
阅读量:2
文章目录
🚋Python推导式

🚀一、列表推导式
🌈1. 了解推导式
列表推导式(List Comprehensions)是Python中一种简洁、高效的创建列表的方法。它允许你用一行代码代替多行循环结构来生成新的列表。列表推导式的语法结构紧凑,易于阅读,适用于基于现有列表或者其他可迭代对象生成新列表的场景,特别是当新列表的每个元素都是通过对原列表元素进行某种变换或过滤得到时。
基本语法结构如下:
[expression for item in iterable if condition] expression:是要应用到每个元素上的表达式,用于生成新列表中的元素。item:是每次循环迭代中的当前元素。iterable:是你要遍历的任何可迭代对象,如列表、元组、字符串等。if condition:是可选的筛选条件,只有当条件为真时,对应的元素才会被包含在新列表中。
[ 表达式 for 变量 in 序列 [if 条件] ] # 表达式 是需要进行的操作,可以包括各种数学运算、函数调用、字符串操作等; # 变量 是循环体内部的循环变量,每次循环从 序列 中取出一个元素; # 序列 是需要遍历的对象,可以是列表、元组、字符串等可迭代对象; # if 条件 是可选的条件判断语句,用于对元素进行筛选。 ❤️2. 实践
【示例1】:生成 0 到 9 的平方数列表
# 生成 0 到 9 的平方数列表: squares = [x**2 for x in range(10)] print(squares) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] 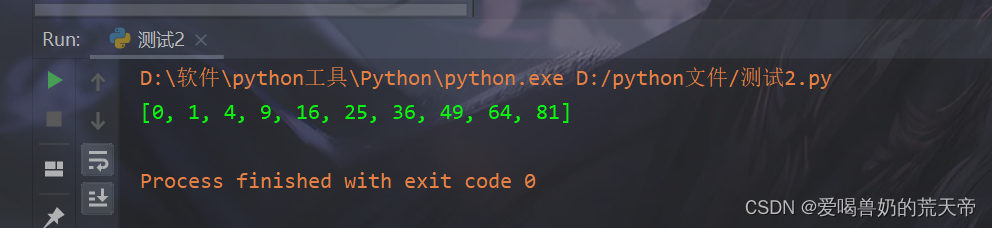
【示例2】:获取一个列表中所有偶数的平方
# 获取一个列表中所有偶数的平方 numbers = [1, 2, 3, 4, 5, 6] even_squares = [x**2 for x in numbers if x % 2 == 0] print(even_squares) # [4, 16, 36] 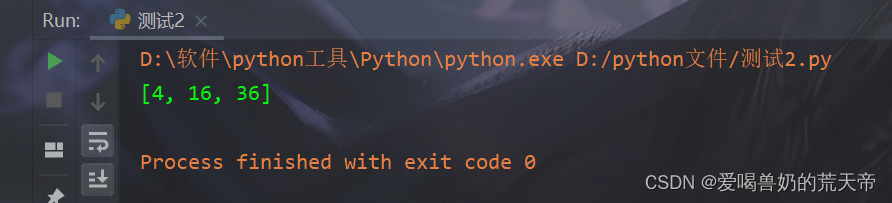
【示例3】:将一个句子拆分成单词列表
# 将一个句子拆分成单词列表 sentence = "This is a sample sentence." words = [word for word in sentence.split()] print(words) # ['This', 'is', 'a', 'sample', 'sentence.'] 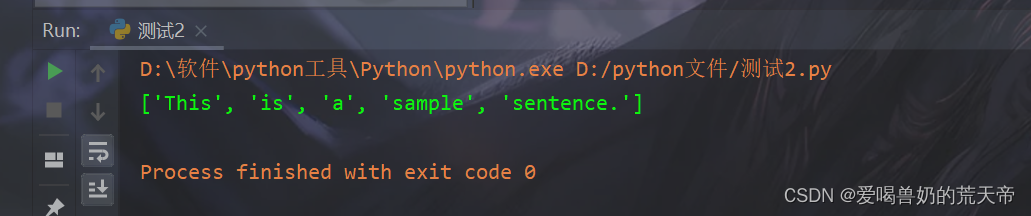
【示例4】:将data里面不与demo重复的数据进行添加进demo中
# 在多场景的情况下需要有特殊操作 demo = [1] data = [1, 2, 3, 4, 5, 6] # 将data里面不与demo重复的数据进行添加进demo中 [demo.append(i) for i in data if i not in demo] # 这里之所以不进行变量接收是因为数据是添加到了demo列表里面了 print(demo) 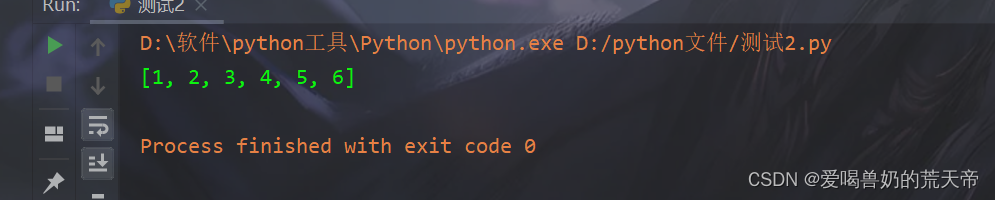
💥3. 总结
