阅读量:2
KMP算法的介绍
KMP算法是一种用于字符串搜索的高效算法,全称为Knuth-Morris-Pratt算法。它通过避免字符串的重复比较,提高搜索效率。KMP算法的核心是“部分匹配”表(也称为“最长公共前后缀”表),这个表用于在搜索过程中确定当发生不匹配时,模式串应该向右滑动多少位。
KMP算法的基本步骤如下:
构建部分匹配表(Next数组):对于模式串,计算每个位置之前字符串的最长公共前后缀长度。这个表用于在不匹配时决定模式串的滑动距离。
模式串与主串的匹配:使用Next数组,当模式串与主串在某个位置不匹配时,根据Next数组中的值,将模式串向右滑动相应的位数,而不是重新开始比较。
重复匹配过程:继续匹配过程,直到模式串与主串完全匹配,或者模式串滑过主串的末尾。
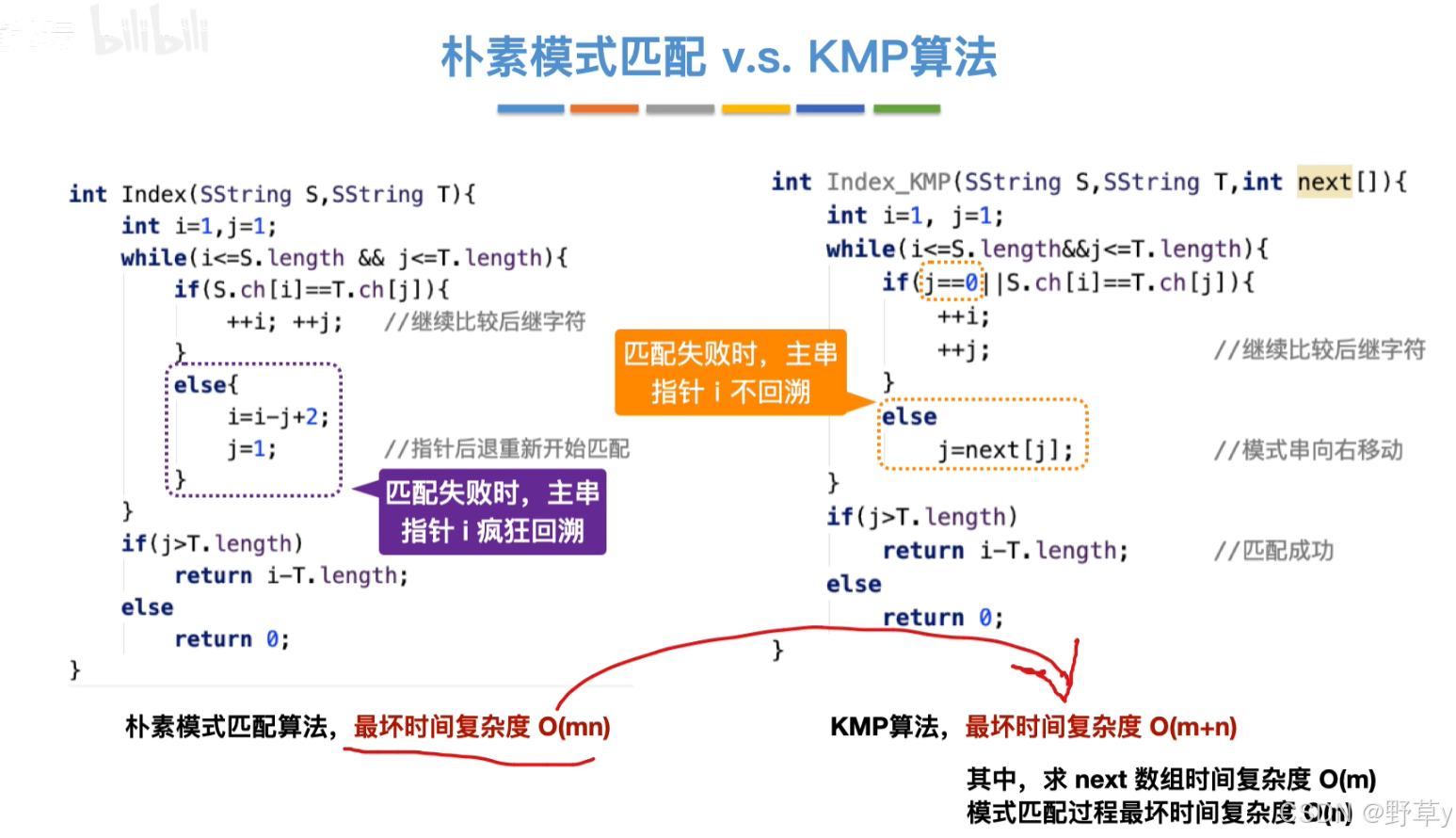
KMP算法的时间复杂度为O(n+m),其中n是主串的长度,m是模式串的长度,求next数组时间复杂度O(m)。这比朴素的字符串搜索算法(时间复杂度为O(n*m))要高效得多。
KMP算法的关键在于如何利用已匹配的信息,避免重复匹配。我将以一个简单的例子来解释KMP算法的工作原理。
