
阅读量:2
HIVE调优-数据倾斜优化
目录
1.排序优化
1)order by
全局排序操作, 只有一个Reduce任务去对数据进行排序,会造成全部的数据堆积在一个Reduce任务中进行处理
经常会出现OOM异常? 一个Reduce任务的内存是有限的,承载不了太多数据
2)distribute by + sort by
distribute by:是指我们的分区操作
sort by: 跟上distribute by 之后可以实现在分区内进行排序,
如果当前的Reduce数量为1,那么也没有优化的效果,可以通过设置reduce的数量对不同分区中的数据进行拆分排序
通过 set mapreduce.job.reduces = N; 设置Reduce数量,默认参数值为-1 即根据资源及查询语句情况进行分配reduce,
3)cluster by语句:
如果分区字段和排序字段是同一个字段,那么和 distribute by + sort by 效果一致
2.数据倾斜优化
1)原因:
1.Key分布不均,导致某一些Key在做Reduce端处理时,执行较慢
2.数据重复,在关联时,会产生笛卡尔积,致使数据膨胀,严重的可能会导致集群挂掉
2)表现:
任务进度长时间维持在99%(或100%),
查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大
3)创建表格(查看一下具体效果)
1.创建带有部分NULL的学生表和成绩表
1.创建带有部分NULL的学生表和成绩表 DROP TABLE learn4.student_null; CREATE EXTERNAL TABLE IF NOT EXISTS learn4.student_null( id STRING COMMENT "学生ID", name STRING COMMENT "学生姓名", age int COMMENT "年龄", gender STRING COMMENT "性别", clazz STRING COMMENT "班级" ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ","; load data local inpath "/usr/local/soft/hive-3.1.2/data/student_null.txt" INTO TABLE learn4.student_null; DROP TABLE learn4.score_null; CREATE EXTERNAL TABLE IF NOT EXISTS learn4.score_null( id STRING COMMENT "学生ID", subject_id STRING COMMENT "科目ID", score