
阅读量:1
学习mongodb,体会mongodb的每一个使用细节,欢迎阅读威赞的文章。这是威赞发布的第92篇mongodb技术文章,欢迎浏览本专栏威赞发布的其他文章。如果您认为我的文章对您有帮助或者解决您的问题,欢迎在文章下面点个赞,或者关注威赞。谢谢。
Mongodb字段允许包含字符,文档,数组等各种各样的类型。同样Mongodb索引也可以支持字符,文档,数组等类型。本文结合Mongodb官方文档,介绍Mongodb数组类型数据的索引——多键索引。如果应用经常查询数组字段,为该字段添加多键索引,能够提高查询效率,增加索引查询覆盖率,优化数据库查询性能。
如在学生集合当中,包含了存储学生测验成绩的test_scores字段,这个学期的每一次测验成绩都会在这个数组当中。老师需要查询出至少5次测验成绩超过90分的学生 。这样就可以在字段test_scores上添加索引来提高查询效率。因为test_scores是数组类型,Mongodb自动为数组类型创建多键索引。
概述
多键索引,包含并排序了字段中的数组数据。多键索引,能够改善数组字段的查询性能。用户不需要显示的定义多键索引类型。当Mongodb构建索引时,看到该字段是数组字段,就会自动的创建多键索引。Mongodb可以为普通类型数据数组(如字符串数组,数字数组)和嵌入式文档数据来构建多键索引。如果一个数组包含相同值的多个元素,则Mongodb只会选择这些元素中的一个来放入索引当中。
下面的图中描述了多键索引的结构。有一个collection集合,字段addr是文档类型的数组。现在为addr数组中的zip字段建立索引。在索引当中,数组元素的数值从小到大排列。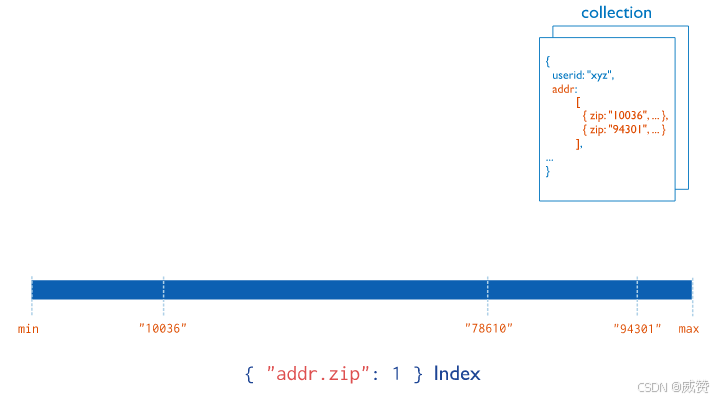
语法
使用下面的语句来创建多键索引
db.<collection>.createIndex({<arrayField>: <sortOrder>})使用和限制
索引边界
在查询中,边界定义了索引扫描的各个部分。Mongodb在多键索引边界计算上有特殊的规则,详细查看文档《Mongodb多键索引边界》。
唯一多键索引
在唯一多键索引当中,文档的数组元素,只能包含集合中其他文档数组中不存在的元素。
复合多键索引
在复合多键索引中,每一个文档最多只能包含一个被索引的数组字段。
用户不可以为多个数组创建索引。如在集合中包含了下面一个文档数据
{_id: 1, scores_spring:[8, 6], scores_fall:[5,9]}其中字段scores_spring和字段scores_fall是数组索引,用户不能够使用{scores_spring: 1, scores_fall:1}来创建索引。
如果一个复合索引已经存在,用户也不能够插入还是索引定义相违背的文档数据。
如集合中包含文档
{_id: 1, scores_spring:[8, 6], scores_fall:9} {_id: 2, scores_spring:6, scores_fall:[5, 7]}用户可以创建一个复合多键索引{scores_spring: 1, scores_fall:1},因为每一个文档当中,只有一个字段是数组索引,不包含这两个字段同时是数组字段的文档数据。该索引创建后,Mongodb不允许用户插入两个字段都是数据元素的文档。
排序
基于数组字段的索引进行排序时,满足下面两个条件,才会使用索引排序,而不会在查询中包含一个内存排序。
- 所有排序字段的值包含在索引边界最大最小值内
- 任何一个与排序模版带有相同前缀的多键索引都不能有边界限制。这句话在文档中很绕口。尝试去理解一下。如前面提到的索引{scores_spring: 1, scores_fall:1}。当某个查询排序,使用{sort:{scores_spring:1}},这该排序字段是索引{scores_spring: 1, scores_fall:1}的索引前缀。在查询当中,不能对scores_spring做边界限制,否者将使用内存排序。
分片集合
多键索引的字段,不能作为分片键。但是,当分片键是复合索引的前缀时,后续索引字段包含数组时,这个复合索引就会成为一个符合多键索引。
如下文档, 集合中带有索引{field2:1, field1: 1},当使用field2字段作为分片集的关键字时,则field2既是分片关键字,也是复合索引的前缀。外国人写的这些英语,还是很绕的,要理解一下。
{_id:1, field1: [2,8],field2: 'A'}哈希索引
哈希索引,不能是多键索引
索引覆盖查询
多键索引不能覆盖数组字段的查询。但是,多键索引,能够使用索引前缀,覆盖非数组字段的查询。如下面的一个使用案例。
在集合matches中插入文档。
db.matches.insertMany([ { name: "joe", event: ["open", "tournament"]}, { name: "bill", event: ["match", "championship"]} ])在name字段和event字段建立索引
