise ORM 提供了强大的查询构建功能,允许开发者构建复杂的查询条件,以检索所需的数据。这包括使用链式调用、比较运算符、逻辑运算符等。
- 关系映射:Tortoise ORM 支持定义模型之间的关系,如一对一、一对多、多对多等。这使得开发者可以轻松地处理复杂的数据关系,并在代码中以直观的方式表示它们。
- 迁移和同步:Tortoise ORM 还提供了数据库迁移工具,用于管理数据库模式的变更。这使得在应用开发过程中,可以轻松地添加、修改或删除表结构,而无需手动编写SQL语句。
Tortoise ORM 安装
Tortoise ORM 属于Python的第三方库,需要额外下载安装,命令如下:
pip install tortoise-orm Tortoise ORM 数据库支持
SQLite
from tortoise import Tortoise # 配置 SQLite 数据库 config = { 'db_url': 'sqlite://:memory:', # 使用内存中的 SQLite 数据库,也可以指定文件路径 'modules': { 'tortoise.backends.sqlite': { '_fk': True, # 开启外键支持 } }, 'generate_schemas': True # 自动创建表结构 } # 初始化 Tortoise ORM Tortoise.init(**config) # 创建表 Tortoise.generate_schemas() PostgreSQL
from tortoise import Tortoise # 配置 PostgreSQL 数据库 config = { 'db_url': 'postgres://user:password@localhost/dbname', # 替换为你的 PostgreSQL 连接信息 'modules': { 'tortoise.backends.postgres': { 'sslmode': 'disable' # 可选的,根据你的 PostgreSQL 配置调整 } }, 'generate_schemas': True # 自动创建表结构 } # 初始化 Tortoise ORM Tortoise.init(**config) # 创建表 Tortoise.generate_schemas() MySQL
from tortoise import Tortoise # 配置 MySQL 数据库 TORTOISE_ORM = { "connections": { "default": { # "engine": "tortoise.backends.asyncpg", # 数据库引擎 PostgresQL "engine": "tortoise.backends.mysql", # 数据库引擎 Mysql or Mariadb "credentials": { "host": "127.0.0.1", # 地址 "port": "3306", # 端口 "user": "root", # 用户名 "password": "root", # 密码 "database": "fastapi", # 数据库名称(需要提前创建数据库) "minsize": 1, # 最少连接 "maxsize": 5, # 最大连接 "charset": "utf8mb4", # 编码 "echo": True # 是否反馈SQL语句 } } }, "apps": { "models": { "models": ["models"], # models数据模型迁移 "default_connection": "default" } }, "use_tz": False, "timezone": "Asia/Shanghai" } # 初始化 Tortoise ORM Tortoise.init(**config) # 创建表 Tortoise.generate_schemas() Oracle
