
阅读量:6
文章目录
前提回顾
前面以一种优雅的形式实现了一个翻译助手。但是有一个非常大的问题,里面的案例都是中文到英文的案例,如果用户定义的翻译助手是日文到英文,那这个案例就不起作用了,反而还有可能起反作用,
我们希望的是根据不同的助手选择不同的案例,这样对模型的回答才具有指导意义。
few-shot selectors
在langchain中,还真就提供了这么一个机制,它可以为FewShotPromptTemplate提供一个选择器,当我们传入变量的时候,选择器会根据变量匹配出几个候选的案例来,下面就先介绍一个案例
SemanticSimilarityExampleSelector
SemanticSimilarityExampleSelector选择器是按照文本语义的相似度来来找相似案例的,所以要有一个判断相似的机制,通常在语言任务中用的都是embedding那一套(embedding章节会讲):
- 引入一个embedding模型和一个向量数据库
2. 将所有案例进行embedding化,存入向量数据库中
3. 将输入的变量进行embedding化,然后在向量数据库中根据相似度计算(通常是余弦相似度)找出topK条相似案例
下面先给出代码,然后对着代码说明
from langchain_core.prompts import PromptTemplate,FewShotPromptTemplate from langchain_chroma import Chroma from langchain_core.example_selectors import ( SemanticSimilarityExampleSelector, MaxMarginalRelevanceExampleSelector, LengthBasedExampleSelector) from pydantic_settings import BaseSettings,SettingsConfigDict from langchain_community.embeddings import DashScopeEmbeddings example_prompt = PromptTemplate.from_template("question: {question}->answer:{answer}") examples = [ {'question':'美丽',"answer":'beautiful'}, {'question':'男孩',"answer":'boy'}, {'question':'男人',"answer":'man'}, {'question':'456',"answer":'four'}, {'question':'456',"answer":'four hundred and fifty-six'}, {'question':'1',"answer":'one'}, {'question':'34',"answer":'thirty-four'}, {'question': 'beautiful', "answer": '美丽'}, {'question':'thirty-four',"answer":'34'}, {'question':'man',"answer":'男人'}, {'question': '你好', "answer": 'こんにちは'}, {'question': '123', "answer": '百二十三'}, {'question': '美丽', "answer": '美しい'}, ] prefix = """ 你是一个翻译助手,你擅长将{source_language}翻译为{dst_language},请将我发送给你的question的内容翻译为{dst_language},不要返回无关的内容,只需返回最终翻译结果,下面的history examples中提供了一些具体的案例,为你提供一些参考: ## history examples: """ suffix = """ ## user true task: question:{user_input_words}->answer: """ class ModelConfig(BaseSettings): model_config = SettingsConfigDict(env_file="../../../.env", env_file_encoding="utf-8") qwen_key:str deepseek_key:str deepseek_base_url:str model_config = ModelConfig() qwen_key = model_config.qwen_key # 1. 引入embedding模型 embeddings = DashScopeEmbeddings(model="text-embedding-v1", dashscope_api_key=qwen_key) # 2. 创建案例选择器 example_selector = SemanticSimilarityExampleSelector.from_examples( examples, embeddings, Chroma, k=3 ) # 3. 创建fewshot模版 prompt_template = FewShotPromptTemplate( example_selector=example_selector, example_prompt=example_prompt, prefix=prefix, suffix=suffix, input_variables=['user_input_words','source_language','dst_language'] ) lag2lag = input("你想我成为什么翻译助手(格式如:中文-英文):") source_language,dst_language = lag2lag.split('-') new_prompt_template = prompt_template.partial(source_language=source_language,dst_language=dst_language) prompt = new_prompt_template.invoke({'user_input_words':"hello"}) print(prompt.to_string()) 代码创建过程