使用列表推导式可以方便地生成一个列表,并且能够对其中的元素进行变换和过滤。 它是一种简洁、灵活的编程技巧,常用于数据处理和清洗等场景。 在python代码执行的规则性能上面来看,其效率会更好一些;不过不建议处理过于复杂的结构,不利于代码维护及调试 元组推导式及集合推导式 的操作与列表推导式相同 🚀二、字典推导式
🌈1. 了解字典推导式
字典推导式(Dictionary Comprehensions)是Python中用于创建字典的快捷方式,其工作原理类似于列表推导式,但用于生成字典。字典推导式让你能够以一种简洁、易读的方式从可迭代对象中创建字典。其基本结构允许你快速地对数据进行转换或过滤,并形成键值对。
基本语法结构如下:
{key_expression: value_expression for item in iterable if condition} key_expression:为字典中每个键生成的表达式。value_expression:为字典中每个值生成的表达式。item:在迭代过程中当前的元素。iterable:要遍历的任何可迭代对象。if condition:可选条件,仅当条件为真时,当前元素才会被包含在新字典中。
# 基本语法 { 键表达式: 值表达式 for 变量 in 序列 [if 条件] } # 键表达式 和 值表达式 分别是需要进行的操作,可以包括各种数学运算、函数调用、字符串操作等; # 变量 是循环体内部的循环变量,每次循环从 序列 中取出一个元素; # 序列 是需要遍历的对象,可以是列表、元组、字符串等可迭代对象; if 条件 是可选的条件判断语句,用于对元素进行筛选。 ❤️2. 实践
【示例1】:将一个字典中所有键转换为大写
# 将一个字典中所有键转换为大写 d = {'name': 'Alice', 'age': 25, 'email': 'alice@example.com'} new_d = {key.upper(): value for key, value in d.items()} print(new_d) # {'NAME': 'Alice', 'AGE': 25, 'EMAIL': 'alice@example.com'} 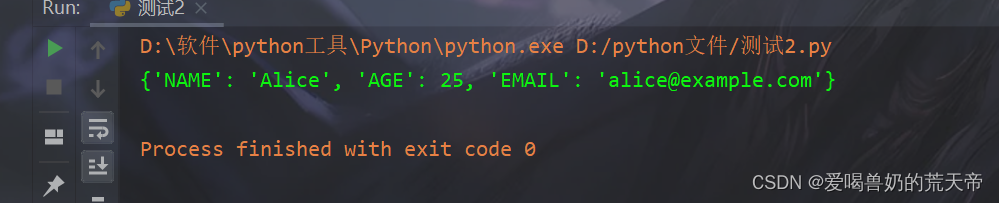
【示例2】:将一个列表中的元素映射为它们本身及其长度
# 将一个列表中的元素映射为它们本身及其长度 words = ['apple', 'banana', 'pear'] word_lengths = {word: len(word) for word in words} print(word_lengths) # {'apple': 5, 'banana': 6, 'pear': 4} 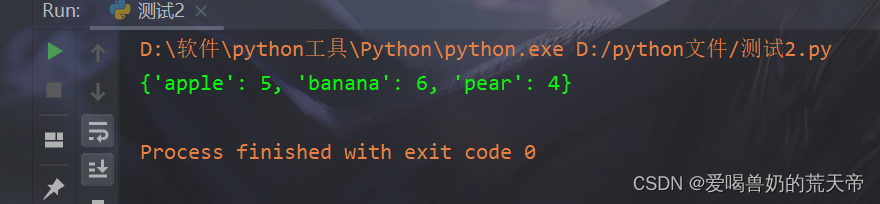
【示例3】:倒转一个字典中的键值对
