
阅读量:1
【图解大数据技术】Spark
Spark简介
Spark与MapReduce一样,也是大数据计算框架。Spark相比MapReduce拥有更快的执行速度和更低的编程复杂度。
Spark包括以下几个模块:
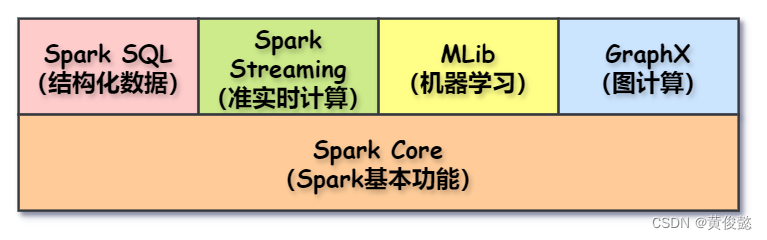
- Spark Core:封装了Spark的基本功能,比如RDD、任务调度等。
- Spark SQL:Spark SQL可以处理结构化数据,当我们遇到结构化数据的计算时,可以使用Spark SQL,它允许我们把数据集映射为表结构,然后像操作关系型数据库的库表一样操作Spark SQL的表。
- Spark Streaming:Spark Streaming可以做流式的准实时计算,比如可以监听kafka的消息做实时计算。
- MLib:提供了机器学习的程序库。
- GraphX:用于图计算的API。
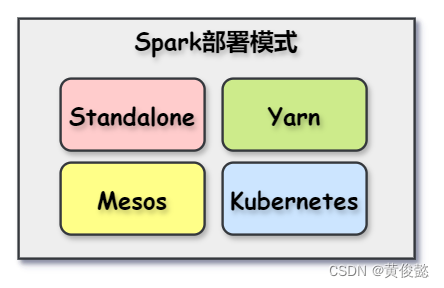
Spark支持以下几种部署模式:
- Standalone
- Yarn
- Mesos
- Kubernetes
Spark是支持使用Yarn做资源调度的,因此Spark是可以替代掉MapReduce的。
而Mesos和Yarn一样,也是一个分布式资源管理器。
RDD
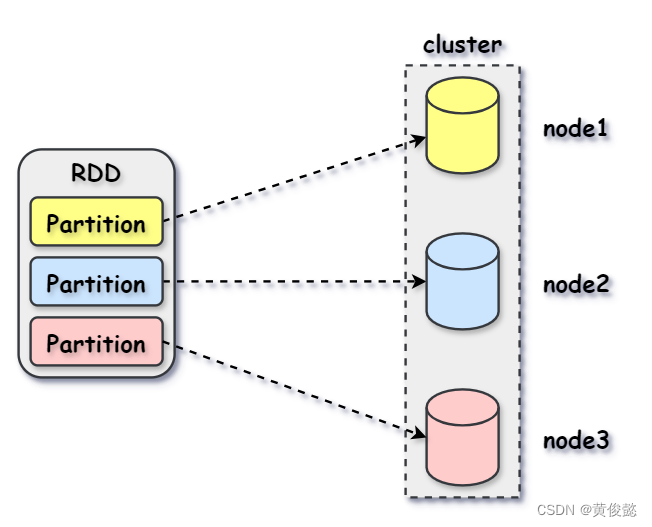
RDD(Resilient Distributed Dataset)的意思是弹性分布式数据集,本质上就是数据集,是Spark中最基本的数据抽象。
RDD是对不同存储节点的分片数据组成的数据集的抽象,RDD中每个Partition都指向存储集群中某个节点上的一个数据分片,当然我们也可以手动指定RDD的分区数。