- 引入一个embedding模型,我这里引入的是阿里的一个在线embedding服务,你可以引入任何embedding模型,甚至可以本地加载
- 穿件一个选择器,和我最开始说的一样,这个选择器需要的是一个embedding模型,一个向量库,当然还需要案例列表,和一个k值,这个k值就是指定要返回的相似的topK的值
- 将选择器传入FewShotPromptTemplate模板中
代码匹配过程
- 引入一个embedding模型和一个向量数据库
- 将所有案例进行embedding化,存入向量数据库中
- 将输入的变量进行embedding化,然后在向量数据库中根据相似度计算(通常是余弦相似度)找出topK条相似案例
按原理上来说,其实应该能解决我们的问题,但是实际运行的时候,却发现匹配的结果不如我们所想的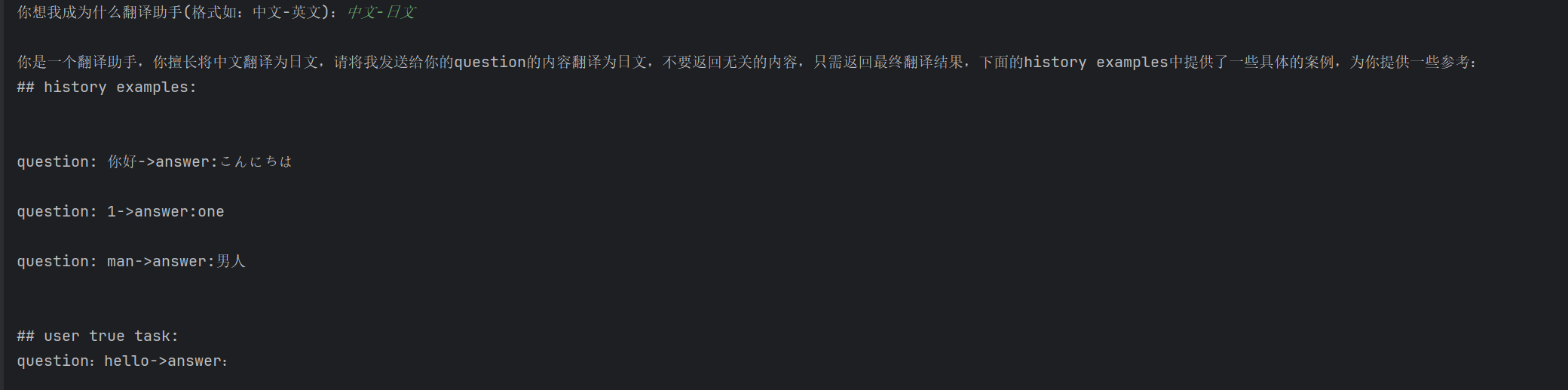
其问题就是出在了它的匹配原则上,虽然是按照相似度匹配,但是它在构建文本的时候有很大的问题,下面我按照源码的实际原理来举例,我拿出两个例子吧:
examples = [ {'question':'美丽',"answer":'beautiful'}, {'question': '美丽', "answer": '美しい'}, ] - 首先会对list中的每一个字典进行处理
2. 对字典中的成员按照key排序,然后取出排序后的对应value,进行拼接,比如上面两个拼接后的内容就是:“beautiful 美丽”,“美しい 美丽”
3. 对拼接后的内容进行向量化 - 当输入变量时,会用变量和向量化后的案例进行相似度计算,返回最相似的topK案例
从上面来看,比对的完全是具体的翻译内容,这样,如果我输入"美丽"这个词,最相似的肯定是带有"美丽"的案例 ,但是这样显然是不对的,我们需要匹配的内容,其实和翻译的案例没关系,而是和种类有关系,最直觉的方法就是在案例中加入种类信息
examples = [ {"lang2lang":"中文-英文",'question':'美丽',"answer":'beautiful'}, {"lang2lang":"中文-日文",'question': '美丽', "answer": '美しい'}, ] 这样匹配的时候就考虑到了翻译种类的信息,但是,我们虽然在案例上加入了种类信息,麻烦的地方是输入的时候我们只能输入变量,而种类信息我们是把他定义到了partial变量中,除非我们把这个变量也拿出来。现在
我们就把partial变量也去掉,所有变量都保存在input_variables中,这样,就好使了,下面我先展示代码:
from langchain_core.prompts import PromptTemplate,FewShotPromptTemplate example_prompt = PromptTemplate.from_template("{source_language}-{dst_language}任务 question: {question}->answer:{answer}") examples = [ {'source_language':'中文','dst_language':"英文",'question':'美丽',"answer":'beautiful'}, {'source_language':'中文','dst_language':"英文",'question':'男孩',"answer":'boy'}, {'source_language':'中文','dst_language':"英文",'question':'男人',"answer":'man'}, {'source_language':'中文','dst_language':"英文",'question':'456',"answer":'four'}, {'source_language':'中文','dst_language':"英文",'question':'456',"answer":'four hundred and fifty-six'}, {'source_language':'中文','dst_language':"英文",'question':'1',"answer":'one'}, {'source_language':'中文','dst_language':"英文",'question':'34',"answer":'thirty-four'}, {'source_language':'英文','dst_language':"中文",'question': 'beautiful', "answer": '美丽'}, {'source_language':'英文','dst_language':"中文",'question':'thirty-four',"answer":'34'}, {'source_language':'英文','dst_language':"中文",'question':'man',"answer":'男人'}, {'source_language':'中文','dst_language':"日文",'question': '你好', "answer": 'こんにちは'}, {'source_language':'中文','dst_language':"日文",'question': '123', "answer": '百二十三'}, {'source_language':'中文','dst_language':"日文",'question': '美丽', "answer": '美しい'}, ] prefix = """ 你是一个翻译助手,你擅长将{source_language}翻译为{dst_language},请将我发送给你的question的内容翻译为{dst_language},不要返回无关的内容,只需返回最终翻译结果,下面的history examples中提供了一些具体的案例,为你提供一些参考: ## history examples: """ suffix = """ ## user true task: {source_language}-{dst_language}任务 