from tortoise import Tortoise config = { 'db_url': 'oracle://username:password@host:port/service_name', # 替换为你的 Oracle 连接信息 'modules': { 'tortoise.backends.oracle': { # 这里可以配置其他 Oracle 特定的设置,如使用钱包等 } }, 'generate_schemas': True # 如果需要自动创建表结构,设置为 True } Tortoise.init(**config) Tortoise ORM 创建模型
CharField字符串类型字段
- **max_length (int):**字符串的最大长度。
- **default (Any):**字段的默认值。
- **null (bool):**是否允许字段为NULL。默认为False。
- **unique (bool):**字段值是否必须在数据库中唯一。默认为False。
- **index (bool):**是否为该字段创建索引。默认为False。
- **description (str):**字段的描述信息,主要用于文档和生成的SQL schema。
- **pk (bool):**是否将此字段设置为主键。默认为False。
- **generated (bool):**是否为自动生成的字段(如自增主键)。默认为False。
FloatField浮点类型字段
- default, null, unique, index, description, pk, generated: 与CharField相同。
- **gt, lt, ge, le (int):**用于设置字段值的范围限制(大于、小于、大于等于、小于等于)。
IntegerField整数类型字段
- **default, null, unique, index, description, pk, generated:**与CharField相同。
- **gt, lt, ge, le (int):**用于设置字段值的范围限制(大于、小于、大于等于、小于等于)。
BooleanField布尔类型字段
- **default, null, description:**与CharField相同。
DateField和DateTimeField日期时间类型字段
- **auto_now (bool):**如果设置为True,则在对象保存时自动设置为当前日期/时间。默认为False。
- **auto_now_add (bool):**如果设置为True,则在对象第一次保存时自动设置为当前日期/时间。默认为False。
- **default, null, unique, index, description, pk:**与CharField相同。
ForeignKeyField关系型字段
- **to (str or Type[Model]):**指定外键关联的模型。
- **related_name (str):**在关联模型上创建反向关系的名称。
- **on_delete (str):**当关联的对象被删除时的行为(如CASCADE、SET_NULL等)。
- **default, null, description, pk, index:**与CharField相同。