Spark的计算就是对RDD的计算,Spark的计算是基于RDD进行的,一个RDD经过若干转换操作函数,转换操作本身返回的也是RDD,直到遇到action操作,则生成数据结果集返回。
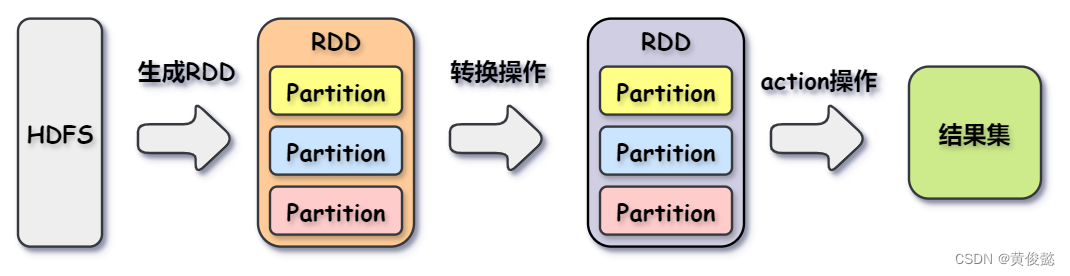
RDD的转换操作和action操作包括以下这些:
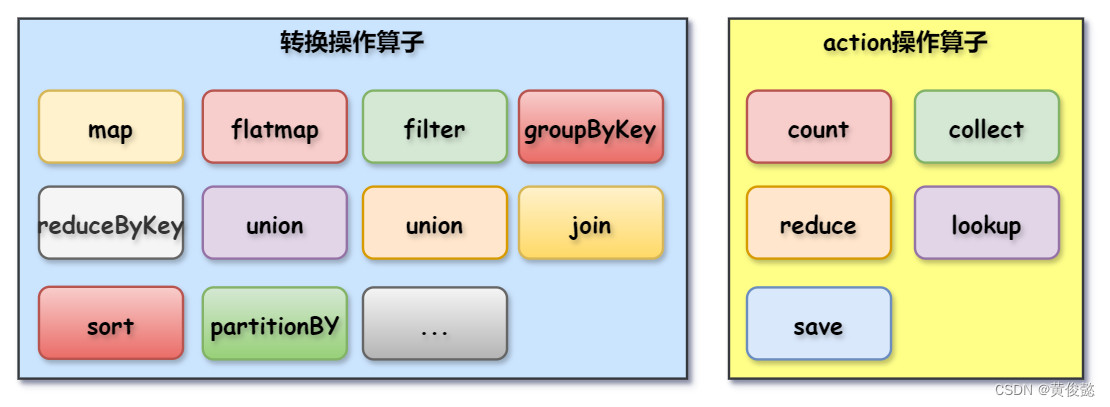
Spark示例
Spark的wordcount示例:
val textFile = sc.textFile("hdfs://...") // 从hdfs中读取数据生成一个RDD val counts = textFile.flatMap(line => line.split(" ")) // 按行切分 .map(word => (word, 1)) // 每个单词映射为1 .reduceByKey(_ + _) // 计算每个单词个数 counts.saveAsTextFile("hdfs://...") // 结果写回HDFS 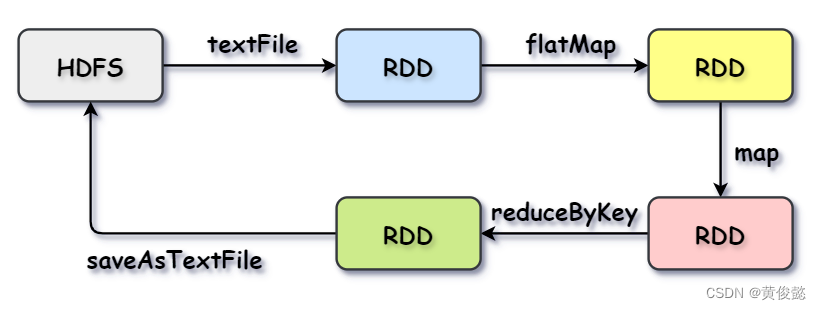
Spark运行原理
整体流程
Spark 支持 Standalone、Yarn、Mesos、Kubernetes 等多种部署方案,下面的运行流程不针对任何一种运行方案,不同运行方案可能角色名称不同,但是大体流程是相似的。
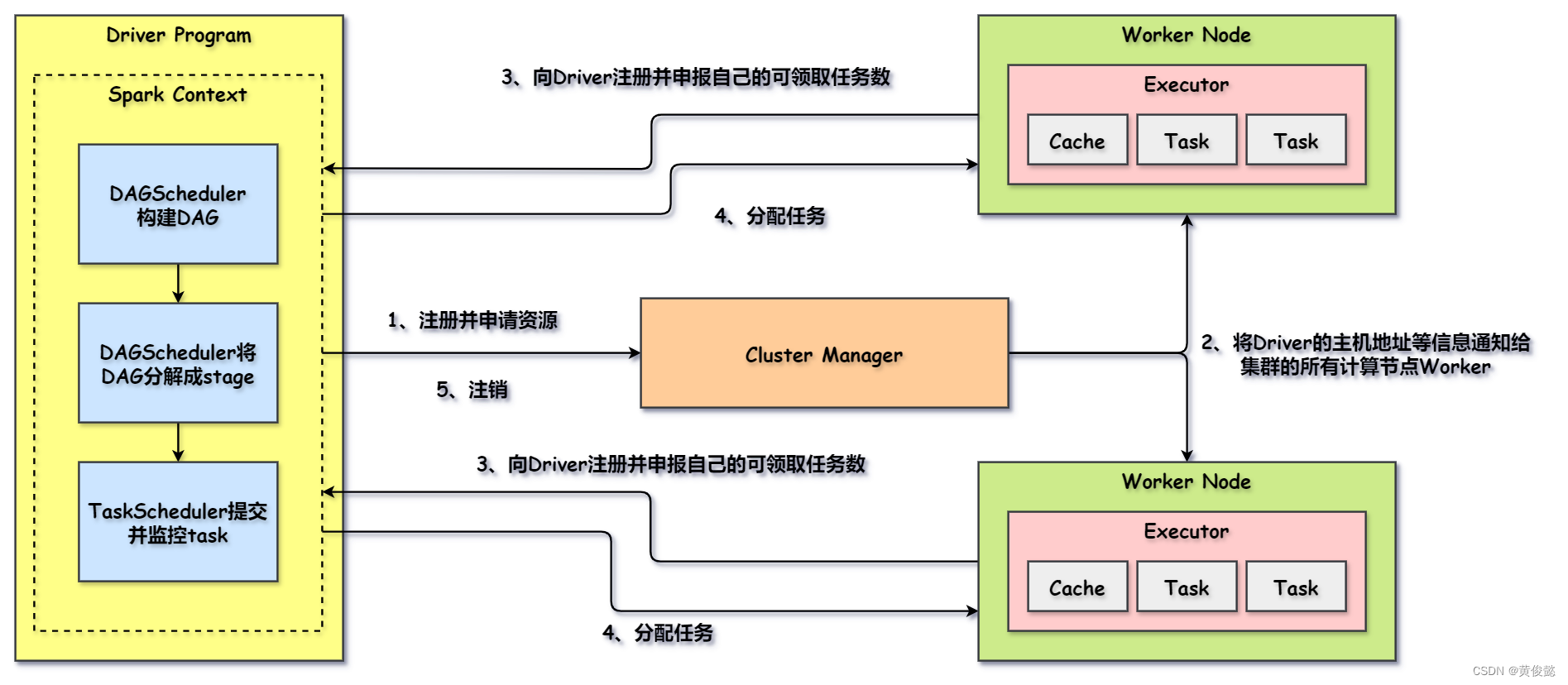
- Spark应用程序在JVM进程中启动,这个进程就是Driver进程。
- Driver进程启动后,调用SparkContext进行初始化,SparkContext启动DAGScheduler构建DAG(有向无环图)。
- DAGScheduler将DAG切分成一个一个的stage(阶段)。
- Driver向ClusterManager注册并申请资源。