int COMMENT "成绩" ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ","; load data local inpath "/usr/local/soft/hive-3.1.2/data/score_null.txt" INTO TABLE learn4.score_null; select * from learn4.student_null limit 10; select * from learn4.score_null limit 10; 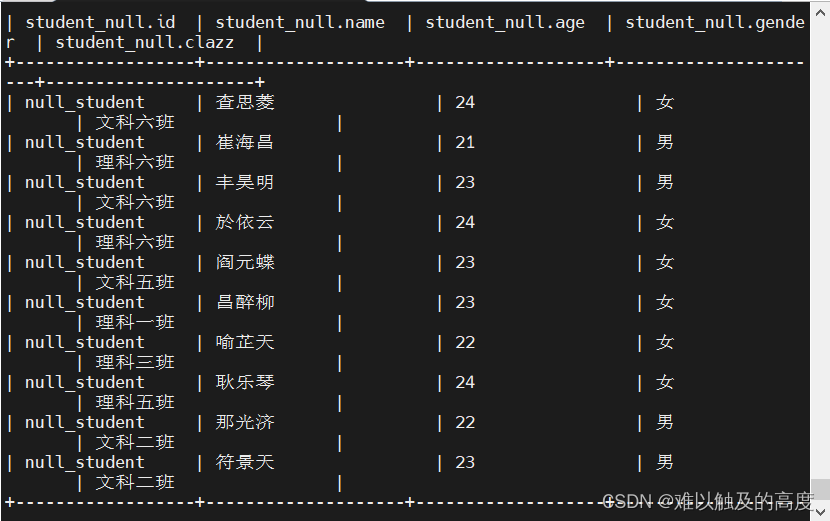
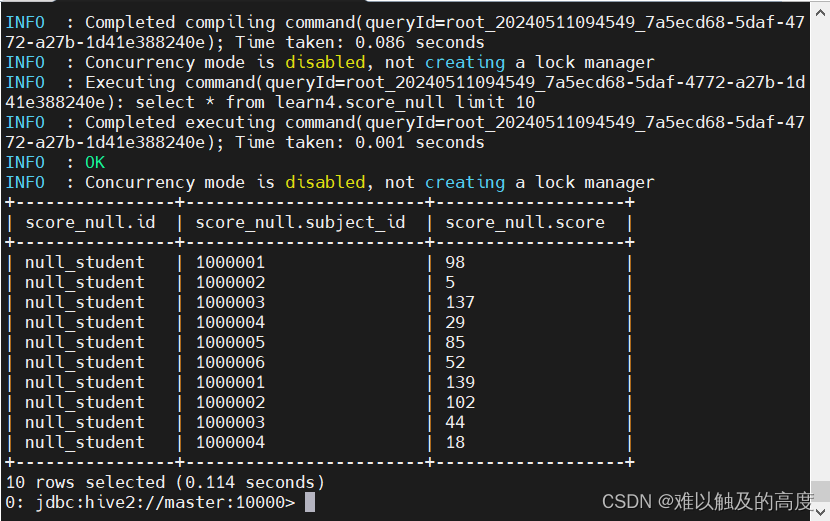
2.大空表与小空表进行关联
设置reduces =5 set mapreduce.job.reduces = 5;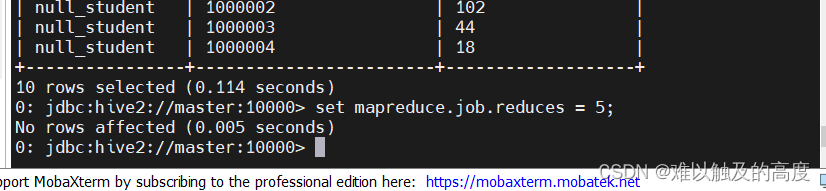
SELECT T1.id ,count(*) as num FROM learn4.student_null T1 JOIN learn4.score_null T2 ON T1.id = T2.id GROUP BY T1.id; 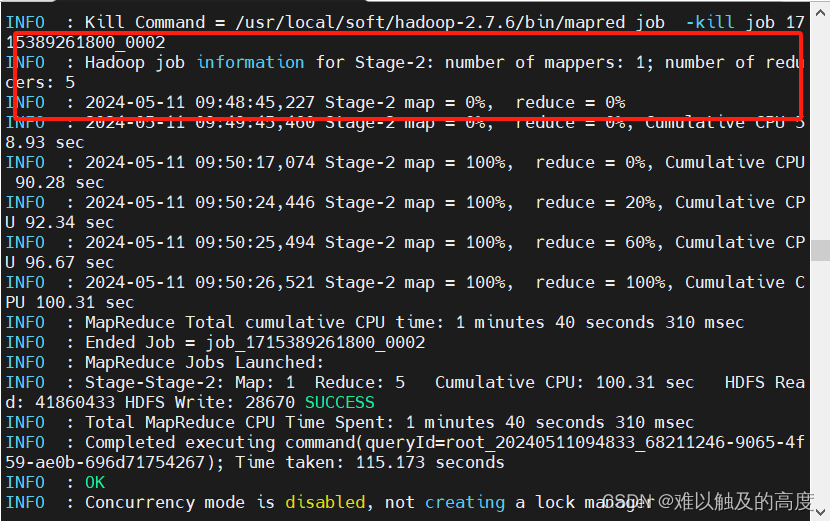
我们打开master:8088 找到我们刚刚执行的命令 点击history 发现是打不开的
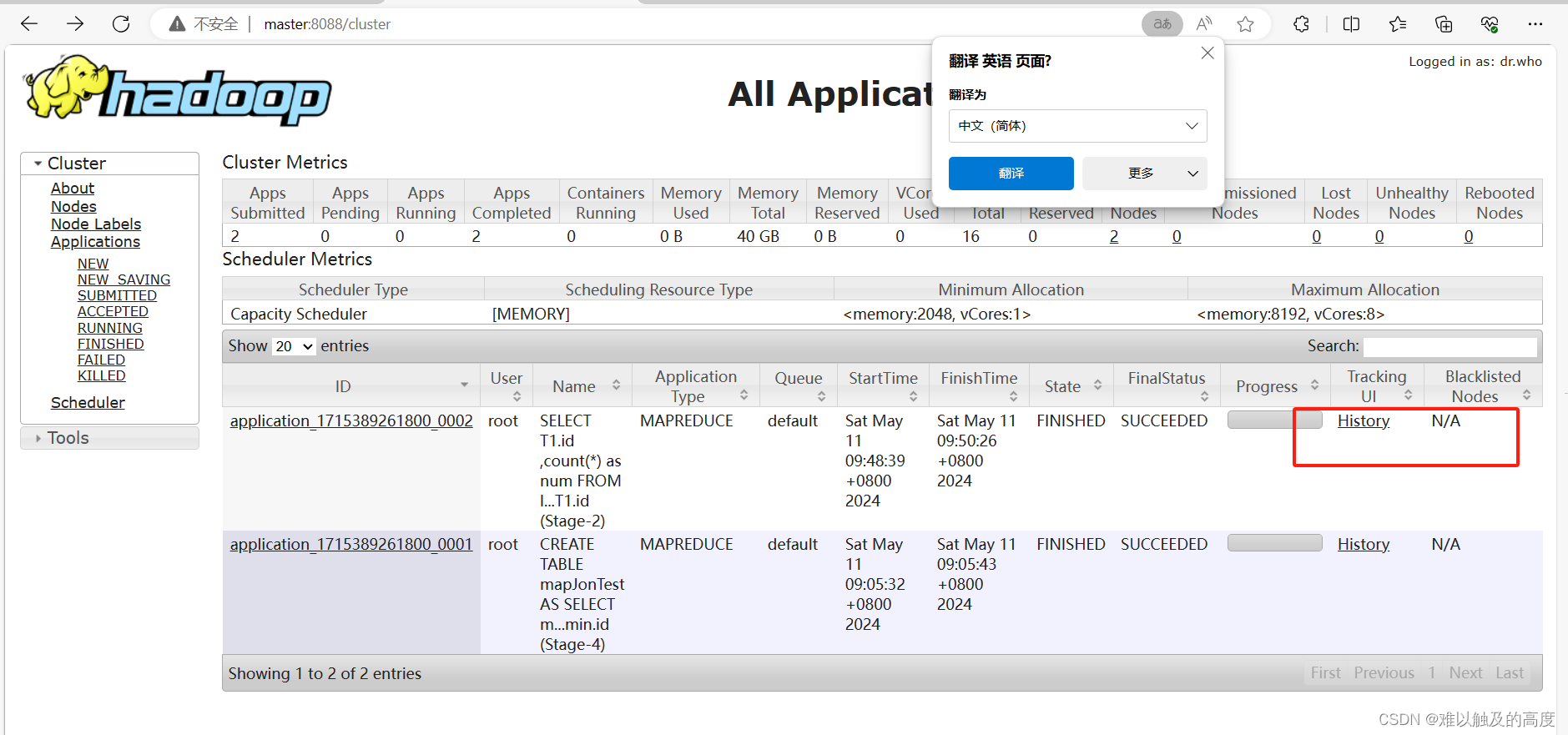
所以我们需要去配置一下日志文件
配置文件 vim mapred-site.xml <property> <name>mapreduce.jobhistory.done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/done</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>${yarn.app.mapreduce.am.staging-dir}/done_intermediate</value> </property> <property> <name>yarn.app.mapreduce.am.staging-dir</name> <value>/hadoop/yarn/historylog</value> </property> hdfs dfs -mkdir -p /hadoop/yarn/historylog # 启动历史服务 mr-jobhistory-daemon.sh start historyserver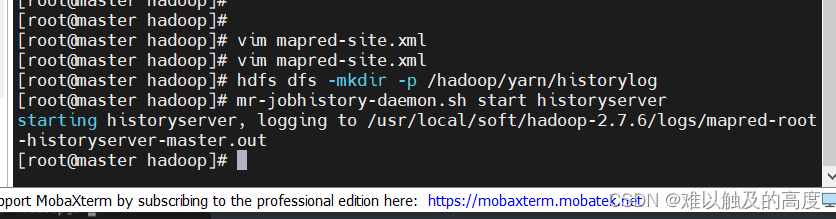