ManyToManyField关系型字段
- through: 用于定义多对多关系的中间表。如果不指定,Tortoise ORM将自动创建一个中间表。
- related_name: 与ForeignKeyField中的用法相同,用于反向查询。
- **default, null, description, pk, index:**与CharField相同。
TextField文本类型字段
- **default, null, description:**与CharField相同。通常用于存储大量文本。
JSONField序列话类型字段
- **default, null, description:**与CharField相同。用于存储JSON格式的数据。
以选课系统为例,创建models.py文件,代码如下所示:
from tortoise.models import Model from tortoise import fields class Student(Model): id = fields.IntField(pk=True) name = fields.CharField(max_length=32, description="学生姓名") pwd = fields.CharField(max_length=32, description="学生密码") sno = fields.IntField(description="学生学号") # 一对多的关系 clazzs = fields.ForeignKeyField("models.Clazz", related_name="students") # 多对多的关系 courses = fields.ManyToManyField("models.Course", related_name="students") class Course(Model): id = fields.IntField(pk=True) name = fields.CharField(max_length=32, description="课程名称") teacher = fields.ForeignKeyField("models.Teacher") class Clazz(Model): name = fields.CharField(max_length=32, description="班级名称") class Teacher(Model): id = fields.IntField(pk=True) tno = fields.IntField(description="教师编号") pwd = fields.CharField(max_length=32, description="教师密码") name = fields.CharField(max_length=32, description="教师名称") aerich 迁移工具简介
Aerich是Tortoise ORM框架的一个插件,它负责为数据库模型生成迁移脚本。在数据库开发中,迁移是一种管理数据库模式(即表结构)更改的方式;
当更改了模型类(例如,添加了一个新字段或更改了现有字段的类型),需要将这些更改应用到数据库中。
迁移工具允许你生成一个或多个脚本,这些脚本描述了如何将数据库从旧模式迁移到新模式。
Aerich的使用通常遵循以下步骤:
- 定义模型:首先,你需要在 Python 代码中定义你的数据库模型类,使用
Tortoise ORM的字段类型。- 生成迁移:当你对模型做出更改后,你可以使用
