
阅读量:1
公众号:尤而小屋
编辑:Peter
作者:Peter
大家好,我是Peter~
今天给大家介绍基于密度的聚类算法DBSCAN,包含:
- DBSCAN算法定义
- sklearn.cluster.DBSCAN参数详解
- DBSCAN聚类实战
- DBSCAN聚类效果评估
- DBSCAN聚类可视化
- DBSCAN算法优缺点总结
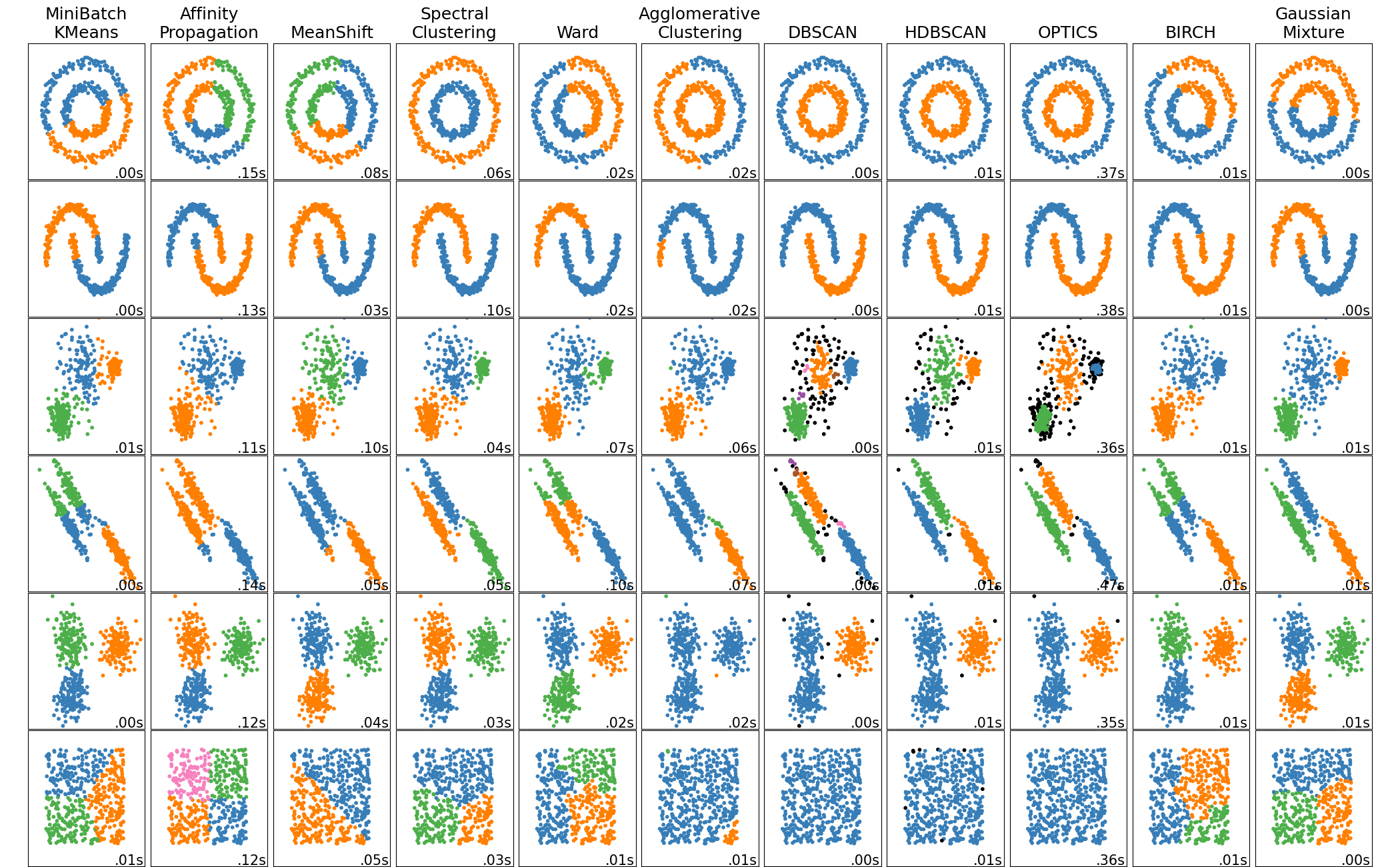
https://scikit-learn.org/stable/auto_examples/cluster/plot_cluster_comparison.html#sphx-glr-auto-examples-cluster-plot-cluster-comparison-py
1 DBSCAN定义
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,基于密度的带有噪声的空间聚类应用)是一种基于密度的聚类算法。
密度聚类算法一般假定类别是可以通过样本分布的紧密程度来决定。同一个类别中,样本之间是紧密相连的,也就说通过将紧密相连的样本划分为一类,这样就生成了一个聚类类别。
关于DBSCAN到底是如何实现聚类的?