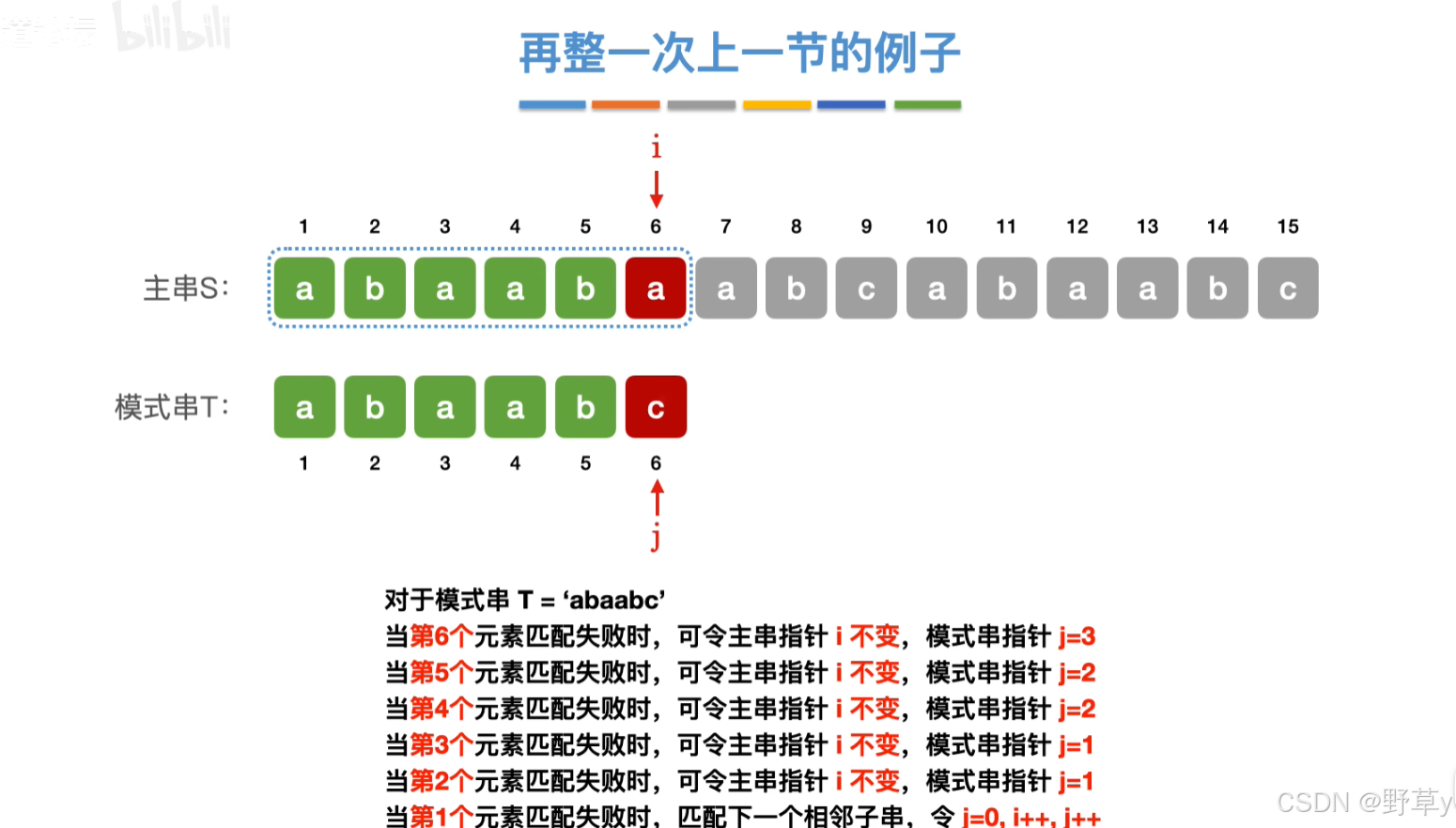
假设我们有一个主串S和一个模式串P。我们想要找出P在S中的位置。如果用传统的暴力匹配方法,当S和P在某个位置不匹配时,我们会将P向右移动一位,然后重新开始匹配。但KMP算法会这样做:
构建Next数组:首先,我们需要为模式串
P构建一个Next数组。这个数组的作用是,当P与S在某个位置不匹配时,告诉P应该向右移动多少位。Next数组的每个元素Next[i]表示P的前i个字符中,最长公共前后缀的长度。例如,对于模式串
P = "ABCDABD",Next数组如下:Next[0] = 0,因为没有任何字符。Next[1] = 0,因为只有一个字符,没有前后缀。Next[2] = 0,前两个字符"AB"没有公共前后缀。Next[3] = 0,前三个字符"ABC"没有公共前后缀。Next[4] = 1,前四个字符"ABCD"的公共前后缀是"A"。Next[5] = 2,前五个字符"ABCDA"的公共前后缀是"AB"。Next[6] = 0,前六个字符"ABCDAB"没有除了第一个字符"A"之外的公共前后缀。Next[7] = 1,前七个字符"ABCDABD"的公共前后缀是"A"。