Aerich生成迁移脚本。这通常通过命令行工具完成,例如运行aerich migrate --name your_migration_name。这个命令会检查模型类与当前数据库模式之间的差异,并生成一个或多个迁移脚本。- 应用迁移:一旦你有了迁移脚本,你可以使用
Aerich将其应用到数据库中。这通常通过运行aerich upgrade命令完成。这个命令会按照定义的顺序执行迁移脚本,将数据库更新到最新的模式。
Aerich还提供了其他功能,如回滚迁移(aerich downgrade)和列出所有迁移(aerich show)等。使用
Aerich的好处是,它允许你以一种可控制和可追踪的方式管理数据库模式的更改。通过查看迁移脚本,可以清楚地看到每次更改的内容和顺序,这有助于在团队中协作和调试数据库问题。
aerich 迁移工具安装
pip install aerich aerich 迁移工具使用
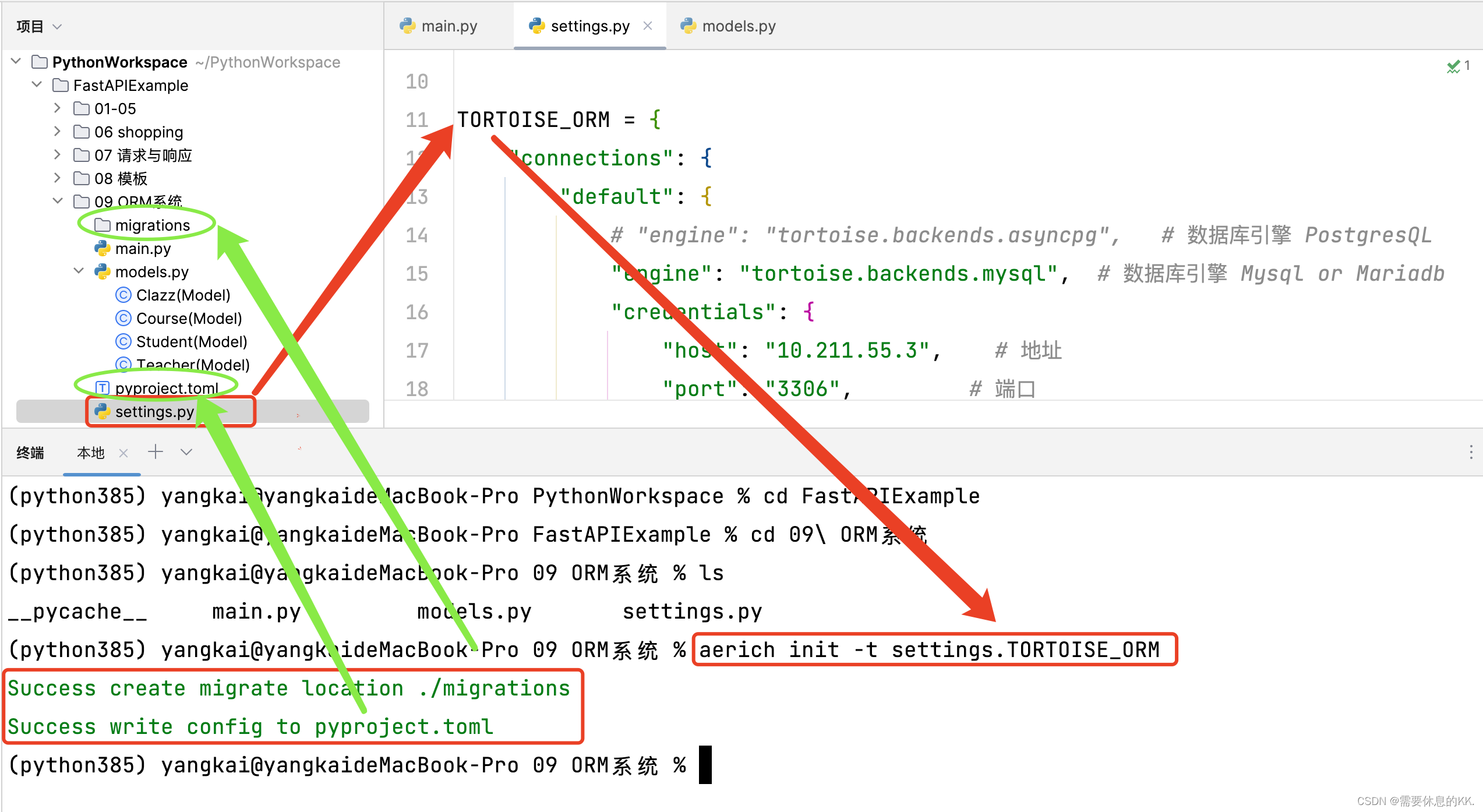
初始化配置(只需要使用一次)
aerich init -t settings.TORTOISE_ORM # TORTOISE_ORM配置的位置 初始化完成会在当前目录下生成一个文件:pyproject.toml和一个文件夹:migrations
- pyproject.toml:保存配置文件路径,低版本可能是aerich.ini
- migrations:存放迁移文件的目录
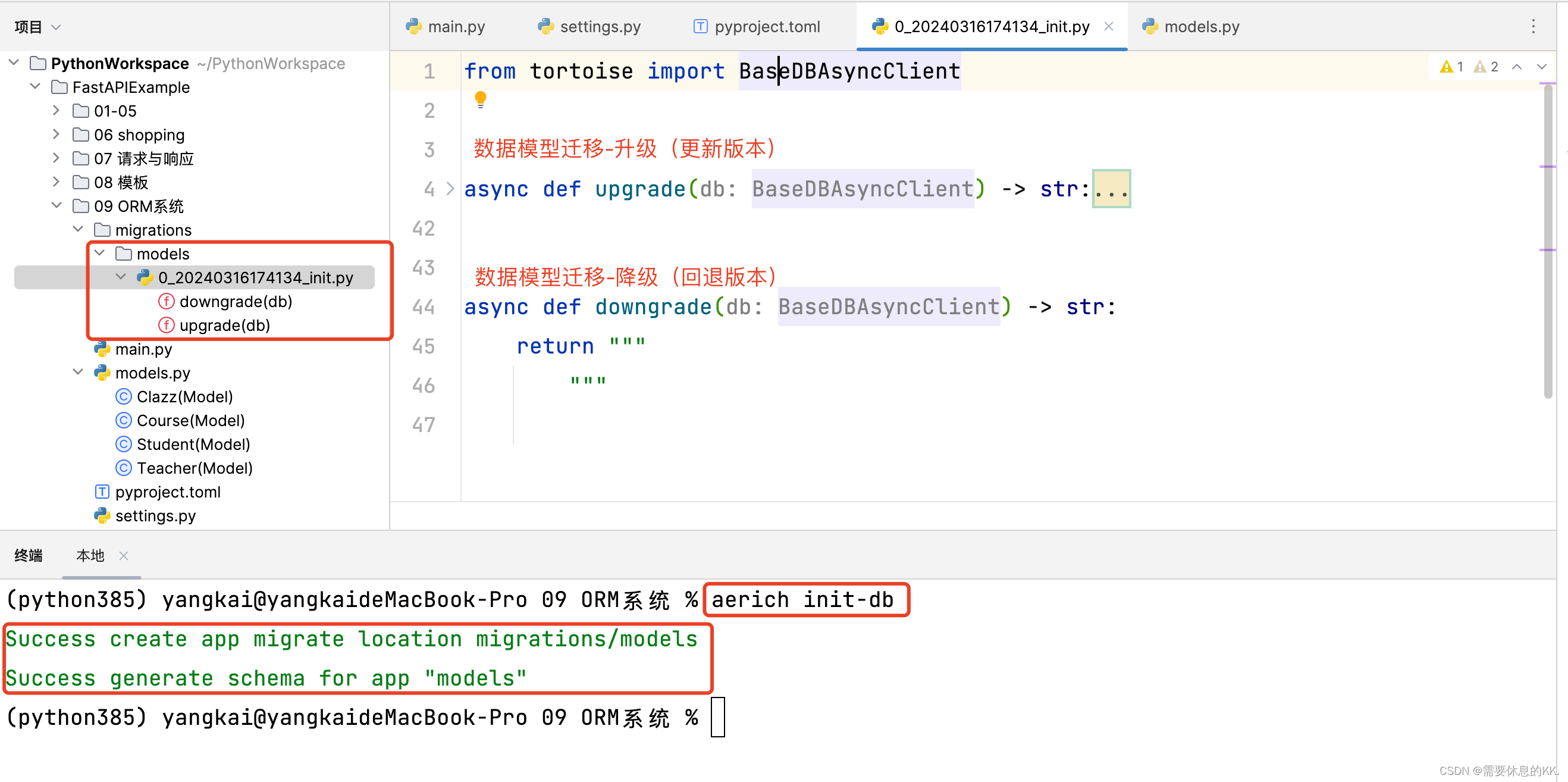
初始化数据库(一般情况下只需要使用一次,更新数据库表字段)
aerich init-db 此时数据库中就会有对应数据模型的数据表格
如果TORTOISE_ORM配置文件中的models改了名字,则执行这条命令时需要增加**–app**参数,来指定修改的名称
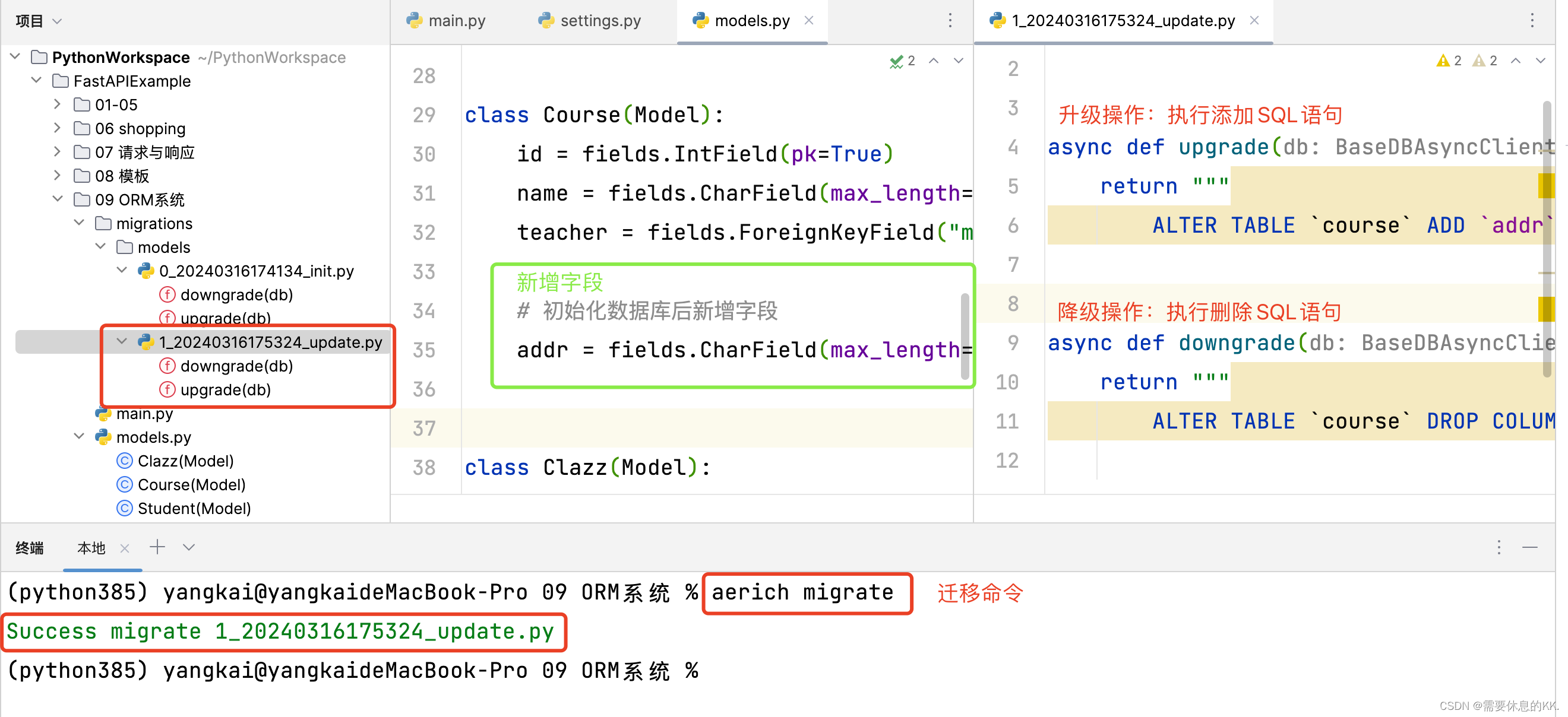
数据迁移
修改models类,重新生成迁移文件,比如添加一个字段
class Course(Model): id = fields.IntField(pk=True) name = fields.CharField(max_length=32, description="课程名称") teacher = fields.ForeignKeyField("models.Teacher") # 初始化数据库后新增字段 addr = fields.CharField(max_length=32, description="教室地址", default="") aerich migrate [--name](标记修改操作) # aerich migrate --name add_column 迁移文件名称的格式为:{version_num}{datetime}{namelupdate}.json
升级:更新数据模型版本
aerich-更新数据模型-更新前
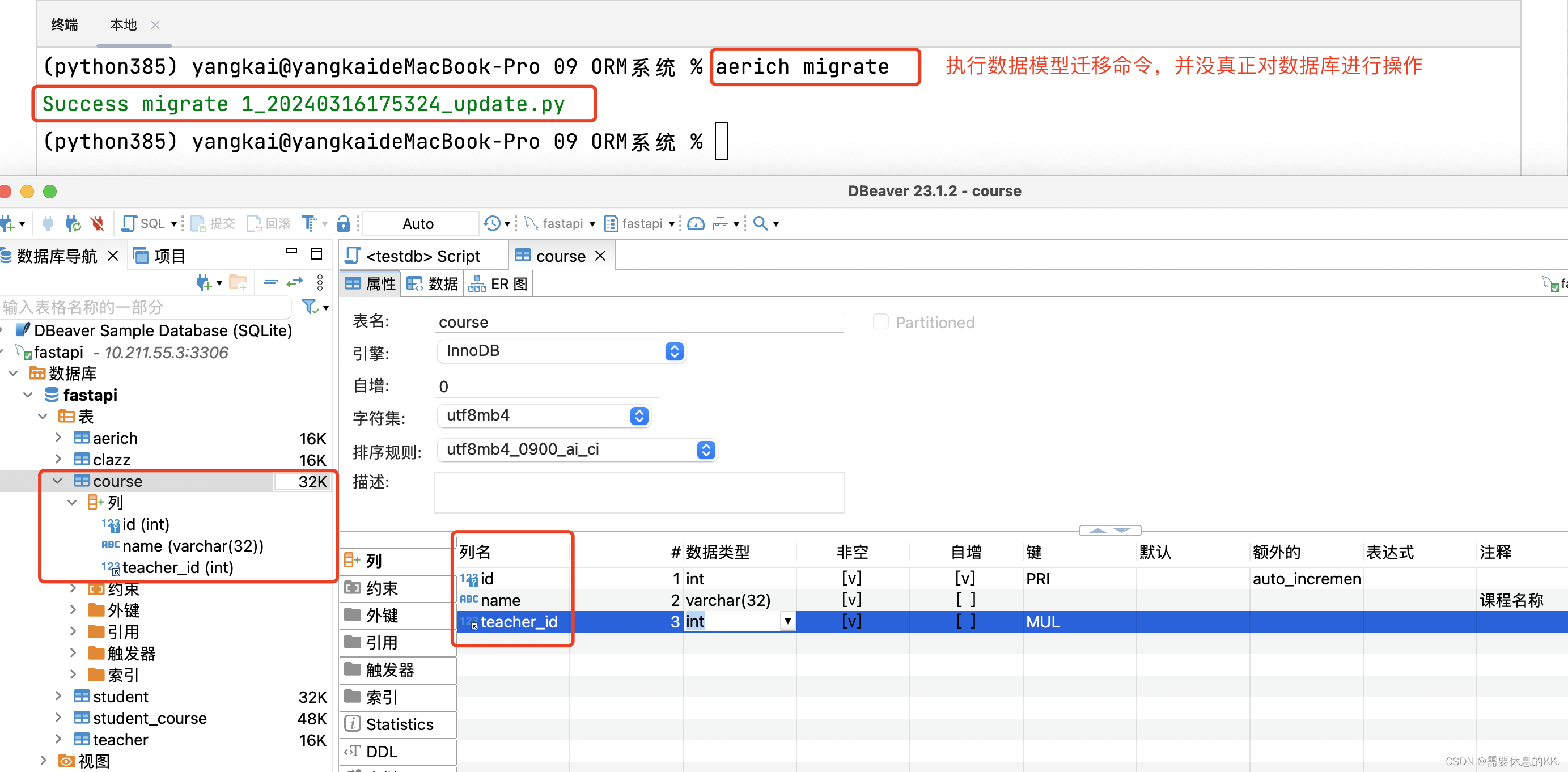
aerich upgrade 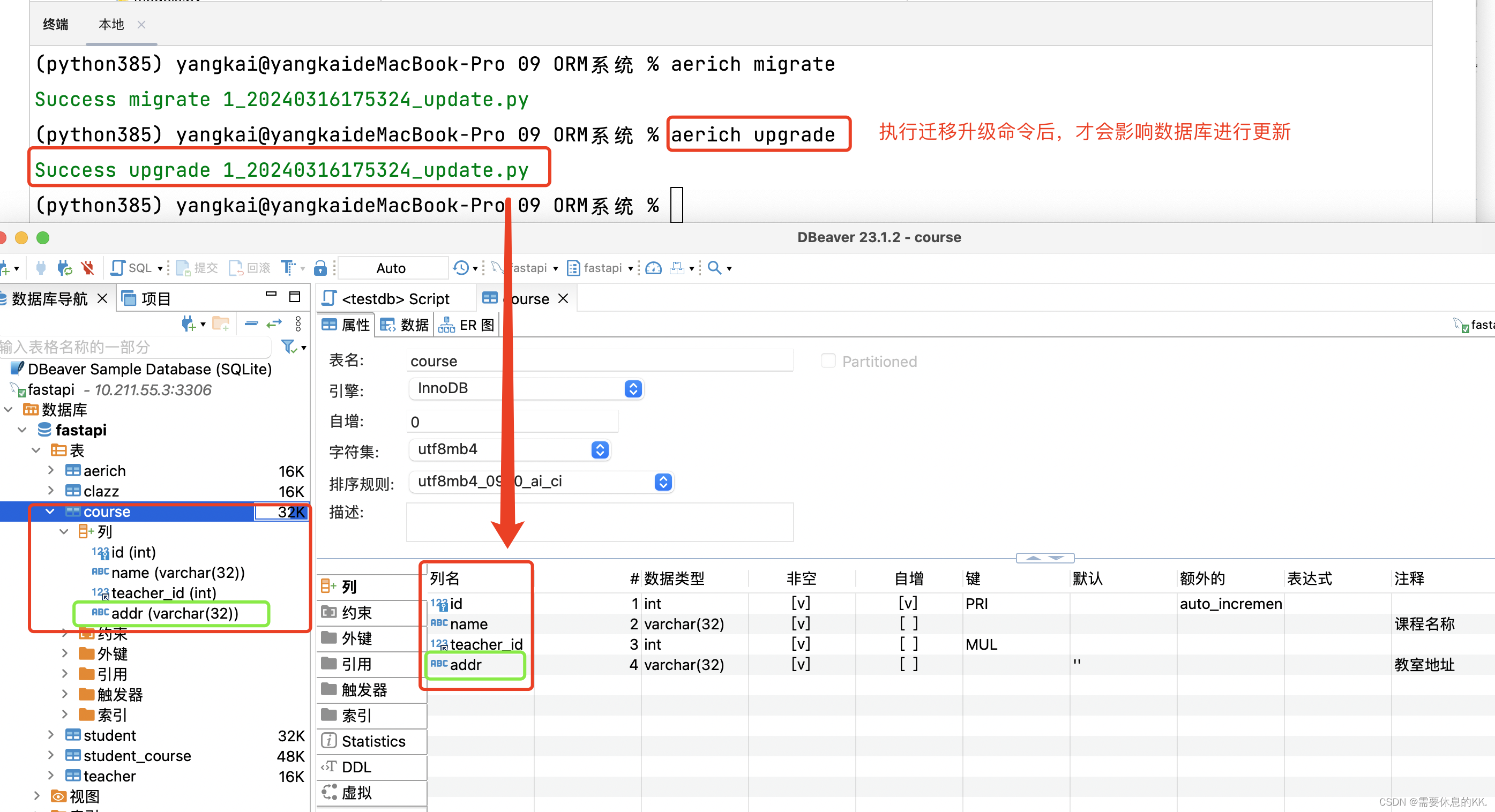
降级:回退数据模型版本
aerich downgrade aerich-更新数据模型-降级后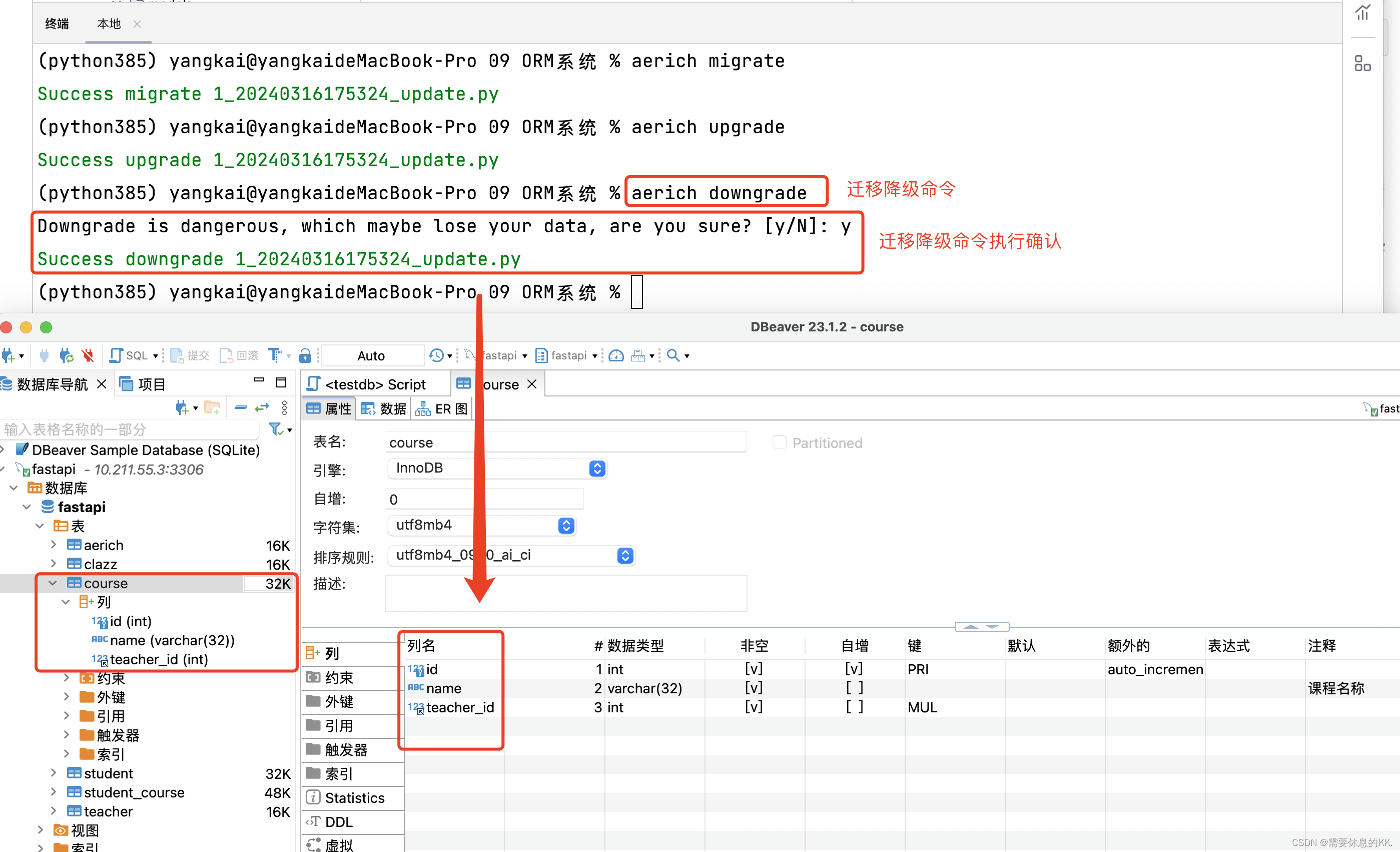
查看历史迁移记录
aerich history 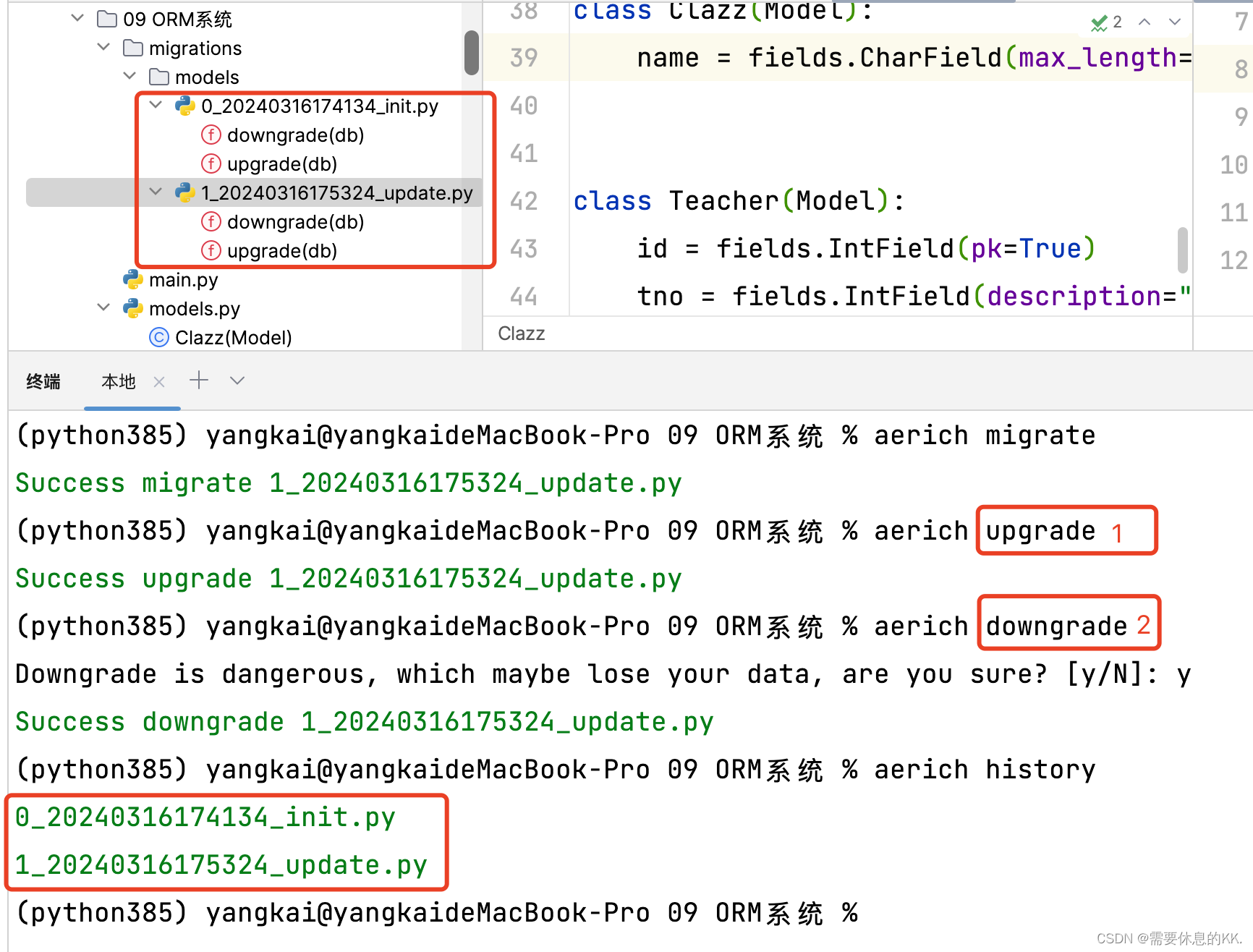
Trotoise ORM 查询数据
get()方法用于根据主键获取单条数据。如果数据不存在,将返回
None
