
阅读量:1

一、故障概述
某日10:58分左右客户管理系统数据库节点1所有实例异常重启,重启后业务恢复正常。经过分析发现,此次实例异常重启的是数据库节点1。
二、故障原因分析
1、数据库日志分析
从节点1的数据库日志来看,10:58:49的时候数据库进程开始被abort,最终PMON进程因为481错误而终止实例,这个报错一般表示网络问题。
alert_reportdb1.log:
***********************************************************************
Sat Dec 07 10:58:49 XXXX
***********************************************************************
Fatal NI connect error 12537, connecting to:
(LOCAL=NO)
Fatal NI connect error 12537, connecting to:
(LOCAL=NO)
Fatal NI connect error 12537, connecting to:
(LOCAL=NO)
VERSION INFORMATION:
TNS for Linux: Version 11.2.0.4.0 - Production
Oracle Bequeath NT Protocol Adapter for Linux: Version 11.2.0.4.0 - Production
TCP/IP NT Protocol Adapter for Linux: Version 11.2.0.4.0 - Production
TNS-12537: TNS:connection closed
ns main err code: 12537
ns secondary err code: 12560
TNS-12537: TNS:connection closed
nt main err code: 0
ns secondary err code: 12560
nt secondary err code: 0
nt main err code: 0
TNS-12537: TNS:connection closed
nt OS err code: 0
nt secondary err code: 0
ns secondary err code: 12560
nt OS err code: 0
nt main err code: 0
nt secondary err code: 0
nt OS err code: 0
opiodr aborting process unknown ospid (36742) as a result of ORA-609
opiodr aborting process unknown ospid (36722) as a result of ORA-609
opiodr aborting process unknown ospid (36738) as a result of ORA-609
Sat Dec 07 10:58:49 2023
***********************************************************************
Fatal NI connect error 12537, connecting to:
(LOCAL=NO)
VERSION INFORMATION:
TNS for Linux: Version 11.2.0.4.0 - Production
Oracle Bequeath NT Protocol Adapter for Linux: Version 11.2.0.4.0 - Production
TCP/IP NT Protocol Adapter for Linux: Version 11.2.0.4.0 - Production
Time: 07-DEC-XXXX 10:58:49
Tracing not turned on.
Tns error struct:
ns main err code: 12537
TNS-12537: TNS:connection closed
ns secondary err code: 12560
nt main err code: 0
nt secondary err code: 0
Sat Dec 07 10:58:49 2023
***********************************************************************
nt OS err code: 0
Fatal NI connect error 12537, connecting to:
(LOCAL=NO)
VERSION INFORMATION:
TNS for Linux: Version 11.2.0.4.0 - Production
Oracle Bequeath NT Protocol Adapter for Linux: Version 11.2.0.4.0 - Production
TCP/IP NT Protocol Adapter for Linux: Version 11.2.0.4.0 - Production
Time: 07-DEC-XXXX 10:58:49
Tracing not turned on.
Tns error struct:
ns main err code: 12537
TNS-12537: TNS:connection closed
opiodr aborting process unknown ospid (36751) as a result of ORA-609
ns secondary err code: 12560
nt main err code: 0
nt secondary err code: 0
nt OS err code: 0
opiodr aborting process unknown ospid (36761) as a result of ORA-609
Sat Dec 07 10:58:49 2023
。。。。。
opiodr aborting process unknown ospid (36746) as a result of ORA-609
opiodr aborting process unknown ospid (36777) as a result of ORA-609opiodr aborting process unknown ospid (36807) as a result of ORA-609
opiodr aborting process unknown ospid (36819) as a result of ORA-609
Sat Dec 07 10:58:49 2023
PMON (ospid: 48234): terminating the instance due to error 481
2、Crs alert日志分析
从crs的alertlog信息中可以知道,在10:58:49的时候,所有数据库资源监测失败,这个和数据库实例abort时间点一致,应该是数据库中止后的表现。
------------------------------节点1 crs alert trace文件----------------------
xxxx- 12-07 10:58:49.068 [CRSD(46493)]CRS-5825: Agent '/u01/app/grid/12.1.0.2/bin/oraagent_grid' is unresponsive and will be restarted. Details at (:CRSAGF00131:) {1:44542:2} in /u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd.trc.
xxxx- 12-07 10:58:49.094 [ORAAGENT(47263)]CRS-5832: Agent '/u01/app/grid/12.1.0.2/bin/oraagent_grid' was unable to process commands. Details at (:CRSAGF00128:) {1:44542:2} in /u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_grid.trc.
