
阅读量:1
目录
一. Kafka介绍
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。
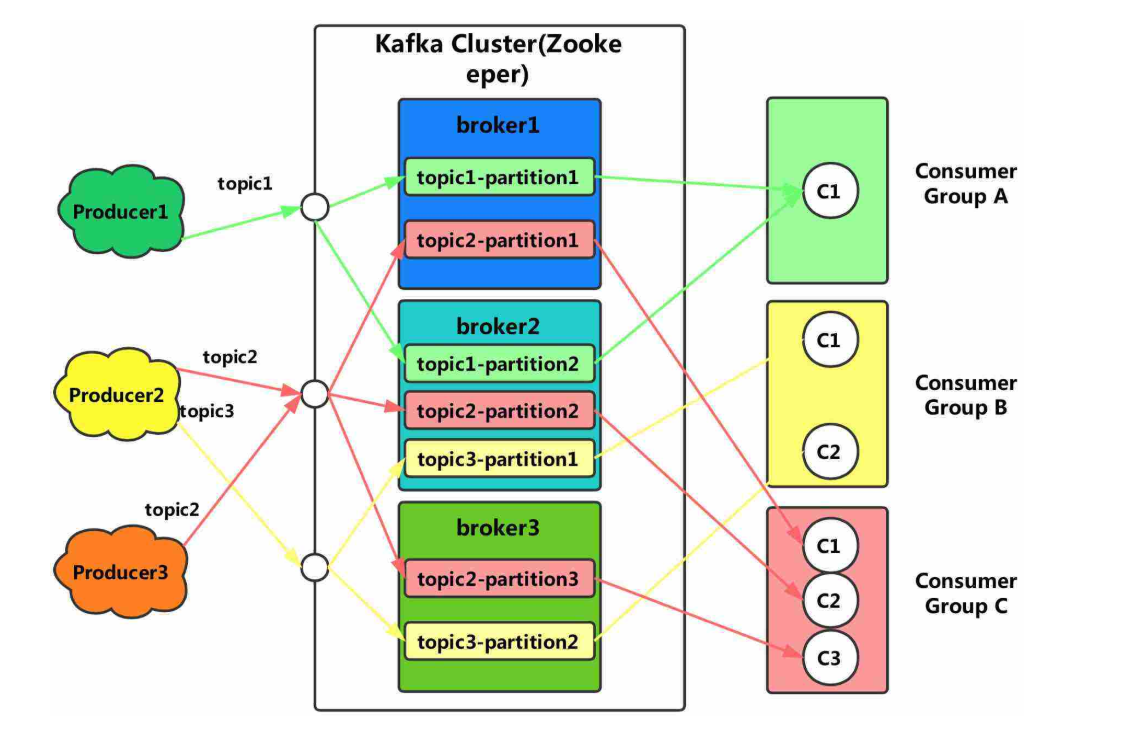
1. 应用场景
Kafka可以看作是一个能够处理消息队列的中间件,适用于实时的流数据处理,主要用于平衡好生产者和消费者之间的关系。
- 生产者
生产者可以看作是数据源,可以来自于日志采集框架,如Flume,也可以来自于其它的流数据服务。当接收到数据后,将根据预设的Topic暂存在Kafka中等待消费。对于接收到的数据将会有额外的标记,用于记录数据的被消费【使用】情况。
- 消费者
消费者即数据的使用端,可以是一个持久化的存储结构,如Hadoop,也可以直接接入支持流数据计算的各种框架,如Spark - Streaming。消费者可以有多个,通过订阅不同的Topic来获取数据。
2. 版本对比
Kafka的0.x和1.x可以看作是上古版本了,最近的更新也是几年以前,从目前的场景需求来看,也没有什么特别的理由需要使用到这两个版本了。
- 2.x
在进行版本选择时,通常需要综合考虑整个数据流所设计到的计算框架和存储结构,来确定开发成本以及兼容性。目前2.x版本同样是一个可以用于生产环境的版本,并且保持着对Scala最新版本的编译更新。
- 3.x
3.x是目前最新的稳定版,需要注意的是,Kafka的每个大版本之间的差异较大,包括命令参数以及API调用,所以在更换版本前需要做好详细的调查与准备,本文以3.x的安装为例。
二. Kafka安装
解压安装的操作方式可以适用于各种主流Linux操作系统,只需要解决好前置环境问题。
1. 前置环境
此前,运行Kafka需要预先安装Zookeeper。在Kafka 2.8.0版本以后,引入了Kraft(Kafka Raft)模式,可以使Kafka在不依赖外部Zookeeper的前提下运行。除此之外Kafka由Scala语言编写,需要JVM的运行环境。
(1)安装JDK
Ubuntu/Debian:
sudo apt install openjdk-8-jdkCentOS/RedHat:
sudo yum install java-1.8.0-openjdk安装完成后可以使用java-version命令验证【可省去环境变量配置】。

2. 软件安装
- 下载Kafka ,链接如下:
# 离线下载安装包 https://downloads.apache.org/kafka/3.5.2/kafka_2.12-3.5.2.tgz # 在线利用wget远程下载 wget https://downloads.apache.org/kafka/3.5.2/kafka_2.12-3.5.2.tgz- 解压安装
tar -zvxf kafka_2.12-3.5.2.tgz(3)环境变量配置
需要在环境变量中指定Kafka的安装目录以及命令文件所在目录,系统环境变量与用户环境变量配置其中之一即可。
/etc/profile 文件最下方添加如下两行命令--配置全局环境。
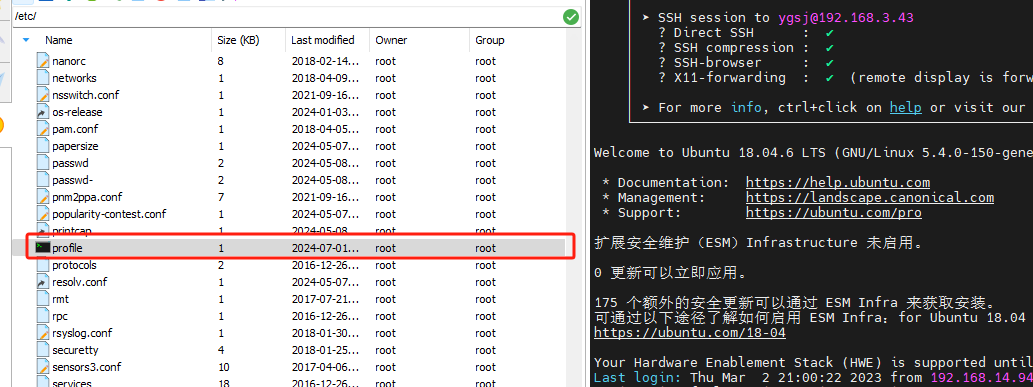
export KAFKA_HOME=/home/ygsj/Config_files/kafka_server/kafka_2.12-3.5.2 export PATH=$PATH:$KAFKA_HOME/bin在文件结尾添加以上内容后执行source命令,使其立即生效。
source /etc/profile [Ubuntu/Debian] source ~/.bashrc [CentOS/RedHat] source ~/.bash_profile 执行后可以输入kafka,然后按Tab尝试补全【需要按多次】,如果出现命令列表则证明配置成功。

(3)服务启动
使用Kraft模式,则需要先进行集群初始化【即使是单个节点】,以下为操作步骤:
- 目录下创建 kafka-logs文件夹
- 修改配置文件
修改Kafka的/config/kraft/server.properties文件,更换其中的log.dirs目录指向创建目录,防止默认的/tmp被清空:
log.dirs=/home/ygsj/Config_files/kafka_server/kafka-logs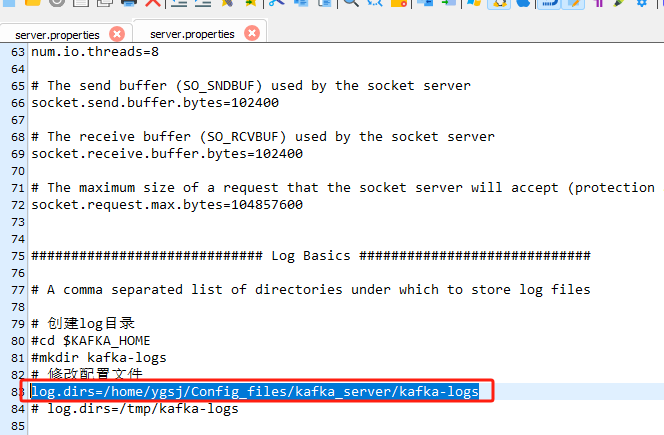
- 创建Kafka的集群ID
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"调用 kafka-storage.sh 生成一个UUID

将获得的 UUID 放到 kafka_2.12-3.5.2/config/kraft/server.properties 文件中 如下:
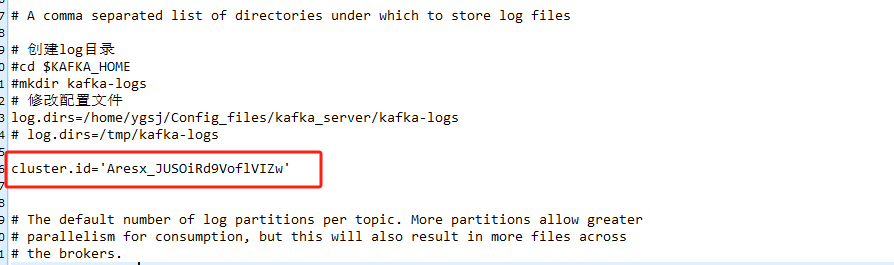
相同文件内修改:远程连接开启 (红框内写服务器ip)---自己测试0.0.0.0无效
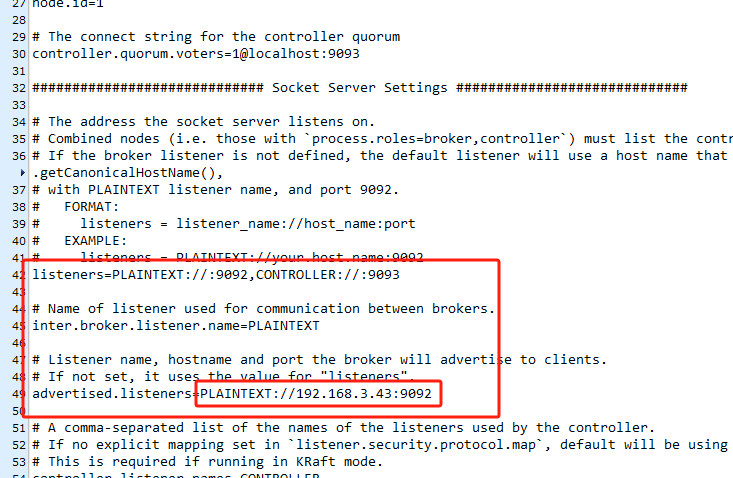
进入到Kafka的家目录后,执行以下命令