# 获取id为1的用户,如果数据不存在,则抛出错误 student = await Student.get(id=1) # 获取id为100的用户,如果数据不存在,将返回 `None` student = await Student.get_or_none(id=100) if student: print(student.name) else: print("student not found")
all()方法用于查询所有数据,返回所有数据集(QuerySet对象)。如果不加任何条件,它会返回表中的所有记录。
students = await Student.all() # Queryset: [Student(), Student(), Student(), ...] # 此时不加 await 就会出现异常(线程不安全) for student in students: print(student.name)
filter()方法用于根据条件查询数据,返回满足条件的数据集(QuerySet对象)。可以使用
all()方法获取所有的查询结果,或者使用first()方法获取第一个结果。
# 获取所有名字为'赵德柱'的数据 students = await Student.filter(name="赵德柱").all() for student in students: print(student.id, student.name) # 获取第一个名字为'赵德柱'的数据 students = await Student.filter(name="赵德柱").first() if students: print(students.id, students.name) else: print("No user found") 比较运算符
# 获取id等于1的数据 students = await Student.filter(id=1).all() # 获取id不等于1的数据 students = await Student.filter(id__not=1).all() # 获取id大于1的数据 students = await Student.filter(id__gt=1).all() # 获取id大于等于1的数据 students = await Student.filter(id__gte=1).all() # 获取id小于5的数据 students = await Student.filter(id__lt=1).all() # 获取id小于等于5的数据 students = await Student.filter(id__lte=1).all() 成员运算符
# 获取姓名 在 指定列表中的数据 names = ['赵德柱', '李铁柱'] students = await Student.filter(name__in=names).all() for student in students: print(student.id, student.name) -------------------- # 获取姓名 不在 指定列表中的数据 names = ['赵德柱', '李铁柱'] students = await Student.filter(name__nin=names).all() for student in students: print(student.id, student.name) 模糊查询
# Tortoise ORM 不直接支持SQL中的LIKE模糊查询, # 但可以使用`icontains`、`istartswith`、`iendswith`等操作符进行模糊查询。 # 学号包含200 student = await Student.filter(sno__icontains='200') # 学号是200开头 student = await Student.filter(sno__istartswith='200') # 学号是200结尾 student = await Student.filter(sno__iendswith='200')
exclude()方法用于排除满足条件的数据,返回不满足条件的数据集。
