
阅读量:4

摘要
回答需要做出潜在决策的复杂问题是一项具有挑战性的任务,尤其是在监督有限的情况下。
最近的研究利用大型语言模型(LMs)的能力,在少量样本设置中通过展示如何在单次处理复杂问题的同时输出中间推理过程,来执行复杂的问答任务。我们引入了“连续提示”(Successive Prompting)方法,在这个方法中,我们将复杂任务迭代地分解为简单任务,解决它,然后重复这个过程直到得到最终解决方案。连续提示将分解复杂问题的监督与回答简单问题的监督分离,使我们能够(1)在每个推理步骤都有多次机会查询上下文示例,(2)将问题分解与问题回答分开学习,包括使用合成数据,(3)在大型LM表现不佳的推理步骤中使用定制的(微调的)组件。这种中间监督通常是手动编写的,收集起来可能成本高昂。我们介绍了一种生成合成数据集的方法,该方法可以用来启动模型分解和回答中间问题的能力。我们的最佳模型(使用连续提示)在相同监督下,与最新模型相比,在DROP数据集的少量样本版本上实现了约5%的绝对F1分数提升。
1 引言
组合式阅读理解数据集,如HotpotQA(Yang等人,2018年)和DROP(Dua等人,2019年),激发了一系列模型架构的学习,这些模型能够在最终答案的弱监督下回答复杂问题。最近的一个方向是利用大型语言模型(LMs)通过在回答问题之前生成潜在推理步骤,用极少的示例来解决组合式任务(Wei等人,2022年;Nye等人,2021年;Karpas等人,2022年)。给定一个复杂问题,这种方法首先从(问题,推理,答案)三元组的数据集中找到最近的训练示例,然后将它们连接起来为LM创建一个输入。然后,大型LM被这个输入提示,以生成所需的中间推理步骤,同时在单次处理中回答复杂问题。
虽然这个方法很有前景,但它通过将问题分解的监督与执行中间步骤的监督耦合在一起,丢弃了之前针对此任务的许多方法的优点(Khot等人,2021年;Karpas等人,2022年)。此外,其非模块化的特性不允许在符号推理引擎表现优于LM的情况下使用替代的符号推理引擎。另外,模型只接触到基于它们与复杂问题相似性选择的单一组上下文示例,这些示例可能不包含执行所需中间步骤的最佳监督。
我们提出“连续提示”,我们迭代地将复杂问题分解为下一个要回答的简单问题,回答它,然后重复,直到复杂问题得到回答(图1)。执行这些步骤时,每个步骤都对LM进行单独的查询。由于分解和回答步骤是分开执行的,我们可以解耦每个步骤的监督,提供两个主要的好处。首先,在进行上下文学习时,我们有多个机会选择不同的上下文示例,这些示例可以针对正在执行的特定分解或回答步骤进行定制,而不是仅基于复杂问题选择一组示例。其次,在微调时(有或没有上下文示例(Chen et al, 2022)),我们可以为每个步骤独立提供训练示例,因此模型一次只需要学习执行一个步骤。

图1:在DROP示例上,连续提示的问题分解和问题回答阶段使用的示例分解。该模型在预测要问的简单问题和回答简单问题之间迭代。
这种解耦还允许我们明智地将合成数据注入到学习过程中,例如,帮助模型回答以前无法回答的特定类型的简单问题,或者它不知道如何分解的新推理组合。因为步骤是分开的,我们可以隔离模型故障并开发综合方法来填补空白。它还允许我们用其他专用组件替换LM,以便在适当的时候执行符号推理(Khot等人,2021;Segal等人,2020;Jin et al, 2021)。
