
阅读量:1
目录
3.2.2、BeautifulSoup + Requests
1、前言
网络爬虫技术在信息时代的大数据时代中变得越来越重要。它是一种从互联网上获取数据的技术,被广泛应用于搜索引擎、数据挖掘、商业情报等领域。
2、什么是网络爬虫
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。通常网络爬虫是一种自动化程序或脚本,专门用于在互联网上浏览和抓取网页信息。网络爬虫的主要目的是从网络上的不同网站、页面或资源中搜集数据。它是搜索引擎、数据挖掘、内容聚合和其他信息检索任务的关键组成部分。
网络爬虫的工作方式类似于人类在互联网上浏览网页的过程,但是它能够以更快的速度、更大的规模和更一致的方式执行这些任务。网络爬虫的基本流程包括:
- 发送请求:爬虫向目标网站发送HTTP请求,请求特定的网页或资源。
- 获取网页内容:爬虫接收到服务器的响应,获取网页的HTML或其他相关内容。
- 解析网页:爬虫使用解析器(如HTML解析器)分析网页的结构,提取需要的信息。
- 存储数据: 爬虫将提取的数据存储到本地数据库、文件或其他存储介质中。
- 遍历链接:爬虫可能会继续遍历网页中的链接,递归抓取更多的页面。
虽然网络爬虫在信息检索和数据分析中具有重要作用,但需要注意合法使用,遵循网站的爬取规则,以及尊重隐私和版权等法律和伦理规定。
3、常见的爬虫框架
爬虫框架是一种用于开发网络爬虫(Web Crawler)的工具或软件框架。网络爬虫是一类程序,用于自动地浏览互联网,并收集、提取感兴趣的信息。爬虫框架提供了一系列的工具和功能,简化了爬虫的开发过程,加速了数据采集的效率。这里汇总了一些常见的Java类爬虫框架和Python类爬虫框架。
3.1、java框架
3.1.1、WebMagic
WebMagic是一款基于Java的开源爬虫框架,支持注解和设计模式,简化了爬取任务的实现。官网地址:Introduction · WebMagic Documents
WebMagic的总体架构:
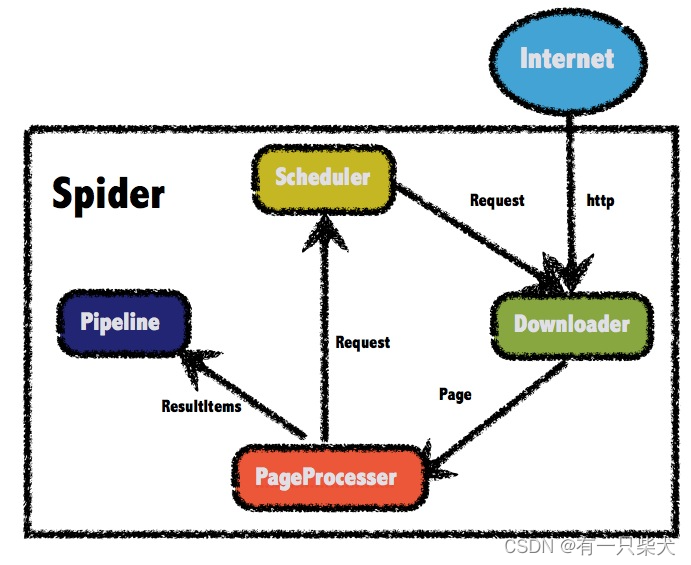
以下是一个简单的WebMagic示例:
import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.Spider; import us.codecraft.webmagic.processor.PageProcessor; public class MySpider implements PageProcessor { private Site site = Site.me().setRetryTimes(3).setSleepTime(1000); @Override public void process(Page page) { // 爬虫逻辑,提取页面内容等 } @Override public Site getSite() { return site; } public static void main(String[] args) { Spider.create(new MySpider()) .addUrl("http://www.example.com") .run(); } } 3.1.2、Jsoup
Jsoup是一款用于解析HTML文档的Java库,提供了类似于jQuery的API。官网地址:jsoup: Java HTML parser, built for HTML editing, cleaning, scraping, and XSS safety。
简单示例代码:
import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.IOException; public class JsoupExample { public static void main(String[] args) { String url = "http://www.example.com"; try { Document document = Jsoup.connect(url).get(); // 爬虫逻辑,提取页面内容等 } catch (IOException e) { e.printStackTrace(); } } } 3.1.3、HttpClient
Apache HttpClient 是一个用于发送 HTTP 请求的 Java 库,可以用于编写简单的网络爬虫。以下是一个使用 HttpClient 实现的简单爬虫示例代码。官网地址:Overview (Apache HttpClient 5.2.3 API)
简单示例代码:
import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; import org.apache.http.client.HttpClient; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import java.io.IOException; public class SimpleHttpClientCrawler { public static void main(String[] args) { // 创建 HttpClient 实例 HttpClient httpClient = HttpClients.createDefault(); // 指定要爬取的 URL String url = "http://www.example.com"; // 创建 HTTP GET 请求 HttpGet httpGet = new HttpGet(url); try { // 执行请求并获取响应 HttpResponse response = httpClient.execute(httpGet); // 获取响应实体 HttpEntity entity = response.getEntity(); if (entity != null) { // 将响应实体转换为字符串 String content = EntityUtils.toString(entity); System.out.println(content); } } catch (IOException e) { e.printStackTrace(); } finally { // 关闭 HttpClient 连接 try { httpClient.close(); } catch (IOException e) { e.printStackTrace(); } } } } 3.1.4、Crawler4j