question:{user_input_words}->answer: """ from langchain_core.example_selectors.base import BaseExampleSelector class TranslateExampleSelector(BaseExampleSelector): def __init__(self, examples): self.examples = examples def add_example(self, example): self.examples.append(example) def select_examples(self, input_variables): # This assumes knowledge that part of the input will be a 'text' key source_language = input_variables['source_language'] dst_language = input_variables['dst_language'] task = '-'.join((source_language,dst_language)) batch_example = list() for example in self.examples: if task=='-'.join((example["source_language"],example['dst_language'])): batch_example.append(example) batch_len = min(3,len(batch_example)) return batch_example[:batch_len] example_selector = TranslateExampleSelector(examples) prompt_template = FewShotPromptTemplate( example_selector=example_selector, example_prompt=example_prompt, prefix=prefix, suffix=suffix, input_variables=['user_input_words','source_language','dst_language'] ) source_language,dst_language = "中文-日文".split('-') prompt = prompt_template.invoke({'source_language':source_language,'dst_language':dst_language,'user_input_words':"hello"}) print(prompt.to_string()) 下面开始讲讲上面的代码:
- 首先需要自己定义一个TranslateExampleSelector选择器
2. 这个选择器必须继承BaseExampleSelector,继承之后必须重写两个方法
3. 方法1:add_example,往案例列表中添加新的案例,通常就和我写的一样,不用过多修改。日后如果你想加入更多的案例,直接类似调用example_selector.add_example({'source_language':'中文','dst_language':"日文",'question': '美丽', "answer": '美しい'})
4. 方法2:select_examples,实现匹配规则,得到匹配的结果,本次我们实现的逻辑就是,用传入的source_language和dst_language进行强匹配,后续学了embedding后,可以再回来进行改进 - 将选择器实例化
- 实例化后的选择器传入FewShotPromptTemplate
**注意:**基本上就完工了,这里可以回顾一下前一节[prompt第四讲-fewshot],你会发现实例化FewShotPromptTemplate的时候,如果传入example_selector
,是不用且也不能再传入examples的,如果传入了,在源码逻辑中,选择器就会失效,这是需要注意的一点。
ok,这一小节就讲完了,还有一些选择器,我觉得看一看官网就可以了,主要是要掌握如何自己写选择器,最后展示一下改进后的完整的翻译助手
from langchain_core.prompts import PromptTemplate,FewShotPromptTemplate example_prompt = PromptTemplate.from_template("{source_language}-{dst_language}任务 question: {question}->answer:{answer}") examples = [ {'source_language':'中文','dst_language':"英文",'question':'美丽',"answer":'beautiful'}, {'source_language':'中文','dst_language':"英文",'question':'男孩',"answer":'boy'}, {'source_language':'中文','dst_language':"英文",'question':'男人',"answer":'man'}, {'source_language':'中文','dst_language':"英文",'question':'456',"answer":'four'}, {'source_language':'中文','dst_language':"英文",'question':'456',"answer":'four hundred and fifty-six'}, {'source_language':'中文','dst_language':"英文",'question':'1',"answer":'one'}, {'source_language':'中文','dst_language':"英文",'question':'34',"answer":'thirty-four'}, {'source_language':'英文','dst_language':"中文",'question': 