- ClusterManager把Driver的主机地址等信息通知给计算节点(上图的Worker Node)。
- 计算节点收到ClusterManager的通知后,向Driver注册并申报自己可领取的任务数。
- SparkContext调用TaskScheduler给计算节点分配任务。
- 所有任务执行完毕后,Driver向ClusterManager发起注销。
DAG 与 stage
DAG是有向无环图,我们的代码会被Spark解析成DAG,DAG上的节点代表的就是RDD,边代表的就是RDD的操作。
比如以下程序:
val textFile = sc.textFile("hdfs://...") // 从hdfs中读取数据生成一个RDD val counts = textFile.flatMap(line => line.split(" ")) // 按行切分 .map(word => (word, 1)) // 每个单词映射为1 .reduceByKey(_ + _) // 计算每个单词个数 counts.saveAsTextFile("hdfs://...") // 结果写回HDFS 会被解析成如下DAG

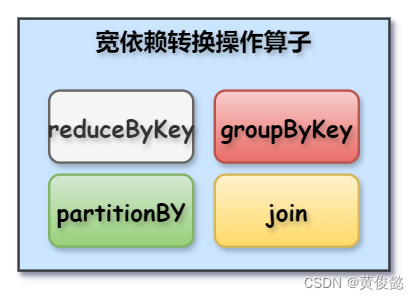
上图中,父RDD的一个Partition只会被子RDD的一个Partition依赖的这种情况叫窄依赖,而父RDD的一个Partition会被子RDD的多个Partition依赖的这种情况叫宽依赖。

宽依赖是存在shuffle的,Spark会根据宽依赖划分stage。
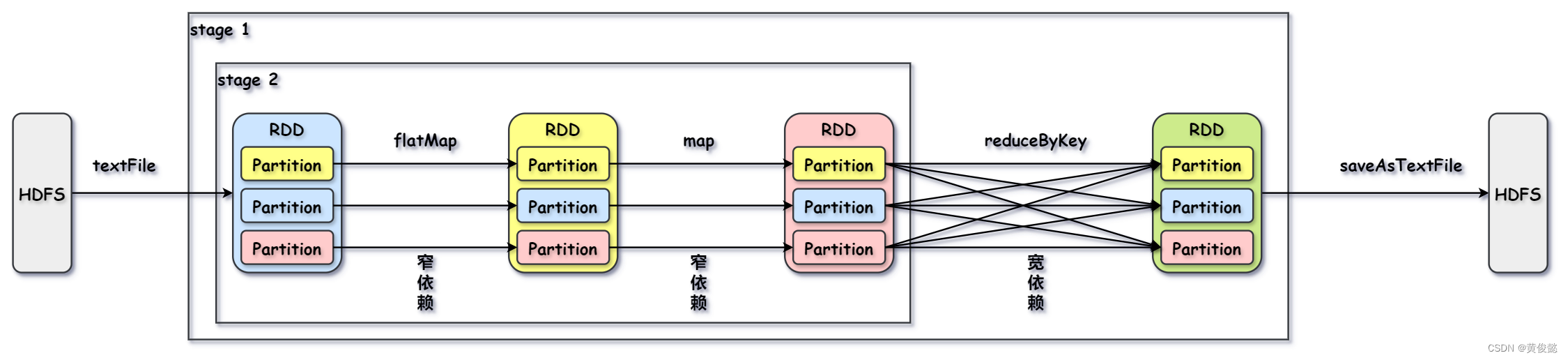
涉及到宽依赖的操作主要有:groupByKey、partitionBy、reduceByKey、join。
为什么Spark比MapReduce快?