4) 如果想展示数据倾斜效果:
1.保证两张表的数据相差不大
2.可以关闭MapJOIN优化,防止执行MapJOIN流程
--查看具体的偏差的结果可以去 Reduce Tasks for job 历史中查看
-- 可以得到结论:数据倾斜之后 部分Reduce的执行时间明显比其他Reduce任务要长
5) 解决方法:
1.对会产生笛卡尔积的数据进行初步过滤
SELECT T1.id ,count(*) as num FROM learn4.student_null T1 JOIN learn4.score_null T2 ON T1.id = T2.id AND (T1.id != "null_student" or T2.id != "null_student") GROUP BY T1.id;
2.可以对Key比较集中的数据进行加随机数,然后再进行处理
SELECT T1.id ,count(*) as num FROM learn4.student_null T1 JOIN learn4.score_null T2 ON concat(T1.id,floor((rand()*10)%5)) = concat(T2.id,floor((rand()*10)%5)) GROUP BY T1.id; SELECT substring(T.id,1,-1) as id ,sum(T.num) --对打散的ID统计过的结果进行汇总 FROM ( SELECT T1.id ,count(*) as num --对打散的ID进行统计 FROM ( SELECT concat(T1.id,floor((rand()*10)%5)) as id --将T1表中的数据进行打散 FROM learn4.student_null) T1 JOIN ( SELECT concat(T1.id,floor((rand()*10)%5)) as id --将T2表中的数据进行打散 FROM learn4.score_null) T2 ON T1.id =T2.id )T GROUP BY substring(T.id,1,-1);3.通过参数进行调整
设置开启Map端的聚合操作
set hive.map.aggr = true设置groupby的检查点条数
set hive.groupby.mapaggr.checkinterval = 100000
开启GROUP BY 的负载均衡操作
set hive.groupby.skewindata = true 通过调整该参数,使得有倾斜的数据在Map reduce过程中 被随机的从Map端发送到Reduce端进行处理,
reduce会对随机发送过来的数据进行 初步的处理,之后再进行后续的统计