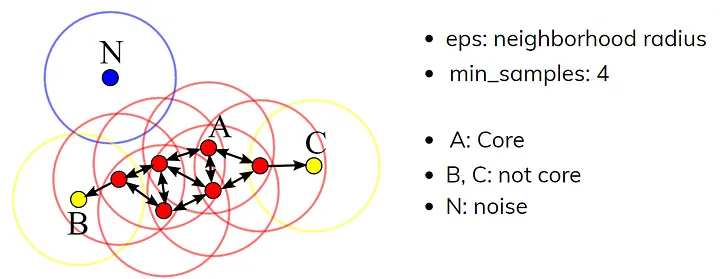
一个关键点:DBSCAN是基于一组邻域来描述样本集的紧密程度,参数 ( ϵ , M i n P t s ) (\epsilon,MinPts) (ϵ,MinPts)用来描述邻域的样本紧密程度。其中 ϵ \epsilon ϵ描述邻域半径,表示两个样本被视为相邻的最大距离;MinPts表示某一样本的距离为 ϵ \epsilon ϵ的邻域中样本个数的阈值。
DBSCAN的全称是Density-Based Spatial Clustering of Applications with Noise,中文意为“基于密度的带有噪声的空间聚类应用”。它能够通过样本点的密集区域识别出各个聚类簇,并且对噪声点具有很强的鲁棒性。以下是关于DBSCAN的相关介绍:
- 核心思想:DBSCAN的核心在于基于样本点的密度进行聚类,即通过找出样本空间中密集的区域来进行簇的划分。
- 算法参数:DBSCAN需要两个主要参数:邻域半径和最少点数目。只有当某点在其邻域内的点数大于或等于最少点数目时,该点才被视为核心点。
- 点类别:DBSCAN中的点分为三类:核心点、边界点和噪声点。核心点是指那些在邻域内具有足够多的点的对象,边界点则是那些邻近核心点但自身不是核心点的点,而噪声点则既不是核心点也不是边界点
- 点关系:DBSCAN中的点关系包括密度直达、密度可达和密度相连。这些关系定义了如何从一个核心点扩展至整个簇。
更多详细的定义请见:参考资料2
2 sklearn用法
2.1 参数
sklearn.cluster.DBSCAN的完整参数解释-参考资料1:
sklearn.cluster.DBSCAN( eps=0.5, # 邻域半径;它表示两个样本被视为相邻的最大距离。较大的值会导致更多的簇,较小的值会导致更少的簇 *, min_samples=5, # 形成簇所需的最小样本数 # euclidean-欧式距离;manhattan-曼哈顿距离;chebyshev-切比雪夫距离;minkowski-闵可夫斯基距离; # wminkowski-带权重闵可夫斯基距离;seuclidean-标准化欧式距离;mahalanobis-马氏距离 metric='euclidean', # 计算样本之间距离的度量方法; metric_params=None, # 度量方法的其他参数 algorithm='auto', # 用于计算最近邻的算法,默认'auto', ['auto'、'ball_tree'、'kd_tree'和'brute'] leaf_size=30, # 构建最近邻树时的叶子大小 p=None, # Minkowski距离的幂指数,默认值为None。当度量方法为'minkowski'时,该参数有效 n_jobs=None, # 并行计算的线程数,默认为None;若为-1,则使用所有可用的处理器 ) 其中最主要的参数eps(对应 ϵ \epsilon ϵ)和Min_samples(对应 M i n P t s MinPts MinPts)
2.2 属性
- core_sample_indices:核心店的index
- components:核心点的原始数据信息
- lables:每个样本的类别label,noise的label是-1
3 案例1
3.1 模拟数据
In [1]:
import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import DBSCAN from sklearn import metrics # 评估指标 import warnings warnings.filterwarnings("ignore") In [2]:
X = np.array([[1, 2], [2, 2], [2, 3], [3, 5], [9, 7], [8, 9], [45, 80], [30, 50] ]) 3.2 训练数据
In [3]:
# 邻域半径为3;最少样品数为2 clustering = DBSCAN(eps=3, min_samples=2).fit(X) 3.3 3个重要属性
In [4]:
clustering.labels_ # 1、查看标签属性 Out[4]:
array([ 0, 0, 0, 0, 1, 1, -1, -1], dtype=int64) 其中类别为-1的点表示的离群点(noise)
核心点的index;标签为-1的没有显示:
In [5]:
clustering.core_sample_indices_ # 2、核心点index Out[5]:
array([0, 1, 2, 3, 4, 5], dtype=int64) 核心点的原始数据信息:
In [6]:
clustering.components_ # 3、核心点原始数据 Out[6]:
array([[1, 2], [2, 2], [2, 3], [3, 5], [9, 7], [8, 9]]) 4 案例2
4.1 make_blobs用法
In [7]:
from sklearn.datasets import make_blobs # 生成聚类数据 from sklearn.preprocessing import StandardScaler # 数据标准化 make_blobs的用法
data, label = make_blobs( n_features=2, n_samples=100, centers=3, random_state=3, cluster_std=[0.8, 2, 5] ) - n_features:表示每一个样本有多少个特征值
- n_samples:表示样本数
- centers:聚类中心点个数,即label数
- random_state:随机种子,可以固定生成的数据