我们使用DROP数据集的几个示例变体(Dua等人,2019)演示了连续提示的效用,选择了300个示例进行训练(微调或上下文示例选择)。这300个例子是用简单的QA对作为分解手工注释的。
我们发现所有模型的性能都很低,所以我们开发了一个合成数据生成器,通过对半结构化维基百科表的分解来生成复杂的问题(Yoran et al, 2021)。这些综合数据不仅提供了复杂问题的监督,还提供了中间步骤的监督。我们用300个(复杂的)训练样本和它们从DROP中分解出来的数据来增强这个数据。在这个少样本设置中,我们表现最好的连续提示模型显示,与最先进的DROP模型相比,F1提高了~ 5%。代码和数据可在https://github.com/dDua/succesive_prompting上获得。
2 分解复杂问题
组合式问题回答的目标是在一个段落p的上下文中回答一个复杂问题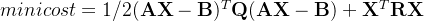 (共同表示为x),通过推理潜在的顺序决策来达到最终答案y。已经提出了许多模型来完成这个任务,它们在不同的监督程度和可解释性下进行操作。在Chain-of-Thought(CoT,Wei等人,2022年)这样的提示方法中,潜在的步骤是被监督的、可解释的句子;在其他模型中,这些潜在步骤可能是一个程序(Gupta等人,2020年;Chen等人,2020年)或者甚至只是模型中的(无监督)隐藏状态(Segal等人,2020年;Andor等人,2019年)。
(共同表示为x),通过推理潜在的顺序决策来达到最终答案y。已经提出了许多模型来完成这个任务,它们在不同的监督程度和可解释性下进行操作。在Chain-of-Thought(CoT,Wei等人,2022年)这样的提示方法中,潜在的步骤是被监督的、可解释的句子;在其他模型中,这些潜在步骤可能是一个程序(Gupta等人,2020年;Chen等人,2020年)或者甚至只是模型中的(无监督)隐藏状态(Segal等人,2020年;Andor等人,2019年)。
我们专注于那些接收上下文示例并产生一个离散的、用语言编码的z的模型,其中CoT是主要的示例。我们给出了CoT的一般形式,给定一个输入x,一个语言模型编码器,以及从索引查询得到的N个上下文示例——每个示例都包含一个三元组,包括段落与复杂问题(),潜在步骤()和最终答案()——如下所示:
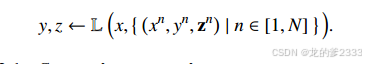
2.1 连续提示
在连续提示(Successive Prompting)中,我们将每个潜在步骤表示为简单问题与答案的 pair, (见图1中的示例QA对),这与CoT不同,CoT将每个潜在步骤表示为一个陈述句。此外,CoT仅查询索引一次以获取上下文示例,并提示语言模型L生成输出。然而,在连续提示中,我们将z分解为多个问答步骤,这给了我们多次机会来提示L,每次步骤可能使用更符合简单问题的不同上下文示例。它还允许我们在给定中间状态zk的情况下重新编码上下文,这在某些需要长链引用的问题中可能很有用(例如,图3中的排序-计数示例)。我们可以将连续提示的一般形式写成如下:
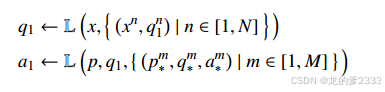
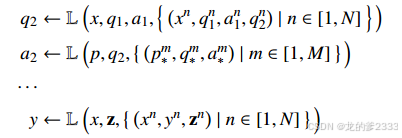