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties # bin/kafka-server-start.sh config/kraft/server.properties 这种方式并不是后台运行,需要保证终端开启,等测试稳定后可以在后台执行或者注册为系统服务。
这种方式并不是后台运行,需要保证终端开启,等测试稳定后可以在后台执行或者注册为系统服务。
三. Console测试
基础命令
(1)列出Kafka集群中所有存在的主题
kafka-topics.sh --list --bootstrap-server localhost:9092
--bootstrap-server localhost:9092 指定了Kafka集群的连接地址(在这里是本地的Kafka服务器)
如果集群中没有主题,命令不会返回任何内容
当你创建主题后,这条命令会返回集群中存在的主题列表
(3)创建一个新的主题
kafka-topics.sh --create --topic my-topic --bootstrap-server localhost:9092这条命令用于创建一个名为 my-topic 的新主题。
--create 指定了创建操作。
--topic my-topic 指定了要创建的主题名称。
--bootstrap-server localhost:9092 指定了Kafka集群的连接地址。
Created topic my-topic. 表示主题 my-topic 已成功创建。
(3)删除主题
kafka-topics.sh --delete --topic my-topic --bootstrap-server localhost:9092--delete: 指定要删除一个主题。
--topic my-topic: 指定要删除的主题名称是 my-topic。
--bootstrap-server localhost:9092: 指定Kafka集群的连接地址(在此是本地的Kafka服务器)。
(4)描述主题
kafka-topics.sh --describe --topic my-topic --bootstrap-server localhost:9092获取指定主题 my-topic 的详细信息。
--describe 指定了描述操作。
--topic my-topic 指定了要描述的主题名称。
--bootstrap-server localhost:9092 指定了Kafka集群的连接地址。
(5)启动生产者
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my-topic启动一个基于console的生产者脚本,可以方便的进行数据输入的测试,直接进行数据输入即可。