开始匹配:现在我们用模式串
P去匹配主串S。- 如果在某个位置匹配成功,我们继续向后匹配。
- 如果在某个位置匹配失败,我们查看
Next数组。假设当前匹配到了模式串的第i个字符失败,那么我们将模式串向右移动Next[i-1]个位置,然后继续匹配。
重复匹配过程:我们继续这个过程,直到模式串与主串完全匹配,或者模式串滑过主串的末尾。
通过这种方式,KMP算法避免了大量的重复匹配,大大提高了搜索效率。
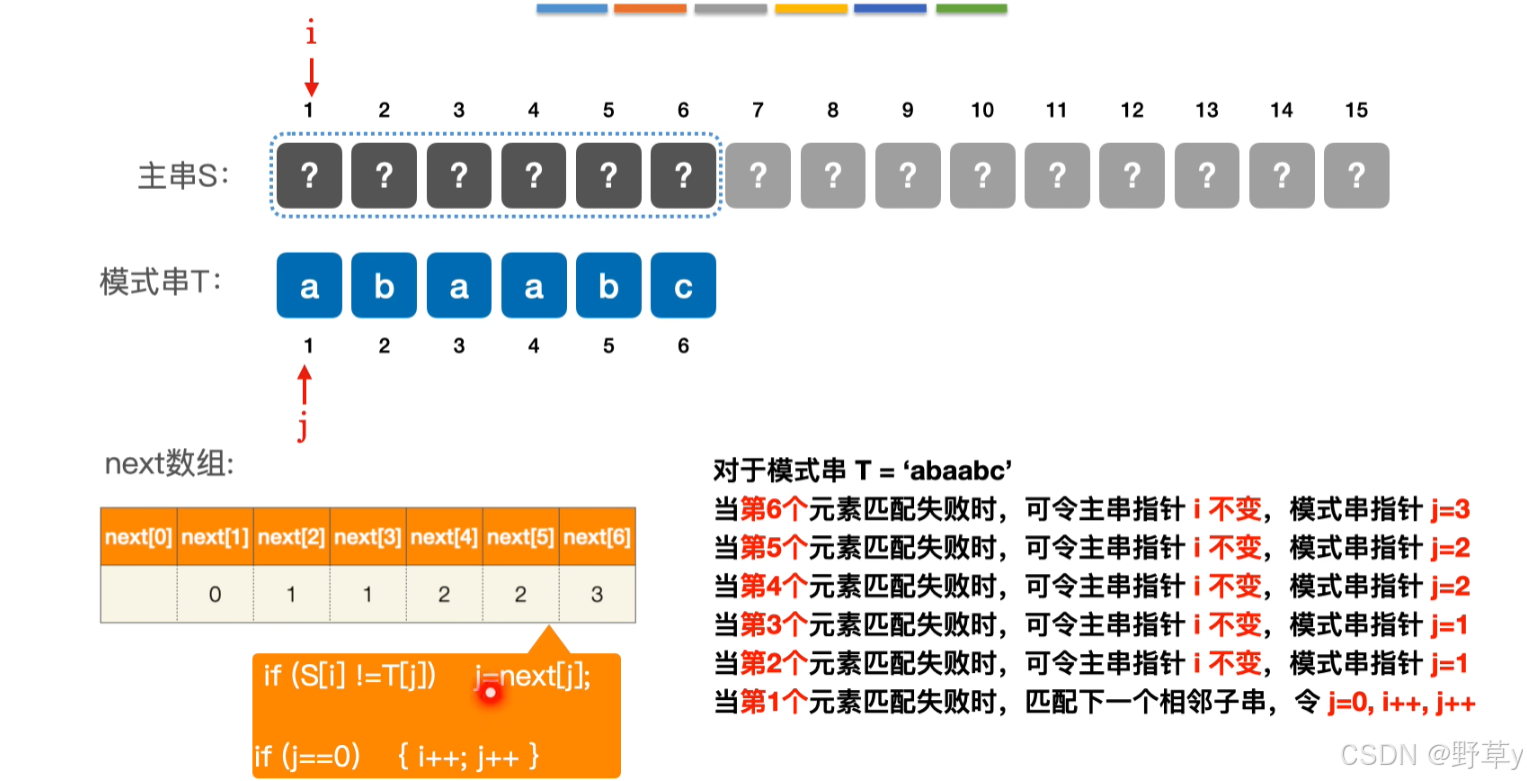
寻找最长公共前后缀是KMP算法中的一个关键步骤。这个步骤通常在构建Next数组时完成。Next数组中的每个元素Next[i]表示模式串P的前i个字符中,最长公共前后缀的长度。下面是寻找最长公共前后缀的步骤:
初始化:首先,我们需要初始化Next数组。通常,
Next[0]和Next[1]都是0,因为一个字符或没有字符的情况下,不存在公共前后缀。遍历模式串:从模式串的第二个字符开始,逐个字符向后遍历。
比较前后缀:对于当前字符