xxxx- 12-07 10:58:49.094 [ORAAGENT(47263)]CRS-5818: Aborted command 'check' for resource 'ora.LISTENER.lsnr'. Details at (:CRSAGF00113:) {1:44542:2} in /u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_grid.trc.
xxxx- 12-07 10:58:50.173 [ORAAGENT(47494)]CRS-5011: Check of resource "reportdb" failed: details at "(:CLSN00007:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_oracle.trc"
xxxx- 12-07 10:58:50.298 [ORAAGENT(47494)]CRS-5011: Check of resource "managedb" failed: details at "(:CLSN00007:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_oracle.trc"
xxxx- 12-07 10:58:51.029 [ORAAGENT(47494)]CRS-5011: Check of resource "hwxddb" failed: details at "(:CLSN00007:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_oracle.trc"
xxxx- 12-07 10:58:51.222 [ORAAGENT(47494)]CRS-5011: Check of resource "hwwlxtdb" failed: details at "(:CLSN00007:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_oracle.trc"
xxxx- 12-07 10:58:51.284 [ORAAGENT(47494)]CRS-5011: Check of resource "hwyyxtdb" failed: details at "(:CLSN00007:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_oracle.trc"
xxxx- 12-07 10:58:51.285 [ORAAGENT(47494)]CRS-5011: Check of resource "yxgldb" failed: details at "(:CLSN00007:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_oracle.trc"
xxxx- 12-07 10:58:51.297 [ORAAGENT(47494)]CRS-5011: Check of resource "mhlwyxdb" failed: details at "(:CLSN00007:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_oracle.trc"
xxxx- 12-07 10:58:51.298 [ORAAGENT(47494)]CRS-5011: Check of resource "boarddb" failed: details at "(:CLSN00007:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_oracle.trc"
xxxx- 12-07 10:58:52.273 [ORAAGENT(47494)]CRS-5011: Check of resource "tyjgdb" failed: details at "(:CLSN00007:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_oracle.trc"
xxxx- 12-07 10:58:52.285 [ORAAGENT(47494)]CRS-5011: Check of resource "obsadb" failed: details at "(:CLSN00007:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_oracle.trc"
xxxx- 12-07 10:58:52.969 [ORAAGENT(36712)]CRS-8500: Oracle Clusterware ORAAGENT process is starting with operating system process ID 36712
xxxx- 12-07 10:58:54.741 [ORAAGENT(41064)]CRS-5011: Check of resource "ora.asm" failed: details at "(:CLSN00006:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/ohasd_oraagent_grid.trc"
xxxx- 12-07 10:58:55.406 [ORAAGENT(36712)]CRS-5011: Check of resource "ora.asm" failed: details at "(:CLSN00006:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_grid.trc"
xxxx- 12-07 10:58:55.424 [ORAAGENT(36712)]CRS-5011: Check of resource "ora.asm" failed: details at "(:CLSN00006:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/crsd_oraagent_grid.trc"
xxxx- 12-07 10:58:55.455 [ORAAGENT(41064)]CRS-5011: Check of resource "ora.asm" failed: details at "(:CLSN00006:)" in "/u01/app/12.1.0.2/diag/crs/mpc01dbadm01/crs/trace/ohasd_oraagent_grid.trc"
xxxx- 12-07 10:58:55.527 [ORAAGENT(36712)]CRS-5017: The resource action "ora.RECOC1.dg start" encountered the following error:
xxxx- 12-07 10:58:55.527+ORA-01092: ORACLE instance terminated. Disconnection forced
3、Asm trace日志分析
从1#asm的alertlog可以看到10:58:48,2#实例发起对1#asm实例的abort,需要通过2#alert和LMON trace分析,同时还伴有IPC Send timeout的信息,这个一般是心跳网络超时的报错。
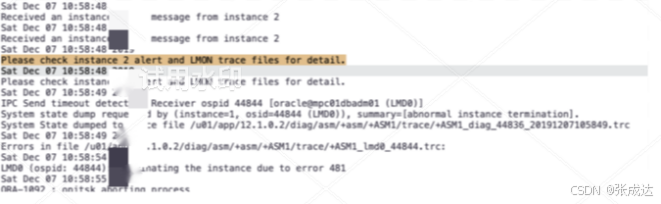
2#ASM的alertlog可以看到10:56:35就发生了2#核心后台进程发给1#LMD0(44844)的超时报错,随即判断1#asm实例僵死而发起kill!