'beautiful', "answer": '美丽'}, {'source_language':'英文','dst_language':"中文",'question':'thirty-four',"answer":'34'}, {'source_language':'英文','dst_language':"中文",'question':'man',"answer":'男人'}, {'source_language':'中文','dst_language':"日文",'question': '你好', "answer": 'こんにちは'}, {'source_language':'中文','dst_language':"日文",'question': '123', "answer": '百二十三'}, {'source_language':'中文','dst_language':"日文",'question': '美丽', "answer": '美しい'}, ] prefix = """ 你是一个翻译助手,你擅长将{source_language}翻译为{dst_language},请将我发送给你的question的内容翻译为{dst_language},不要返回无关的内容,只需返回最终翻译结果,下面的history examples中提供了一些具体的案例,为你提供一些参考: ## history examples: """ suffix = """ ## user true task: {source_language}-{dst_language}任务 question:{user_input_words}->answer: """ from langchain_core.example_selectors.base import BaseExampleSelector class CustomExampleSelector(BaseExampleSelector): def __init__(self, examples): self.examples = examples def add_example(self, example): self.examples.append(example) def select_examples(self, input_variables): # This assumes knowledge that part of the input will be a 'text' key source_language = input_variables['source_language'] dst_language = input_variables['dst_language'] task = '-'.join((source_language,dst_language)) batch_example = list() for example in self.examples: if task=='-'.join((example["source_language"],example['dst_language'])): batch_example.append(example) batch_len = min(3,len(batch_example)) return batch_example[:batch_len] example_selector = CustomExampleSelector(examples) prompt_template = FewShotPromptTemplate( example_selector=example_selector, example_prompt=example_prompt, prefix=prefix, suffix=suffix, input_variables=['user_input_words','source_language','dst_language'] ) from langchain_community.llms import Tongyi from pydantic_settings import BaseSettings,SettingsConfigDict """ 2,1 获取千问的key 我这么写的原因是因为方便我上传项目到github的同时,不暴露我的key,所以我把可以key保存到了最外部的一个.env文件中 这样我每一次同步到github的时候就不会把key也推出去,你们测试的时候,可以直接写成 qwen_key="sk-cc2209cec48c4bc966fb4acda169e",这样省事。 """ class ModelConfig(BaseSettings): model_config = SettingsConfigDict(env_file="../../../.env",env_file_encoding="utf-8") qwen_key:str deepseek_key:str deepseek_base_url:str model_config = ModelConfig() qwen_key = model_config.qwen_key # 1. 读取配置信息,获取模型key llm = Tongyi(dashscope_api_key=qwen_key) lag2lag = input("你想我成为什么翻译助手(格式如:中文-英文):") source_language,dst_language = lag2lag.split('-') while(True): user_input_word = input(f"请输入需要翻译的{source_language}:") if user_input_word.lower() =="quit": break else: prompt = prompt_template.invoke({'source_language':source_language,'dst_language':dst_language,'user_input_words':user_input_word}) print(llm.invoke(prompt)) 附上筋斗云,会有完整教程和代码:https://github.com/traveler-leon/langchain-learning.git