P[i],我们需要比较它的前缀P[0...i-1]和后缀P[1...i]。这里的关键是利用已经计算出的Next数组中的信息。更新Next数组:如果
P[i]与P[Next[i-1]]相等,那么Next[i] = Next[i-1] + 1。这是因为如果当前字符与它之前的子串的最长公共前后缀的下一个字符相等,那么当前子串的最长公共前后缀就是之前子串的最长公共前后缀加上这个字符。处理不匹配情况:如果
P[i]与P[Next[i-1]]不相等,我们需要继续向前查找,直到找到一个位置j,使得P[i]与P[Next[j-1]]相等,或者我们回到了模式串的起始位置。在这个过程中,我们实际上是在寻找当前字符之前的最长公共前后缀的次长公共前后缀。重复上述过程:对于模式串中的每个字符,重复上述步骤,直到遍历完整个模式串。
通过这个过程,我们可以为模式串构建出Next数组,这个数组将在KMP算法的匹配阶段被用来决定模式串在不匹配时应该向右滑动多少位。

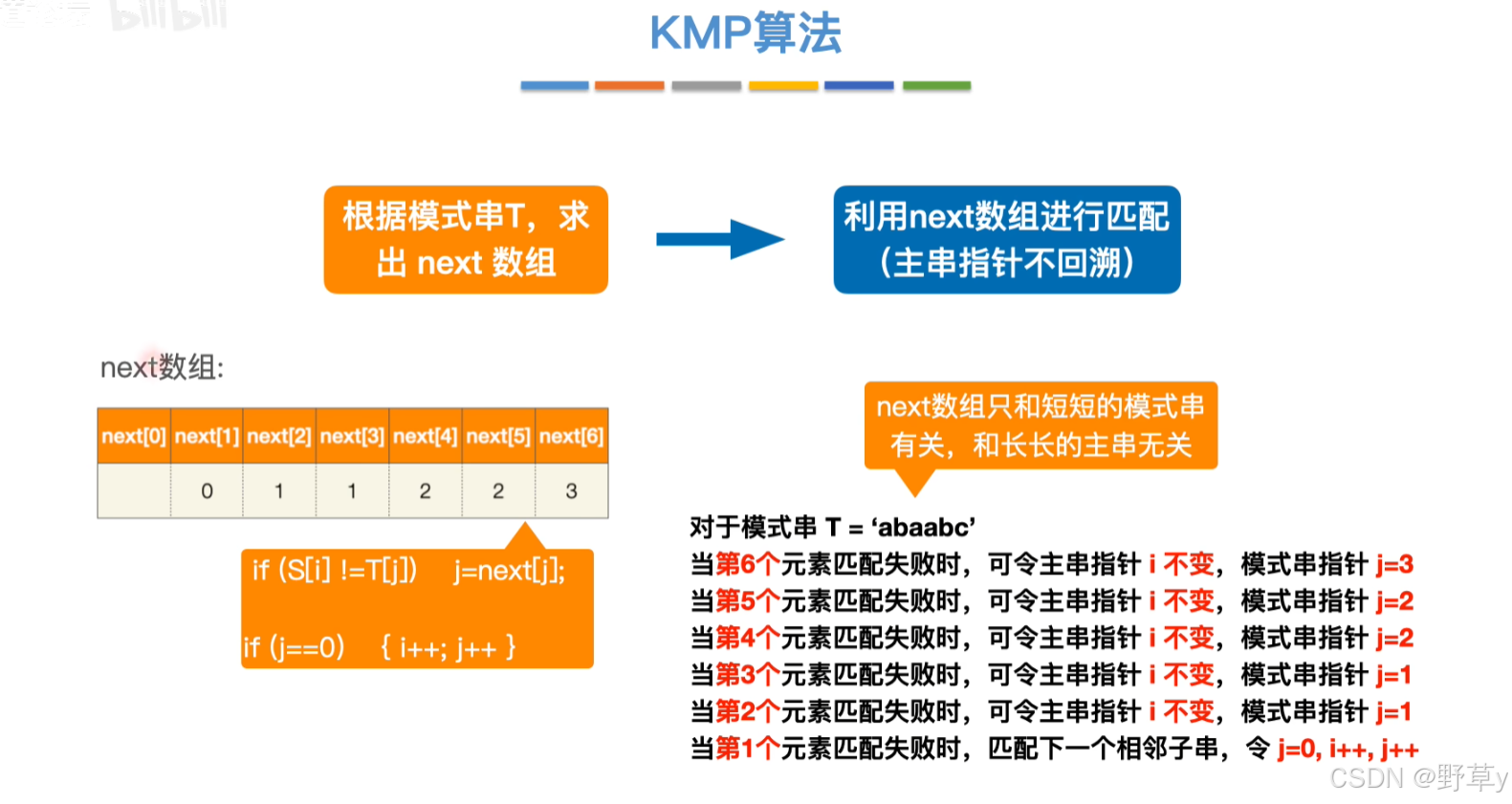
用代码表示
int Index_KMP(SString S, SString T, int next[]) { int i = 1, j = 1; // 初始化主串S和模式串T的指针i和j,从第一个字符开始比较 while (i <= S.length && j <= T.length){ // 当两个指针都没有超出各自字符串的长度时,继续循环 if (j == 0 || S.ch[i] == T.ch[j]) { // 如果模式串的指针j已经移到第一个字符,或者当前比较的字符相等 ++i; ++j; // 主串和模式串的指针都向后移动一位,继续比较下一个字符 } else j = next[j]; // 如果字符不匹配,根据next数组移动模式串的指针 // 这里的next[j]表示模式串中前j个字符的最长公共前后缀的长度 // 通过移动模式串,我们避免了不必要的重复比较 } if (j > T.length) return i - T.length; // 如果模式串的指针j超出了模式串的长度,说明匹配成功 // 返回匹配开始的位置,即主串指针i减去模式串长度T.length else return 0; // 如果模式串没有完全匹配,返回0表示匹配失败 } 与朴素模式匹配算法比较