# 倒转一个字典中的键值对 d = {1: 'A', 2: 'B', 3: 'C'} new_d = {value: key for key, value in d.items()} print(new_d) # {'A': 1, 'B': 2, 'C': 3} 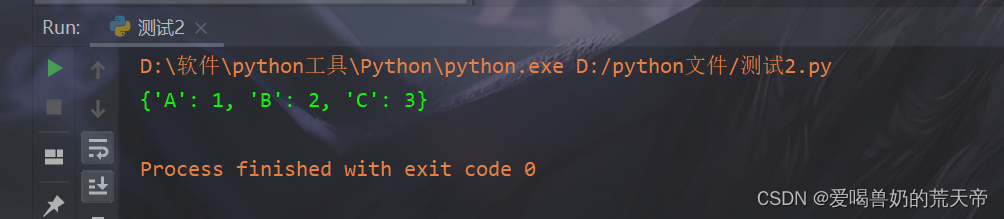
# 构建字典 key_1 = ['比赛', '友谊'] value_2 = [1, 2] # 字典推导式创建列表的话就只要一行搞定!!! dict_2 = {key_1[i]: value_2[i] for i in range(len(key_1))} print(dict_2) ------------------------------------------------------------------------------------------------- key_1 = ['快乐', '日拱一卒', 'hahha', 'dddd'] value = [18, 19] # dict1 = {key_1[i]: value[i] for i in range(len(key_1)) if len(key_1) == len(value)} num = len(key_1) - len(value) # 查看长度差 if num > 0: # 如果num大于0 说明键列表长度 大于 值列表长度 # 将能够配对部分进行构建字典 ---- range(len(key_1)-num) dict1 = {key_1[i]: value[i] for i in range(len(key_1)-num)} # 将没有值的键部分进行构建 # len(key_1)-a ---- 下标起始位 # len(key_1) -------- 结束位置 # [dict1.setdefault(key_1[i], None) for i in range(len(key_1)-a, len(key_1))] for i in range(len(key_1)-a, len(key_1)): dict1[key_1[i]] = None else: dict1 = {key_1[i]: value[i] for i in range(len(key_1))} print(dict1) 💥3. 总结
使用字典推导式可以方便地生成一个字典,并且能够对其中的元素进行变换和过滤。 它是一种简洁、灵活的编程技巧,常用于数据处理和清洗等场景。 🚀三、集合推导式
🌈1. 了解集合推导式
集合推导式(Set Comprehensions)是Python中用来创建集合(set)的一种高效、简洁的语法结构。集合内的元素是唯一的,不重复。集合推导式的语法形式类似于列表推导式,但用花括号{}替代了方括号[]。这使得它非常适合于从可迭代对象中过滤出唯一值或执行集合运算。
基本语法结构如下:
{expression for item in iterable if condition} expression: 表达式,计算结果作为集合中的元素。item: 迭代变量,代表iterable中的每个元素。iterable: 任何可迭代对象,如列表、元组、字符串等。condition(可选): 筛选条件,只有当条件为真时,相应的expression才会被包含进结果集合中。
❤️2. 实践
【示例1】:数字的唯一集合