Crawler4j是一个开源的Java类库提供一个用于抓取Web页面的简单接口。可以利用它来构建一个多线程的Web爬虫。官网地址:GitHub - yasserg/crawler4j: Open Source Web Crawler for Java
以下是简单示例代码:
public class Controller { public static void main(String[] args) throws Exception { String crawlStorageFolder = "/data/crawl/root"; int numberOfCrawlers = 7; CrawlConfig config = new CrawlConfig(); config.setCrawlStorageFolder(crawlStorageFolder); // Instantiate the controller for this crawl. PageFetcher pageFetcher = new PageFetcher(config); RobotstxtConfig robotstxtConfig = new RobotstxtConfig(); RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher); CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer); // For each crawl, you need to add some seed urls. These are the first // URLs that are fetched and then the crawler starts following links // which are found in these pages controller.addSeed("https://www.ics.uci.edu/~lopes/"); controller.addSeed("https://www.ics.uci.edu/~welling/"); controller.addSeed("https://www.ics.uci.edu/"); // The factory which creates instances of crawlers. CrawlController.WebCrawlerFactory<BasicCrawler> factory = MyCrawler::new; // Start the crawl. This is a blocking operation, meaning that your code // will reach the line after this only when crawling is finished. controller.start(factory, numberOfCrawlers); } }3.1.5、HtmlUnit
HtmlUnit 是一个用于模拟浏览器行为的 Java 库,可用于爬取动态网页。它对 HTML 文档进行建模并提供一个 API,允许您调用页面、填写表单、单击链接等......就像您在“普通”浏览器中所做的那样。它具有相当好的 JavaScript 支持(正在不断改进),甚至能够使用相当复杂的 AJAX 库,根据所使用的配置模拟 Chrome、Firefox 或 Internet Explorer。官网地址:HtmlUnit – Welcome to HtmlUnit
简单示例代码:
import com.gargoylesoftware.htmlunit.BrowserVersion; import com.gargoylesoftware.htmlunit.WebClient; import com.gargoylesoftware.htmlunit.html.HtmlPage; public class HtmlUnitExample { public static void main(String[] args) { try (WebClient webClient = new WebClient(BrowserVersion.CHROME)) { // 打开一个包含 JavaScript 渲染的页面 HtmlPage page = webClient.getPage("http://www.example.com"); // 获取页面标题 String title = page.getTitleText(); System.out.println("Page Title: " + title); } catch (Exception e) { e.printStackTrace(); } } } 3.1.6、Selenium
Selenium是一个用于Web
应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
同样也可以用于爬取动态网页。官网地址:Selenium
简单示例代码:
import org.openqa.selenium.WebDriver; import org.openqa.selenium.chrome.ChromeDriver; public class SeleniumExample { public static void main(String[] args) { // 设置 ChromeDriver 路径 System.setProperty("webdriver.chrome.driver", "/path/to/chromedriver"); // 创建 ChromeDriver 实例 WebDriver driver = new ChromeDriver(); try { // 打开一个包含 JavaScript 渲染的页面 driver.get("http://www.example.com"); // 获取页面标题 String title = driver.getTitle(); System.out.println("Page Title: " + title); } finally { // 关闭浏览器窗口 driver.quit(); } } } 3.2、Python框架
3.2.1、Scrapy
Scrapy是一个功能强大且灵活的开源爬虫框架,用于快速开发爬虫和数据提取工具。它提供了基于规则的爬取方式,支持分布式爬取,并且有着良好的文档和活跃的社区。官网地址:GitHub - scrapy/scrapy: Scrapy, a fast high-level web crawling & scraping framework for Python.