这种一般形式的模型输出有三种:中间问题、中间答案和最终答案y。我们将第一类输出称为问题分解(QD),第二类输出称为问答(QA)。我们将最终答案预测作为问题分解的一种特殊情况,其中模型决定不需要再进行分解并输出最终答案,因此我们在问题分解和问题回答之间迭代交替,直到模型终止。
2.2 训练范式
到目前为止,我们已经描述了在只给出上下文示例的设置中的连续提示,因此没有执行模型训练。然而,连续提示也可以与模型微调结合使用,其中每个中间输出都被视为l的训练示例。在本节中,我们首先描述如何在每个步骤中选择上下文示例,然后详细说明如何将这些示例用于模型微调。
in-context Learning 在in-context Learning过程中,少量的训练样例在测试输入之前直接提供给一个大的LM。这些例子是根据它们与测试输入的相似性从索引中选择出来的。对于连续提示,我们创建了两个索引:ID,用于查找QD的相关演示,IA,用于查找QA的相关演示。索引ID在每个步骤k处包含部分分解的链,展示了训练数据中每个复杂问题将产生的下一个问题qk。索引IA包含来自所有复杂问题的训练数据中的所有简单QA对。
在问题分解(QD)阶段,索引ID被查询,以复杂测试问题q和当前步骤数k为条件,选择关于如何为保留示例生成下一个问题的演示。在问答(QA)阶段,索引IA被查询,以在QD阶段生成的简单问题qk为条件,选择相关的简单QA对。图2展示了如何在每个阶段逐步执行上下文学习,直到QD输出特殊短语“没有更多问题要问”,以及最终答案。
连续提示允许问答阶段访问从复杂问题派生的简单问题,这些问题通过Chain-of-Thought提示是无法检索到的,因为从表面上看,它们与保留的复杂问题不相似,尽管它们共享相似的子问题。
模型微调 对于模型微调,我们使用基于T5(Raffel等人,2020年)的序列到序列模型。这类模型通常在多任务设置中使用控制代码进行训练(Ma等人,2021年;Rajagopal等人,2022年),以在共享模型参数的QD和QA任务之间切换。我们调整并扩展了文本模块化网络(TMNs,Khot等人,2021年)引入的控制代码,以用于我们的合成数据的训练。TMNs在它们可以处理的操作上有限制,因为它们不会超出第一阶推理。我们使用合成生成的数据,这使我们能够处理DROP中的高阶推理问题。因为我们是在微调模型,所以我们可以使用特殊令牌来表示问题分解和其他分隔符,而不是图2中显示的自然语言提示,尽管内容是相同的。每个步骤使用的具体令牌列表见附录A。
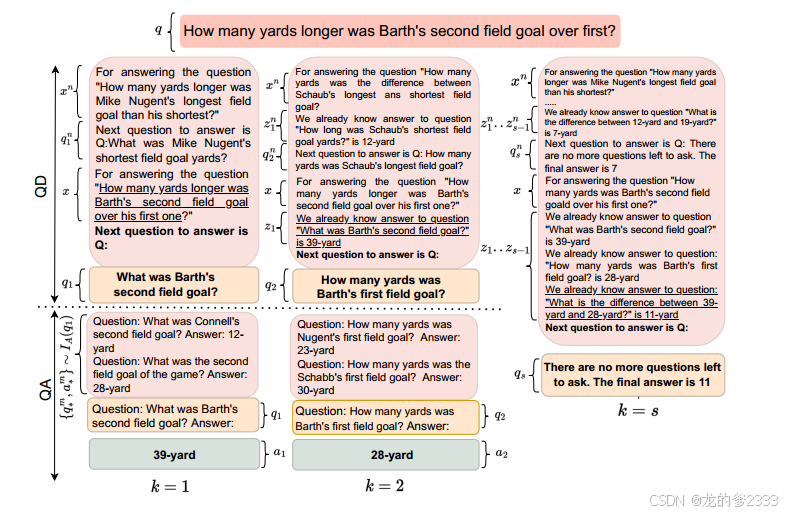
图2:连续提示与上下文学习的演示。模型对选定的监督示例和前置上下文段落(为简化说明省略)的待答复杂问题进行编码,分别在QD和QA阶段生成问题和答案。在微调过程中,对于QD和QA模型的学习,只采用训练监督的方式进行。
专门模块 连续提示还允许我们使用专门的子模块来解决不同的QA任务,因为我们不再以端到端的方式执行QD和QA。对于语言模型来说,解决计数、求差、排序等算术运算可能具有挑战性。因此,我们遵循Khot等人(2021年)的方法,构建了一个简单的数学子模块用于QA,该子模块解析生成的简单问题以确定符号操作类型及其参数,并以确定性方式执行它们。如果生成的简单问题无法被解析为数学运算,我们应用语言模型来解决它。