numbers = [1, 2, 2, 3, 4, 4, 5] unique_numbers = {num for num in numbers} print(unique_numbers) 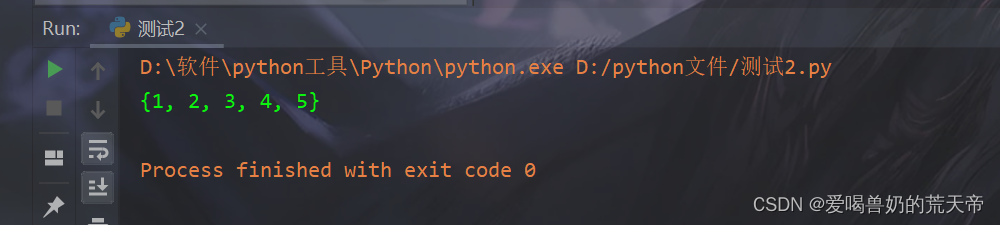
【示例2】:只想保留偶数
numbers = [1, 2, 2, 3, 4, 4, 5] even_numbers = {num for num in numbers if num % 2 == 0} print(even_numbers) 
💥3. 总结
集合推导式是Python中一种高级且紧凑的构造集合(set)的方式,它借鉴了列表推导式的概念,但生成的是一个不包含重复元素的集合。这种表达式非常适合于从可迭代对象中快速提取唯一值、执行条件过滤或转换数据,同时利用集合的特性来自动去除重复项。
🚀四、生成器推导式
🌈1. 了解生成器推导式
生成器推导式(Generator Expression)是Python中另一种高效的数据处理工具,它是列表推导式的lazy(惰性)版本,用于创建生成器对象。生成器不会立即计算出所有结果并存储在内存中,而是在每次迭代时按需生成下一个值,这对于处理大规模数据集时尤其有用,因为它可以显著节省内存。生成器推导式的语法结构与列表推导式相似,但使用圆括号而非方括号包围。
基本语法:
(expression for item in iterable if condition) expression:生成的每个项的计算表达式。item:在迭代期间考虑的当前项。iterable:任何可迭代的对象,如列表、元组、字符串或其它可迭代数据结构。condition(可选):一个过滤条件,仅当条件为真时,相应的项才被生成。
特点总结:
- 内存效率:生成器推导式在内存中不保存所有生成的值,而是在每次迭代时生成下一个值,这对于大数据处理至关重要。
- 惰性求值:直到调用(如通过迭代或转换为列表等操作),生成器才开始计算。
- 使用场景:适合处理大量数据流、实现无限序列或在内存限制下操作数据集。
- 功能强大:可以结合迭代、条件判断和函数调用,实现复杂的数据处理逻辑。
- 语法简洁:与列表推导式相似的紧凑语法,易于阅读和编写。
❤️2. 实践
【示例】:计算1到10的平方,但只包括偶数平方
# 计算1到10的平方,但只包括偶数平方 squares_gen = (x**2 for x in range(1, 11) if x % 2 == 0) for square in squares_gen: print(square, end=' ') 
(x**2 for x in range(1, 11) if x % 2 == 0)定义了一个生成器推导式,它会按需计算并产生满足条件的偶数平方值。每次循环迭代时,生成器推进到下一个值,直到所有的元素都已生成完毕。
💥3. 总结
生成器推导式是Python中一种高级构造,用于简洁地创建迭代器对象。它类似于列表推导式,但不立即计算所有元素而是生成一个惰性求值的迭代器。当需要处理大量数据或无限序列时,这种方式尤其有效,因为它可以逐个产生项目,仅在需要时计算,从而节省内存。通过使用圆括号而非方括号定义,生成器推导式允许程序在遍历数据集合的同时保持低内存占用,非常适合于数据流处理和高效循环遍历场景。