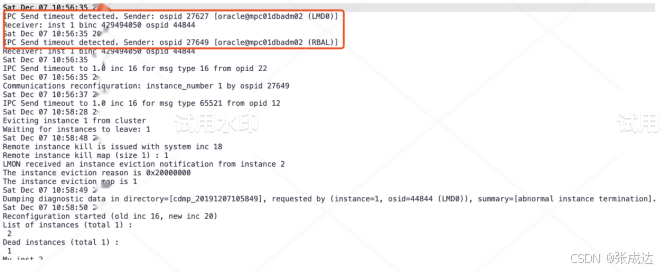
再看2#ASM的LMON日志,10:56:35开始尝试reconfig,并设置100s超时vote:
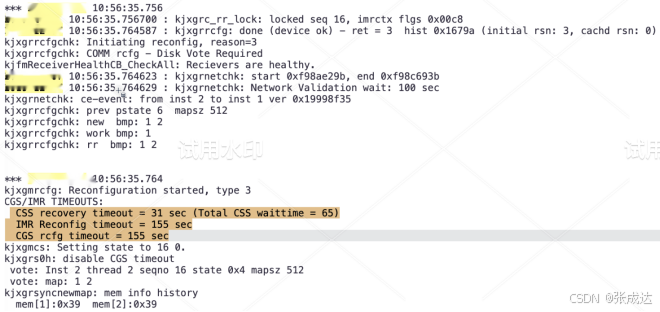
......
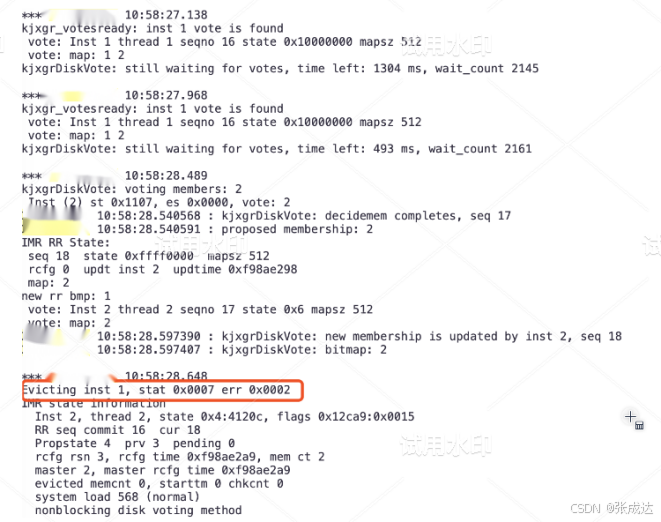
随后在10:58:28通过选举驱逐1#asm实例:
4、节点1 diag日志分析
看看1#asm实例crash时的diag文件+ASM1_diag_44836_20231207105849.trc,看看2#asm进程接受进程LMD0(44844)的状态:
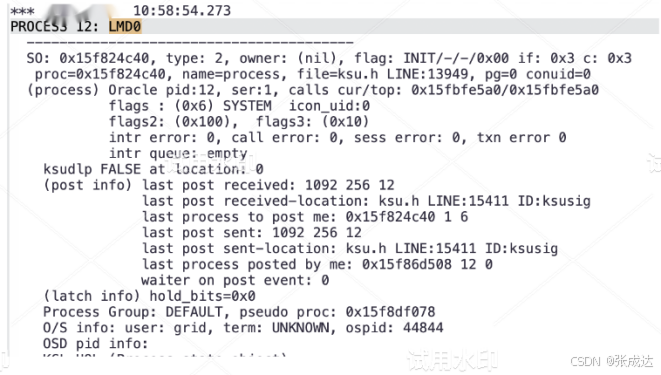
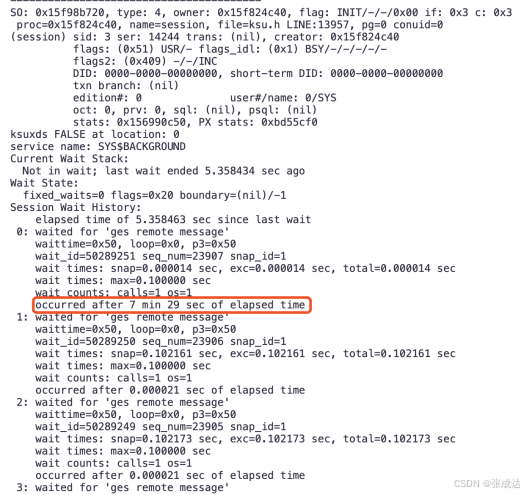
可以看到故障前的等待都是“ges remote message”,最后1个历史等待7分29s,这个是典型的IPC网络等待:
查看系统和网络丢包有关的参数,发现2个节点都会有大量的“packet reassembles failed”丢包发生:
[root@mpc01dbadm01 trace]# netstat -s
Ip:
36764567053 total packets received
70116 with invalid addresses
0 forwarded
0 incoming packets discarded
24572526733 incoming packets delivered
21770066525 requests sent out
692241 outgoing packets dropped
30980 fragments dropped after timeout
15457160506 reassemblies required
3265291587 packets reassembled ok
226816 packet reassembles failed
1796293625 fragments received ok
664 fragments failed
7885036302 fragments created
[root@mpc01dbadm02 trace]# netstat -s
Ip:
30349664623 total packets received
79036 with invalid addresses
0 forwarded
0 incoming packets discarded
23893920057 incoming packets delivered
23820631106 requests sent out