(6)启动消费者
kafka-console-consumer.sh --help 打印所有参数
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic my-topic --from-beginning添加from-beginning参数来从头消费数据。

四. 注册系统服务
为了方便的控制Kafka服务的启动和停止,可以将其注册为系统服务。
1. Systemd服务配置
创建Systemd服务文件
sudo vim /etc/systemd/system/kafka.service
在文件中添加以下内容,需要手动替换ExecStart和ExecStop中关于路径的部分:
[Unit] Description=Apache Kafka Requires=network.target remote-fs.target After=network.target remote-fs.target [Service] Type=simple ExecStart=/home/ygsj/Config_files/kafka_server/kafka_2.12-3.5.2/bin/kafka-server-start.sh /home/ygsj/Config_files/kafka_server/kafka_2.12-3.5.2/config/kraft/server.properties ExecStop=/home/ygsj/Config_files/kafka_server/kafka_2.12-3.5.2/bin/kafka-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target重新加载Systemd配置
sudo systemctl daemon-reload2. Kafka服务控制
- 开机自动启动
sudo systemctl enable kafka.service- 启动Kafka服务
sudo systemctl start kafka.service- 检查Kafka状态
sudo systemctl status kafka.service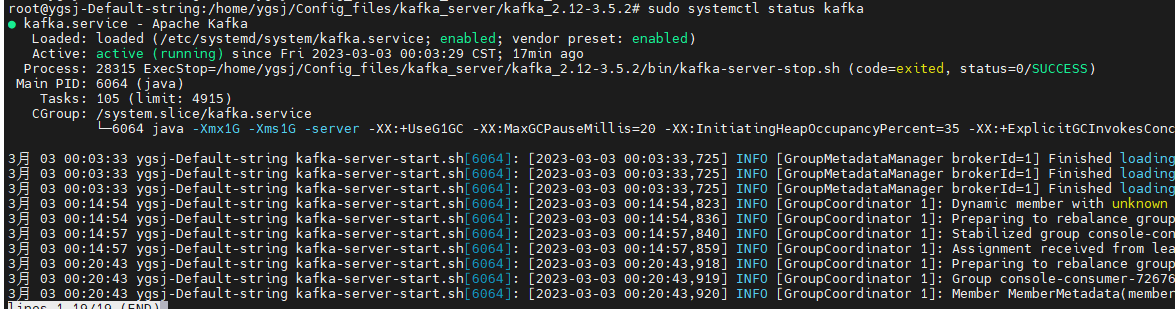
- 停止Kafka服务
sudo systemctl stop kafka.service- 重启Kafka服务
sudo systemctl restart kafka.service