3 合成数据集
任何提示LMs生成中间推理步骤以回答复杂问题的方法都需要对这些推理步骤进行一定程度的监督。这种注释的收集成本很高,而且通常需要专业知识。
以前的工作通常依赖于少量手工编写的示例分解。我们发现,如此小的集合导致数据集(如DROP)的性能非常差,即使对于大型模型也是如此。
为了缓解这些数据问题,我们提出了一种使用易于解析的半结构化数据综合生成复杂问题及其分解的方法。我们表明,我们可以用这个域外的、综合生成的数据来引导模型学习,这样在有限的域内监督下进行微调时,它可以更好地适应。
生成过程 受Yoran等人(2021年)的启发,我们使用了英语维基百科中丰富的表格中的半结构化数据。我们使用精心设计的模板将表格中的行转换成段落。我们使用单列标题来创建第一阶简单问题,并组合多列来创建更高阶的复杂问题。我们为10种简单操作合成了数据:COUNT,TOP(k),BOTTOM(k),FILTER,SUM,COMPARISON,DIFFERENCE,NEGATION,GATHER和INTERSECTION。
我们在可能的情况下生成第一阶操作的更高阶组合。图3展示了使用表1作为上下文,将原子操作COUNT与一些其他简单操作组合成更高阶组合的示例。所有分解的完整列表在附录A中提供。根据模型的不同,我们使用算术操作的符号版本或自然语言版本。如果我们使用LM来执行算术操作,我们输出自然语言;如果我们使用独立的符号推理引擎,我们输出符号操作。我们生成了大约141K个总复杂问题,这导致了525K个QD示例和257K个QA示例。更多数据集统计数据请参见附录A。
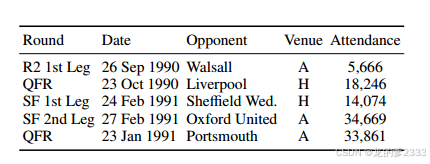
表1:来自Wikipedia的示例表,其中行成为句子,列用于生成问题(用作图3的上下文)。
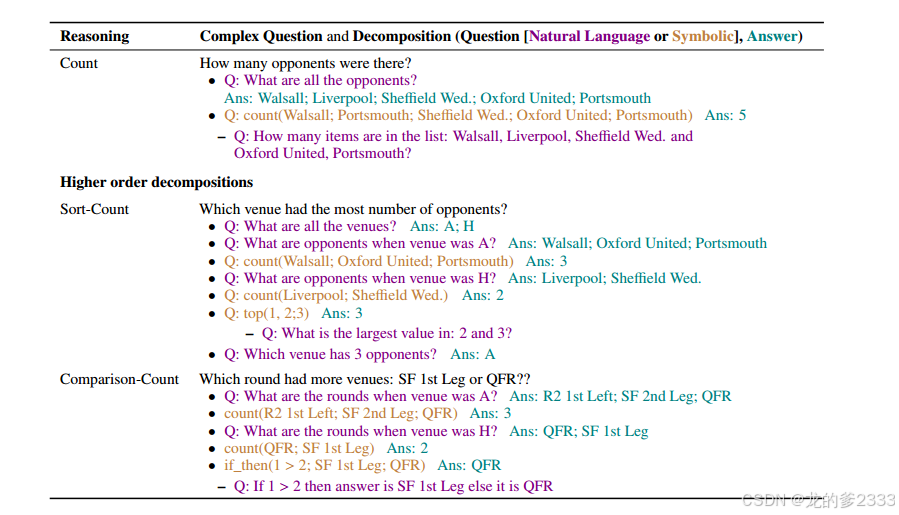
图3:COUNT操作的示例及其一些高阶组合,以及复杂问题的自然语言和符号分解。在符号操作的第一个实例下面,我们显示了其相应的自然语言版本。关于用于生成上下文和问题的原始表,请参见表1。
4 实验与结果
DROP数据集包含各种不均匀分布的推理组合。为了获得DROP示例的公平表示,我们首先使用在QQP数据集上训练的句子嵌入方法嵌入示例(Reimers and Gurevych, 2019)。然后,我们使用余弦相似度为每个训练示例获得前50个最近邻问题。然后使用每个训练问题与其相邻问题之间的连接图,通过顶点覆盖算法获得覆盖大部分训练数据的300个问题。我们用与合成数据相同的格式用分解的QA对手动注释这300个示例(图3)。对于合成示例,由于我们知道推理类型,因此我们统一地从每个推理类型中采样示例演示。
4.1 上下文学习
设置 我们使用faiss1索引与基于QQP的句子嵌入(Reimers和Gurevych, 2019)来索引所有问题。我们使用GPT-J (6B),这是我们可以使用的最大免费模型,其提示包含6个上下文示例。
结果 在表2中,我们比较了没有任何提示(标准)、思维链提示(CoT)和连续提示的语言模型的性能。我们观察到,当只有合成数据可用时,连续提示的性能比CoT好3.5%,当有来自DROP的合成数据和300条注释时,连续提示的性能比CoT好4.3%。开发集(Synthetic+DROP)上最好的连续提示版本的测试集性能为30.6% F1。我们还执行了一个消蚀,其中符号计算器被语言模型取代,并观察到性能下降了1.5% F1。这进一步表明,模块化方法优于试图解决所有任务的单个模型。