简单示例代码:
import scrapy class MySpider(scrapy.Spider): name = 'myspider' start_urls = ['http://www.example.com'] def parse(self, response): # 爬虫逻辑,提取页面内容等 pass 3.2.2、BeautifulSoup + Requests
BeautifulSoup是一个HTML解析库,而Requests是一个用于发送HTTP请求的库。它们经常一起使用,可以轻松地进行网页解析和数据提取。官网地址:Beautiful Soup 4.12.0 文档 — Beautiful Soup 4.12.0 documentation
简单示例代码:
import requests from bs4 import BeautifulSoup url = 'http://www.example.com' response = requests.get(url) if response.status_code == 200: soup = BeautifulSoup(response.text, 'html.parser') # 爬虫逻辑,提取页面内容等 else: print(f"请求失败,状态码:{response.status_code}") 3.2.3、Selenium
同Java下的Selenium一样,Python也同样支持该库。是一个用于自动化浏览器的工具,可以用于爬取动态网页,支持JavaScript渲染。它模拟用户在浏览器中的操作,适用于一些需要模拟用户行为的场景。
简单示例代码:
from selenium import webdriver url = 'http://www.example.com' driver = webdriver.Chrome() driver.get(url) # 爬虫逻辑,提取页面内容等 driver.quit() 3.2.4、PyQuery
PyQuery是一个类似于jQuery的库,用于解析HTML文档。它提供了简洁的API,使得在Python中进行HTML解析变得更加方便。官网地址:pyquery · PyPI
简单示例代码:
from pyquery import PyQuery as pq url = 'http://www.example.com' doc = pq(url) # 爬虫逻辑,提取页面内容等 3.2.5、PySpider
PySpider 是一个强大的分布式爬虫框架,使用 Python 语言开发,专注于提供简单、灵活、强大、快速的爬虫服务。PySpider 支持分布式部署,具有良好的可扩展性和高度定制化的特点。官网地址:Introduction - pyspider
简单示例代码:
from pyspider.libs.base_handler import * class Handler(BaseHandler): crawl_config = { 'headers': { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' } } @every(minutes=24 * 60) def on_start(self): self.crawl('https://movie.douban.com/top250', callback=self.index_page) @config(age=10 * 24 * 60 * 60) def index_page(self, response): for each in response.doc('div.item'): self.crawl(each('div.hd a').attr.href, callback=self.detail_page) next = response.doc('.next a').attr.href self.crawl(next, callback=self.index_page) @config(priority=2) def detail_page(self, response): return { "url": response.url, "title": response.doc('h1 span').text(), "rating": response.doc('strong.ll.rating_num').text(), "cover": response.doc('img[rel="v:image"]').attr.src, } 3.2.6、Portia
Portia 是一个开源的可视化爬虫工具,用于从网站上提取结构化数据。它是 Scrapinghub 公司开发的一部分,旨在简化和加速网页数据抽取的过程,无需编写复杂的代码。官网地址:Getting Started — Portia 2.0.8 documentation
Python中安装Portia:
pip install portia # 安装后直接启动 portia 它将在本地启动一个 Web 服务,并提供一个 web 页面来进行数据抽取的可视化操作。
3.2.7、Newspaper
Newspaper 是一个用于提取文章内容的 Python 库。它旨在帮助开发者从新闻网站和其他在线文章中提取有用的信息,例如标题、作者、正文内容等。Newspaper 的设计目标是易于使用且高效,适用于各种新闻网站和文章结构。官网地址:GitHub - codelucas/newspaper: newspaper3k is a news, full-text, and article metadata extraction in Python 3. Advanced docs:
安装newspaper3k
pip install newspaper3k简单代码示例:
from newspaper import Article # 输入文章的 URL article_url = 'https://www.example.com/article' # 创建 Article 对象并下载文章内容 article = Article(article_url) article.download() # 解析文章内容 article.parse() # 输出文章信息 print("Title:", article.title) print("Authors:", article.authors) print("Publish Date:", article.publish_date) print("\nArticle Content:\n", article.text) 3.2.8、Crawley
Crawley可以高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSON、XML等。Crawley 提供了非常强大和灵活的内容提取功能。它支持使用 CSS 选择器和 XPath 表达式从网页中提取所需的信息,使用 PyQuery 和 lxml 库进行解析。官网地址:Crawley’s Documentation — crawley v0.1.0 documentation