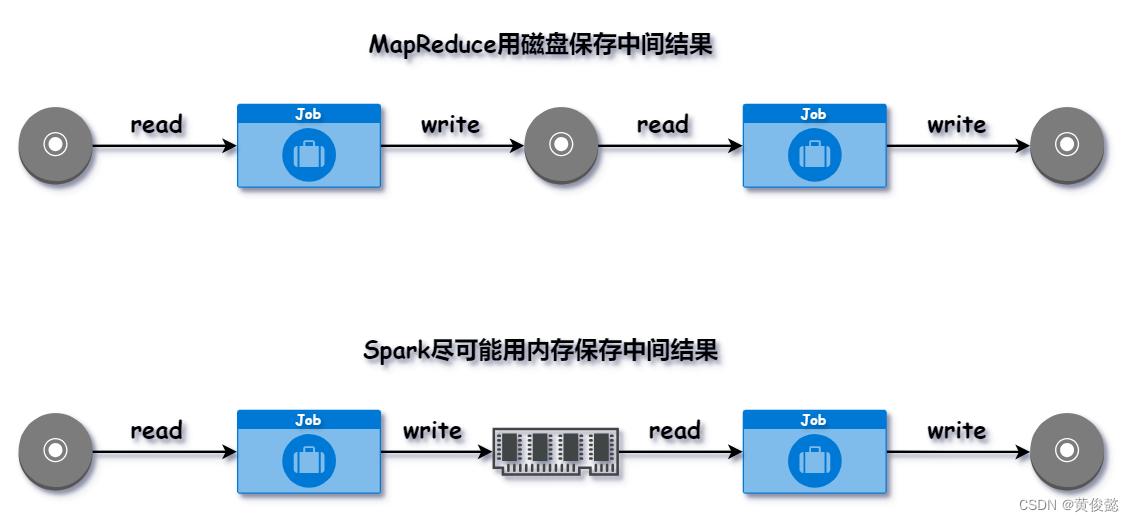
Spark尽量使用内存来保存中间结果;而MapReduce则默认使用磁盘保存中间结果,这是Spark比MapReduce快的其中一个原因。
另外一个原因是在处理迭代式计算的时候,MapReduce要通过多个MapReduce程序进行处理,每个MapReduce都经过Map-Shuffle-Reduce的处理,然后上一个Reduce输出的结果作为下一个Map的输入,这种处理方式效率不高。
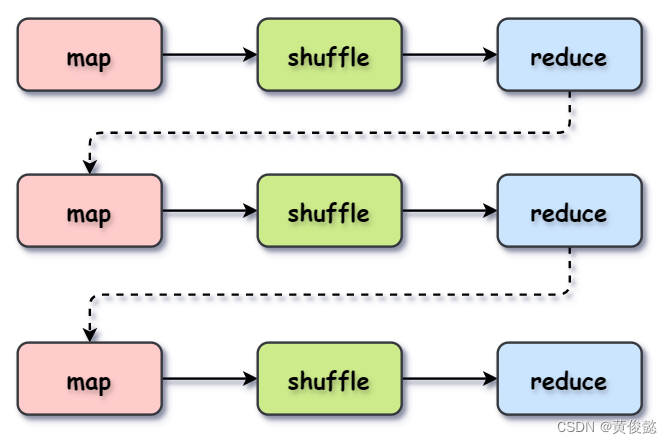
而Spark使用DAG 执行引擎,能够构建复杂的多阶段任务流程,并优化执行计划。这样可以在任务之间重用数据,减少不必要的读写操作,相比MapReduce的线性Map-Shuffle-Reduce流程,DAG能更灵活地管理计算任务,减少磁盘I/O次数,尽管shuffle次数本身并不能减少。