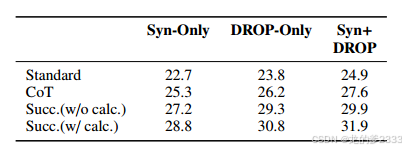
表2:有和没有域内注释的DROP开发集上的上下文提示的F1性能。
4.2 模型微调
我们采用了一个基于T5-large版本UnifiedQA (Khashabi et al, 2020)的共享问题分解(QD)和回答模型(QA),以多任务方式训练。我们使用附录A中描述的格式来提示UnifiedQA。对于符号问题,我们使用一个简单的计算器来解析生成问题中的运算符和参数,并对检测到的参数执行离散运算符。
为了防止模型学习不正确的步骤,我们使用对比估计(Smith and Eisner, 2005)。特别是,在生成输出序列(简单的问题或答案)时,我们首先训练具有交叉熵损失的两个时代的模型。然后,我们通过添加一个辅助损失项来继续训练,这增加了中间子问题产生正确子答案的可能性,而代价是不产生正确子答案(Dua等人,2021)。我们在每一步取样最多3个负样本。我们使用HuggingFace变压器3来训练我们的模型,学习率为5e-5,最大输入长度为768。
由于维基百科中存在的上下文表类型的差异,合成数据集分布在不同的推理类型之间并不均匀。为了对不同推理类型的问题进行平衡表示,我们采用动态抽样(Gottumukkala等人,2020),在每个epoch的开始,我们从所有推理类型中选择80,000个实例,按照当前性能相对于前一个epoch在helout合成数据上的下降比例。对于第一个历元,我们按原始比例采样每个推理类型的大小。在推理过程中,我们使用大小为5的束搜索来生成分解,在QD和QA阶段之间切换,直到QD达到分解的结束(“EOQ”)或我们设置为10的最大步数。
我们比较了许多不同的基线,有象征性的,也有非象征性的。作为非符号基线,我们使用UnifiedQA (Khashabi等人,2020)和PReasM (Yoran等人,2021),前者是在许多现有的问答数据集上进行预训练的,后者是在合成生成的组合QA对上进行预训练的。我们还包括一个具有符号成分的基线,TASE (Segal et al, 2020)。
该模型(以及其他类似模型)(Jin et al, 2021;Andor等人,2019))能够执行连续和离散运算的组合,这对于DROP至关重要。TASE不需要用特定的语法表达分解,可以使用自然语言。我们选择这个模型是因为它接近完整DROP数据集的最新状态,并且有公开可用的代码。
在表3中,我们使用DROP开发集来比较不同符号和非符号模型在三种设置下的性能:(1)不使用来自DROP (0-shot)的训练数据,(2)仅使用来自300个DROP示例的问答监督,(3)同时使用300个DROP示例的问答监督和分解。在这些设置中,我们可以使用或不使用我们生成的合成数据来训练模型。

表3:DROP开发集上各种模型架构的F1性能,在合成数据上进行预训练,并使用300个DROP示例进一步微调。