# 获取名字不是'赵德柱'的所有数据 students = await Student.exclude(name='赵德柱').all() for student in students: print(student.id, student.name)
count()方法用于统计满足条件的数据数量。
# 统计名字为'赵德柱'的数量 count = await Student.filter(name='赵德柱').count() print(f"Number of users named '赵德柱': {count}")
order_by()方法用于按照指定字段排序查询结果。
# 按id升序获取所有数据 students = await Student.all().order_by("id") for student in students: print(student.id, student.name) # 按id降序获取所有数据 students = await Student.all().order_by("-id") for student in students: print(student.id, student.name)
__range查询学号在指定范围之间
students = await Student.filter(sno__range=[2001, 2003]).all() for student in students: print(student.id, student.name)
__isnull:是否为空(IS NULL)
# 查询学生姓名为空的数据 students = await Student.filter(name__isnull=True).all()
__regex:正则表达式匹配
(REGEXP 或 LIKE,取决于数据库)
# 查询名字匹配正则表达式的数据 pattern = r'^赵.*' # 以 赵 开头的名字 students = await Student.filter(name__regex=pattern).all()
__iregex:不区分大小写的正则表达式匹配
(IREGEXP 或 ILIKE,取决于数据库)
# 查询名字不区分大小写匹配正则表达式的用户 pattern = r'^a.*' # 以 a(不区分大小写)开头的名字 students = await Student.filter(name__iregex=pattern).all()
一对多查询、多对多查询
# values 可过滤需要的字段 students = await Student.all().values("name") # 一个学生的一对多查询 students = await Student.get(name="赵德柱@") print(students.sno) # 学号,2001 print(students.name) # 姓名,赵德柱@ print(students.clazzs_id) # 班级编号(外键),1 print(await students.clazzs.values("name")) # 利用外键对象查询name字段,{'name': '计算机科学与技术'} # 多个学生的一多对查询 # Student.all() 查询若干个学生对象 # values() 查询字段 # clazzs__name:clazzs是学生对象(班级)外键关联的对象,通过外键对象查找 students = await Student.all().values("name", "clazzs__name") print(students) # [{'name': '赵德柱@', 'clazzs__name': '计算机科学与技术'}, {'name': '吴鱼子@', 'clazzs__name': '计算机科学与技术'}, {'name': '史丹利@', 'clazzs__name': '计算机科学与技术'}, {'name': '李茂山@', 'clazzs__name': '计算机科学与技术'}, {'name': 'yangkai', 'clazzs__name': '计算机科学与技术'}, {'name': 'yangkai', 'clazzs__name': '计算机科学与技术'}, {'name': 'yangkai', 'clazzs__name': '计算机科学与技术'}, {'name': 'yangkai', 'clazzs__name': '计算机科学与技术'}, {'name': '李铁柱@', 'clazzs__name': '网络编程'}, {'name': '梁小龙@', 'clazzs__name': '网络编程'}, {'name': '百灵鸟@', 'clazzs__name': '信息技术'}, {'name': '吕小布@', 'clazzs__name': '信息技术'}] # 一个学生的所有课程(一对多)对应的所有教师(多对多) students = await Student.get(name="赵德柱@") # 赵德柱学生对象 print(await students.courses.all()) # 赵德柱学生所有的课程(一对多)[<Course: 1>, <Course: 2>] print(await students.courses.all().values("name")) # 赵德柱学生所有的课程的名称(一对多)[{'name': 'Python开发'}, {'name': 'Java开发'}] print(await students.courses.all().values("name", "teacher__name")) # 赵德柱学生所有的课程对应的教师(多对多)[{'name': 'Python开发', 'teacher__name': '李建国'}, {'name': 'Java开发', 'teacher__name': '郑忠良'}] # 多个学生的所有课程(一对多)对应的所有的教师(多对多) students = await Student.all().values("name", "clazzs__name", "courses__name") print(students) # [{'name': '赵德柱@', 'clazzs__name': '计算机科学与技术', 'courses__name': 'Python开发'}, {'name': '赵德柱@', 'clazzs__name': '计算机科学与技术', 'courses__name': 'Java开发'}, {'name': '吴鱼子@', 'clazzs__name': '计算机科学与技术', 'courses__name': 'Python开发'}, {'name': '史丹利@', 'clazzs__name': '计算机科学与技术', 'courses__name': 'Python开发'}, {'name': '李茂山@', 'clazzs__name': '计算机科学与技术', 