简单示例代码:
from crawley.crawlers import BaseCrawler from crawley.scrapers import BaseScraper from crawley.extractors import XPathExtractor from models import * class pypiScraper(BaseScraper): #specify the urls that can be scraped by this class matching_urls = ["%"] def scrape(self, response): #getting the html table table = response.html.xpath("/html/body/div[5]/div/div/div[3]/table")[0] #for rows 1 to n-1 for tr in table[1:-1]: #obtaining the searched html inside the rows td_updated = tr[0] td_package = tr[1] package_link = td_package[0] td_description = tr[2] #storing data in Packages table Package(updated=td_updated.text, package=package_link.text, description=td_description.text) class pypiCrawler(BaseCrawler): #add your starting urls here start_urls = ["http://pypi.python.org/pypi"] #add your scraper classes here scrapers = [pypiScraper] #specify you maximum crawling depth level max_depth = 0 #select your favourite HTML parsing tool extractor = XPathExtractor3.2.9、Grab
Grab 是一个用于编写网络爬虫的 Python 框架。它提供了一套强大而灵活的工具,使得爬取和处理网页变得更加容易。Grab 的设计目标是简化常见的爬虫任务,同时保持足够的灵活性来处理各种不同的网站结构。官网地址:http://docs.grablib.org/en/latest/
简单示例代码:
from grab import Grab # 创建 Grab 实例 g = Grab() # 设置要抓取的 URL url = 'https://www.example.com' g.go(url) # 输出抓取的页面内容 print("Content of", url) print(g.response.body) 3.2.10、Python-goose
python-goose 是一个轻量级的文章提取库,旨在从网页中提取文章内容。它使用类似于自然语言处理的技术来分析页面,提取标题、作者、正文等信息。官网地址:GitHub - grangier/python-goose: Html Content / Article Extractor, web scrapping lib in Python
简单示例代码:
from goose3 import Goose # 创建 Goose 实例 g = Goose() # 设置要提取的文章 URL url = 'https://www.example.com/article' article = g.extract(url) # 输出提取的信息 print("Title:", article.title) print("Authors:", article.authors) print("Publish Date:", article.publish_date) print("\nArticle Content:\n", article.cleaned_text) 3.2.11、Cola
cola 是另一个用于提取文章内容的库,它使用机器学习技术,并具有可配置的规则引擎,可以适应不同的网站结构。cola 的目标是实现高准确性和高可用性。官网地址:GitHub - qinxuye/cola: A high-level distributed crawling framework.
简单示例代码:
from cola.extractors import ArticleExtractor # 设置要提取的文章 URL url = 'https://www.example.com/article' # 使用 ArticleExtractor 提取文章信息 article = ArticleExtractor().get_article(url) # 输出提取的信息 print("Title:", article.title) print("Authors:", article.authors) print("Publish Date:", article.publish_date) print("\nArticle Content:\n", article.text) 4、爬虫策略
爬虫策略是指在进行网络爬虫操作时制定的一系列规则和策略,用于规范爬取行为、保护被爬取网站和服务器、确保合法合规的数据采集。以下是一些常见的爬虫策略:
- 遵守 robots.txt 文件:robots.txt 是网站根目录下的一个文本文件,用于指示爬虫哪些页面可以爬取,哪些不可以。爬虫应该尊重 robots.txt 文件中的规定。
- 设置合理的爬取速率:控制爬虫的爬取速率,以避免对目标服务器造成过大的负担。爬虫速度过快可能导致服务器负载过高,影响其他用户访问该服务器。
- 使用合法的 User-Agent:设置合法的 User-Agent,模拟正常用户的请求。一些网站可能会禁止爬取行为,特别是对于没有合法 User-Agent 的爬虫。
- 处理重试和错误: 确保爬虫能够正确处理页面请求失败、超时等情况,实现自动重试或记录错误信息。这可以提高爬虫的鲁棒性。
- 爬取深度和范围控制:设置爬虫的爬取深度和范围,以限制爬取的页面数量。这有助于控制爬虫的规模,避免对目标站点的过度访问。
- 使用代理IP池:使用代理服务器来隐藏真实 IP 地址,减少被封禁的风险。代理池可以轮流使用多个代理,避免单个 IP 被封锁。
- 定时更新爬虫规则:定期检查目标网站的变化,更新爬虫规则,以适应网站结构的变化。这可以提高爬虫的稳定性和持久性。
- 合法数据使用:爬取到的数据只能用于合法用途,不得用于侵犯隐私、侵权、非法竞争等违法活动。遵守法律法规,尊重网站的使用政策。
- 尊重隐私和版权:避免爬取包含个人隐私信息的页面,不要违反版权法。在进行爬取时,要考虑到被爬取网站的合法权益。
- 合理使用缓存:在适当的情况下使用缓存,避免频繁请求相同的页面,减轻服务器负担。