我们观察到我们的域外合成数据普遍提高了模型性能,并且在TASE中改进最为明显,接近20%的绝对改进。在没有合成数据的情况下,PReasM是性能最好的基准,但是当有合成数据可用时,TASE会超过PReasM。此外,毫不奇怪的是,从0-shot到复杂QA对再到分解,增加监督的数量普遍提高了模型的性能。
最后,我们的方法,即一个结合了符号推理引擎的微调连续提示模型,取得了最佳性能,相比于具有相似监督的最新模型,即TASE+Synthetic w/ decomp,F1分数提高了5.4。我们遵循标准做法,只对我们的最终最佳表现模型(SP w/ decomp)使用测试集。我们观察到,我们的最佳模型在测试集上的性能为50.2 F1,比具有相似监督的最新模型(45.1 F1)高出5.1% F1。
总体而言,学习将复杂问题分解为简单QA对的方法可以很好地适应新领域的复杂问题,分解的域内监督很少(SP w/ decomp: 51.3 F1)或没有(SP 0-shot: 49.8)。如果我们有有限的复杂QA监督(没有任何分解),不可解释的符号模型会产生最佳性能(TASE +合成w/o分解:44.1)。这有两个原因。
首先,这样的模型可以捕获特定领域的答案先验,这可能会导致良好的保持性能(Dua等人,2020;Agrawal et al, 2018)。其次,根据上下文,有时可能无法直接将复杂问题分解为QA对。
4.3 上下文vs微调
为了理解连续提示与上下文学习和微调之间的性能差距,我们对QD和QA模块的上下文和微调版本进行了精简。我们观察到,上下文学习不能很好地回答导致答案列表的简单问题——这对DROP来说尤其重要,因为符号聚合通常应用于答案列表。在使用微调QA模型时,我们看到在使用上下文QD模型时F1的改进约为10%。此外,由于最终答案的性能取决于QA模型的性能,使用更好的QD模型(微调)对整体性能没有多大帮助,除非QA模型可以处理由QD模型产生的分解。
4.4 定性举例
为了评估分解的QA对的正确性,我们使用上下文(DROP-only)学习和模型微调(几次)手动分析开发集中的预测子集。我们通过随机抽样50个正确的预测来确定不正确的分解产生正确答案的频率。我们观察到,QD阶段在上下文中的准确性为88%,在微调模型中为96%。错误的分解主要是因为分解后的问题与原问题相同。例如,“谁投了最长的投篮?”如果文章中只提到一个投篮得分,有时不需要分解问题就可以正确回答。
我们还抽样了50个不正确的预测,以确定在上下文中和微调设置中不正确预测的原因。我们观察到,最终的预测是不正确的,原因主要有三种:不正确的QA模型预测、不正确的下一个问题预测(QD)和超出范围的推理类型。在上下文中和微调时,QA模型对简单问题的输出错误答案分别为40%和22%。第二类错误是由于不正确的分解造成的,在上下文中和微调中都有30%的错误发生。最后一类错误,由于合成生成的注释没有涵盖作文问题,发生28%(在上下文中)和46%(微调)的时间。
在图4中,我们展示了一些正确和错误预测的例子,并指出了连续提示的优点和缺点。连续提示的主要优势在于,通过分解问题,我们能够更好地监督QA。因此,它能够在回答“两队在上半场踢进了多少球?”的问题时正确识别上半场的进球,而不像CoT会返回整场比赛的进球。
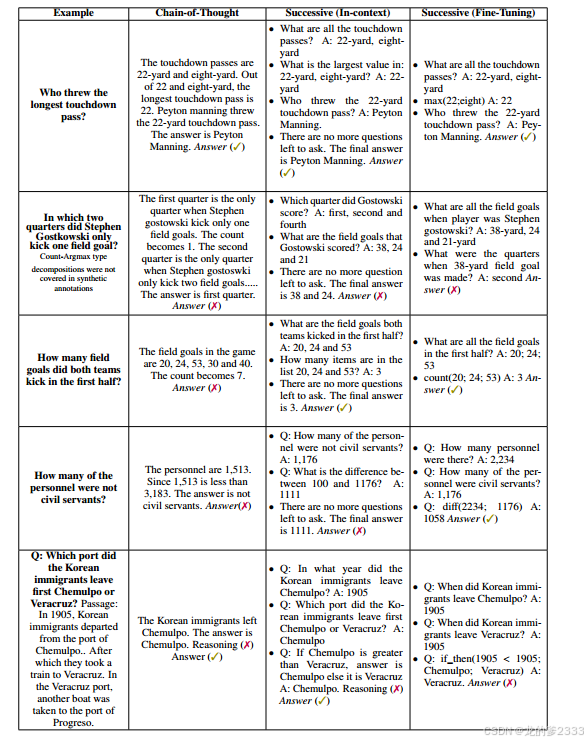
图4:生成的分解描述了连续提示的优点和缺点。