db.matches.createIndex({ name: 1, event: 1 })该索引是复合多键索引,但是能够覆盖在name字段的查询
db.matches.find({ name: "joe" }).explain()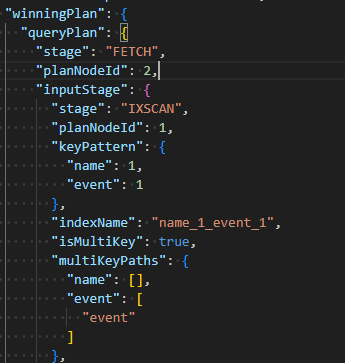
使用数组作为查询条件
当查询过滤器中,使用整个数组做为查询条件时,Mongodb能够使用多键索引,查询数组过滤条件中的第一个数组元素,但不能使用多键索引去查询整个数组。当Mongodb使用多键索引查询过滤数组中的第一个元素以后所查询出来的文档,Mongodb在内存中会对这部分文档进一步过滤,过滤出复合查询条件中整个数组的文档。
举例说明一下这个过程。创建集合inventory并插入数据
db.inventory.insertMany([ { _id:5, type: "food", item:"apple", ratings: [ 5, 8, 9 ] }, { _id:6, type: "food", item:"banana", ratings: [ 5, 9 ] }, { _id:7, type: "food", item:"grapes", ratings: [ 9, 5, 8 ] }, { _id:8, type: "food", item:"orange", ratings: [ 5, 9, 5 ] }, { _id:9, type: "food", item:"pear", ratings: [ 9, 5 ] } ])在数组ratings建立多键索引
db.inventory.createIndex({ratings: 1})构建一个使用数组作为过滤器的查询语句
db.inventory.find({ ratings: [5, 9] })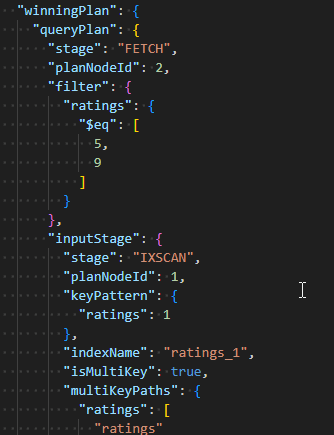
在查询计划中,能够看出,mongodb先使用5通过多键索引,查询出所有包含元素5的文档,然后在内存中过滤出包含整个数组[5,9]的文档数据
$expr
$expr表达式,不支持多键索引
应用
为数值数组添加索引
创建students集合,并插入数据。其中 test_scores是数值类型的数组。
db.students.insertMany([ {name: 'Andre Robinson', test_scores: [88, 97]}, {name: 'Alice Martin', test_scores: [62, 73]}, {name: 'Bob Smith', test_scores: [92, 89]} ])用户经常需要查询出至少有一次测验分数大于90的同学,这可以向数组字段添加索引来提高性能
db.students.createIndex({test_scores: 1})因为字段test_scores是数组类型,所以Mongodb自动为该字段创建了多键索引。该索引中包含了字段test_scores的所有值,并按照从小到大排列,[62, 73, 88, 89, 92, 97].该索引支持在字段test_scores上的查询
如
db.students.find({ test_scores: { $elemMatch: { $gte: 90 } } })为文档数组添加索引
构建inventory集合并插入数据
db.inventory.insertMany([ { item: "t-shirt", stock: [ { size: "S", quantity: 8 }, { size: "L", quantity: 10 } ] }, { item: "sweater", stock: [ { size: "S", quantity: 4 }, { size: "M", quantity: 7 } ] }, { item: "vest", stock: [ { size: "S", quantity: 6 }, { size: "L", quantity: 1 } ] } ])用户需要在库存低于5的时候,下订单来补货。为了查找出哪些需要补货,需要构建语句,查出来stock数组中,数量quantity少于5的记录。为了提高性能,用户需要在字段stock.quantity上添加索引。
db.inventory.createIndex({'stock.quantity': 1})因为stock是包含文档的数组,索引Mongodb将这个索引存储为多键索引。该索引将字段stock.quantity所有值按照从小到大排列[1,4,6,7,8,10]
构建语句,查询出少于5的数据
db.inventory.find({'stock.quantity': { $lt: 5 }})查询数据,按照库存的倒序排列
db.inventory.find().sort({'stock.quantity': -1})