'courses__name': 'Python开发'}, {'name': '李茂山@', 'clazzs__name': '计算机科学与技术', 'courses__name': 'Java开发'}, {'name': 'yangkai', 'clazzs__name': '计算机科学与技术', 'courses__name': None}, {'name': 'yangkai', 'clazzs__name': '计算机科学与技术', 'courses__name': None}, {'name': 'yangkai', 'clazzs__name': '计算机科学与技术', 'courses__name': None}, {'name': 'yangkai', 'clazzs__name': '计算机科学与技术', 'courses__name': 'Python开发'}, {'name': 'yangkai', 'clazzs__name': '计算机科学与技术', 'courses__name': 'Java开发'}, {'name': '李铁柱@', 'clazzs__name': '网络编程', 'courses__name': 'Python开发'}, {'name': '梁小龙@', 'clazzs__name': '网络编程', 'courses__name': 'Python开发'}, {'name': '百灵鸟@', 'clazzs__name': '信息技术', 'courses__name': 'Python开发'}, {'name': '吕小布@', 'clazzs__name': '信息技术', 'courses__name': 'Python开发'}] 分页查询
# limit 和 offset() 方法可以用于限制返回的结果数量和跳过指定数量的结果。 # 获取前5个用户 first_five_sutdents = await Student.all().limit(5) for student in first_five_sutdents: print(student.id, student.name) # 跳过前5个用户,再获取5个用户 next_five_students = await Student.all().offset(5).limit(5) for student in next_five_students: print(student.id, student.name) Trotoise ORM 修改数据
# 根据id修改学生数据 update_num = await Student.filter(id=1).update(name="赵不柱") # 批量更新 students = await Student.all() for student in students: student.name += "@" Trotoise ORM 删除数据
delete_num = await Student.filter(id=1).delete() Trotoise ORM 新增数据
# 单条新增 create_student_object = await Student.create(name="张无忌", pwd=123, sno=2009, clazzs_id=1) # 批量新增 create_student_object_list = await Student.bulk_create( [Student(name="批量新增名称"+str(i), pwd=123, sno=2009+i, clazzs_id=1) for i in range(3)] ) 