与微调(无论提示类型如何)相比,上下文学习的局限性之一是,它只根据问题选择示例,而忽略了上下文。例如,DROP有这样的问题:“以百分比计算,有多少人不是德国人?,我们首先需要回答“有多少人是德国人,以百分比计算?”,然后执行一个否定运算(即从100中减去)。单词“not”会影响示例查找以选择包含否定的分解,即使要回答的问题需要不同的操作。
连续提示的一个局限性是,有时分解问题具有挑战性,尤其是当问题涉及从段落中隐含推理时。例如,对于“韩国移民是先离开仁川港还是韦拉克鲁斯港?”这个问题,很难从句子“之后他们乘坐火车去了韦拉克鲁斯”中明确地定义一个比较风格的分解。
5 相关工作
提示是作为一种测试大型语言模型推理能力的方法而引入的(Brown et al, 2020)。在后续作品中(Schick, 2022;Chowdhery等人,2022;Marasovic et al ', 2021)提示技术被用作监督模型决策的机制,很少有演示作为条件反射上下文来指导其对未知示例的预测。像思维链推理(Wei et al, 2022;Zelikman等人,2022)特别关注作文问题,他们提供了一个推理链作为演示。在并行工作中,最小到最多提示(Zhou et al ., 2022)采用了与我们类似的观点,将问题分解为子问题。然而,在连续提示中,问题分解和回答阶段是交错的,不像最小到最大,问题首先被分解成子问题,然后按顺序执行。在我们的方法中,下一个问题预测可以访问之前回答的子问题,这对于需要长链引用的问题很有用。
其他同时期作品(Press et al, 2022;Khot等人,2022)使用非常大的语言模型(超过我们使用的两倍),并显示出更好的少量泛化。Perez等人(2021)的工作表明,拥有正确的上下文示例对于下游性能的重要性,从而导致学习检索相关上下文示例的工作(Rubin等人,2021)。大多数非符号方法是在大量问答数据上训练的序列到序列模型(Khashabi et al, 2020;Yoran et al, 2021)。
像神经模块网络这样的方法将复杂的问题解析成预先指定的语法,并学习神经组件来处理符号数学运算(Gupta等人,2020;Chen et al ., 2020;Nye et al, 2021),递归执行。然而,DROP上最先进的模型使用基于bert的上下文模型和执行离散操作的计算器的组合(Andor等人,2019;Segal等人,2020;Hu et al, 2019)。
文本模块化网络(Khot等人,2021)和MRKL (Karpas等人,2022)等工作与我们的工作最接近。然而,它们在能够回答的简单问题类型(仅限单跨度)和推理的复杂性(仅限单顺序)方面受到限制。此外,tmn使用分类器对生成的链模块进行评分并过滤掉不正确的问题分解,而我们使用对比估计来学习更好的问题分解器,因此不需要链评分器。
6 结论
我们提出了一种将复杂问题依次分解为简单的QA对的方法,这种方法允许模块化的QD和QA系统可以独立训练和查询。在进行上下文学习时,我们发现连续提示比思维链提示提高了4.6 F1。当将上下文中的QA模块替换为一个经过微调的模块时,我们进一步将整体性能提高了9.5 F1,该模块擅长处理列表类型的问题。
我们相信,分解任务并将任务委托给最合适的模型的模块化系统,无论是大型LM还是定制组件,在解决复杂任务时都比试图让大型LM自己解决整个任务更有效。连续提示显示了完成分解和委托的一种方式。