295480 outgoing packets dropped
186 dropped because of missing route
28255 fragments dropped after timeout
8368295089 reassemblies required
1912747085 packets reassembled ok
202513 packet reassembles failed
3389250826 fragments received ok
3337 fragments failed
16013866546 fragments created
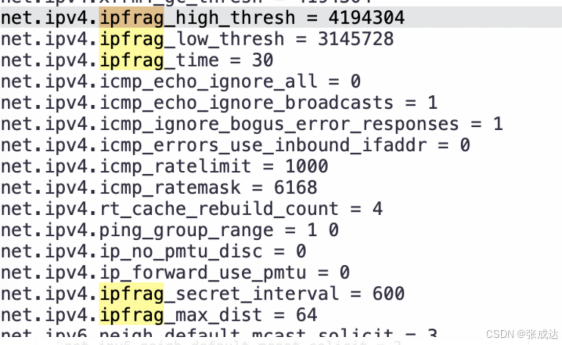
5、OS内核设置
当前数据库系统计算节点为RHEL6.8,存储节点为RHEL7.2,查看ipfrag参数为默认值:
MOS有篇相关文档:RHEL 6.6: IPC Send timeout/node eviction etc with high packet reassembles failure (文档 ID 2008933.1),现象和当前故障匹配,workaound是加大ipfrag相关参数:
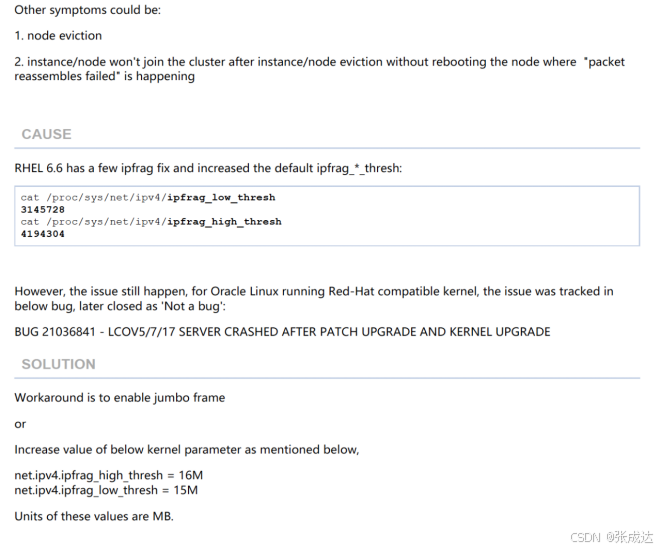
根据REDHAT官方文章说明,这种现象发生在如下场景:
- RHEL6.6/6.7,根据我们经验RHEL6/7都有类似故障发生;
- CPU较多(本机为56个);
- Oracle RAC环境

三、结论
- 本次故障由于ASM进程间通讯超时,导致2#实例发起了对1#asm实例的驱逐;
- 发现2个节点网络均存在大量“packet reassembles failed”丢包,根据MOS文档RHEL 6.6: IPC Send timeout/node eviction etc with high packet reassembles failure (文档 ID 2008933.1),这个是由于RHEL6/7在主机存在大量CPU时,IP分片组包超出分片缓存区导致,处理方案是使用巨桢(jumbo frame)或者调整IPFRAG相关系统配置。
四、处理建议
1、所有节点按如下最佳实践调整系统内核参数:
net.ipv4.ipfrag_high_thresh = 41943040
net.ipv4.ipfrag_low_thresh = 40894464
net.ipv4.ipfrag_time = 120
net.ipv4.ipfrag_secret_interval = 600
net.ipv4.ipfrag_max_dist = 1024
2、为便于故障分析,所有节点部署OSW