- cluster_std:设置每个类别的方差
4.2 模拟数据
In [8]:
centers = [[1, 1], [-1, -1], [1, -1]] # 设置中心 X, labels_true = make_blobs(n_samples=2000, # 样本数 centers=centers, # 中心点 cluster_std=0.4, # 类别的方差 random_state=0 # 随机种子 ) X = StandardScaler().fit_transform(X) X Out[8]:
array([[ 1.72569617, 1.28988372], [-1.28326016, 0.21227269], [-1.10466777, -0.69345567], ..., [ 0.41235673, 1.11593922], [ 1.03405507, 1.54909595], [-0.87265606, -1.06013063]]) In [9]:
labels_true[:10] Out[9]:
array([0, 1, 1, 2, 1, 2, 2, 2, 0, 0]) 4.3 原数据可视化
In [10]:
plt.scatter(X[:, 0], # 所有行第一列 X[:, 1]) # 所有行第二列 plt.show() 
4.4 训练数据
In [11]:
db = DBSCAN(eps=0.3, min_samples=100).fit(X) # -1是异常点noise labels = db.labels_ labels[:20] Out[11]:
array([-1, -1, 0, 2, 0, 2, 2, 2, 1, -1, -1, 0, 2, 1, 0, 2, 2, 1, 0, 1], dtype=int64) In [12]:
n_clusters = len(set(labels)) - (1 if -1 in labels else 0) # n_clusters = len(set(labels)) - 1 print(f"DBSCAN聚类簇的数量:{n_clusters}") DBSCAN聚类簇的数量:3 In [13]:
# 离群点的数量 n_noise = list(labels).count(-1) print(f"DBSCAN聚类离群点的数量:{n_noise}") DBSCAN聚类离群点的数量:332 4.5 聚类评估metrics
In [14]:
# 1、同质性:表示每个簇内样本的相似度;值接近1则表示簇内样本越相似 print(f"Homogeneity: {metrics.homogeneity_score(labels_true, labels):.3f}") # 2、完整性:表示每个簇内的样本是否被完整地划分到某个簇中。值越接近1,表示簇内样本越完整。 print(f"Completeness: {metrics.completeness_score(labels_true, labels):.3f}") # 3、V-measure指标,是同质性和完整性的加权平均。值越接近1,表示聚类效果越好。 print(f"V-measure: {metrics.v_measure_score(labels_true, labels):.3f}") # 4、调整后的Rand指数:用于衡量两个数据分割之间的相似度。值越接近1,表示两个分割越相似。 print(f"Adjusted Rand Index: {metrics.adjusted_rand_score(labels_true, labels):.3f}") # 5、调整后的互信息(Adjusted Mutual Information):用于衡量两个数据分割之间的互信息量。值越大,表示两个分割越相似。 print("Adjusted Mutual Information:" f" {metrics.adjusted_mutual_info_score(labels_true, labels):.3f}" ) # 6、轮廓系数(Silhouette Coefficient):用于衡量聚类结果的质量。值越接近1,表示聚类效果越好;值越接近-1,表示聚类效果越差。 print(f"Silhouette Coefficient: {metrics.silhouette_score(X, labels):.3f}") 具体结果为:
Homogeneity: 0.827 Completeness: 0.666 V-measure: 0.738 Adjusted Rand Index: 0.733 Adjusted Mutual Information: 0.737 Silhouette Coefficient: 0.489 4.6 聚类可视化
In [15]:
unique_labels = set(labels) # 唯一值 core_samples_mask = np.zeros_like(labels, dtype=bool) # 核心点T-F core_samples_mask[:20] # 全部为False Out[15]:
array([False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False]) In [16]:
db.core_sample_indices_[:20] # 核心点索引号 Out[16]:
array([ 2, 4, 8, 11, 12, 13, 14, 15, 16, 18, 22, 31, 32, 34, 35, 36, 38, 39, 40, 44], dtype=int64) In [17]:
core_samples_mask[db.core_sample_indices_] = True # 核心点设置为True core_samples_mask[:20] Out[17]:
array([False, False, True, False, True, False, False, False, True, False, False, True, True, True, True, True, True, False, True, False]) 写法1:
In [18]:
# # colors = ['black','red','green','blue'] # colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))] # print(colors) # for k, col in zip(unique_labels, colors): # color=colors[k+1] # # 类别k的mask矩阵 # class_member_mask = (labels == k) # xy = X[class_member_mask & core_samples_mask] # 核心 # plt.scatter( # xy[:, 0], # xy[:, 1], # s=10, # c=color) # # 绘制非核心点 # xy = X[class_member_mask & ~core_samples_mask] # 非核心 # plt.scatter( # xy[:, 0], # xy[:, 1], # s=60, # c=color) # plt.title(f"Estimated number of clusters: {n_clusters}") # plt.show() 写法2:
In [19]:
colors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))] for k, col in zip(unique_labels, colors): if k == -1: # noise点为黑色 col = [0, 0, 0, 1] class_member_mask = labels == k xy = X[class_member_mask & core_samples_mask] plt.plot( xy[:, 0], xy[:, 1], "o", markerfacecolor=tuple(col), markeredgecolor="k", markersize=14, ) xy = X[class_member_mask & ~core_samples_mask] plt.plot( xy[:, 0], xy[:, 1], "o", markerfacecolor=tuple(col), markeredgecolor="k", markersize=6, ) plt.title(f"Estimated number of clusters: {n_clusters}") plt.show() 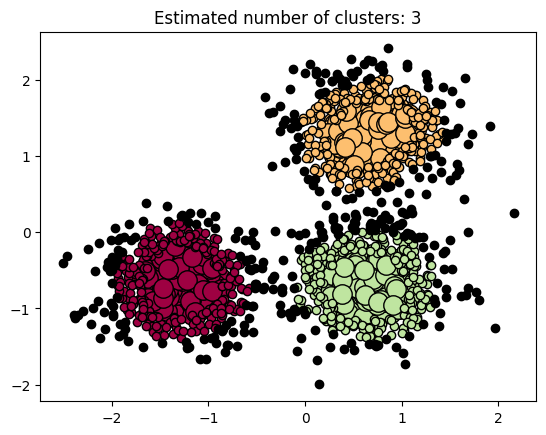
5 DBSCAN特点
总结下DBSCAN聚类算法的优缺点:
5.1 优点
- 能够处理任意形状和大小的簇:由于DBSCAN是基于密度的聚类算法,它能够识别并形成任意形状的簇。这对于具有复杂分布特征的数据集来说尤其适用。
- 对噪声不敏感:DBSCAN算法在设计时考虑到了噪声点的影响,所以对于那些位于低密度区域的噪声点,算法能够将它们排除在聚类之外(类别为-1的点)
- 无需事先指定簇的数量:不像K-means需要指定聚类的簇数,DBSCAN可以自动找出数据集中的簇数量
- 可以发现数据集中的异常点:通过标记那些不属于任何簇的异常点,DBSCAN可以帮助识别数据集中的异常或离群点,常用于异常点检测。
5.2 缺点
- 对输入参数非常敏感:DBSCAN的两个主要参数(邻域半径Eps和最少点数MinPts),对聚类的结果影响巨大。稍微改变这些参数就可能导致聚类结果的显著不同;
- 在高维数据集上表现不佳:随着维度的增加,数据的稀疏性问题会变得更加严重,导致基于密度的聚类方法难以有效区分簇和噪声
- 计算复杂度高:特别是在大数据集上,因为每个点的邻域都需要被考虑和计算,这会导致计算量的大幅增加
- 对于密度不均匀的数据集表现不佳:如果一个数据集中的密度差异很大,使用全局的密度参数可能会导致无法正确发现某些密度较低区域的簇
总的来说,DBSCAN算法在处理具有不规则分布、含噪声的数据集中表现出了显著的优势。它能自动确定簇的数量并发现数据集中的异常值。然而,这种算法对参数的选择非常敏感,且在高维数据集和密度不均匀的数据集上的应用受到了限制
6 参考资料
1、sklearn的官网学习地址:
- https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html
- https://scikit-learn.org/dev/auto_examples/cluster/plot_dbscan.html#sphx-glr-auto-examples-cluster-plot-dbscan-py
- https://scikit-learn.org/dev/auto_examples/cluster/plot_cluster_comparison.html#sphx-glr-auto-examples-cluster-plot-cluster-comparison-py
2、刘建平老师博客:
- https://www.cnblogs.com/pinard/p/6208966.html
- https://www.cnblogs.com/pinard/p/6217852.html
最后介绍一个DBSCAN聚类可视化的网站:https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
